
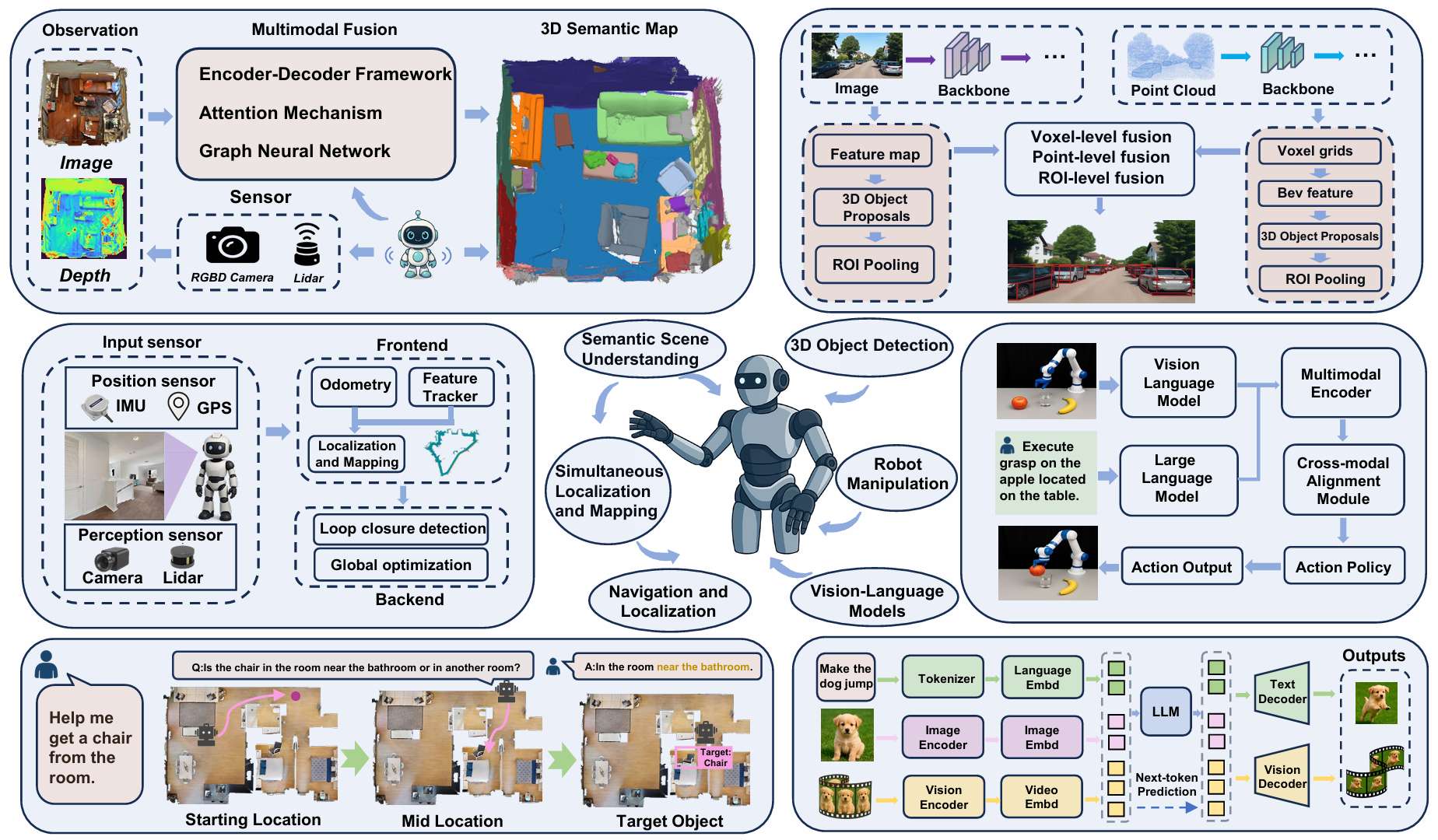
-
作者: Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, Rongtao Xu, Shibiao Xu
-
单位:中科院自动化所多模态人工智能系统国家重点实验室,北京邮电大学人工智能学院,算力互联网与信息安全教育部重点实验室;山东计算机科学中心
-
论文标题:Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
主要贡献
-
系统地整合了传统的多模态融合策略与新兴的视觉语言模型(VLMs),并从架构设计、功能特性及适用任务等方面进行了比较分析,揭示了它们之间的联系、互补优势及融合潜力。
-
与以往主要关注基础任务(如语义分割和目标检测)的综述不同,本文将分析范围扩展到新兴的应用场景,如多模态SLAM、机器人操作和具身导航,展示了多模态融合和VLMs在复杂推理和长期任务决策中的潜力。
-
论文总结了多模态系统相对于单模态方法的关键优势,包括增强的感知鲁棒性、语义表达能力、跨模态对齐和高级推理能力,强调了它们在动态、模糊或部分可观测环境中的实际价值。
-
对当前用于机器人任务的主流多模态数据集进行了深入分析,涵盖了它们的模态组合、覆盖任务、适用场景和局限性,为未来的基准测试和模型评估提供了参考依据。
-
识别了多模态融合中的关键挑战,如跨模态对齐技术、高效训练策略和实时性能优化,并基于这些挑战提出了未来研究方向,以推动该领域的发展。
介绍
研究背景
-
人工智能和机器学习的发展:随着人工智能和机器学习的快速发展,多模态融合和视觉-语言模型(VLMs)已成为推动机器人视觉技术进步的重要工具。
-
单模态方法的局限性:传统的单模态方法(例如仅依赖RGB图像)在处理真实世界环境中的复杂任务时,常常遇到感知限制,如遮挡、光照变化、纹理稀疏和语义信息不足等问题。
-
多模态融合的优势:多模态融合通过整合来自不同传感器输入(例如视觉、语言、深度、激光雷达和触觉数据)的互补信息,增强了机器人视觉系统的感知、推理和决策能力。
-
视觉-语言模型的崛起:视觉-语言模型的迅速崛起进一步推动了多模态融合范式的发展。这些模型不仅具备跨模态对齐和泛化能力,还在零样本理解、指令遵循和视觉问答等任务中展现出强大的潜力。
研究动机
-
从被动感知到主动智能系统:多模态融合和VLMs的应用标志着机器人视觉系统从被动感知向主动智能系统的转变,能够实现语义理解和自然语言交互。
-
实际应用中的挑战:尽管多模态融合和VLMs具有广阔的应用前景,但在实际应用中仍面临一些挑战,如高效地整合异构数据、实时性能和资源效率的要求,以及预训练模型在特定机器人任务中的适应性问题。
研究内容
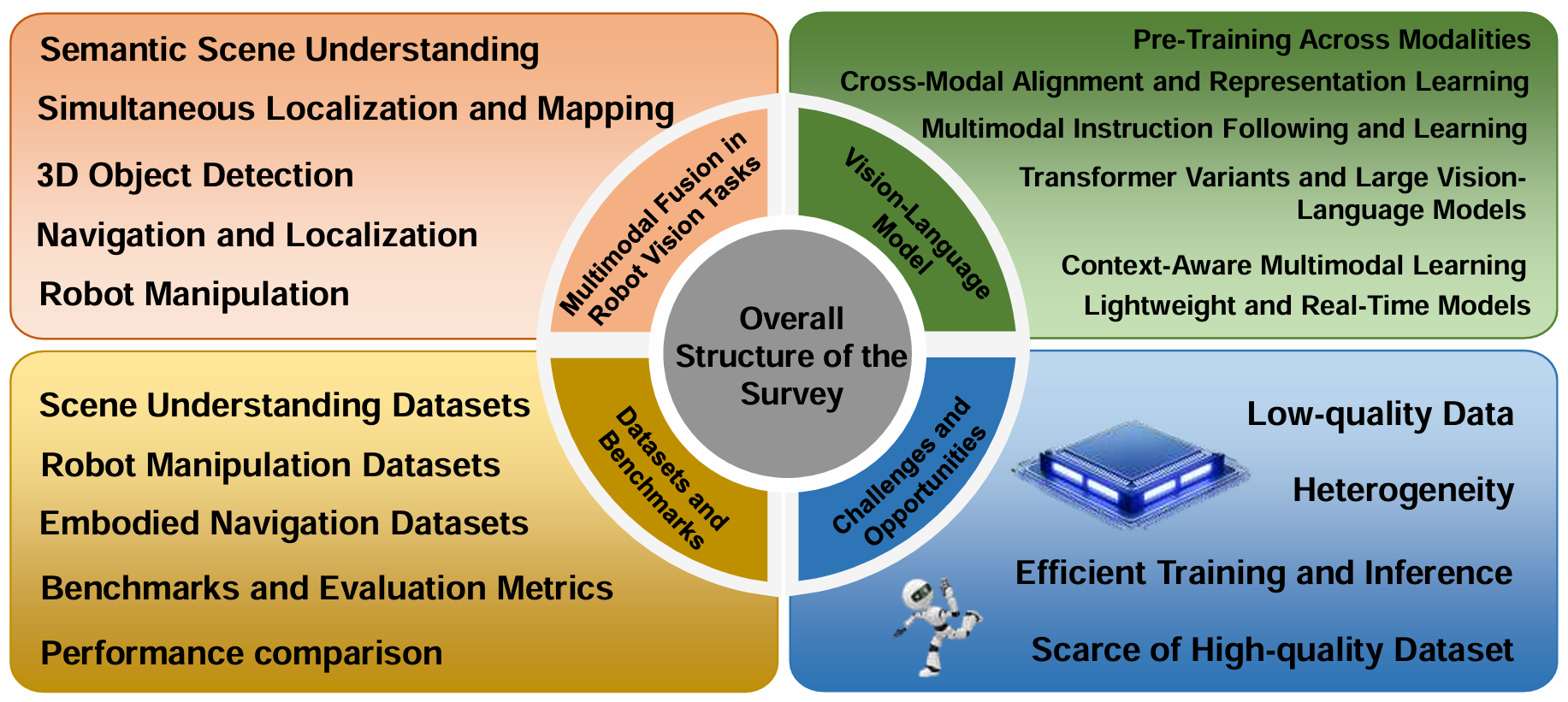
-
多模态融合技术:系统回顾了多模态融合技术在关键机器人视觉任务中的应用,包括语义场景理解、同时定位与建图(SLAM)、3D目标检测、导航与定位以及机器人操作等。
-
视觉-语言模型(VLMs):比较了基于大型语言模型(LLMs)的VLMs与传统多模态融合方法,分析了它们的优势、局限性和协同效应。
-
数据集和基准测试:对常用的多模态数据集进行了深入分析,评估了它们在真实世界机器人场景中的适用性和挑战。
-
关键挑战和未来方向:识别了多模态融合中的关键挑战,如跨模态对齐技术、高效训练策略和实时性能优化,并提出了未来研究方向。
多模态融合与机器人视觉
语义场景理解
背景与挑战
语义场景理解是计算机视觉中的一个核心任务,旨在对图像或视频中的场景进行高级语义分析,包括目标识别、分割和目标间关系建模。传统的单模态方法(例如仅使用RGB图像)在复杂场景中会遇到各种限制,如遮挡、光照变化和多目标歧义性。多模态融合通过结合视觉、语言、深度数据、激光雷达和语音等多种信息源,增强了场景语义理解的能力。
多模态融合策略
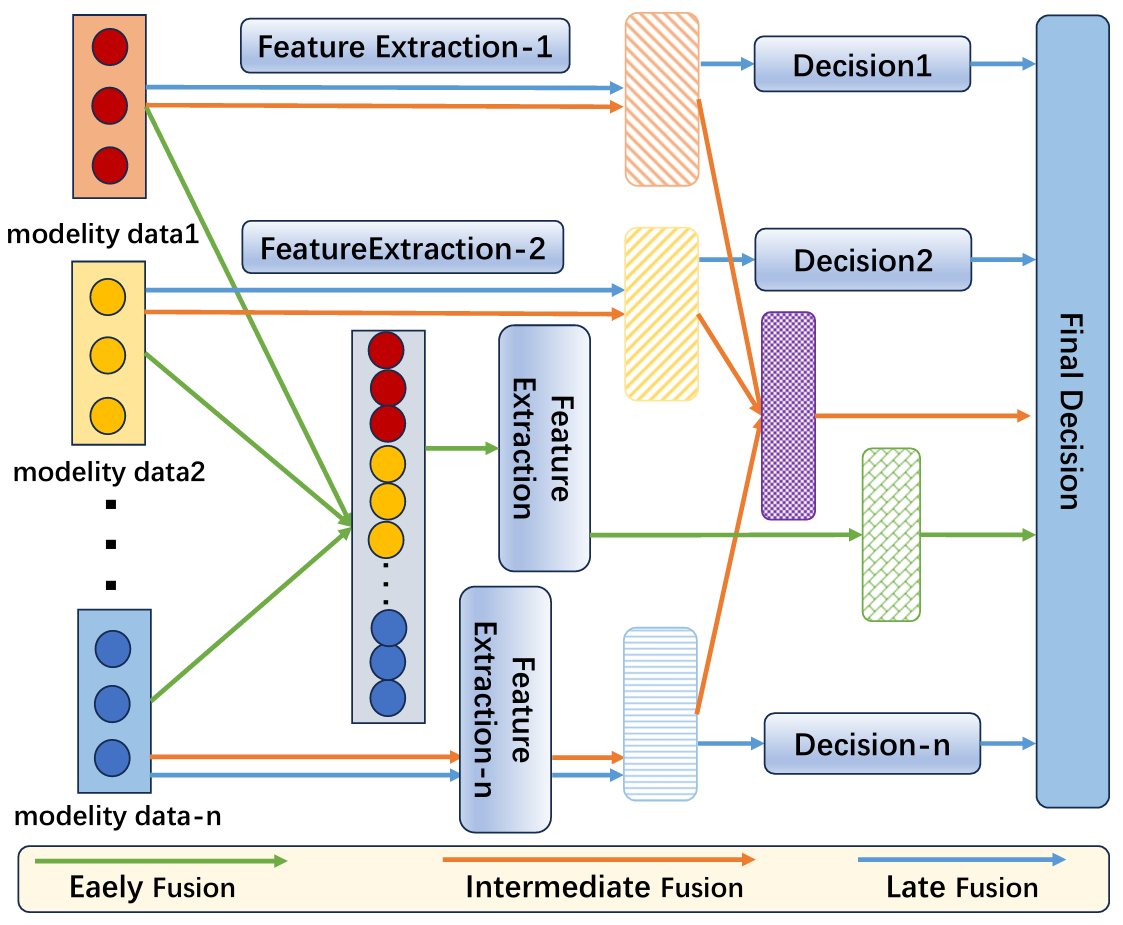
多模态融合策略可以根据融合策略分为早期融合、中期融合和晚期融合。早期融合直接在数据层面整合多模态输入,例如将RGB图像和深度图在输入模型之前进行拼接。中期融合在中间层进行,通过特定机制(如特征拼接或加权)结合模态特征。晚期融合则在每个模态独立完成决策后,通过整合决策结果来实现。
-
早期融合:简单直接,但可能难以处理高维数据。
-
中期融合:通过注意力机制、特征加权或图神经网络(GNN)等方法结合模态特征,具有较高的灵活性和适应性。
-
晚期融合:通过加权平均、投票机制或逻辑规则等方法整合决策结果,具有较强的模态独立性和可扩展性。
