作者:来自 Elastic Drew Tate
Elasticsearch 拥有许多新功能,可以帮助你根据使用场景构建最佳搜索方案。浏览我们的示例笔记本了解更多内容,开始免费试用云服务,或者立即在本地机器上尝试 Elastic。
对于我们开发者来说,优秀的自动补全似乎是理所当然的。它运行得很顺畅 ------ 直到你尝试亲手构建它。
这篇文章讲的是我们最近为支持 ES|QL 持续演进而进行的一次自动补全架构重建。
关于 ES|QL 的一点介绍
如果你还没听说过,ES|QL 是 Elastic 推出的新查询语言。它非常强大,我们认为它将成为未来 AI 代理、应用程序和人类与 Elastic 交互的主要方式。因此,我们在 Kibana 的多个地方(包括 Discover 和 Dashboard 应用)提供了 ES|QL 的编辑体验。
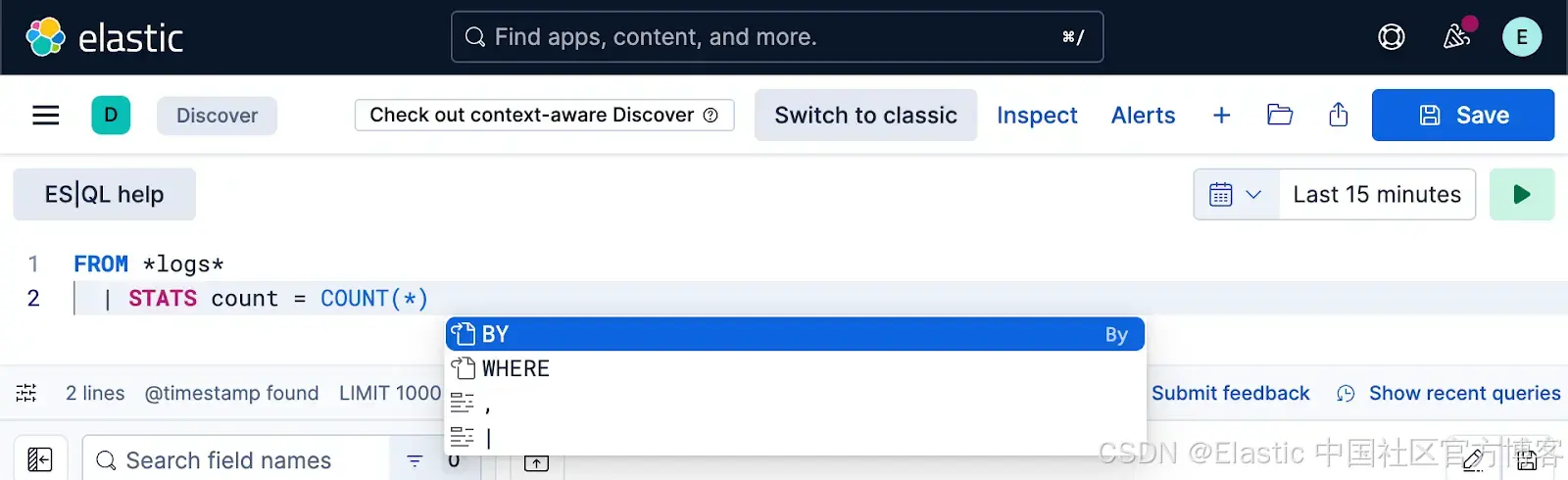 Discover 中的 ES|QL
Discover 中的 ES|QL
要理解这次重构,关键是要了解一些语言组件。
一个 ES|QL 查询由一系列连接在一起的命令组成,用于执行一连串的操作。
这里,我们将一个索引的数据与另一个索引进行连接:
FROM firewall_logs-* METADATA _index
| LOOKUP JOIN threat_list ON source.IP
