SqueezeNet / MobileNet / ShuffleNet / EfficientNet
一、背景与动机
随着深度神经网络在图像识别任务上取得巨大成功,它们的结构越来越深、参数越来越多。然而在移动端或嵌入式设备中:
- 存储资源有限
- 推理计算能力弱
- 能耗受限
因此,研究者提出了多种轻量化 CNN 架构,目标是在保持较高准确率的同时,显著减少模型的参数量与计算开销。
代表性模型包括:
- SqueezeNet:通过 1×1 卷积和模块压缩,极致减少参数
- MobileNet:基于深度可分离卷积,高效解耦空间与通道维度
- ShuffleNet:引入通道重排机制,打破 group convolution 的隔离性
二、SqueezeNet:压缩卷积架构的先驱
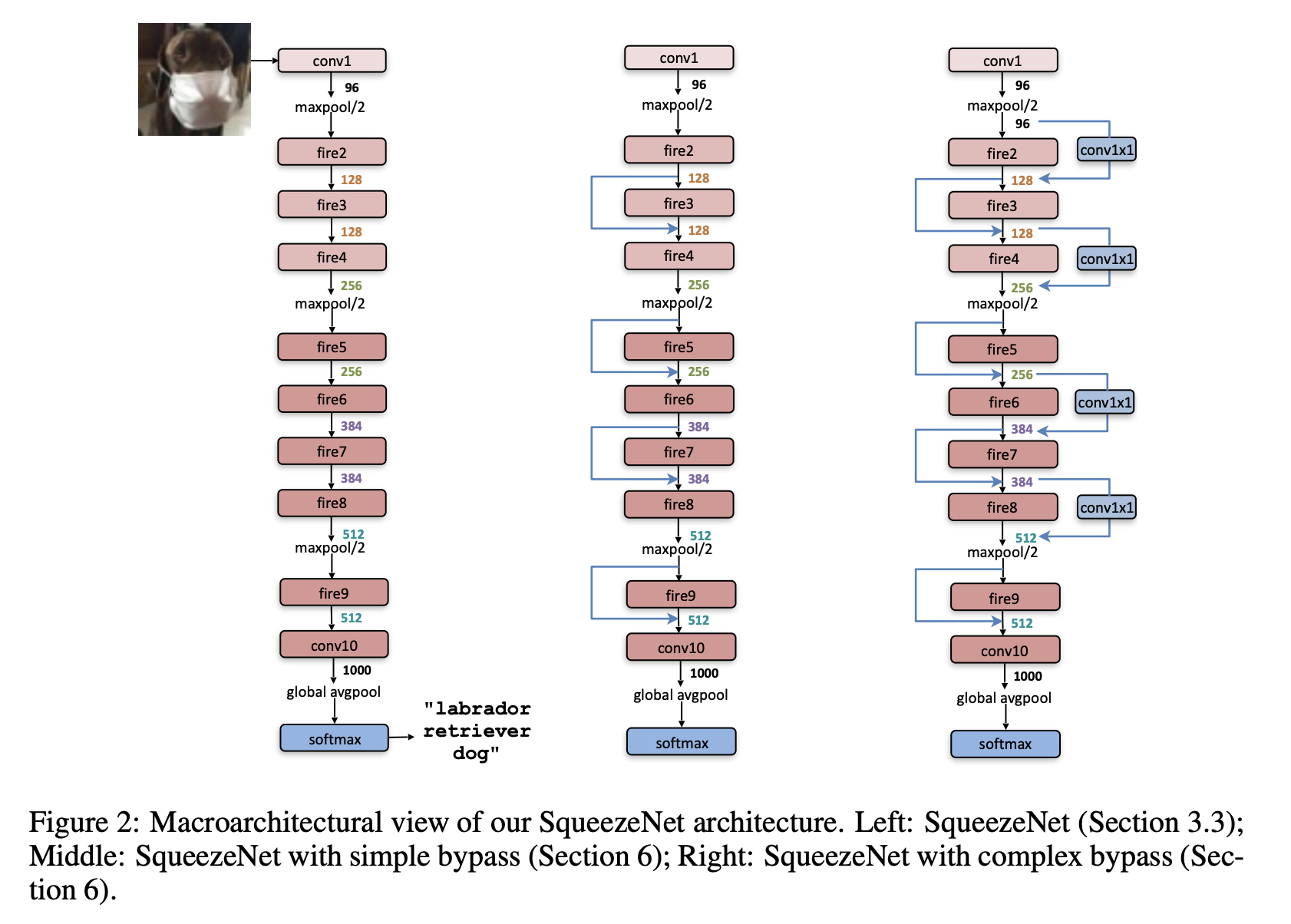
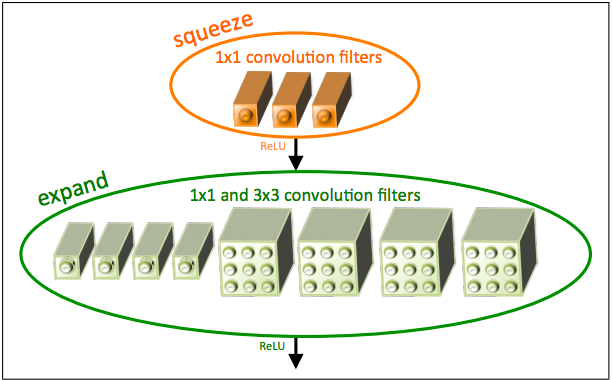
SqueezeNet 的目标是以极小模型参数量达到与 AlexNet 相似的精度。其核心设计是:
- 使用大量 1×1 卷积 代替 3×3 卷积
- 将特征图压缩后再展开,降低计算与参数
- 延迟使用下采样(pooling),保持高分辨率激活图
SqueezeNet 的基础构件是 Fire 模块。
Fire Module 结构
由两个部分组成:
- Squeeze 层:1×1 卷积 → 输出少量通道(如 16)
- Expand 层:同时使用 1×1 卷积 和 3×3 卷积 → 拼接输出(如各输出 64)
结构图如下:
输入 → 1×1 Conv(压缩) →
→ 1×1 Conv + 3×3 Conv(展开) → Concatenate → 输出
例如:
输入通道数为 64,Squeeze 输出 16 个通道,Expand 输出 128 → Fire 模块输出为 128 通道。
1×1 卷积的作用
- 通道压缩:1×1 卷积本质是对每个空间位置的通道向量进行线性组合,可以用来"压缩通道数",降低后续计算量
- 增加非线性:在 ReLU 之后插入更多 1×1 卷积可以增加网络的非线性表达能力
