













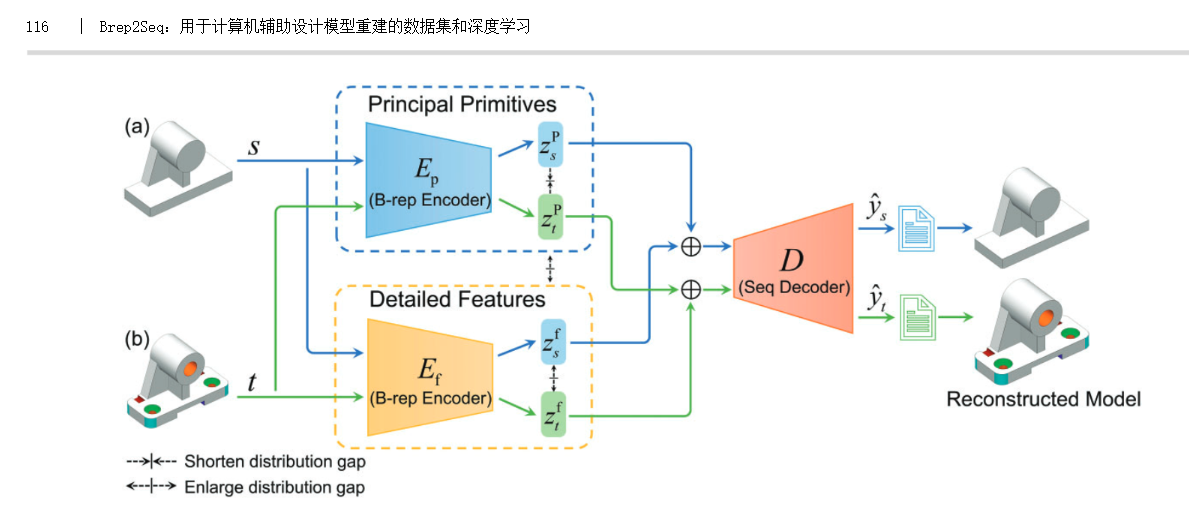


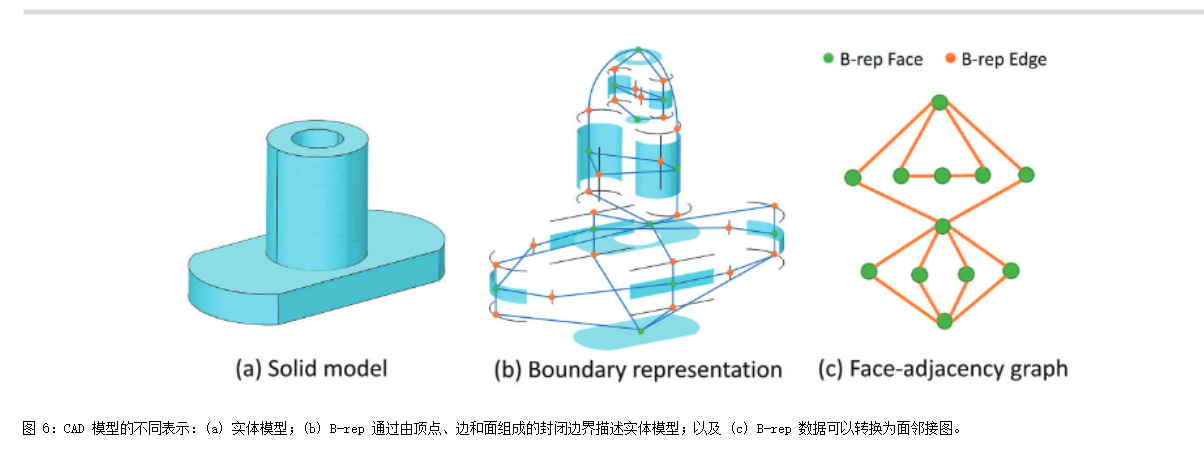






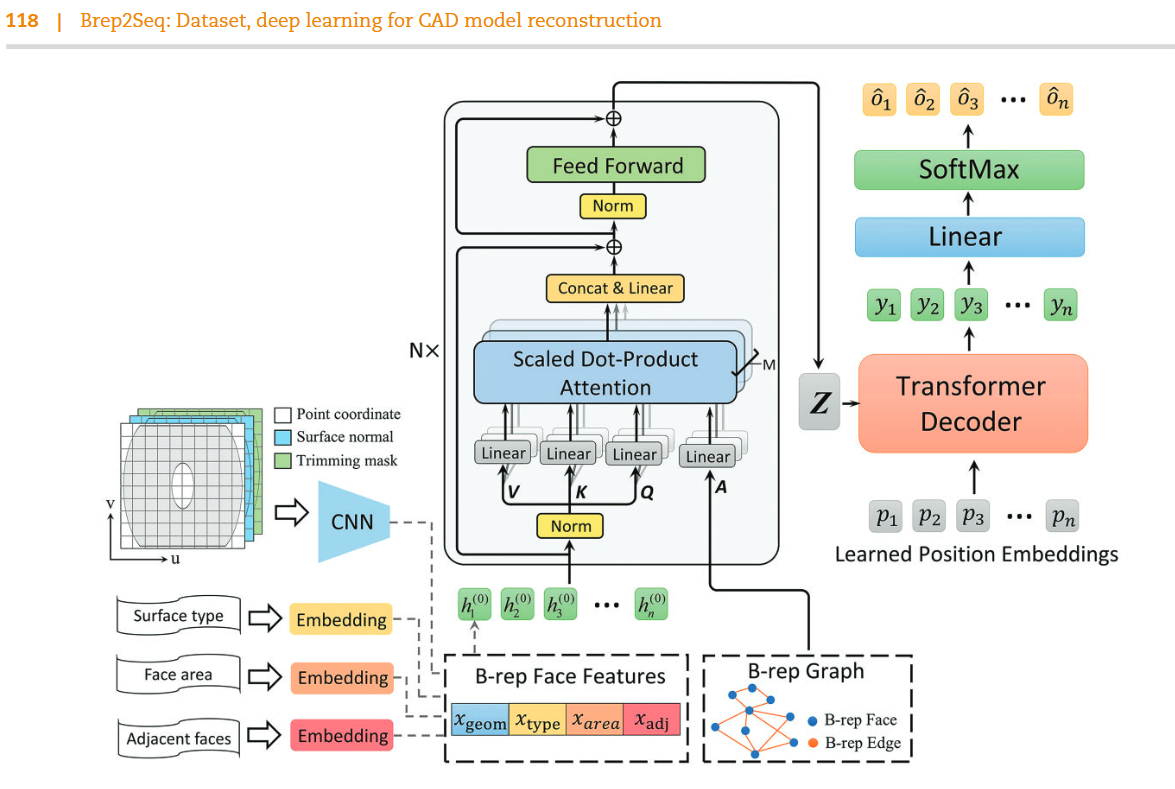





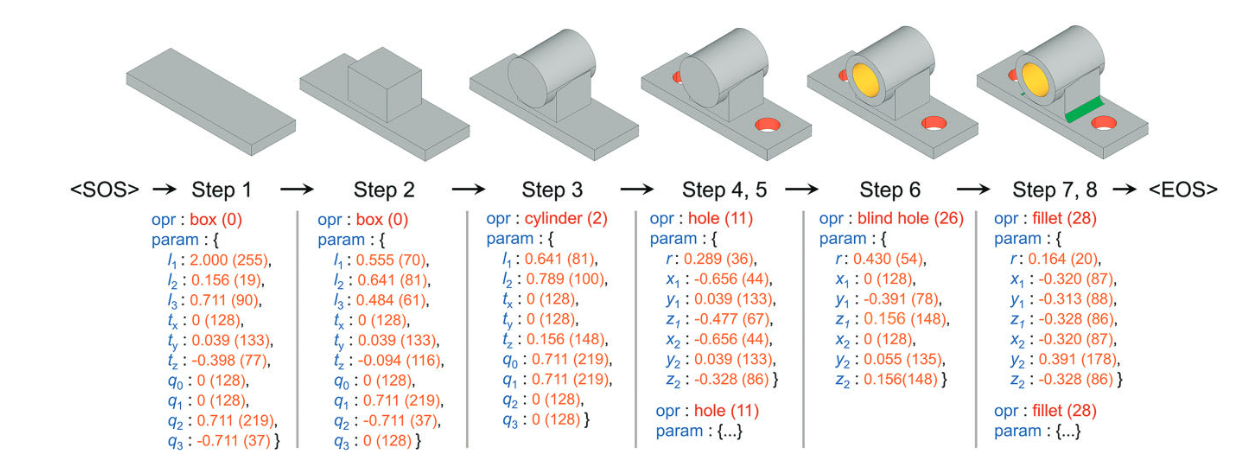
这段文本描述了一个多头自注意力机制(MultiHead Attention)的实现细节,该机制是Transformer架构中的核心组件之一。以下是公式(14)和(15)及其相关概念的详细解释:
公式(14)解析
MultiHead (H): 多头自注意力机制的输出。
Concat(head_1, ..., head_M): 将M个独立的自注意力头(heads)的输出进行拼接(concatenation)。每个自注意力头都会生成一个单独的特征表示,通过拼接这些表示,可以得到一个更丰富的综合特征。
W^O: 一个线性变换矩阵,用于将拼接后的特征向量映射到最终的输出维度。
公式(15)解析
- head_m = self-att(H, A_1, A_2, A_3):
这部分定义了第m个自注意力头的计算过程,它依赖于输入隐藏状态H以及三个额外的矩阵A_1、A_2和A_3,这些矩阵可能包含了关于节点间关系的特定信息。
- softmax(...):
计算注意力分数的过程使用了softmax函数,以确保所有注意力分数加起来等于1,从而形成一个有效的概率分布。