| SORT _index在上面的示例中,FROM、LOOKUP JOIN 和 SORT 是命令。
命令可以包含主要的子组件(称为子命令),通常由下一个管道符号前的第二个关键字标识(例如上面示例中的 METADATA)。和命令一样,子命令也有自己的语义规则,用于定义关键字后面可以出现的内容。
ES|QL 也有函数,看起来与你预期的一样。请看下面示例中的 AVG:
FROM logs-* | STATS AVG(bytes) BY agent.name自动补全是帮助用户学习 ES|QL 的一个重要功能。
自动补全 1.0
我们最初构建的自动补全引擎具有以下几个关键特点:
- 声明式 - declarative ------ 使用静态声明来描述命令
- 通用性 - generic ------ 严重依赖通用逻辑,适用于大多数或全部语言上下文
- 具体化子命令 - Reified subcommands------ 将子命令视为一等抽象,拥有自己的逻辑
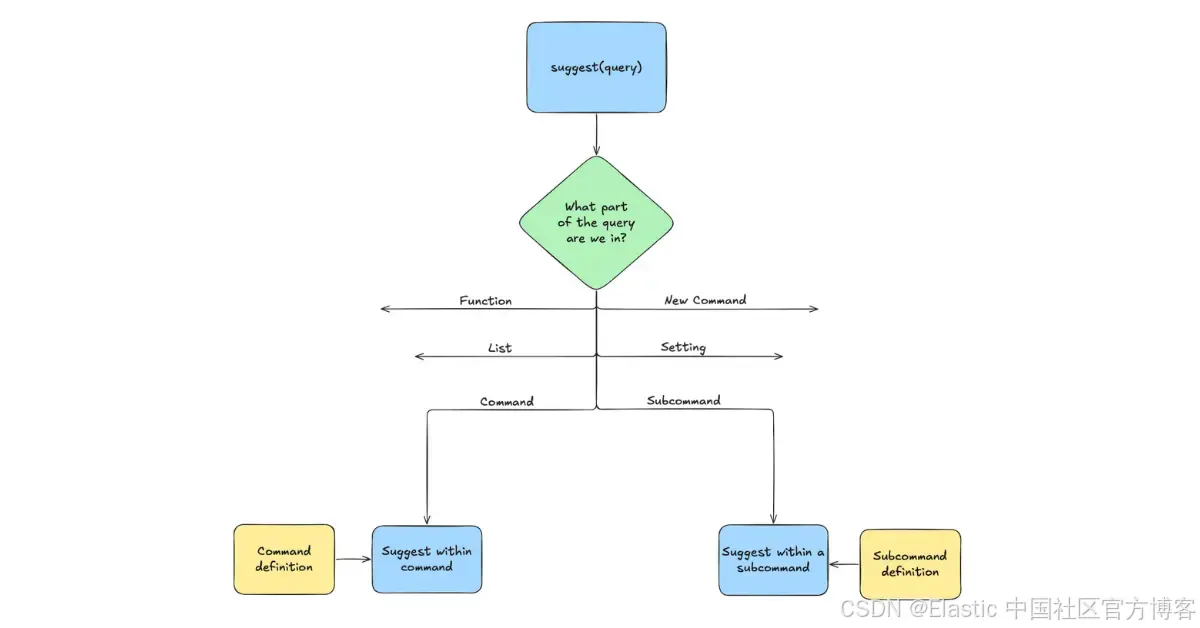
在顶层建议程序中,我们的代码会分析查询内容,检测用户光标所在的大致区域。然后根据语言子组件的不同,进入多个子程序中的一个。
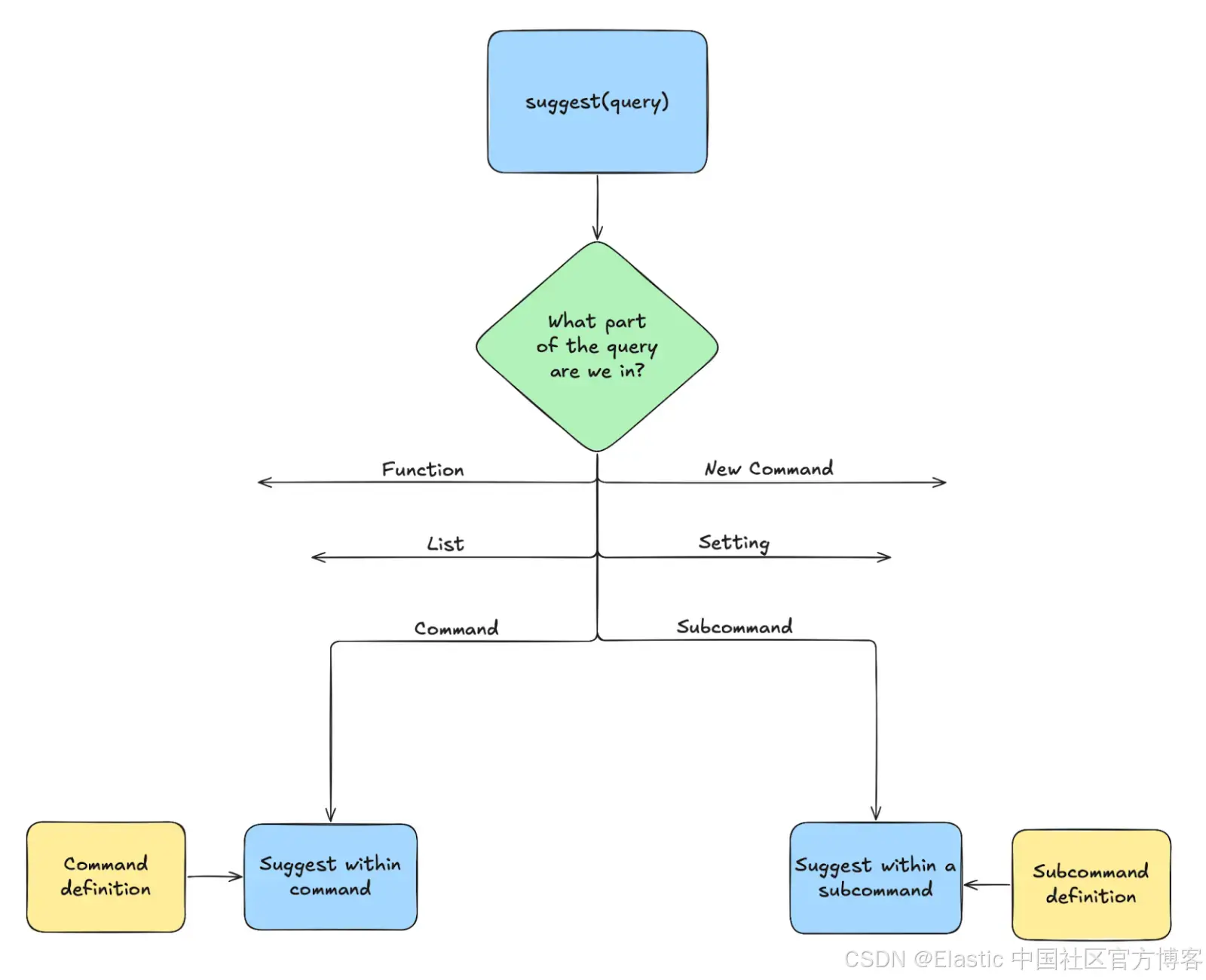
命令和子命令的语义是通过 "命令签名 - command signature" 以声明式方式描述的。它定义了命令名称后可以使用的模式。比如,它可能会声明 "接受任意数量的布尔表达式",或者"先接受一个字符串字段,再接受一个数值字面量"。
