前言:当计算机学会了"找东西"
你有没有遇到过这种情况?
-
在停车场转了半天,死活找不到自己的车
-
翻遍相册想找一张带狗的照片,结果只能手动一张张看
-
超市排队时,总希望有个自动收银台能快速识别商品
这些问题,目标检测(Object Detection) 技术都能解决!而今天我们要聊的 YOLO(You Only Look Once) ,就是目标检测领域的"闪电侠"------快、准、狠!
在这篇文章中,我会带你:
✅ 用5行代码 实现第一个目标检测程序
✅ 搞懂YOLO为什么比传统方法快10倍
✅ 亲手试试用YOLOv12检测日常物品
准备好了吗?让我们开始这场"视觉智能"的冒险!
1. 目标检测简史:从慢动作到闪电战
(1) 石器时代:滑动窗口法
早期的目标检测就像用放大镜一点点扫描整张图片:
# 伪代码:传统检测流程
for window in image:
if contains_object(window):
draw_box(window)缺点:慢如蜗牛!检测一张图可能要几分钟。
(2) 工业革命:Faster R-CNN
2015年出现的Faster R-CNN引入了区域提议网络(RPN),速度提升到每秒5帧(FPS),但依然不够实时。
(3) 闪电战时代:YOLO降临!
2016年,Joseph Redmon提出了YOLO,核心思想就一句话:
"只看一眼,全图预测!"
相比Faster R-CNN的"先找候选区再检测",YOLO直接把检测变成单次回归问题,速度飙升至45 FPS!
| 方法 | 速度 (FPS) | 准确率 (mAP) | 特点 |
|---|---|---|---|
| 滑动窗口 | 0.1 | 20% | 简单但极慢 |
| Faster R-CNN | 5 | 73% | 两阶段,精度高 |
| YOLOv1 | 45 | 63% | 首次实现实时检测 |
| YOLOv12 | 120 | 78% | 速度精度双巅峰 |
🔍 小知识:mAP(平均精度)是检测准确率指标,越高越好;FPS(帧率)代表每秒能处理多少张图。
2. 5行代码实战:你的第一个YOLO检测器
理论够了!现在让我们用YOLOv12(官方预训练模型)快速实现一个物品检测程序。
环境准备
确保已安装Python 3.10+和PyTorch:
pip install torch torchvision opencv-python ultralytics完整代码
import cv2
import torch
from ultralytics import YOLO
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 下载地址为https://github.com/sunsmarterjie/yolov12/releases/download/v1.0/yolov12x.pt
model = YOLO('yolov12x.pt').to(device).eval()
# 读取图片(替换成你的图片路径)
image = cv2.imread("office.jpg")
# 执行检测
results = model(image)
# 保存结果
annotated_img = results[0].plot()
output_path = "office_annotated.jpg"
cv2.imwrite(output_path, annotated_img)原图:

运行效果:

代码解析
-
YOLO('yolov12x.pt'):加载官方预训练模型 -
model.eval():切换为评估模式(关闭Dropout等训练专用层)
3. YOLO为什么快?揭秘单阶段检测黑科技
传统方法像"先猜后验证",而YOLO则是"一眼定乾坤":
传统方法(两阶段)
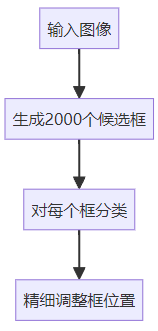
YOLO方法(单阶段)
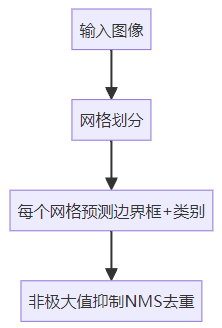
关键创新:
-
网格预测:将图像划分为S×S网格,每个网格直接预测B个边界框
-
端到端训练:损失函数同时优化位置和类别预测
-
多尺度融合 :v12新增的特征金字塔能更好检测小物体
4. 进阶实战:用YOLOv12打造"办公室物品统计器"
让我们升级刚才的简单demo,实现一个统计办公室物品的小工具:
from collections import defaultdict
# 统计物品数量
item_counts = defaultdict(int)
for box in results[0].boxes:
item_counts[results[0].names[int(box.cls)]] += 1
# 生成统计报告
print("=== 办公室物品清单 ===")
for item, count in item_counts.items():
print(f"{item}: {count}个")输出示例:
=== 办公室物品清单 ===
chair: 5个
tv: 1个
keyboard: 1个
person: 4个
laptop: 3个
potted plant: 1个
bottle: 1个5. 常见问题Q&A
Q:检测时GPU不是必须的? A:是的!但用CPU会慢3-5倍。建议:
-
笔记本:用
model.to('cuda')启用GPU加速 -
树莓派:建议使用Tiny版本的模型