注意力分数由以下几部分组成:
Q_mK_m^T / √d_k: 这是标准的自注意力机制中的点积注意力(Dot-product attention),其中Q_m和K_m分别是查询(Query)和键(Key)矩阵,d_k是它们的维度。这个部分用于衡量不同位置之间的相似度。
A_1(W_a1^m)^T + A_2(W_a2^m)^T + A_3(W_a3^m)^T: 这些项引入了额外的偏置或权重,它们与A_1、A_2和A_3矩阵相乘,并与查询和键的点积结果相加。这可能是为了融入图结构或其他先验知识到注意力机制中。
- V_m:
V_m是值(Value)矩阵,它与注意力分数相乘,以生成最终的输出特征向量。
- Q_m, K_m, V_m 的计算:
对于每一个自注意力头m,查询Q_m、键K_m和值V_m都是通过输入隐藏状态H与相应的权重矩阵W_q^m、W_k^m和W_v^m相乘得到的。
总结
每个自注意力头独立地计算注意力分数和输出特征,然后将这些特征拼接在一起并通过一个线性变换层得到最终的多头自注意力输出。
通过引入额外的矩阵A_1、A_2和A_3,该机制能够更好地捕捉和利用输入数据中的结构化信息,如图结构中的边和面的关系。
这种设计使得模型能够在处理复杂的数据结构时,更加灵活和高效地提取和整合信息。



















等等研究这篇3D CAD model retrieval based on sketch and unsupervised variational autoencoder - ScienceDirect