具体方法
-
编码器-解码器框架:通过编码器提取不同模态(如图像、文本等)的特征,然后通过解码器融合这些特征以产生最终输出。例如,DeepLabv3+和PointRend等方法利用编码器-解码器框架进行语义分割。
-
注意力机制:通过自适应加权能力有效捕获跨模态特征之间的长距离依赖关系,增强不同模态信息之间的关联性。例如,MRFTrans和DefFusion等方法利用注意力机制进行3D场景补全和语义分割。
-
图神经网络:通过图结构建模多模态数据,提取和融合不同模态的高级语义表示。例如,MISSIONGNN和VQA-GNN等方法利用GNN进行语义推理和视觉问答。
3D目标检测
激光雷达+相机融合
3D目标检测是自动驾驶系统中的一个关键感知任务,旨在通过各种传感器获取环境的三维信息,识别和定位车辆、行人和障碍物等目标。激光雷达和相机的融合是3D目标检测中的主要研究方向之一。
-
何时融合:融合的时机可以分为早期融合(在原始数据阶段)、中期融合(在特征提取后)和晚期融合(在每个模态独立决策后)。
-
融合什么:对于相机输入,常见的数据元素包括特征图、注意力图和伪激光雷达点云;对于激光雷达,典型输入包括原始点云、体素化表示和多视图投影(如鸟瞰图、前视图和后视图)。
-
如何融合:融合技术可以分为基于注意力的融合和非基于注意力的融合。例如,MV3D和AVOD等早期方法是非基于注意力的,而TransFusion和UVTR等近期方法则利用Transformer架构进行基于注意力的融合。
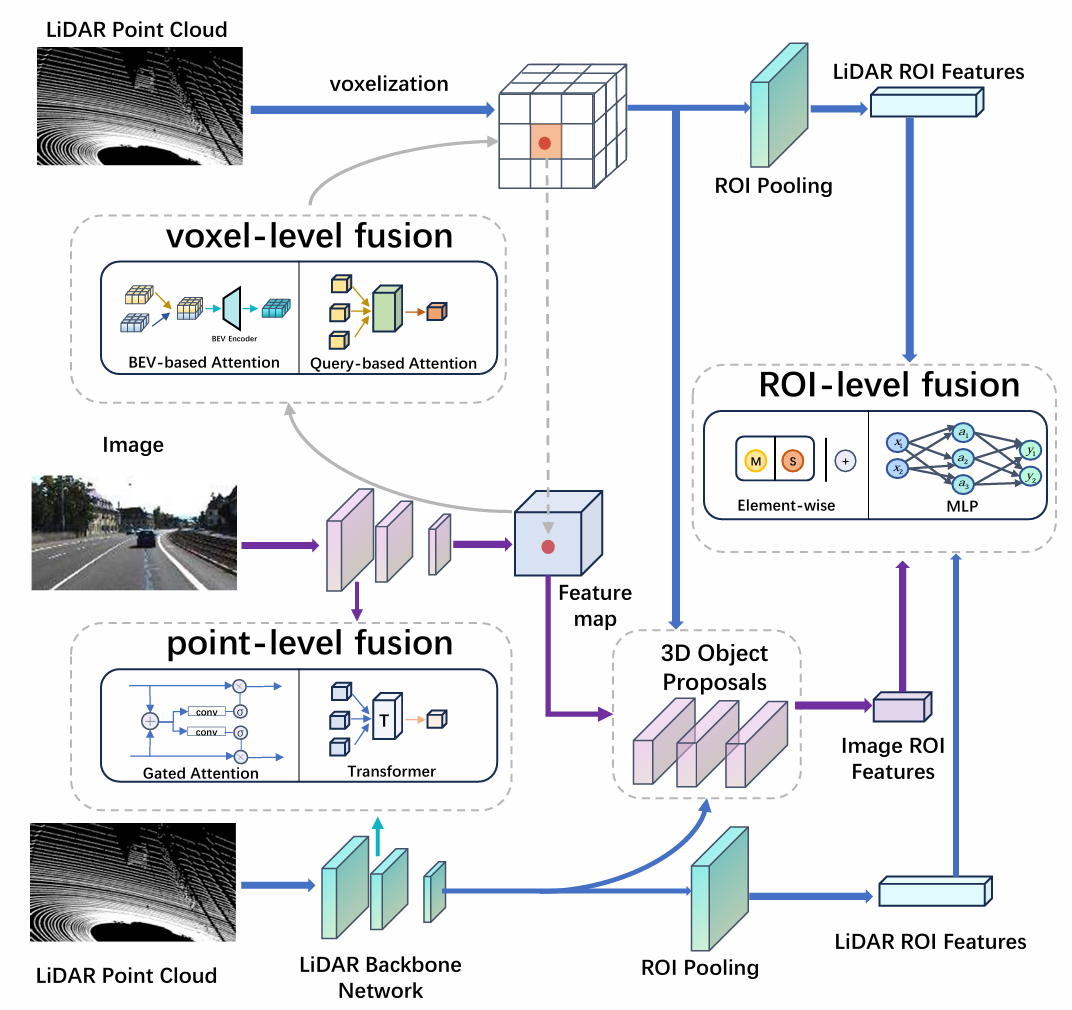
其他传感器融合
除了激光雷达和相机的融合,还有基于雷达和相机、激光雷达和雷达的融合研究。例如,RRPN将雷达检测映射到图像坐标系中,生成快速ROI建议;CenterFusion利用基于staccato的方法关联雷达数据和相机质心,增强3D目标检测的准确性。
导航与定位
具身导航
具身导航依赖于多模态信息(例如视觉、触觉和听觉输入)来指导智能体在动态和非结构化环境中高效行动。具身导航的研究主要集中在目标导向导航、指令遵循导航和对话式导航三个方向。
-
目标导向导航:机器人基于环境中的物体信息自主导航,无需外部指导。
-
指令遵循导航:机器人根据自然语言指令进行导航,需要进行跨模态语义对齐。
-
对话式导航:机器人在导航过程中与用户进行交互,以获取额外的环境信息或澄清模糊指令。
视觉定位
视觉定位在机器人视觉中起着关键作用,使自主智能体能够在复杂和动态的环境中准确确定自己的位置。多模态融合,特别是基于深度学习的方法,显著提高了定位的准确性和鲁棒性。例如,DeepVO和D3VO等模型通过结合卷积和循环神经网络,实现了端到端的自我运动和深度估计。
SLAM
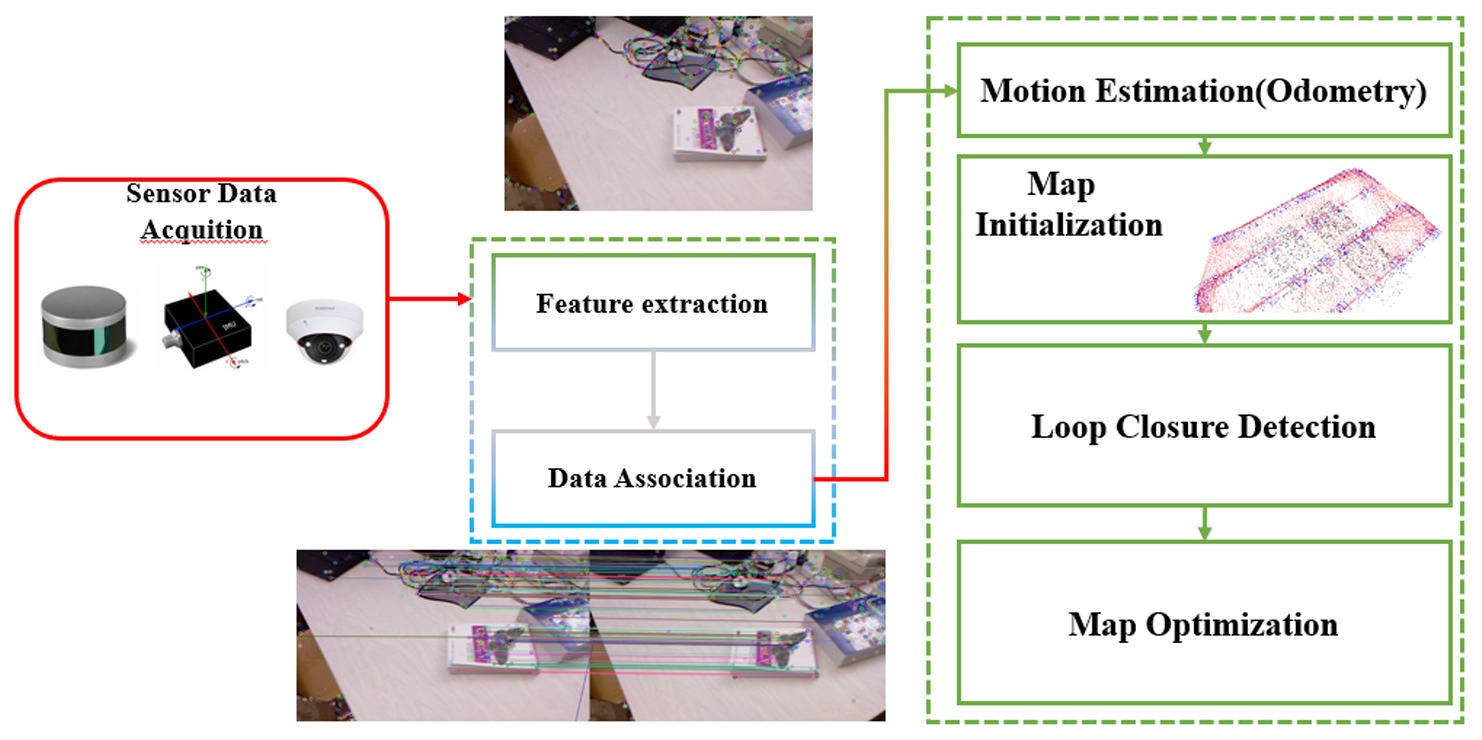
SLAM是机器人视觉中的一个基础任务,使自主智能体能够在探索未知环境的同时准确估计自己的位置。传统的SLAM系统包括基于激光雷达和视觉的方法。多模态融合SLAM通过整合异构传感器数据(如相机、激光雷达、惯性测量单元、GPS和雷达)来增强环境感知能力。
- 多模态SLAM方法:例如VLOAM整合了视觉里程计和激光雷达建图,LIMO进一步整合了惯性测量单元数据,而LIC-Fusion和LIC-Fusion 2.0采用了紧密耦合的优化框架,实现了高精度和实时性能的平衡。
机器人操作
视觉-语言-动作模型
多模态特征融合是机器人操作任务中从感知到行动无缝过渡的核心技术。视觉-语言-动作(VLA)模型通过整合视觉感知、语言理解和动作规划,为复杂操作任务提供了一个高效的框架。
-
RT-2模型:通过预训练对齐视觉和语言表示,使机器人能够从语言输入生成控制命令。
-
RoboMamba模型:将动作动态整合到多模态融合框架中,优化视觉、语言和动作以进行任务规划。
基于触觉的操作
视觉和触觉的多模态融合对于机器人抓取任务的精度和稳定性至关重要。例如,FusionNet-A结合触觉和视觉特征进行分类,提高了目标识别和规划的准确性。
视觉语言模型的技术演变
跨模态预训练
背景与重要性
预训练在多模态融合中起着至关重要的作用。通过在大规模多模态数据上进行预训练,模型能够学习视觉和语言之间的深层关联,显著提升其在不同模态间的信息理解和表示能力。预训练不仅提高了模型在视觉-语言任务(如视觉问答和图像描述)上的性能,还减少了对大量标注数据的依赖,增强了模型在新任务和数据上的泛化能力。
预训练方法
-