- 参数极少:相比 3×3 卷积,1×1 卷积仅有 1/9 的参数,且无空间维度重叠,计算更快
- 实现跨通道交互:为后续层提供新的特征组合方式
SqueezeNet 大量用 1×1 卷积进行 squeeze → expand 操作,使得参数量大幅减少(仅 1.2M),而准确率仍接近 AlexNet。
三、MobileNet:深度可分离卷积架构
MobileNet 系列由 Google 提出,目标是在手机等设备上部署高效 CNN 模型。
MobileNet 的核心是 Depthwise Separable Convolution(深度可分离卷积),它将标准卷积分解为:
- Depthwise Conv(逐通道卷积):每个通道单独做卷积,不混通道
- Pointwise Conv(1×1 卷积):再用 1×1 卷积将各通道融合
结构为:
输入 → Depthwise 3×3 → Pointwise 1×1 → 输出
相比标准卷积,计算量约减少 8~9 倍。
1×1 卷积在 MobileNet 中的作用
MobileNet 的计算瓶颈几乎全部集中在 1×1 卷积:
- 它承担了通道融合、表达建模的全部任务
- 在 Depthwise Conv 后,通道仍是独立的,1×1 Conv 是关键建模过程
- 通常伴随 BatchNorm + ReLU 使用,形成完整的特征通道变换层
MobileNet 的架构本质上是 "大量 Depthwise + 重度依赖 Pointwise 1×1 Conv"。
在 MobileNet v2 中,1×1 卷积还被用于扩展通道(Expand)与压缩通道(Project)结构中,组成 Inverted Residual Block。
四、ShuffleNet:分组卷积下的通信增强
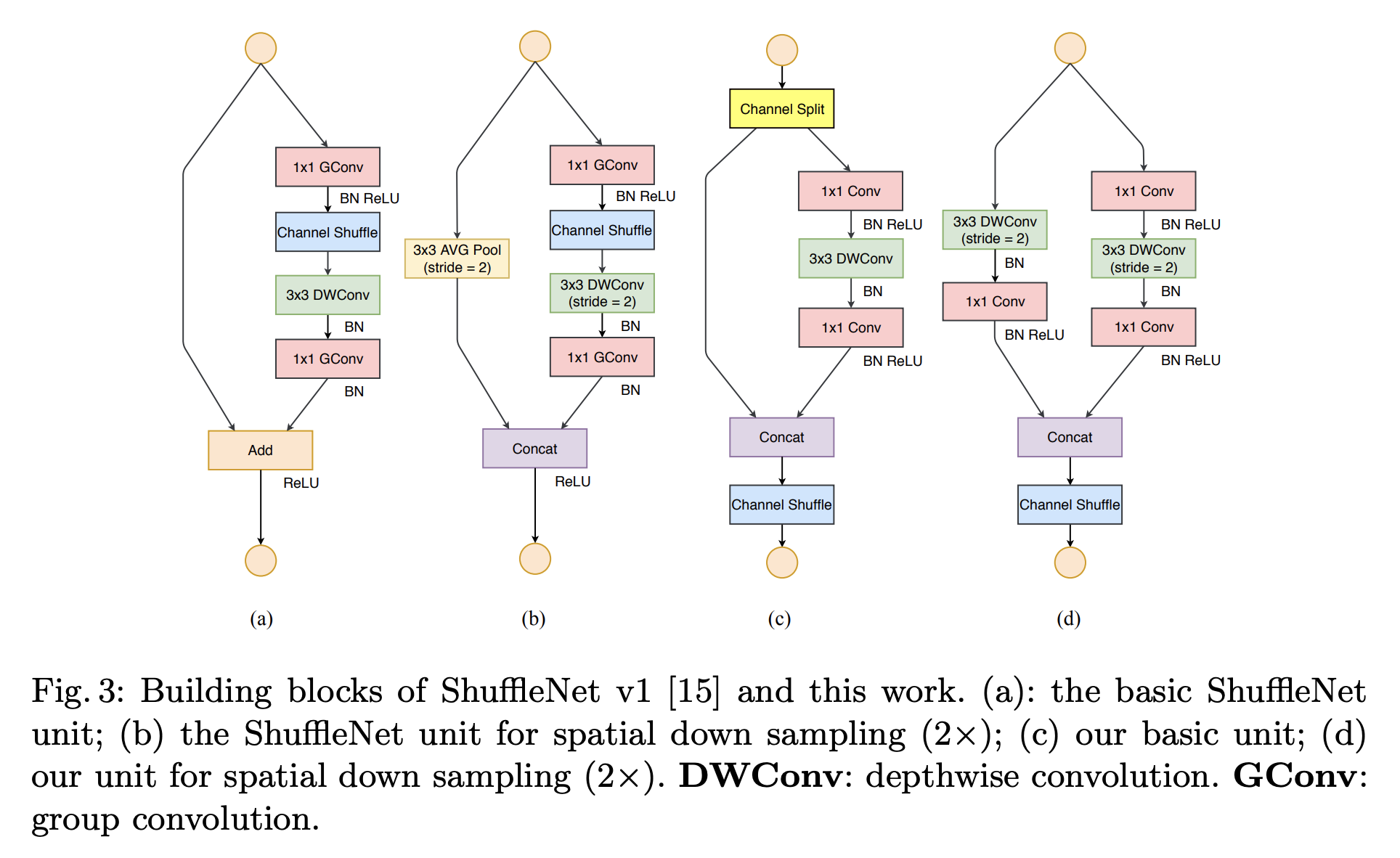
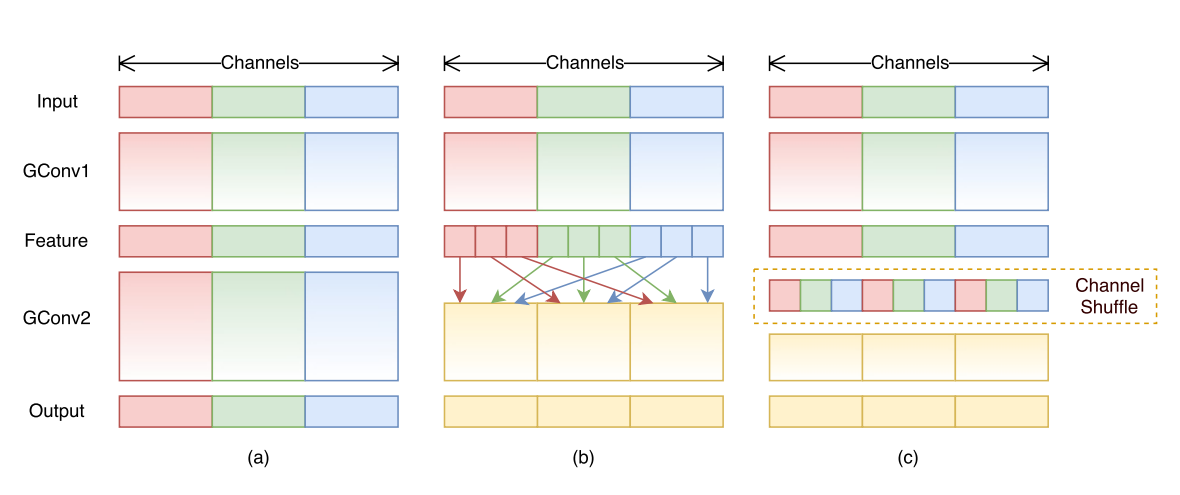
ShuffleNet 进一步提出:
- 组卷积虽然节省参数,但组与组之间信息隔离
- 提出 Channel Shuffle 操作,实现组间信息重组
结构流程如下:
输入 → 1×1 group conv(压缩) → Channel Shuffle
