#作者:闫乾苓
文章目录
- 概述
- 工作原理
- 集群环境
- 节点管理
- 副本管理
-
- [add_member 在给定节点上添加仲裁队列成员(副本)](#add_member 在给定节点上添加仲裁队列成员(副本))
- delete_member删除给定节点上的仲裁队列成员(副本)
- 节点高可用测试
本文使用目前官方推荐的quorum 类型的队列如何进行高可用设置进行了测试及说明。
概述
仲裁队列是一种现代队列类型,它基于Raft 共识算法实现了持久的、复制的 FIFO 队列。
旨在更加安全,并提供更简单、定义明确的故障处理语义,用户在设计和操作系统时应该更容易推理。
仲裁队列和流现在取代了原始的、复制的镜像经典队列。镜像经典队列早已被弃用,并已从 RabbitMQ 4.x 中删除。
仲裁队列针对数据安全是首要任务的用例进行了优化。仲裁队列应被视为复制队列类型的默认选项。
工作原理
RabbitMQ的仲裁队列通过使用Raft一致性算法、消息复制和持久化等技术,实现了高可用性的消息传输和数据存储。这些机制共同确保了即使在节点故障或网络异常等不利情况下,消息仍然能够可靠地传输和存储
1.节点之间的交互
在RabbitMQ的集群中,节点之间通过交换消息来进行状态同步。当一个新节点加入或发生故障转移时,其他节点会与该节点进行交互,以确保其状态与集群保持同步。
2.消息复制
RabbitMQ使用消息复制技术来确保消息在集群中的可靠存储。每个消息都会被复制到多个节点上,以防止在某些节点发生故障时数据丢失。这种复制机制为数据的高可用性提供了保障。
3.共识机制
RabbitMQ的仲裁队列使用Raft一致性算法来实现共识机制。Raft是一种用于管理复制日志的一致性算法,它通过在集群中的节点之间达成共识来确保消息的可靠传输。当一个节点发送一条消息时,其他节点会验证该消息的一致性,并确保其在整个集群中可靠传输。
4.选举领导者
在RabbitMQ的仲裁队列中,存在一个领导者节点和一个或多个副节点。领导者节点负责处理写请求,而副节点则复制领导者的操作。当领导者节点发生故障时,副节点会通过Raft算法进行选举,以选出一个新的领导者节点来继续处理写请求。
5.消息持久化
RabbitMQ中的仲裁队列支持消息持久化,这意味着即使在节点重启或崩溃的情况下,消息也不会丢失。通过将消息写入磁盘并在副节点之间进行复制,仲裁队列确保了消息的长期保存和可靠性。
6.自动故障转移
如果领导者节点发生故障,RabbitMQ会自动将一个副节点提升为新的领导者节点。其他副节点则会与新的领导者节点进行同步,以确保集群的可用性和数据的一致性。这种自动故障转移机制进一步提高了RabbitMQ仲裁队列的高可用性。
集群环境
Rabbimq集群使用RabbitMQ Cluster Kubernetes Operator部署,使用nfs storageClass的pvc进行持久化存储。
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: rabbitmq-cluster01
namespace: rabbitmq-test
spec:
replicas: 3
image: rabbitmq:3.13.7-management
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 2000m
memory: 4Gi
rabbitmq:
additionalConfig: |
cluster_partition_handling = pause_minority
disk_free_limit.relative = 1.0
collect_statistics_interval = 10000
channel_max = 1000
vm_memory_high_watermark_paging_ratio = 0.7
total_memory_available_override_value = 4GB
log.file = /var/log/rabbitmq/rabbit.log
persistence:
storageClassName: nfs
storage: "20Gi"
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- rabbitmq-cluster01
topologyKey: kubernetes.io/hostname
service:
type: NodePort节点管理
仲裁队列增加集群节点
通过在指定节点上为所有匹配的队列添加成员(副本)来增长仲裁队列集群。
rabbitmq-queues [--node <node>] [--longnames] [--quiet] grow <node> <all | even> [--vhost-pattern <pattern>] [--queue-pattern <pattern>] [--membership <promotable|voter>]
<--node>
用于放置副本的节点名称
<all | even>
为所有匹配的队列或仅为成员计数为偶数的队列添加成员
--queue-pattern
用于匹配队列名称的正则表达式
--vhost
匹配虚拟主机名的正则表达式
--membership
添加可晋升的非投票人(默认)或正式投票人
--errors-only
仅列出报告错误的队列为所有匹配的队列,vhost为/,匹配所有queue 增加'rbt04'副本节点
rabbitmq-queues grow "rabbit@rbt04" "all" --vhost-pattern "/" --queue-pattern ".*"

