作者简介
我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。

目录
[1. 前言](#1. 前言)
[2. 开通DeepSeek-V3/R1商用服务](#2. 开通DeepSeek-V3/R1商用服务)
[2.1 准备工作](#2.1 准备工作)
[2.2 详细开通步骤](#2.2 详细开通步骤)
[Step 1:登录华为云控制台](#Step 1:登录华为云控制台)
[Step 2:进入"模型推理-在线推理"模块](#Step 2:进入“模型推理-在线推理”模块)
[Step 3:开通商用服务](#Step 3:开通商用服务)
[Step 4:获取API调用信息](#Step 4:获取API调用信息)
[3. 方式一:REST API调用](#3. 方式一:REST API调用)
[3.1 基础调用示例](#3.1 基础调用示例)
[3.2 流式输出模式](#3.2 流式输出模式)
[4. 方式二:OpenAI SDK调用](#4. 方式二:OpenAI SDK调用)
[4.1 环境准备](#4.1 环境准备)
[4.2 基础调用示例](#4.2 基础调用示例)
[4.3 流式输出模式](#4.3 流式输出模式)
[5. 对比评测](#5. 对比评测)
[6. 使用建议](#6. 使用建议)
[7. 常见问题](#7. 常见问题)
[8. 总结](#8. 总结)
1. 前言