跨模态预训练:通过联合训练不同模态的数据(如图像和文本),使模型能够学习模态之间的关联和互补性。这通常通过创建一个共享的嵌入空间实现,其中不同模态的数据被投影到同一空间,模型通过对比学习和自监督学习等方法优化模态间的对齐。
-
自监督学习:利用数据本身生成标签,例如通过图像修复或文本掩码预测等任务,使模型能够学习模态间的有用特征表示。
-
生成模型:通过生成一种模态(如图像)来基于另一种模态(如文本)进行训练,例如使用生成对抗网络(GANs)或变分自编码器(VAEs)。
跨模态对齐与表示学习
背景与挑战
跨模态对齐和表示学习是视觉-语言模型的核心,使不同模态(如视觉、文本、音频)能够在共享嵌入空间中交互。对齐有助于模型映射模态间的关系,例如将图像与文本或音频对齐。然而,由于模态在结构、表示和数据特征上的差异,对齐面临挑战,如图像的高维性与文本的离散符号性之间的差异,以及大规模未标注数据中的尺度差异和噪声。
方法
-
对比学习:通过最小化正样本(同一类别)之间的距离并最大化负样本(不同类别)之间的距离来优化模态间的对齐。例如,CLIP和ALIGN等模型通过对比学习将视觉和语言数据对齐到共享空间。
-
自监督学习:通过设计任务(如图像修复或文本掩码预测)使模型能够从数据本身学习表示,无需大量手动标注数据。例如,DINO是一种基于对比学习的自监督方法,通过最大化图像及其变换版本之间的相似性来学习视觉表示。
-
生成模型:通过生成一种模态(如图像)来基于另一种模态(如文本)进行训练,例如T2F(文本到面部)使用GANs将文本描述转换为面部图像。
Transformer与视觉语言大模型
Transformer架构
自2017年引入以来,Transformer架构已成为深度学习的核心,尤其在自然语言处理(NLP)、计算机视觉(CV)和多模态学习中取得了重大进展。其关键创新是自注意力机制,能够高效地建模长距离依赖关系,并通过并行计算提高训练速度。
Transformer在视觉语言任务中的应用
-
自然语言处理:BERT和GPT等模型展示了Transformer在自然语言理解(NLU)和自然语言生成(NLG)中的优势。随着计算能力的提升,Transformer模型不断扩展,如GPT-2和GPT-3,展示了零样本和少样本学习的能力。
-
计算机视觉:Vision Transformer(ViT)证明了Transformer架构可以直接应用于图像分类任务,并在大规模数据集上取得了优于卷积神经网络(CNNs)的性能。Swin Transformer通过引入移位窗口注意力机制,显著提高了在密集预测任务(如目标检测和语义分割)中的性能。
视觉语言大模型

-
预训练方法:通过大规模图像-文本对的联合训练,VLMs能够学习视觉和语言之间的深层关系,提高模型在跨模态任务中的性能。例如,Flamingo和PaLM-E等模型通过预训练展示了在图像描述、视觉问答和指令遵循等任务中的强大能力。
-
模型架构:VLMs通常结合了编码器-解码器结构,其中编码器处理输入模态(如图像和文本),解码器生成输出模态(如文本描述或动作指令)。例如,LLaVA通过指令调整(instruction tuning)提高了模型在不同任务中的灵活性和适应性。
-
计算效率:为了提高计算效率,研究人员引入了高效的Transformer变体,如Reformer、Longformer和Linformer,以及基于混合专家(MoE)架构的模型,如Switch Transformer和GLaM,以优化资源使用并提高模型的泛化能力。
多模态指令遵循和学习
指令调整
指令调整是提高大规模预训练模型泛化能力的关键技术。其核心思想是通过明确的任务指令引导模型学习不同的任务模式,从而实现跨任务的高效迁移和泛化。在多模态任务中,指令调整通常涉及以下步骤:
-
指令数据集构建:构建包含多样化任务指令的数据集,帮助模型学习如何理解和执行不同的任务指令。
-
监督微调:利用构建的指令数据集对预训练模型进行微调,以提高模型在特定任务上的性能。
-
基于人类反馈的强化学习:通过收集人类偏好数据,训练奖励模型,并利用强化学习优化语言模型,使其更好地适应人类意图。
-
多模态适应:将指令调整扩展到涉及多种模态(如图像、文本、音频和视频)的任务中,使模型能够根据自然语言指令动态调整其行为。
应用示例
-
图像描述:模型根据任务需求调整风格和细节,例如BLIP-2在医学成像和社交媒体描述中的应用。
-
视觉问答(VQA):模型提供准确的回答,例如GPT-4V在不同领域的应用,以及LLaVA在详细回答中的表现。
-
视觉推理:模型通过图像内容推断关系,例如PaLM-E在物理世界任务中的应用,以及DeepMind的Flamingo在因果推理中的表现。
上下文感知多模态学习
背景与方法