仅为副本数为偶数的队列,vhost为/,匹配所有queue, 增加'rbt05'副本节点
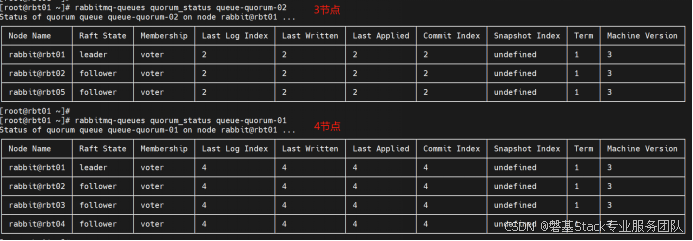
[root@rbt01 ~]# rabbitmq-queues grow "rabbit@rbt05" "even" --vhost-pattern "/" --queue-pattern
".*"因使用了even参数,只匹配了偶数节点的queue-quorum-02

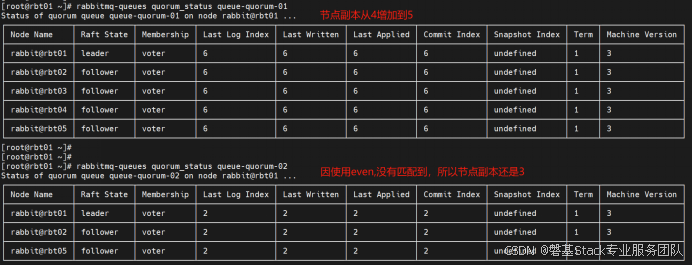
重新平衡仲裁队列leader所在节点
在正在运行的集群节点之间重新平衡复制队列的领导者
用法:
rabbitmq-queues [--node <node>] [--longnames] [--quiet] rebalance < all | classic | quorum | stream > [--vhost-pattern <pattern>] [--queue-pattern <pattern>]
<type>
队列类型,必须是以下之一:all、classic、quorum、stream
--queue-pattern <pattern>
用于匹配队列名称的正则表达式
--vhost-pattern <pattern>
匹配虚拟主机名的正则表达式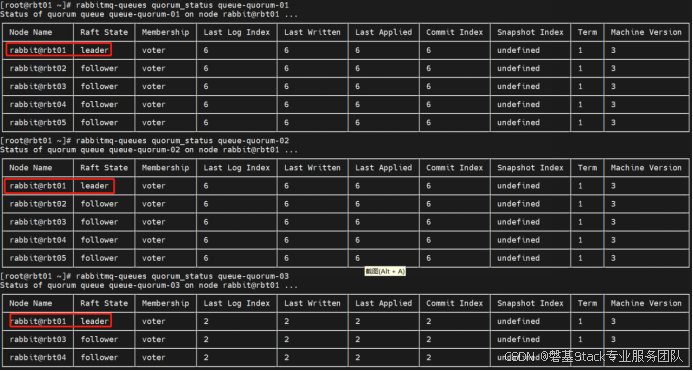
对vhost /下,所有的queue,进行重新平衡leader
[root@rbt01 ~]# rabbitmq-queues rebalance "all" --vhost-pattern "/" --queue-pattern ".*"重新平衡后,3个队列的leader 由原来的全部为rbt01,变成了rbt01,rbt03,rbt04
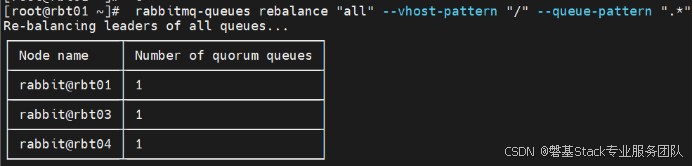
仲裁队列减少集群节点
用法:
rabbitmq-queues [--node <node>] [--longnames] [--quiet] shrink <node> [--errors-only]
<node>
从中删除副本的节点名称
--errors-only
仅列出报告错误的队列
[root@rbt01 ~]# rabbitmq-queues shrink rabbit@rbt04
Shrinking quorum queues on rabbit@rbt04...
vhost name size result
/ queue-quorum-03 2 ok
/ queue-quorum-01 4 ok
/ queue-quorum-02 4 ok
[root@rbt01 ~]# rabbitmq-queues shrink rabbit@rbt05
Shrinking quorum queues on rabbit@rbt05...
vhost name size result
/ queue-quorum-01 3 ok
/ queue-quorum-02 3 ok副本管理
声明仲裁队列时,必须在集群中启动其初始副本数。默认情况下,要启动的副本数最多为三个,集群中每个 RabbitMQ 节点一个。
三个节点是仲裁队列的实际最小副本数。在节点数较多的 RabbitMQ 集群中,添加比仲裁更多的副本不会在仲裁队列可用性方面带来任何改进,但会消耗更多集群资源。
因此,仲裁队列的推荐副本数是群集节点的仲裁数(但不少于三个)。这假设一个完整的群集至少有三个节点。
仲裁队列的副本由管理员管理。当新节点添加到集群时,它将不托管仲裁队列副本,除非管理员明确将其添加到仲裁队列或仲裁队列集的成员(副本)列表中。
当需要退役节点(从集群中永久删除)时,必须将其从其当前托管副本的所有仲裁队列的成员列表中明确删除。
为了成功添加和删除成员,集群中必须有一定数量的副本,因为集群成员资格的更改被视为队列状态的更改。
在执行涉及成员资格变更的维护操作时,需要小心不要因失去法定人数而意外导致队列不可用。
更换集群节点时,先添加新节点然后再退役其替换的节点是更安全的做法。
用于队列(尤其是仲裁队列)的维护任务, 管理复制队列的副本
add_member 在给定节点上添加仲裁队列成员(副本)