近年来,大模型技术快速发展,华为云推出的DeepSeek-V3/R1 商用大模型服务,为企业及开发者提供了高性能的AI推理能力。本文将详细介绍如何在华为云ModelArts Studio上开通DeepSeek-V3/R1商用服务,并分享实际使用体验,帮助开发者快速上手。
2. 开通DeepSeek-V3/R1商用服务
2.1 准备工作
-
华为云账号 :需注册并完成实名认证(个人/企业均可)
-
账号余额 ≥10元 (避免因欠费导致服务开通失败)
-
访问入口 :华为云ModelArts Studio
2.2 详细开通步骤
Step 1:登录华为云控制台
-
访问华为云官网,点击右上角**"登录"**,输入账号密码。
-
进入控制台 ,在顶部搜索栏输入 "ModelArts" ,进入 ModelArts Studio 服务页面。
Step 2:进入"模型推理-在线推理"模块
-
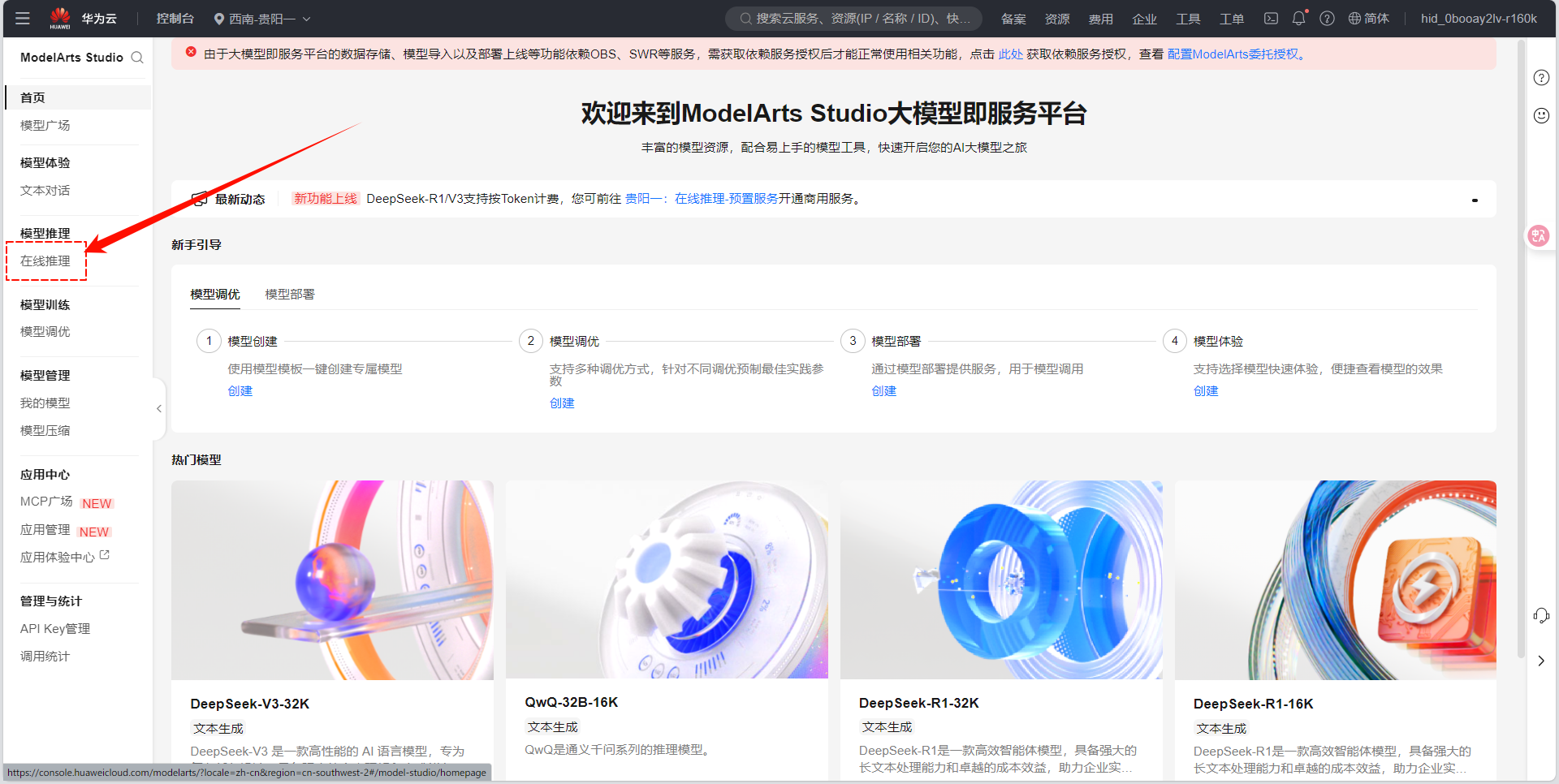
在左侧导航栏选择 "模型推理" → "在线推理" 。
-
点击 "商用服务" 标签页,找到 DeepSeek-V3/R1 大模型服务。
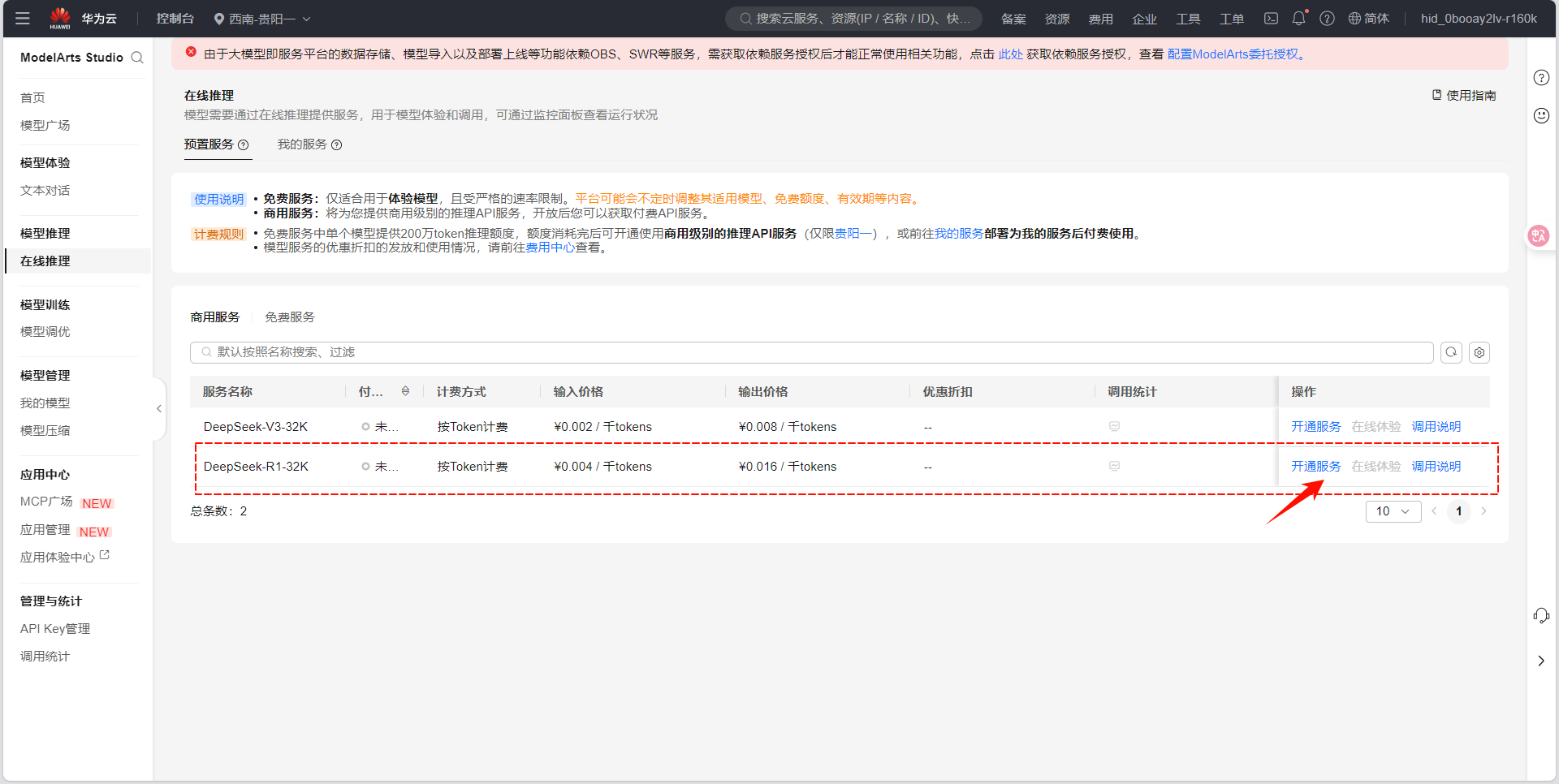
Step 3:开通商用服务
-
点击 "立即开通" ,系统会提示 "服务授权" ,勾选同意后确认。
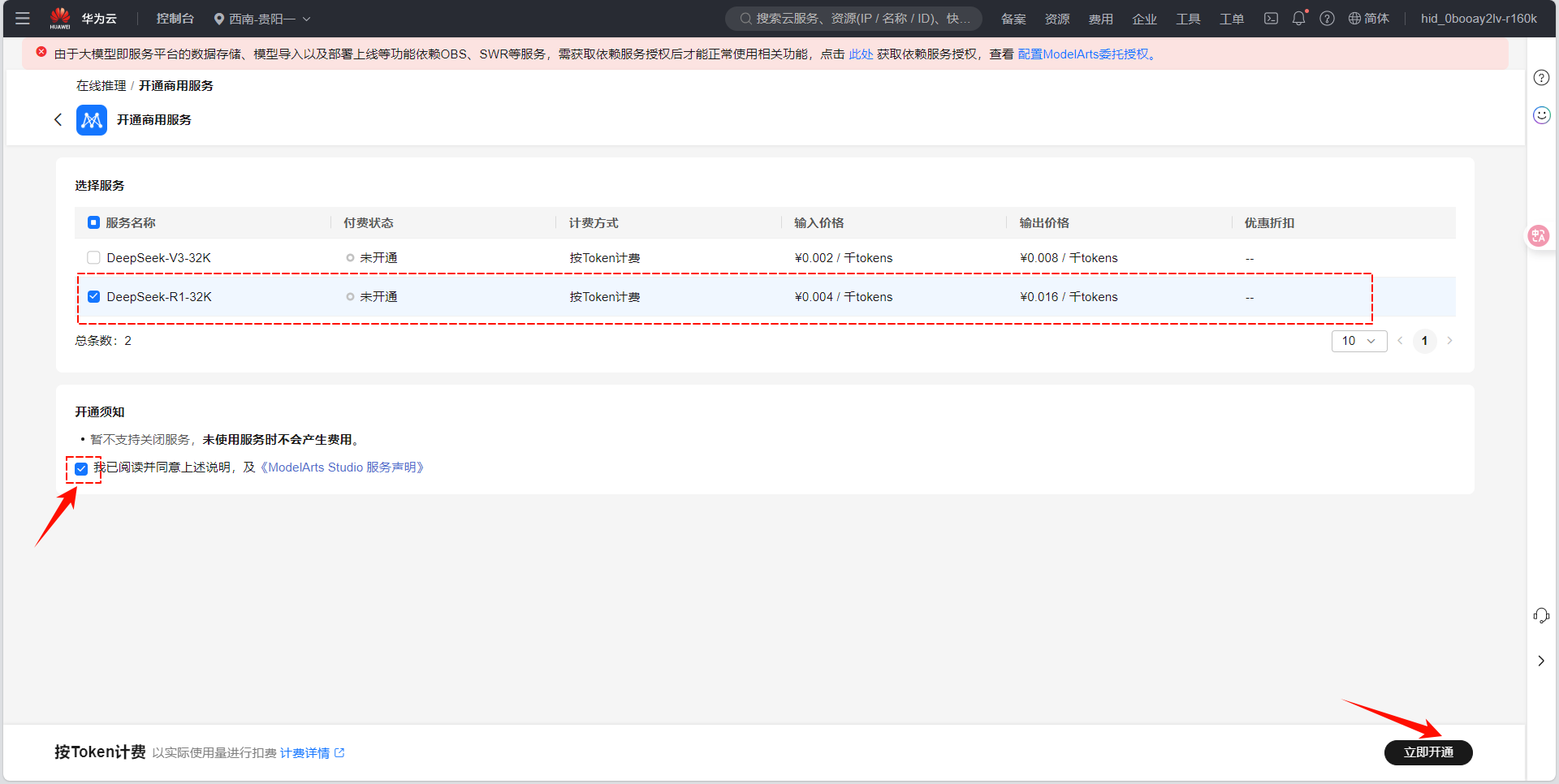
-