上下文感知建模是多模态学习中的一个前沿方向,旨在通过整合不同模态的数据来增强模型的表示能力和预测准确性。其核心思想是在训练过程中包含上下文信息,使模型能够更好地理解数据点之间的关系及其底层上下文。上下文感知建模通常包括以下步骤:
-
特征提取:从输入数据中提取特征。
-
上下文信息定义与整合:设计动态权重调整机制,以适应上下文的变化。
-
决策制定:基于上下文信息做出决策。
挑战与解决方案
上下文感知建模面临的挑战包括处理动态变化的上下文、平衡不同模态数据的重要性以及防止过拟合。解决方案包括使用自适应模型架构、引入注意力机制以及利用迁移学习等技术来增强模型的鲁棒性和泛化能力。
轻量化和实时模型
背景与需求
随着物联网和无线网络的发展,边缘设备和数据量呈爆炸式增长。传统的云计算模型在处理边缘生成的数据时面临实时性差、带宽限制、能耗高和数据安全问题。因此,边缘计算应运而生,直接在网络边缘处理数据,满足下游云数据和上游物联网数据的处理需求。
方法与应用
-
轻量化视觉模型:EfficientNet通过提出一种新的CNN深度、宽度和分辨率的缩放方法,实现了更少的参数和操作,同时保持了高性能。
-
轻量化自然语言处理模型:TinyBERT通过知识蒸馏减少Transformer模型的大小,使其更适合移动设备部署。
-
边缘计算应用:例如,Zhang等人提出的云边协同系统用于建模驾驶行为,Lu等人提出的CLONE框架用于跨边缘设备的协作学习,以及Zhang等人提出的非侵入式家电状态检测系统。
多模态融合数据集和基准测试
场景理解数据集
数据集概述
多模态数据集在语义场景理解领域中起着关键作用。这些数据集涵盖了从室内环境到城市街道的各种场景类型,并整合了RGB图像、深度信息、激光雷达、雷达和音频等多种模态数据。这些数据集为多任务学习和跨领域研究提供了重要支持。
代表性数据集
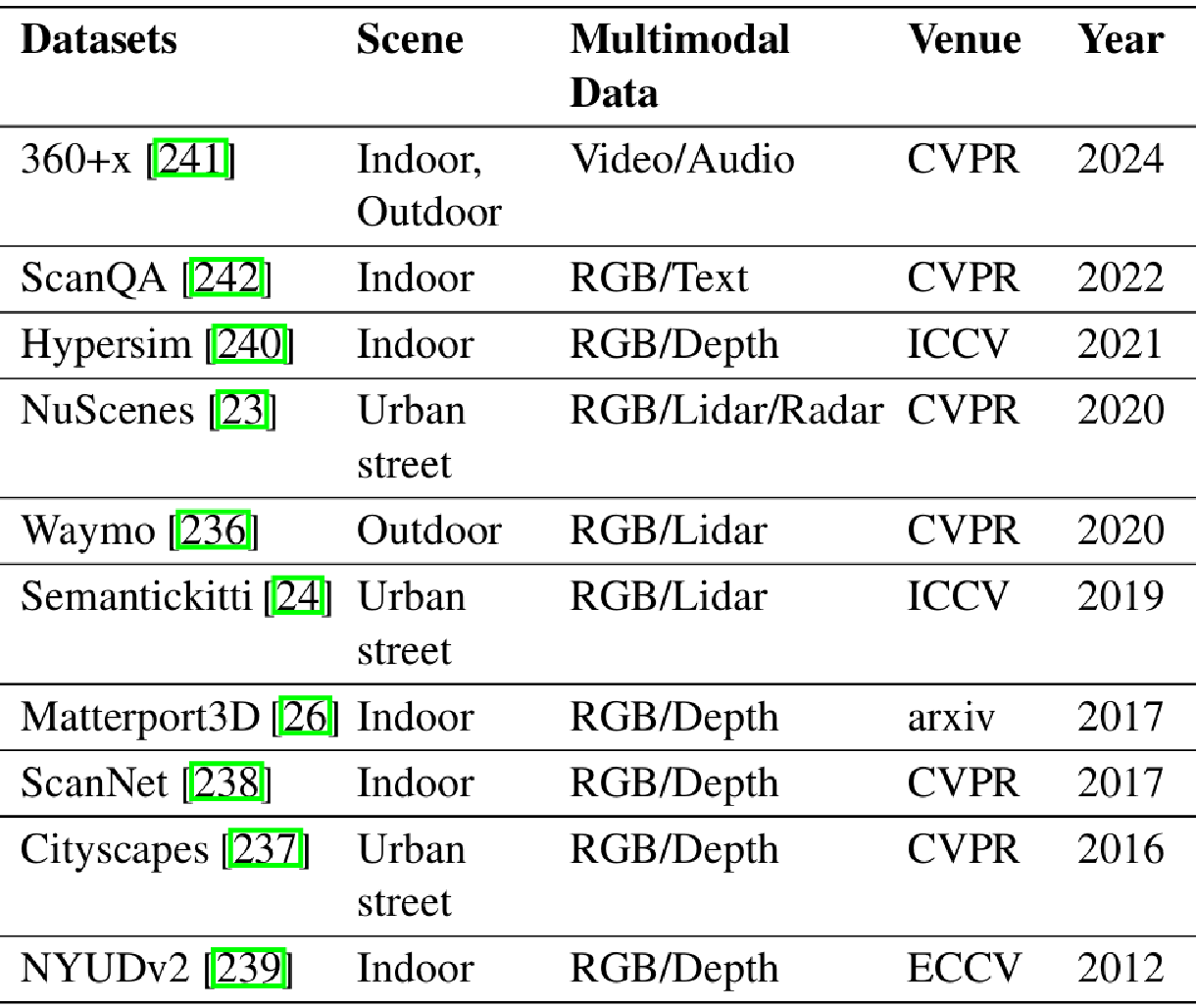
下面列出了近年来广泛使用的代表性多模态语义场景理解数据集。这些数据集不仅涵盖了从室内到室外的各种场景,还整合了多种模态数据,如RGB图像、深度信息、激光雷达、雷达和音频等。以下是一些关键数据集的介绍:
-
nuScenes:包含来自6个摄像头、5个雷达和1个激光雷达的数据,覆盖360°视图,支持23个类别的3D检测和跟踪任务。
-
Waymo Open Dataset:在地理覆盖范围和数据规模方面处于领先地位,包含1200万个3D边界框标注,支持跨领域泛化和多模态传感器融合研究。
-
SemanticKITTI:专注于激光雷达点云的语义分割,为序列级语义场景补全提供了重要基准。
-
Cityscapes:以其高分辨率像素级标注和复杂的城市街道场景数据而成为城市语义理解的关键资源。
-
Matterport3D:提供了10,800个全景RGB-D视图,以及准确的3D重建和语义标注,适用于语义分割、3D重建和多任务学习。
-
ScanNet:通过250万RGB-D帧和众包标注,为语义分割和3D建模提供了大规模、高质量的数据集。
-
NYU Depth V2:作为最早的RGB-D数据集之一,提供了1,449张图像,涵盖464个多样化的室内场景,包含详细的语义分割和对象关系标注。
-
Hypersim:利用高保真合成技术生成77,400个室内场景图像,包含详细的像素级标注、光照分解和表面法线,是Sim-to-Real迁移研究的重要工具。
-
360+x:结合了360°全景视图、第一人称和第三人称视角,并整合了音频和文本描述等多种模态,为多视图场景理解和多模态融合研究提供了丰富的实验基础。
-
ScanQA:将自然语言问答与3D场景理解相结合,通过问答任务探索语言引导的对象定位和场景推理。
机器人操作数据集
数据集概述
多模态设计在机器人数据集中变得越来越重要,不同的数据集整合了视觉、语言、深度和触觉等多种模态信息,每个数据集都有其独特的特点和应用价值。下表总结了用于机器人操作任务的代表性多模态数据集,这些数据集不仅为训练提供了资源,还形成了性能基准的基础。
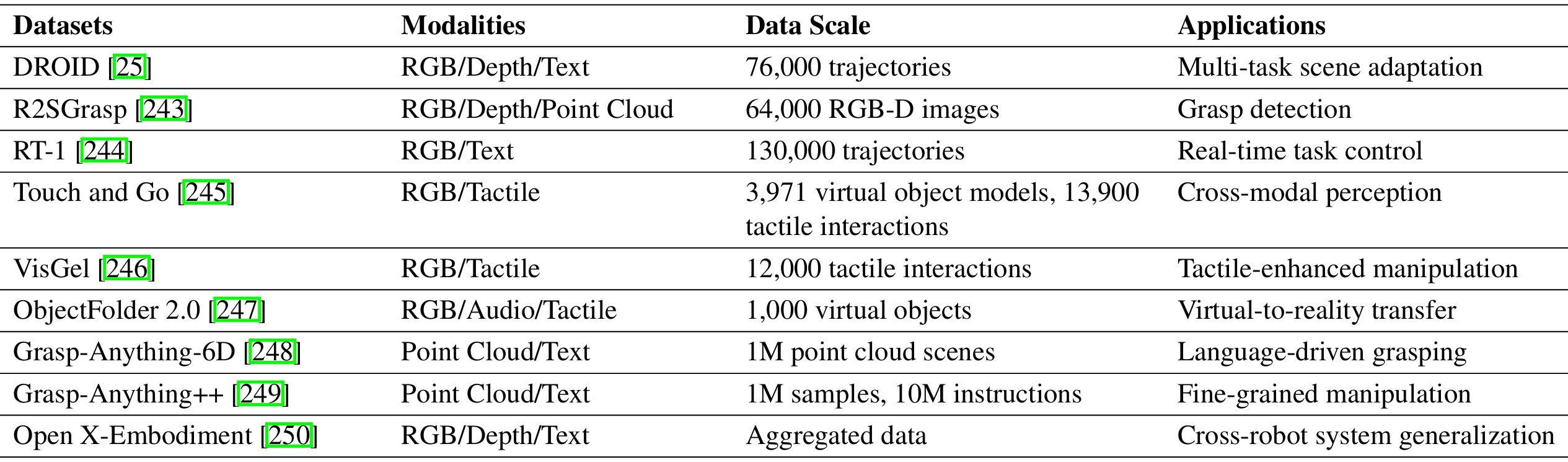
代表性数据集
-
DROID:包含564个场景和86个任务,结合多视图相机流和语言标注,增强机器人对复杂场景的适应性。
-
R2SGrasp:利用"Real-to-Sim"框架最小化模拟和现实之间的领域差距,在6自由度抓取检测方面表现出色。
-
RT-1:采用Transformer架构,实现高效的实时控制,适用于多任务学习。
-
Touch and Go:收集了真实环境中的视觉和触觉数据对,并利用自监督学习方法探索跨模态关系。
-