如果第一次分析判断光标处于某个命令或子命令中,对应的分支就会尝试将(子)命令签名与查询内容进行匹配,并以通用的方式推断出建议内容。
问题开始显现
起初,这种架构是有效的。早期的 ES|QL 命令相对统一。它们基本上看起来像这样:
COMMAND arg[, arg] SUB_COMMAND arg[, arg]但随着时间的推移,命令开始变得更加定制化。
随着每个新命令的增加,几个问题也随之出现并不断加剧:
- 代码复杂性------ 自动补全的代码变得庞大、复杂且难以理解。很难分清哪些逻辑适用于哪些命令。
- 缺乏正交性 ------ 对语言某一部分行为的更改常常会影响到语言的其他部分。例如,在 KEEP 中的字段列表添加逗号建议,意外地也在 DISSECT 的字段后给出逗号建议 ------ 这是无效的。
问题在于,新的语法和行为让我们原本 "通用" 的代码需要越来越多的特定命令分支,而命令定义则需要越来越多其实只适用于单个命令的 "通用" 设置。
逐渐地,我们开始意识到,用一个声明式接口来描述每个命令结构和行为的细微差异,这个想法有些理想化。
投资重构的时机
什么时候该投资进行重构?答案因情境而异。你需要权衡好收益与成本。说实话,你通常可以长期承担低效带来的代价 ------ 而且这可能是合理的。