等待约1-2分钟,系统自动完成服务部署,状态变为 "运行中" 即表示开通成功。
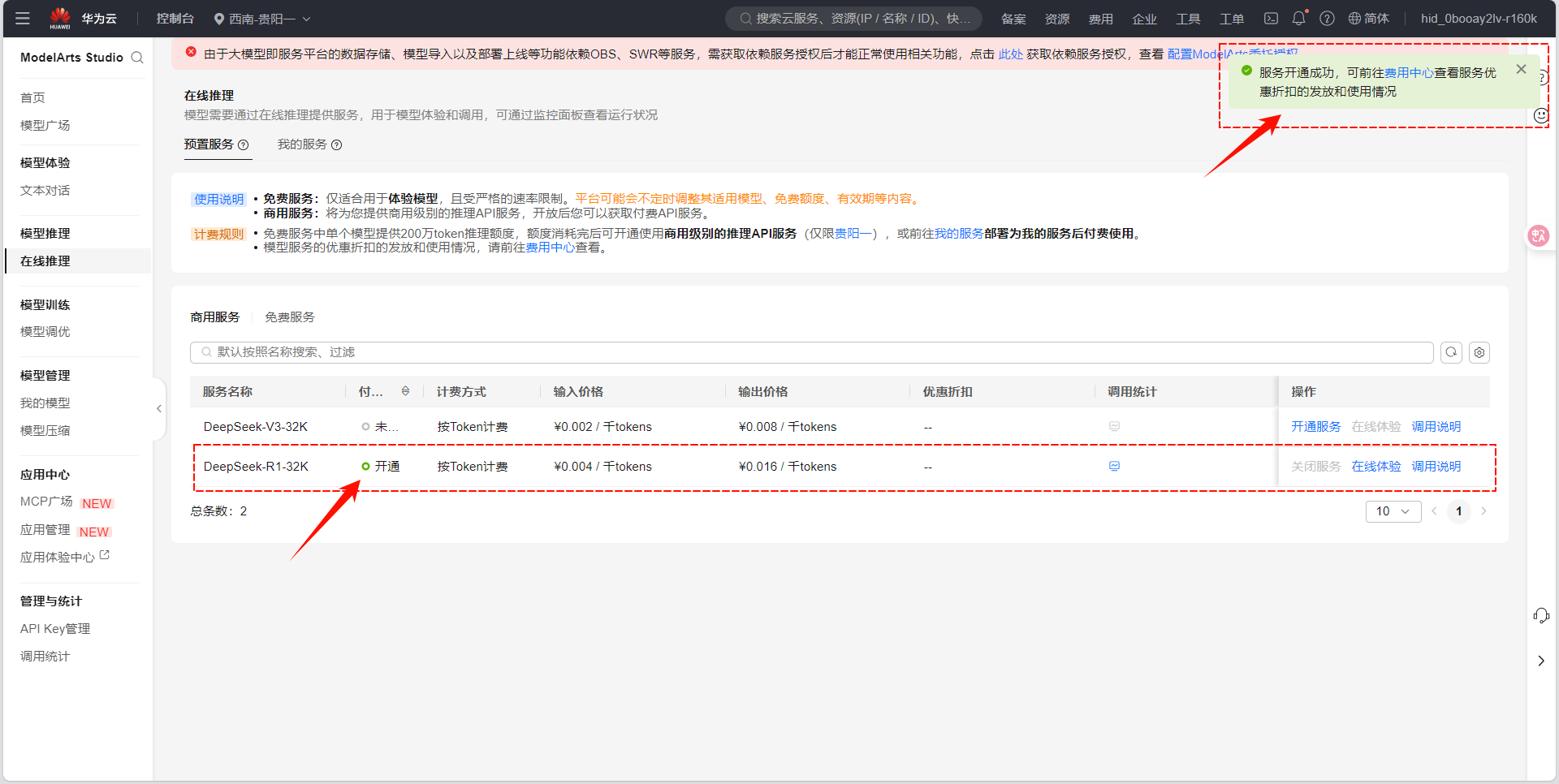
Step 4:获取API调用信息
-
在 "在线推理" 页面,找到已开通的DeepSeek-V3/R1服务,点击 "详情" 。
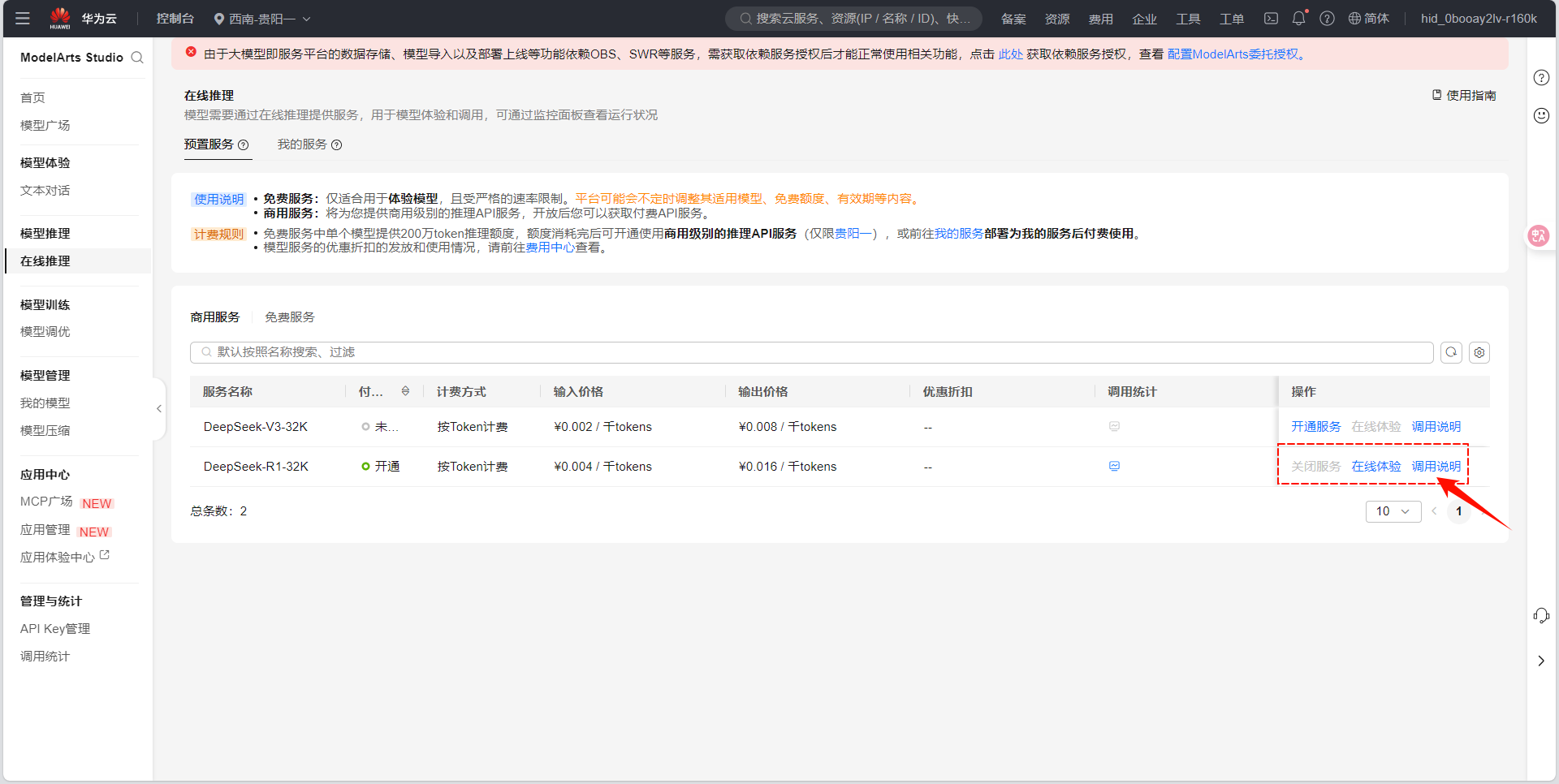
Y3DY4WF5wJLE3q8XEVpbRqNqUBse4SmaazT5_2jYw3logYwxEQEIpa04Vhu8VwRTtII_Grn5SnbNlr4OZb4LAw -
记录 API访问地址(Endpoint) 和 API密钥(AK/SK) ,后续调用需使用。
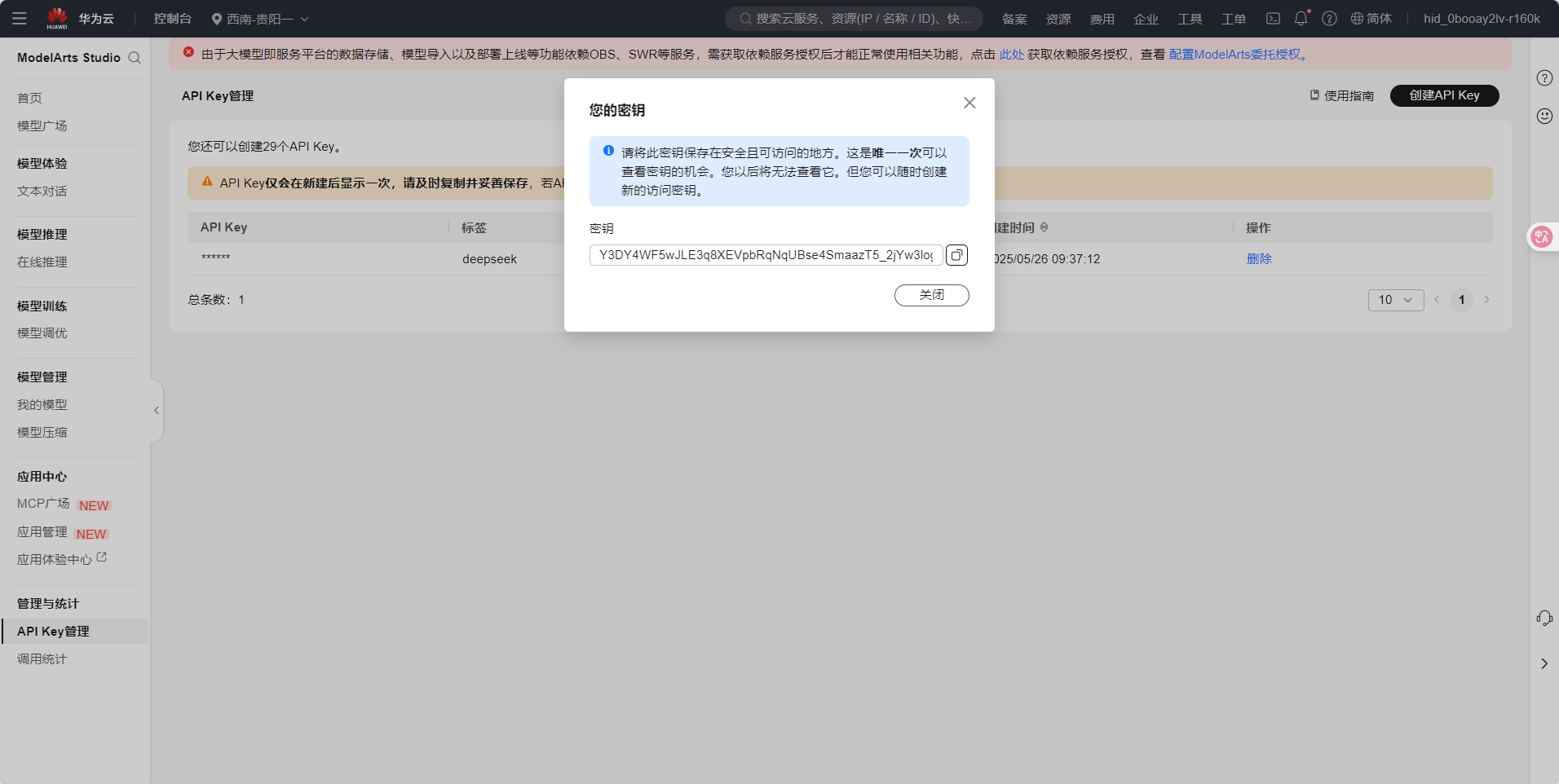
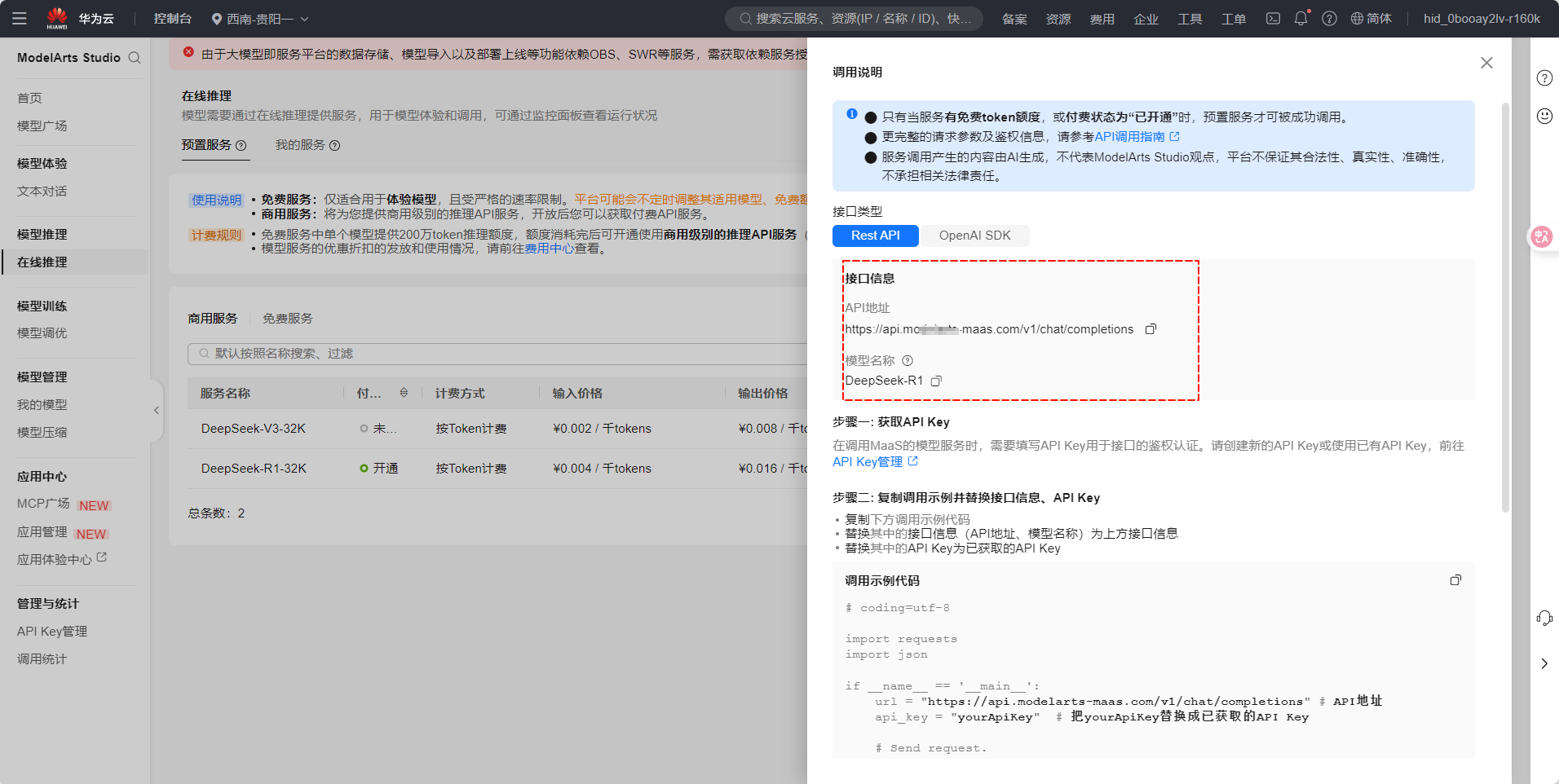
✅ 开通成功! 现在可以开始使用DeepSeek-V3/R1进行推理任务。
3. 方式一:REST API调用
3.1 基础调用示例
# coding=utf-8
import requests
import json
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "" # 替换为你的API Key
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model": "DeepSeek-R1",