VisGel:利用GelSight传感器构建触觉和视觉模态之间的双向生成任务,验证了模态间信息转换的可行性。
-
ObjectFolder 2.0:通过高质量的虚拟对象数据和隐式神经表示技术,实现视觉、听觉和触觉模态的高效渲染,支持Sim-to-Real迁移学习任务。
-
Grasp-Anything-6D:结合点云和语言模态,采用创新的负提示策略优化6自由度抓取检测的准确性。
-
**Grasp-Anything++**:进一步扩展到细粒度抓取任务,支持基于语言的局部抓取,例如操纵对象的特定部分。
-
Open X-Embodiment:采用更广泛的任务不可知视角,整合来自21个机构的多样化机器人形式和环境数据,强调多机器人系统的泛化和迁移能力。
具身导航数据集
数据集概述
具身导航数据集在推进智能体导航和交互能力的研究中发挥着关键作用。这些数据集的设计特点突出了它们在场景类型、模态设计、任务目标和应用场景方面的多样性和进步性。
代表性数据集
-
Matterport3D:提供了90个建筑规模的室内场景、10,800个全景视图和194,400个RGB-D图像,包含2D和3D语义标注,支持场景分类、语义分割和闭环检测等任务。
-
**Room-to-Room (R2R)**:首次整合了自然语言模态,引入了视觉和语言导航(VLN)任务,提供了21,567个众包导航指令,配对全景RGB-D数据,使智能体能够根据语言指令完成路径导航。
-
REVERIE:在Matterport3D的基础上增加了目标对象的边界框标注和自然语言指令,引入了远程具身视觉指代表达(REVERIE)任务,要求智能体在导航环境中定位目标对象。
-
CVDN:进一步扩展了导航任务设计,引入了对话模态,引入了视觉和对话导航任务,提供了2,050个人类对话,模拟智能体在导航过程中通过自然语言交互请求帮助的场景。
-
SOON:强调粗到细的目标导向导航任务,包含4,000个自然语言指令和40,000个轨迹,捕捉丰富的场景描述,包括对象属性、空间关系和上下文信息。
-
R3ED:专注于真实世界数据,提供了5,800个点云和22,400个对象标注,使用Intel RealSense D455传感器收集,支持主动视觉学习任务,如最佳视图规划和3D目标检测。
性能评估
评估指标
为了严格评估多模态融合方法和视觉-语言模型(VLMs)在机器人视觉系统中的性能,定义了一系列关键评估指标,这些指标涵盖了语义理解、3D目标检测、定位和导航等多个方面。这些指标为不同模型和模态设置之间的公平和标准化比较提供了基础。
-
语义理解:包括交并比(IoU)、平均交并比(mIoU)、像素准确率(PA)、精确率、召回率和F1分数等。
-
3D目标检测:包括平均精度(AP)、平均平均精度(mAP)和nuScenes检测分数(NDS)。
-
定位和建图:包括绝对轨迹误差(ATE)和相对姿态误差(RPE)。
-
导航和指令遵循:包括成功率(SR)、目标进度(GP)和按路径长度加权的成功率(SPL)。
性能比较
-
3D目标检测:在nuScenes基准测试中,不同3D目标检测方法在不同传感器融合策略下的性能表现。这些方法包括仅激光雷达(L)、仅相机(C)和相机-激光雷达融合(C+L)设置,主要评估指标包括mAP、mATE、mASE等。
-
导航任务:在Room-to-Room(R2R)基准测试中不同导航方法的性能,主要评估指标包括轨迹长度(TL)、导航误差(NE)、Oracle成功率(OSR)、成功率(SR)和按路径长度加权的成功率(SPL)。
-
3D问答和场景理解:在ScanQA验证集上不同视觉-语言模型(VLMs)的性能比较,主要评估指标包括CIDEr、BLEU-4、METEOR和ROUGE分数。
-
机器人操作基准测试:机器人操作基准测试的比较,涵盖了模拟平台、任务多样性、真实世界可复现性等方面。
机器人操作基准测试比较
上表提供了机器人操作基准测试的详细比较,涵盖了模拟平台、任务多样性、真实世界可复现性等方面。这些基准测试为评估机器人在不同任务中的执行能力、泛化能力和适应能力提供了系统化的方法。
-
RLBench:包含100多个任务,涵盖从基本物体抓取到复杂工具使用和装配任务,适合强化学习(RL)、模仿学习(IL)和传统控制方法。
-
GemBench:专注于任务泛化,引入零样本任务设置和视觉-语言扩展,评估机器人在未见任务和物体上的表现。
-
VLMbench:强调语言条件下的机器人操作,通过组合任务生成,要求机器人进行推理和泛化。
-
KitchenShift:模拟厨房环境,引入环境领域的偏移,评估机器人在不同环境变化下的策略鲁棒性。
-
