参考网站:什么是自回归模型 | IBM
基本说明:
AR是一种强大的最常用于时间序列分析和预测的机器学习技术,使用时间序列先前时间步长的一个或者多个值来创建回归模型。
用同一变数例如x的之前各期,亦即x1至xt-1来预测本期xt的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测 x(自己);所以叫做自回归。
自回归模型假设当前时刻的数据仅依赖于历史时刻的数据,通过条件概率分解序列的联合分布: 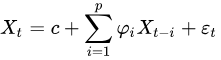
其中: c是常数项;被假设为平均数等于0,标准差等于的随机误差值;被假设为对于任何的t都不变。文字叙述为:X的期望值等于一个或数个落后期的线性组合,加常数项,加随机误差。
生成过程
-
逐步预测:每次基于已生成的部分序列预测下一个元素(如GPT通过上文预测下一个词)。
-
迭代采样:通过随机采样(如从softmax分布中采样)或贪婪搜索生成新元素,并将新元素反馈到模型中以继续生成后续内容。
-
典型架构:Transformer的解码器(如GPT)或因果卷积网络(如WaveNet),通过掩码机制确保仅依赖历史信息。
实际应用中的主要限制
-
计算效率问题
-
序列长度限制:生成长度为N的序列需N次前向计算,导致延迟高(如长文本生成)。
-
内存瓶颈:Transformer的注意力机制内存消耗随序列长度平方增长(O(N\^2))。
-
-
长程依赖建模困难
- 尽管Transformer优于RNN,但远距离依赖仍可能因注意力权重分散或梯度消失而失效(如生成连贯的长文档)。
-
误差累积与暴露偏差
-
训练-测试不一致:训练时使用真实历史数据(Teacher Forcing),而测试时依赖模型自身生成的历史,错误会逐步累积(Exposure Bias)。
-
模式坍塌:倾向于生成高频但低多样性的内容(如重复短语)。
-
-
可控生成挑战
难以精确控制生成内容的属性(如情感、风格),需额外引入约束或后处理。
改进技术手段
-
效率优化
-
稀疏注意力:如Longformer的局部+全局注意力、Reformer的局部敏感哈希(LSH)注意力,将复杂度降至O(N\\log N)。
-
分块生成:将序列分段处理(如Image Transformer对图像分块)。
-
模型蒸馏:训练小型化模型(如DistilGPT-2)保持性能的同时减少计算量。
-
-
长序列建模改进
-
记忆机制:如Transformer-XL通过循环记忆模块保留跨段信息。
-
递归结构:将Transformer与RNN结合(如Compressive Transformer)增强长程记忆。
-
-
缓解误差累积
-
计划采样(Scheduled Sampling):逐步混合训练时的真实输入与模型生成输入。
-
强化学习:通过策略梯度(如RLHF)直接优化生成序列的整体质量。
-
-
可控生成技术
-
条件控制:在输入中嵌入控制信号(如CTRL模型的领域控制前缀)。
-
解码约束:束搜索(Beam Search)中引入禁止重复n-gram等规则。
-
能量模型:如GeDi通过辅助模型引导生成方向。
-
并行化生成
-
非自回归模型(NAR):如Mask-Predict通过迭代掩码预测实现并行解码(牺牲部分质量换取速度)。
-
半自回归:部分步骤并行化(如Blockwise Parallel Decoding)。
-
-
自回归和回归区别:
| 特性 | 自回归模型 (AR) | 非自回归模型 (NAR) |
|---|---|---|
| 生成方式 | 逐步生成,严格顺序依赖 | 并行生成,一步预测所有位置 |
| 速度 | 慢(需O(N)次前向计算) | 快(仅需O(1)次前向计算) |
| 质量 | 高质量,上下文连贯 | 可能因独立性假设降低连贯性 |
| 训练目标 | 最大化似然P(x_t|x_{\ |
直接建模P(x_{1:T}|c)(c为条件) |
| 典型模型 | GPT、Transformer-Decoder | BART、T5、Masked-LM |
| 应用场景 | 文本生成、音乐生成 | 机器翻译、文本摘要(需快速场景) |
python
# 自回归生成(顺序)
for t in range(T):
x_t = model(x_<t) # 依赖历史
# 非自回归生成(并行)
x_1:T = model(c) # 直接输出全部序列应用场景
1. 自回归模型
-
自然语言生成:GPT-3的故事创作、ChatGPT的对话生成。
-
时间序列预测:股票价格预测(ARIMA)、天气建模。
-
语音合成:WaveNet生成逼真语音波形。
-
代码生成:GitHub Copilot的代码补全。
2. 非自回归模型
-
机器翻译:Google的NAT(Non-Autoregressive Translation)。
-
文本摘要:快速生成摘要(如BART的并行解码)。
-
图像生成:部分扩散模型的并行去噪步骤。
代码示例:
python
import torch
import torch.nn as nn
class ARModel(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.LSTM(hidden_size, hidden_size)
self.head = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
# x: [seq_len, batch_size]
x = self.embed(x) # [seq_len, batch_size, hidden_size]
outputs, _ = self.rnn(x)
return self.head(outputs) # [seq_len, batch_size, vocab_size]
# 生成示例(贪婪搜索)
def generate_ar(model, start_token, max_len):
tokens = [start_token]
for _ in range(max_len):
logits = model(torch.tensor([tokens[-1]])) # 预测下一步
next_token = logits.argmax(-1).item() # 贪婪选择
tokens.append(next_token)
return tokens