"messages": [
{"role": "system", "content": "你是一名AI助手"},
{"role": "user", "content": "用Python实现二分查找"}
],
"temperature": 0.6,
"stream": False # 关闭流式输出
}
response = requests.post(url, headers=headers, json=data)
print(f"状态码: {response.status_code}")
print("响应结果:")
print(json.dumps(response.json(), indent=2, ensure_ascii=False))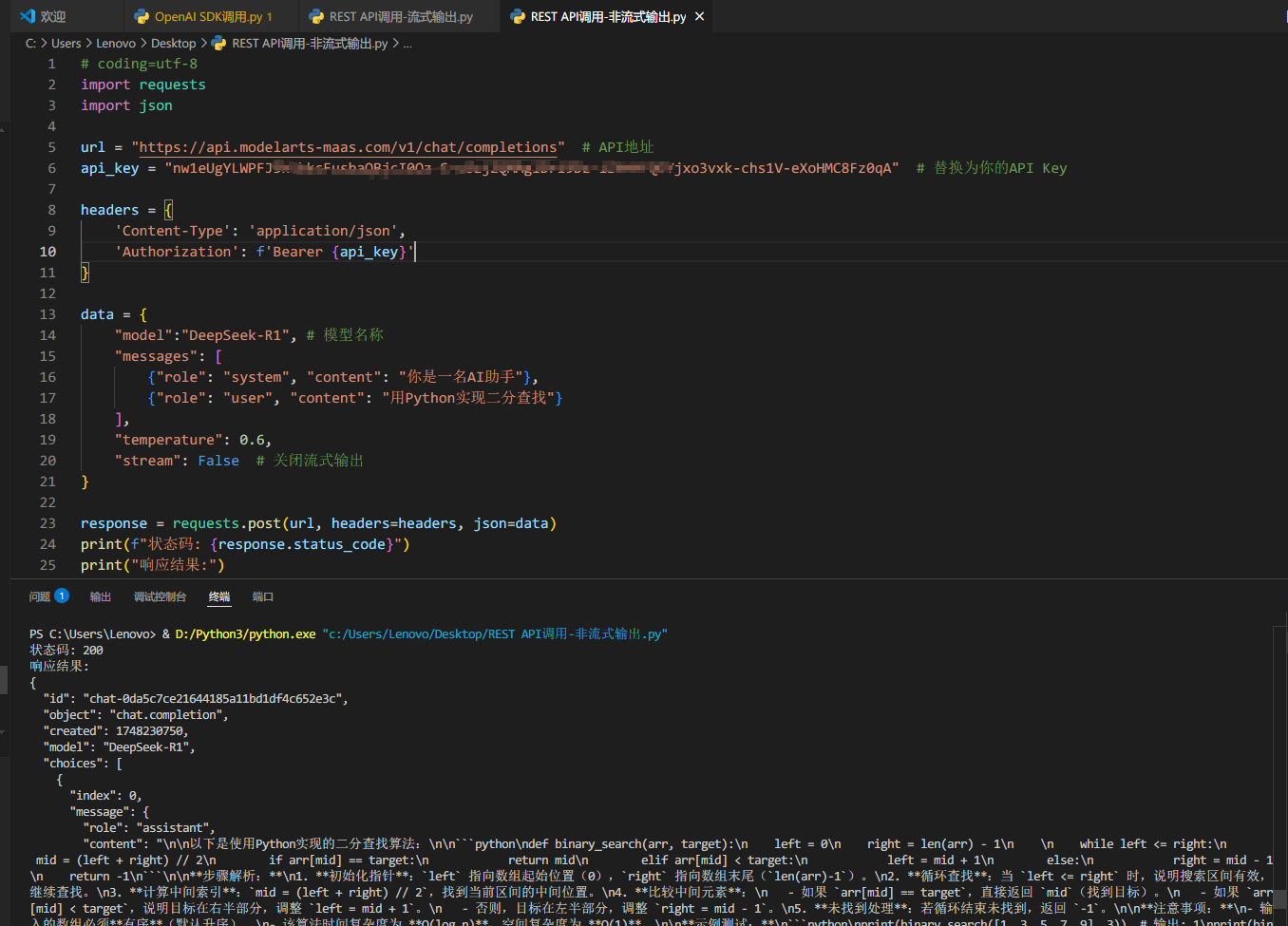
3.2 流式输出模式
# coding=utf-8
import requests
import json
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "" # 替换为你的API Key
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model": "DeepSeek-R1", # 可替换为DeepSeek-R1
"messages": [