CALVIN:包含34个任务,强调长期规划和多任务适应性,适合多任务RL和模仿学习。
-
COLOSSEUM:支持真实世界可复现性,引入环境扰动,评估机器人在不同物理条件下的鲁棒性和多任务学习性能。
-
GenSim2:支持真实世界部署,利用MuJoCo和Isaac Sim支持可变任务配置,专注于大规模数据生成和Sim-to-Real迁移。
-
VIMA:基于Ravens,是一个多模态操作基准测试,评估机器人在多模态输入(视觉、语言和物理约束)下的性能。
小结
数据集的重要性
多模态数据集在推动机器人视觉技术的发展中起到了基础性的作用。这些数据集不仅为模型训练提供了丰富的资源,还为性能评估和优化提供了重要的参考。通过整合多种模态的数据(如RGB图像、深度信息、激光雷达、雷达、音频和文本),这些数据集支持了从单任务到多任务学习的多样化研究。
挑战与机遇
尽管现有的多模态数据集在规模和多样性上取得了显著进展,但仍面临一些挑战:
-
数据质量:高质量的标注数据对于模型的训练和泛化至关重要,但标注成本高昂且容易出错。
-
数据多样性:现有的数据集在场景类型、任务类型和模态组合上仍存在局限性,难以覆盖所有可能的应用场景。
-
真实世界适应性:许多数据集主要基于模拟环境生成,缺乏真实世界的数据,限制了模型在实际应用中的表现。
未来的研究需要在以下几个方向上取得突破:
-
高质量数据集的构建:通过自监督学习、合成数据生成和特定领域数据集构建,提高数据集的规模、多样性和质量。
-
数据集的标准化和规范化:建立统一的数据集格式和评估指标,便于不同研究之间的比较和交流。
-
真实世界数据的收集和标注:通过众包、自动化标注工具和仿真技术,降低数据收集和标注的成本,提高数据的真实性和可靠性。
数据集和基准测试的未来方向
自监督学习和合成数据
-
自监督学习:通过设计无监督或弱监督的任务,如图像修复、文本掩码预测等,使模型能够从数据本身学习有用的特征表示,减少对大规模标注数据的依赖。
-
合成数据生成:利用生成对抗网络(GANs)、变分自编码器(VAEs)等生成模型,生成具有多样性和语义丰富性的数据,增强模型的泛化能力。
跨领域和多任务学习
-
跨领域数据集:构建涵盖多个领域的数据集,支持模型在不同场景中的迁移和泛化。
-
多任务学习:设计包含多种任务的数据集,支持模型在多个任务中的联合训练和优化。
真实世界数据集
-
真实世界数据收集:通过众包、自动化标注工具和仿真技术,收集和标注真实世界的数据,提高数据的真实性和可靠性。
-
真实世界基准测试:开发支持真实世界部署的基准测试,评估模型在实际应用中的性能和适应性。
多模态融合方法的性能评估
评估指标
语义理解
-
交并比(IoU):评估预测分割与真实分割的重叠程度。
-
平均交并比(mIoU):对所有类别计算IoU的平均值,平衡类别不平衡问题。
-
像素准确率(PA):计算正确分类像素的比例。
-
精确率(Precision)和召回率(Recall):评估类别预测的性能。
-
F1分数:精确率和召回率的调和平均值。
3D目标检测
-
平均精度(AP):在不同召回率水平上整合精度。
-
平均平均精度(mAP):对所有目标类别平均AP值。
-
nuScenes检测分数(NDS):综合考虑精度和多种误差指标,如平均平移误差(mATE)、平均尺度误差(mASE)等。
定位和建图
-
绝对轨迹误差(ATE):比较估计轨迹和真实轨迹的全局精度。
-
相对姿态误差(RPE):评估连续姿态之间的局部精度。
导航和指令遵循
-
成功率(SR):计算成功导航试验的百分比。
-
目标进度(GP):衡量机器人相对于初始位置接近目标的程度。
-
按路径长度加权的成功率(SPL):平衡成功率和路径效率。
3D目标检测性能比较
nuScenes基准测试
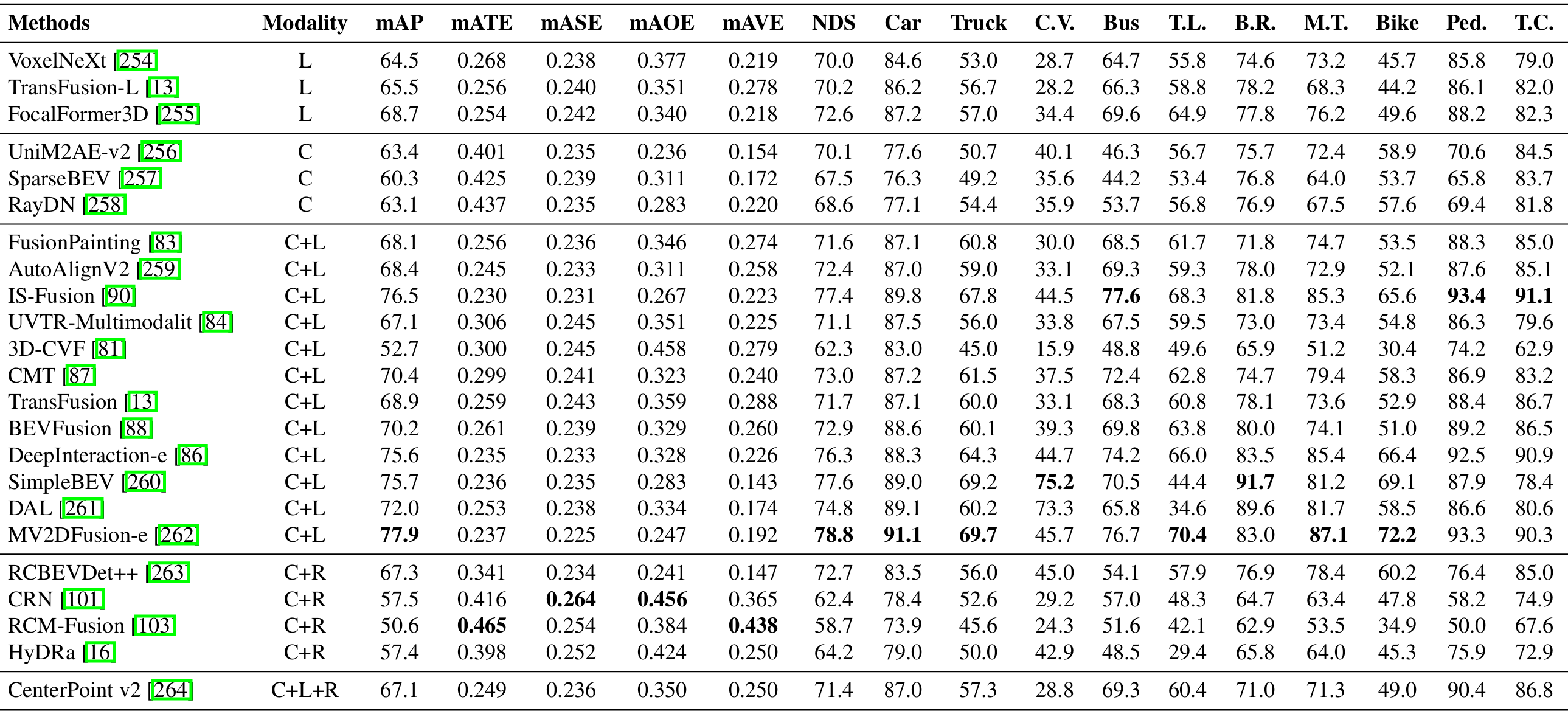
上表展示了在nuScenes基准测试中,不同3D目标检测方法在不同传感器融合策略下的性能表现。这些方法包括仅激光雷达(L)、仅相机(C)和相机-激光雷达融合(C+L)设置,主要评估指标包括mAP、mATE、mASE等。
-
单模态方法:如VoxelNeXt和TransFusion-L等激光雷达方法,以及UniM2AE-v2和SparseBEV等相机方法,在特定任务中表现良好,但在复杂环境中存在局限性。
-
多模态融合方法:如FusionPainting、AutoAlignV2和IS-Fusion等,通过结合激光雷达的精确几何信息和相机的丰富语义特征,显著提高了目标检测的精度和鲁棒性。
-
Transformer驱动的融合方法:如BEVFusion和TransFusion,通过自适应特征对齐优化跨模态信息交互,进一步提升了目标检测的性能。