推迟重构的一种方式是 "治标不治本"。我们就是这样坚持了好几个月。我们用冗长的注释来应对代码复杂性,用更完善的测试覆盖率和细致的人工测试来应对正交性不足的问题。
但总有一个时刻,修修补补的代价超过了彻底重构的成本。对我们来说,这个节点就是一个出色的新 ES|QL 功能的引入 ------ 基于聚合的过滤。
WHERE 命令自 ES|QL 初期就已经存在,但这个新功能让 WHERE 可以作为 STATS 中的子命令使用。
... | STATS COUNT(*) WHERE <expression>这看起来像是一个小改动,但它打破了原本清晰区分命令与子命令的架构界限。现在,我们有了一个既是命令又可以作为子命令的结构。
这个基本抽象的突破,加上之前积累的各种低效问题,让我们决定是时候进行投资了。
Autocomplete 2.0
ES|QL 并不是一个通用语言,而是一种查询语言。所以我们决定接受一个现实:命令本就是为特定需求而设计的(符合传统查询语言的风格)。
新的架构必须足够灵活和适应性强,同时要清晰地表达出哪些代码属于哪个命令。这意味着我们需要一个具备以下特性的系统:
- 命令式 - Imperative------ 不再通过声明命令名之后允许的内容并单独解释声明,而是直接编写逻辑来验证命令的正确性。
- 命令专属 - Command-specific------ 每个命令都有自己的逻辑。不再存在适用于所有命令的通用处理程序。
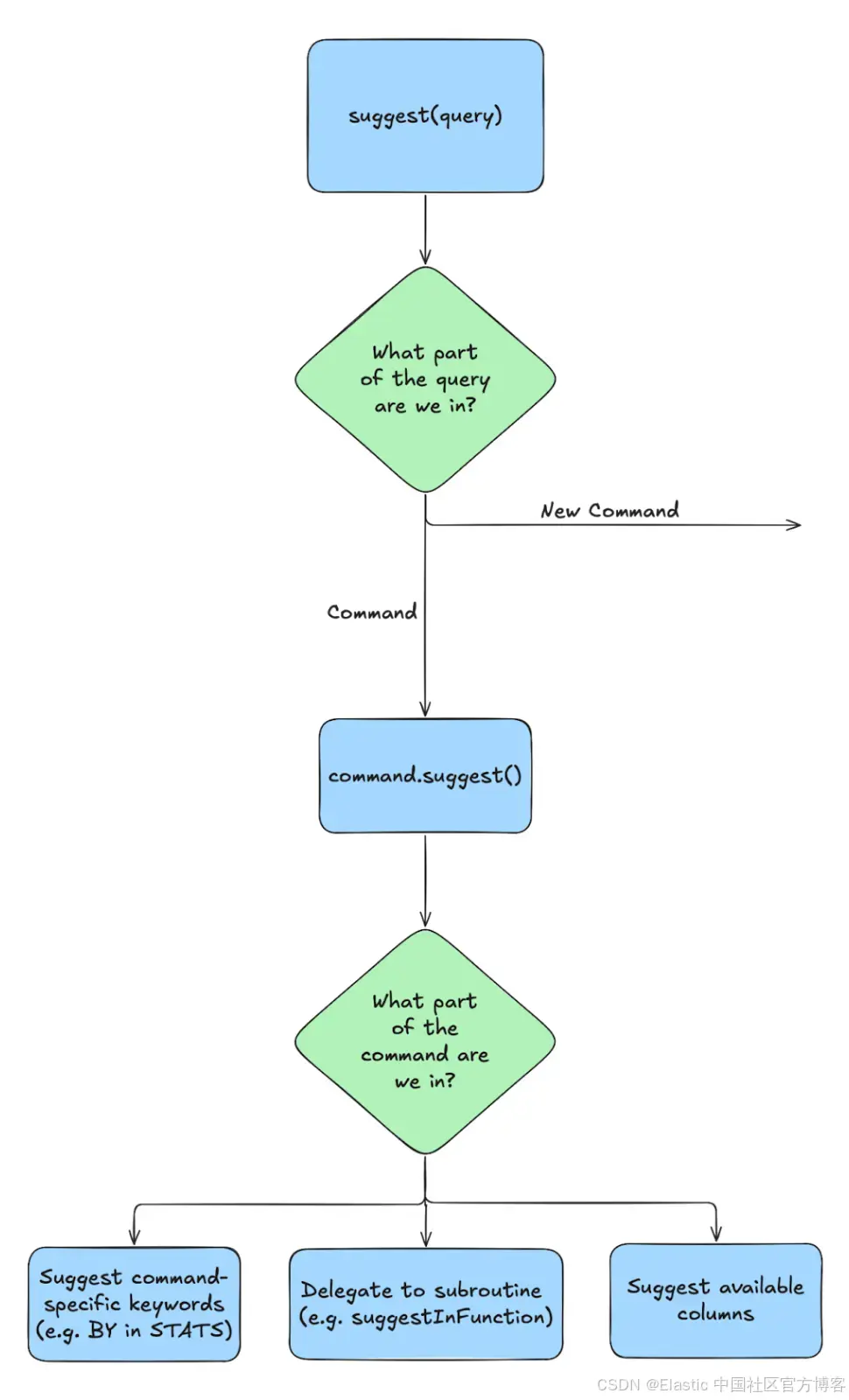