{"role": "system", "content": "你是一名AI助手"},
{"role": "user", "content": "用Python实现二分查找"}
],
"temperature": 0.6,
"stream": True
}
try:
with requests.post(url, headers=headers, json=data, stream=True) as response:
response.raise_for_status() # 检查HTTP错误
print(f"状态码: {response.status_code}")
for chunk in response.iter_lines():
if chunk:
decoded = chunk.decode('utf-8').strip()
if decoded.startswith("data:"):
data_str = decoded[5:].strip() # 去掉 "data: " 前缀
if data_str != "[DONE]":
try:
data_obj = json.loads(data_str)
# 检查数据结构是否包含 content
if "choices" in data_obj and len(data_obj["choices"]) > 0:
delta = data_obj["choices"][0].get("delta", {})
content = delta.get("content", "")
if content:
print(content, end="", flush=True)
except json.JSONDecodeError as e:
print(f"JSON解析错误: {e}, 原始数据: {decoded}")
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")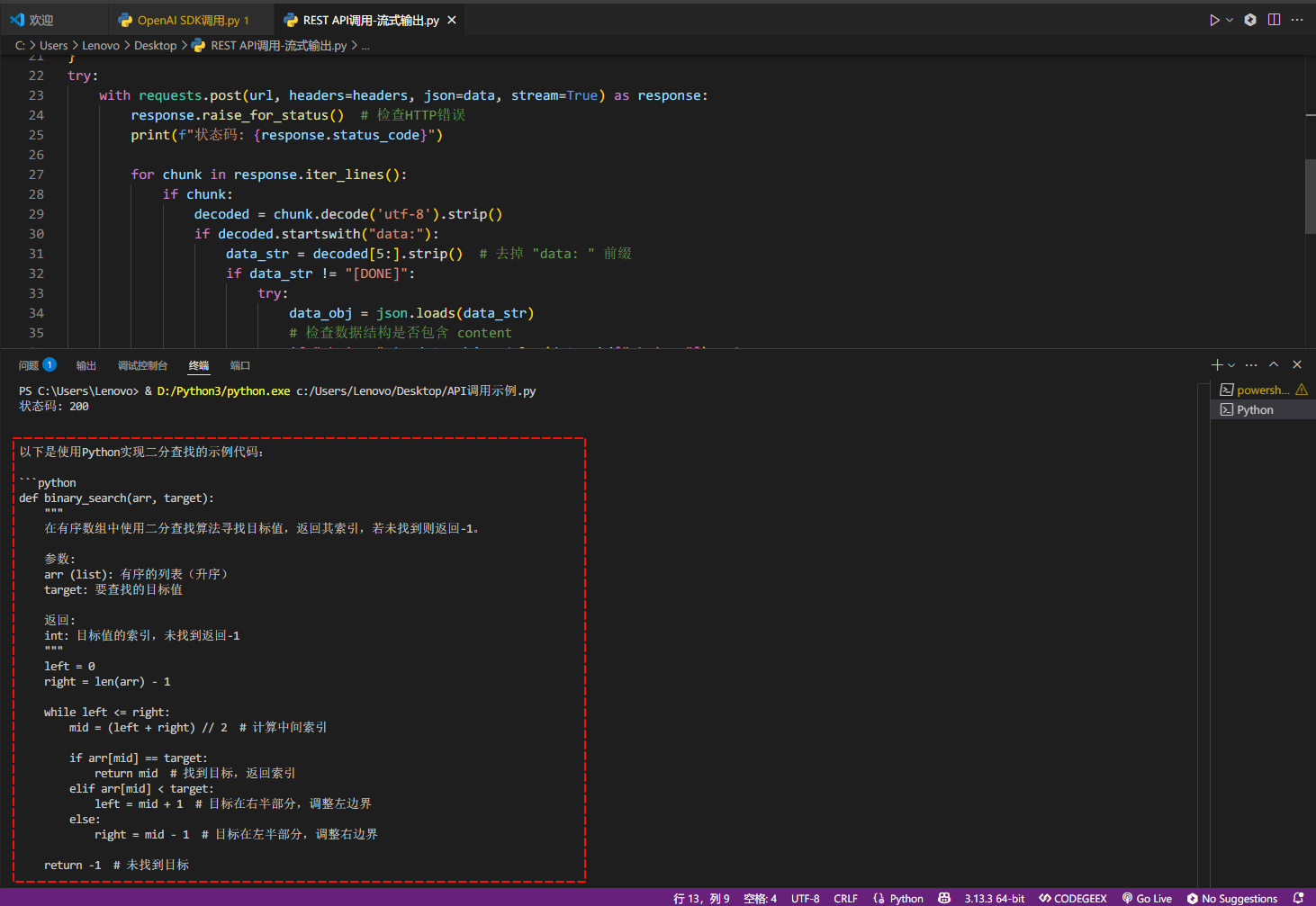
4. 方式二:OpenAI SDK调用
4.1 环境准备
pip install --upgrade "openai>=1.0"4.2 基础调用示例
# coding=utf-8
from openai import OpenAI
client = OpenAI(
base_url="https://api.modelarts-maas.com/v1",
api_key="" # 替换为你的API Key
)
response = client.chat.completions.create(
model="DeepSeek-R1", # 指定模型
messages=[
{"role": "system", "content": "你是一名资深程序员"},
{"role": "user", "content": "解释快速排序算法"}
],
temperature=0.7