→ Depthwise Conv(下采样) → 1×1 group conv(还原) → Add
其中的关键是 Shuffle 操作,它通过通道维度重排列打破 group 的限制,实现跨组特征融合。
1×1 卷积的作用
在 ShuffleNet 中,1×1 卷积仍是核心:
- 用于 group conv 压缩和还原通道
- 配合 Shuffle 操作,使得 group conv 不再是"隔离死角"
- 在轻量网络中,几乎承担了所有"通道信息建模"工作
ShuffleNet 的主要贡献是优化了 group conv 的使用,使得通道维度之间仍能交流,从而提升准确率。
五、小结
| 模型 | 主要创新点 | 1×1 Conv 作用 |
|---|---|---|
| SqueezeNet | Fire 模块:Squeeze + Expand | 通道压缩与扩展,控制参数量 |
| MobileNet | 深度可分离卷积 | 通道融合 + 特征表达,承担主建模任务 |
| ShuffleNet | Channel Shuffle + Group Conv | 通道重建与跨组通信桥梁,提高 group conv 表达力 |
1×1 卷积在轻量 CNN 中的作用已经从"辅助通道变换"变为信息融合的主力结构,它不仅节省参数,还提供了更高效的通道交互机制。
EfficientNet
一、设计动机
卷积神经网络的性能提升往往伴随着参数与计算量的指数增长。以 ResNet、Inception、DenseNet 为例,为了获得更高精度,往往不断加深网络或加宽网络或增加输入分辨率。然而,这三种扩展维度是彼此耦合的,盲目地加大某一维度可能会导致资源浪费而无法换来性能提升。
EfficientNet 的核心贡献是提出一种复合缩放策略(Compound Scaling) ,以统一原则系统地扩展网络的深度、宽度与分辨率,在有限资源下获得最优性能。
二、Compound Scaling 原理
传统的网络扩展方式:
- 只加深:ResNet-101 → ResNet-152
- 只加宽:Wide-ResNet
- 只提分辨率:Inception-ResNet + 299×299 输入