在 Autocomplete 1.0 中,前期的分类逻辑承担了大量工作。现在,它只判断光标是否已经位于某个命令内部。如果在命令内,它就直接交给该命令专属的建议方法。现在大部分的处理逻辑都发生在具体命令内部,该命令拥有对其建议生成的完整控制权。
这并不意味着命令之间完全不共享逻辑。它们仍然会将建议的生成,甚至一些初步判断步骤,委托给可复用的子程序(例如判断光标是否位于一个 ES|QL 函数中)。但同时,它们保留了按需定制行为的灵活性。
为每个命令提供自己的建议方法提升了代码隔离性,减少了副作用,也更清晰地表达了哪些代码适用于哪个命令。
核心仍是用户
毫无疑问,这次重构为开发者带来了更好的体验。每个接触过两个系统的人都能感受到这种改变带来的清新感。但归根结底,我们进行这项投入是为了服务我们的用户。
首先,有些 ES|QL 功能若没有此次重构,是无法合理支持的。我们的用户在编写 ES|QL 时期待获得高质量的建议,现在我们可以在更多上下文中满足这一需求。
旧系统很容易引入回归问题。而现在,我们预计此类问题会更少。
我们团队最主要的任务之一就是为新命令添加支持。现在,我们可以更快完成这项工作。
虽然这项工作还没有结束,但我们已经建立起了一个支持变化、而非抵抗变化的系统。通过这次投入,我们为语言和编辑器的未来发展打下了坚实的基础。
原文:How we rebuilt autocomplete for ES|QL - Elasticsearch Labs