导航任务性能比较
Room-to-Room(R2R)基准测试
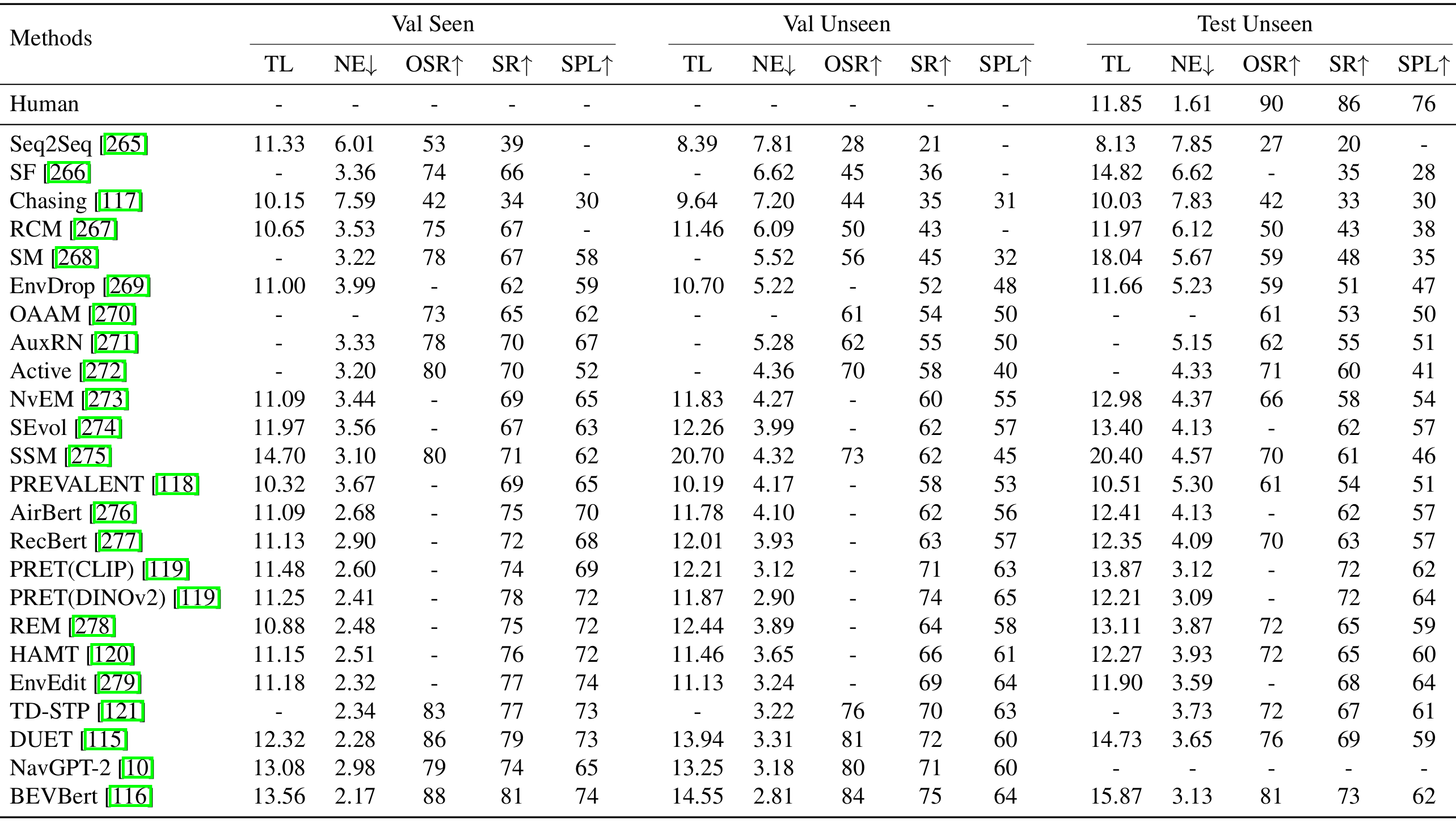
上表比较了在Room-to-Room(R2R)基准测试中不同导航方法的性能,主要评估指标包括轨迹长度(TL)、导航误差(NE)、Oracle成功率(OSR)、成功率(SR)和按路径长度加权的成功率(SPL)。
-
早期序列模型:如Seq2Seq和SF,在未见环境中全局路径优化表现不佳。
-
强化学习和拓扑推理:如RCM和Chasing Ghosts,通过自适应决策提高了导航效率。
-
记忆和环境适应:如SM和SSM,通过改进轨迹推理提高了长期路径效率。
-
多模态预训练:如PRET(DINOv2)和BEVBert,通过自监督学习提高了跨模态对齐能力,显著提升了导航性能。
3D问答和场景理解性能比较
ScanQA基准测试
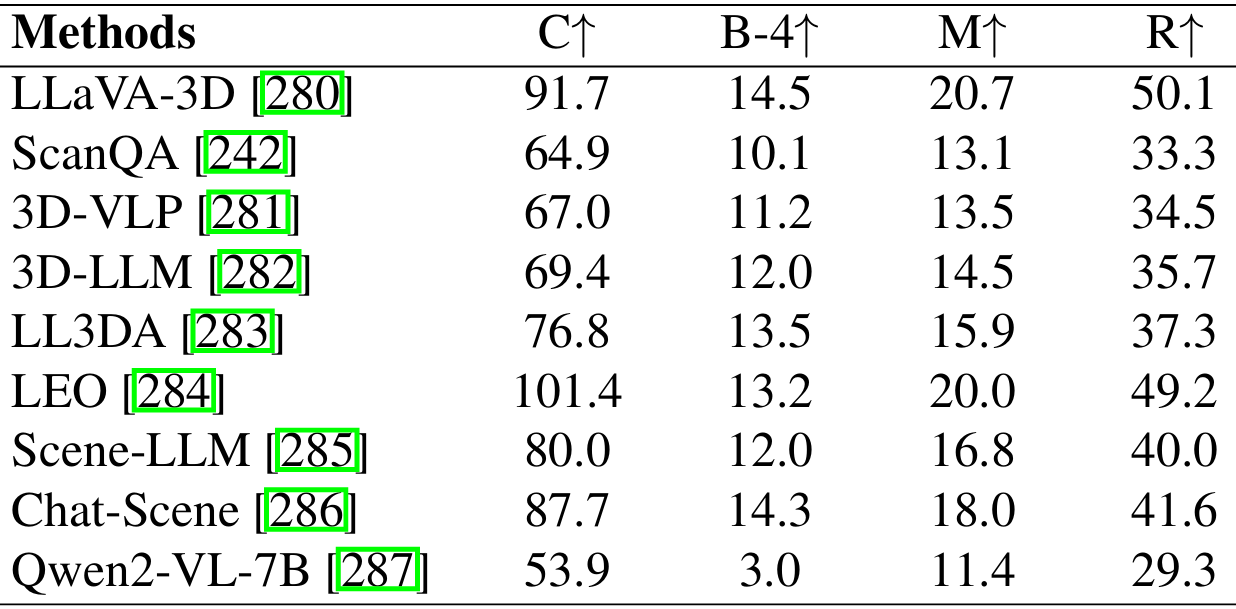
上表展示了在ScanQA验证集上不同视觉-语言模型(VLMs)的性能比较,主要评估指标包括CIDEr、BLEU-4、METEOR和ROUGE分数。
-
LLaVA-3D和3D-LLM:在3D场景理解和问答任务中表现出色,主要得益于优化的多视图特征提取和3D空间嵌入机制。
-
3D-VLP:通过上下文感知对齐策略,在密集场景描述任务中表现良好。
-
LL3DA和LEO:通过视觉交互微调和结构化嵌入,优化了指令遵循和长期任务执行的准确性。
机器人操作基准测试比较
机器人操作基准测试
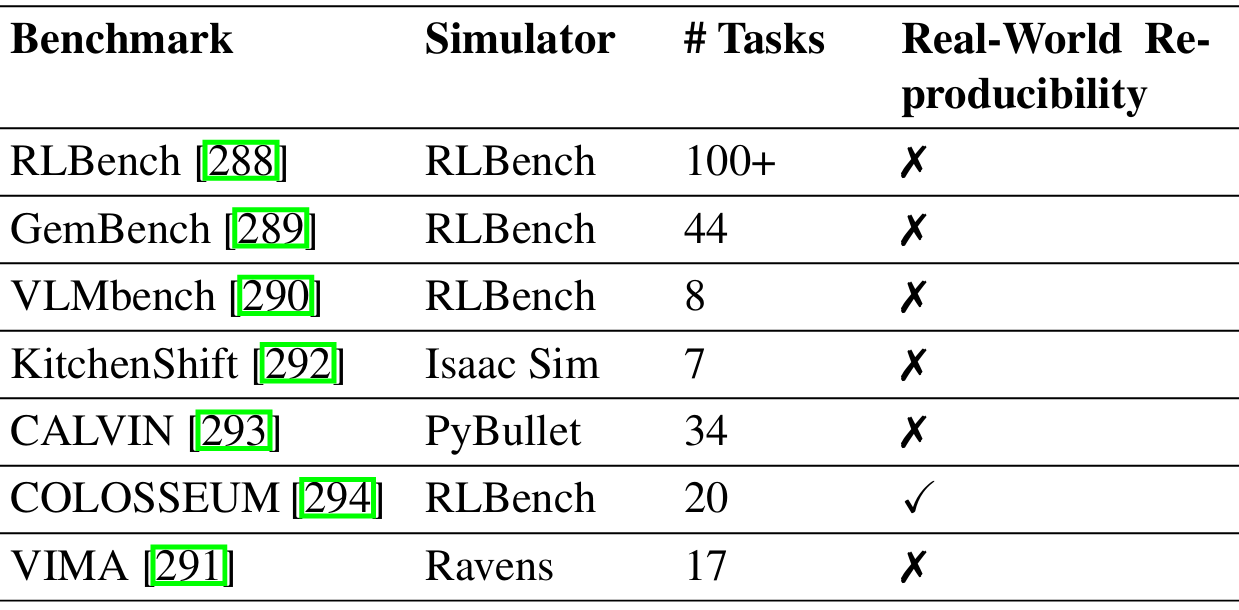
上表提供了机器人操作基准测试的比较,涵盖了模拟平台、任务多样性、真实世界可复现性等方面。这些基准测试为评估机器人在不同任务中的执行能力、泛化能力和适应能力提供了系统化的方法。
-
RLBench:包含100多个任务,涵盖从基本物体抓取到复杂工具使用和装配任务,适合强化学习(RL)、模仿学习(IL)和传统控制方法。
-
GemBench:专注于任务泛化,引入零样本任务设置和视觉-语言扩展,评估机器人在未见任务和物体上的表现。
-
VLMbench:强调语言条件下的机器人操作,通过组合任务生成,要求机器人进行推理和泛化。
-
KitchenShift:模拟厨房环境,引入环境领域的偏移,评估机器人在不同环境变化下的策略鲁棒性。
-
CALVIN:包含34个任务,强调长期规划和多任务适应性,适合多任务RL和模仿学习。
-
COLOSSEUM:支持真实世界可复现性,引入环境扰动,评估机器人在不同物理条件下的鲁棒性和多任务学习性能。
-
GenSim2:支持真实世界部署,利用MuJoCo和Isaac Sim支持可变任务配置,专注于大规模数据生成和Sim-to-Real迁移。
-
VIMA:基于Ravens,是一个多模态操作基准测试,评估机器人在多模态输入(视觉、语言和物理约束)下的性能。
小结
通过结合评估指标与任务特定的基准测试,第5部分提供了多模态方法在多样化机器人场景下的性能结构化概述,为后续关于优势、局限性和新兴趋势的分析奠定了基础。这些评估指标和基准测试为研究人员提供了一个标准化的框架,用于比较和评估多模态融合和视觉-语言模型在机器人视觉任务中的性能表现。
挑战与机遇
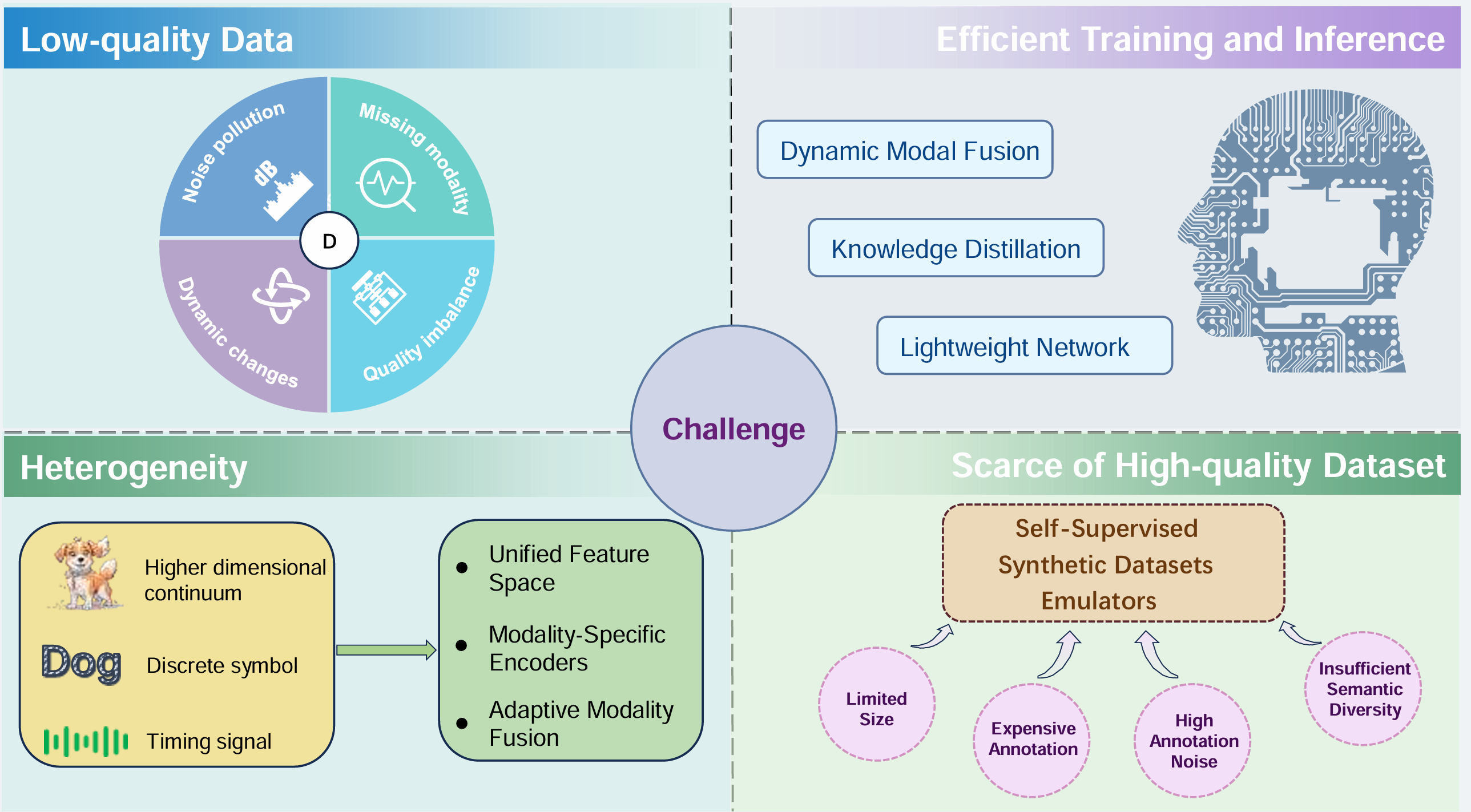
低质量数据
背景与挑战
多模态融合的核心目标是通过整合不同模态的信息来提高模型的泛化能力和鲁棒性。然而,在现实世界中,低质量数据严重影响了多模态学习的性能,使得模型难以在复杂环境中稳定工作。低质量数据的挑战主要体现在以下几个方面:
-
噪声污染:包括模态特定噪声(如视觉模态中的电子传感器噪声、音频模态中的环境干扰)和跨模态噪声(如弱对齐或未对齐样本引入的语义噪声)。
-
缺失模态:由于设备故障、数据丢失或用户偏好,某些模态的数据可能缺失。
-
模态质量不平衡:不同模态的数据质量存在差异,导致模型过度依赖某些模态。
-
模态质量动态变化:模态质量可能随时间和环境条件动态变化。
方法与解决方案
-
模态特定去噪:通过联合优化不同模态数据来去除噪声,例如在多光谱图像融合任务中,通过变分模型去除噪声。
-
跨模态去噪:通过模型校正和噪声鲁棒性正则化来减少噪声的影响。
-
数据插补:对于缺失模态,可以通过矩阵分解、图学习或生成对抗网络(GANs)等方法恢复缺失数据。
-
自适应融合:根据数据质量、信息贡献和任务需求动态调整融合方法。
异构性
背景与挑战