这些方式各有优劣,但非系统设计。EfficientNet 提出:
给定一个计算资源预算,可以通过一个统一的比例因子 ϕ \phi ϕ 同时扩展网络的深度 d d d、宽度 w w w、输入分辨率 r r r,使得整体计算量受控。
具体公式如下:
d = α ϕ w = β ϕ r = γ ϕ subject to α ⋅ β 2 ⋅ γ 2 ≈ 2 \begin{aligned} d &= \alpha^\phi \\ w &= \beta^\phi \\ r &= \gamma^\phi \\ \text{subject to } \alpha \cdot \beta^2 \cdot \gamma^2 \approx 2 \end{aligned} dwrsubject to α⋅β2⋅γ2≈2=αϕ=βϕ=γϕ
其中, α , β , γ \alpha, \beta, \gamma α,β,γ 是通过网格搜索在基准网络上确定的缩放常数。
这样,当我们设定 ϕ = 1 , 2 , 3... \phi=1, 2, 3... ϕ=1,2,3... 时,网络在三维空间上以协调比例扩展,而不是某一维度暴涨。
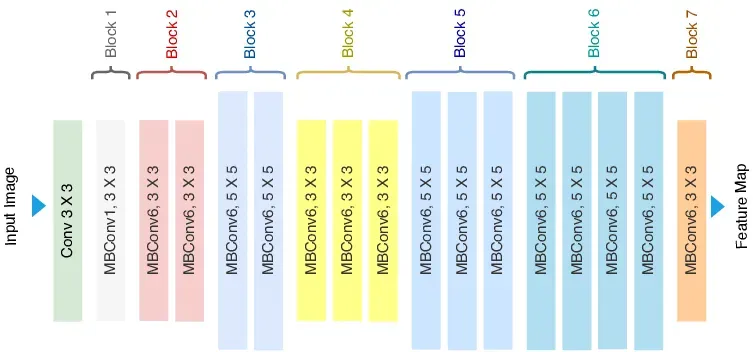
三、EfficientNet-B0 到 B7
EfficientNet-B0 是基准网络,由 NAS(神经架构搜索)发现,结构基于 MobileNetV2 的 MBConv 模块。
然后使用 Compound Scaling 自动扩展,得到 B1 到 B7,不断提高精度和参数量。
| 模型 | Top-1 精度 | 参数量 (M) | FLOPs (B) |
|---|---|---|---|
| ResNet-152 | 77.8% | 60.2 | 11.5 |
| EfficientNet-B0 | 77.1% | 5.3 | 0.39 |
| EfficientNet-B7 | 84.4% | 66 | 37 |
可以看到,EfficientNet 在相同精度下参数量与计算量大幅减少。
四、MBConv 模块(Mobile Inverted Bottleneck Conv)