)
print(response.choices[0].message.content)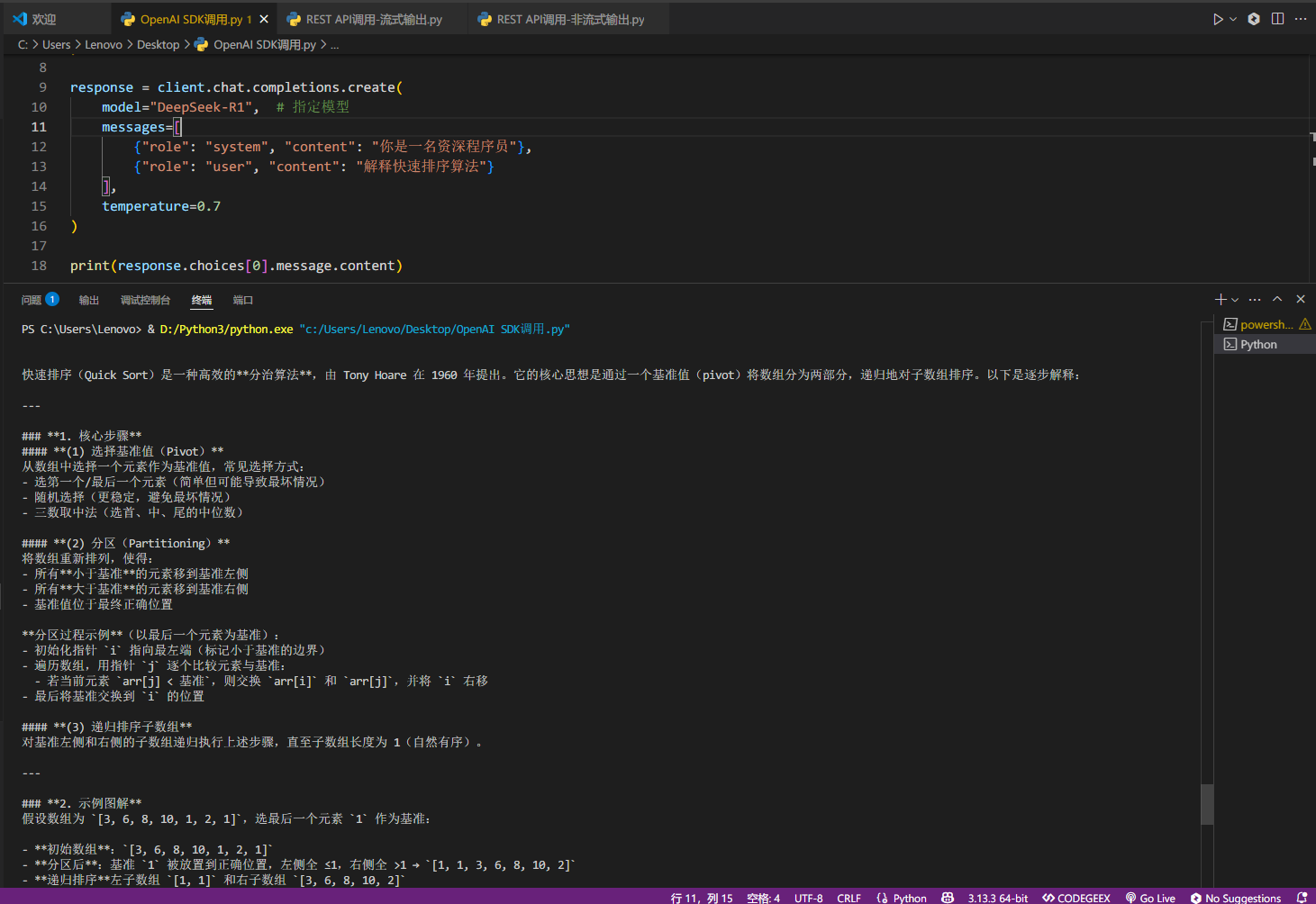
4.3 流式输出模式
from openai import OpenAI
client = OpenAI(
base_url="https://api.modelarts-maas.com/v1",
api_key="" # 替换为你的API Key
)
stream = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role": "user", "content": "用三句话介绍华为云"}],
stream=True
)
for chunk in stream:
if chunk.choices and len(chunk.choices) > 0: # 检查 choices 是否有效
delta = chunk.choices[0].delta
if delta and delta.content: # 检查 delta 和 content 是否存在
print(delta.content, end="", flush=True)
5. 对比评测
|-----------|-----------------|--------------|
| 特性 | REST API | OpenAI SDK |