异构性是多模态融合任务中的一个核心挑战,主要由于不同模态数据在结构、特征分布和信息表示上的差异。例如,图像数据通常是高维连续值,音频数据是时间序列信号,而文本数据是离散符号序列。这种异构性使得直接融合多模态信息变得困难,统一表示学习、特征对齐和信息交互成为关键问题。
方法与解决方案
-
统一特征空间学习:将所有模态的数据投影到同一个特征空间中,例如CLIP通过视觉-语言对比学习使图像和文本共享同一潜在空间。
-
模态特定编码器:为不同模态设计特定的编码器,如使用Transformer处理文本、CNN处理图像、RNN处理音频,然后通过跨模态注意力机制进行特征对齐。
-
自适应模态融合:根据不同模态的数据质量、信息贡献和任务需求动态调整融合方法。例如,在自动驾驶中,根据环境光照条件动态调整RGB图像和激光雷达点云的融合权重。
高效训练和推理
背景与挑战
当前主流的视觉-语言模型(VLMs)通常基于大规模Transformer架构进行预训练,这些模型通常包含数十亿甚至数千亿个参数。预训练需要大量的计算资源和时间成本,限制了模型的训练效率和扩展能力,使得模型部署在实际应用中面临严重的计算瓶颈。此外,视觉和语言模态在数据维度和特征空间上的明显异构性可能导致联合优化时训练效率低下、推理延迟高和内存消耗大。
方法与解决方案
-
轻量化网络架构设计:通过引入轻量级的视觉-语言融合架构,如CrossViT、MobileViT、MoCoViT等多尺度Transformer架构,有效减少计算复杂度。
-
模型压缩和知识蒸馏:通过知识蒸馏将大规模教师模型的知识迁移到轻量级学生模型中,显著提高训练效率,同时保持模型性能。
-
动态模态融合:通过模态dropout或自适应模态选择方法,减少冗余模态计算,提高推理效率。
高质量数据集稀缺
背景与挑战
视觉-语言模型(VLMs)的性能和泛化能力高度依赖于训练数据集的可用性、多样性和质量。然而,现有的大规模视觉-语言数据集(如Visual Genome、Conceptual Captions和LAION-400m)通常存在以下问题:
-
数据集规模有限:数据集的规模不足以支持模型学习丰富的跨模态语义对齐关系。
-
标注噪声高:数据集中存在标注错误或不准确的标注,影响模型学习。
-
语义多样性不足:数据集中的语义内容不够丰富,导致模型难以泛化到更广泛的应用场景。
-
标注成本高:高质量标注需要大量的人力和时间,增加了数据集构建的成本。
方法与解决方案
-
自监督或弱监督学习:通过自监督或弱监督学习策略减少模型对标注质量的依赖,例如CLIP和ALIGN等模型使用大规模弱标注或自然语言监督学习通用的视觉-语言表示。
-
合成数据集生成:通过规则或第三方工具(如Stable Diffusion、DALL-E)生成具有多样性和语义丰富性的图像-文本对,增强模型的泛化能力。
-
特定领域数据集构建:在特定领域(如机器人操作、自动驾驶)中,通过仿真器或世界模型生成更接近物理世界的数据,提高VLMs在真实物理世界中的性能。
小结
尽管多模态融合和视觉-语言模型(VLMs)在机器人视觉中取得了显著进展,但仍然面临低质量数据、异构性、高效训练和推理以及高质量数据集稀缺等关键挑战。未来的研究需要在以下几个方向上取得突破:
-
改进跨模态对齐技术:开发更有效的跨模态对齐方法,以提高模型在不同模态间的信息交互能力。
-
开发高效的训练和推理策略:设计轻量级模型架构,优化模型压缩和知识蒸馏技术,提高模型的训练和推理效率。
-
利用自监督学习增强适应性:通过自监督学习策略,减少对标注数据的依赖,提高模型在不同任务和场景中的适应能力。
-
构建更高质量的数据集:通过自监督学习、合成数据生成和特定领域数据集构建,提高数据集的规模、多样性和质量,支持模型的泛化和迁移学习。
结论与未来工作
-
结论:
-
多模态融合和视觉-语言模型(VLMs)显著提升了机器人视觉系统在复杂环境中的感知、推理和交互能力。
-
通过整合来自不同传感器的互补信息,这些技术在多个关键任务中表现出色,包括语义场景理解、3D目标检测、导航与定位、同时定位与建图(SLAM)和机器人操作等。
-
尽管取得了显著进展,但多模态融合和VLMs在机器人视觉中仍面临低质量数据、异构性、高效训练和推理以及高质量数据集稀缺等关键挑战。
-
-
未来工作:
-
开发更有效的对齐方法,以更好地处理不同模态间的信息交互。
-
设计轻量级模型架构,优化模型压缩和知识蒸馏技术,提高模型的训练和推理效率。
-
通过自监督学习策略,减少对标注数据的依赖,提高模型在不同任务和场景中的适应能力。
-
通过自监督学习、合成数据生成和特定领域数据集构建,提高数据集的规模、多样性和质量,支持模型的泛化和迁移学习。
-