MBConv 是 EfficientNet 的基本构件,其结构如下:
输入 → 1×1 卷积(Expand)
→ 3×3 Depthwise Conv(空间建模)
→ 1×1 卷积(Project)
→ Add(残差连接)
每一层先用 1×1 卷积扩大通道维度(比如从 16 → 96),经过深度卷积处理空间,再用 1×1 卷积降维(比如 96 → 16)。
这个结构来自 MobileNetV2,但在 EfficientNet 中进一步优化:
- 引入 SE(Squeeze-and-Excitation)注意力模块
- 使用 Swish 激活函数 替代 ReLU
- 更合理的 expansion ratio(如 6)
1×1 卷积的作用
-
通道扩展(Expand)
第一个 1×1 卷积将输入从低维度提升为高维(如 16 → 96),使得后续深度卷积有更强的表达能力。
-
特征压缩(Project)
第二个 1×1 卷积将特征重新压缩为初始维度(如 96 → 16),减少输出特征图大小并匹配残差连接。
-
非线性建模核心
所有的非线性(Swish)都作用在 1×1 卷积之后,这使得 1×1 卷积不仅是线性变换器,更是模型建模能力的关键来源。
EfficientNet 中的 1×1 卷积相比以往模型承担了更重的任务,不再只是调节维度,而是主导整个 MBConv 的信息流与学习能力。
五、EfficientNet 的优势总结
- 系统性扩展:统一调整深度、宽度、分辨率,更科学地利用计算资源
- 高性能:在参数量极少的情况下达到或超越最强大模型
- 适配部署:适合从手机到服务器的全平台部署,兼容 TensorRT、TFLite
- 结构可复用:MBConv 模块广泛应用于后续 EfficientNetV2、MixNet、EdgeTPU 模型中
六、小结
EfficientNet 是高效 CNN 架构设计的一次重大突破,通过 Compound Scaling 策略将架构扩展问题转化为优化问题,同时结合 NAS 设计出的 MBConv 模块,实现了极高的性能与效率统一。
它不仅达到了 SOTA 准确率,也成为轻量化模型设计的典范,并在图像分类、目标检测、语义分割等任务中展现出强大通用性。