| 兼容性 | 通用HTTP接口 | 完全兼容OpenAI生态 |
| 流式响应 | 需手动处理chunk数据 | 原生支持stream参数 |
| 代码复杂度 | 需要构造HTTP请求 | 封装完善,调用简洁 |
| 适用场景 | 嵌入式设备、非Python环境 | Python项目快速集成 |
| 额外功能 | 可查看原始响应头 | 自动类型检查 |
6. 使用建议
- 企业级应用:推荐使用REST API,便于统一管理请求日志和监控
- AI原型开发:优先选择OpenAI SDK,可快速迁移其他大模型代码
- 性能敏感场景:流式模式(stream=True)能显著提升用户体验
- 安全注意:API Key需通过环境变量管理,避免硬编码泄露
7. 常见问题
Q1: 如何查看API使用量?
A: 在华为云控制台"费用中心 > 使用量统计"查看调用次数和Token消耗
Q2: 流式输出时如何计算费用?
A: 按实际生成的Token数量计费,与是否流式无关
Q3: 最大支持多少上下文长度?
A: DeepSeek-V3支持32K tokens,R1支持8K tokens
8. 总结
本次体验了华为云 DeepSeek-V3/R1 商用大模型服务,整体流程顺畅,推理能力强大,适用于 智能问答、代码生成、企业知识库 等场景。推荐开发者结合 Dify平台 进行AI应用开发,进一步提升效率。
下一步计划:尝试基于Dify搭建企业知识库,并测试高可用方案,欢迎关注后续评测!
相关资源