rabbitmq-queues add_member --vhost / queue-quorum-01 rabbit@rbt04
rabbitmq-queues add_member --vhost / queue-quorum-01 rabbit@rbt05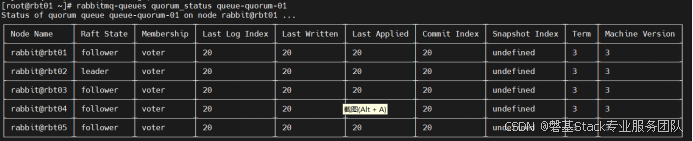
delete_member删除给定节点上的仲裁队列成员(副本)
rabbitmq-queues delete_member --vhost / queue-quorum-01 rabbit@rbt01
rabbitmq-queues delete_member --vhost / queue-quorum-01 rabbit@rbt02
节点高可用测试
创建queue
rabbitmqadmin declare queue name=queue_quorum_01 durable=true arguments='{"x-queue-type": "quorum"}'创建exchange及bingding
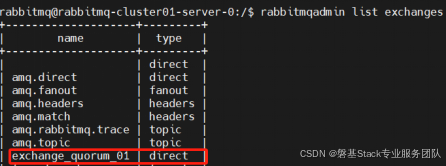
rabbitmqadmin declare exchange name=exchange_quorum_01 type=direct durable=true
rabbitmqadmin declare binding source=exchange_quorum_01 destination=queue_quorum_01 routing_key=queue_quorum_01查看创建的queue_quorum_01的状态

查看exchange是否创建成功
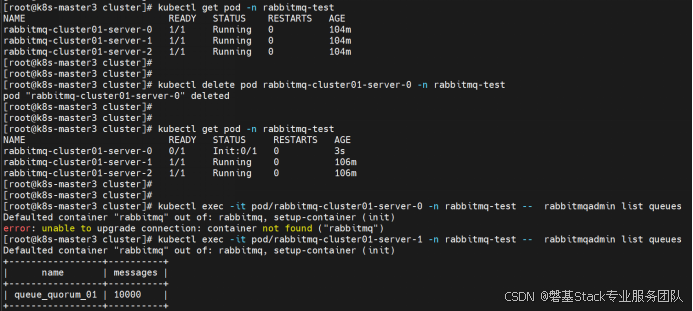
通过python脚本写入10000条消息数据。

手动删除1个pod节点,模拟3节点集群中1个节点宕机的故障,数据不会丢失。
继续在producer客户端和cunsume 客户端python脚本一直时运行时,进行删除pod节点测试。
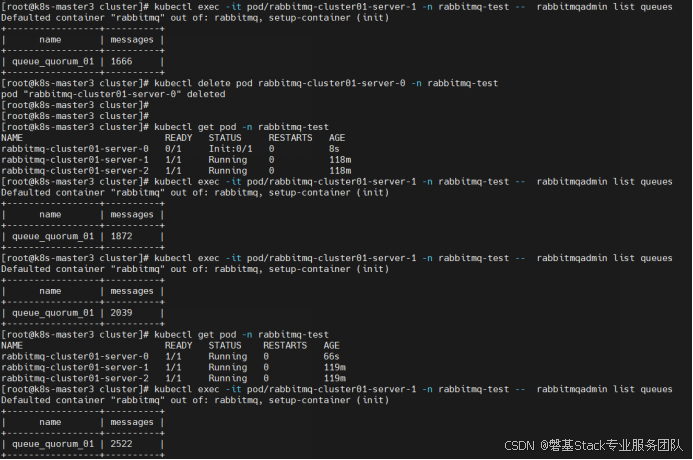
只要客户端连接的不是被停止的pod节点,客户端生产和消费都是正常的。通过web管理界面看,队列的状态是:running
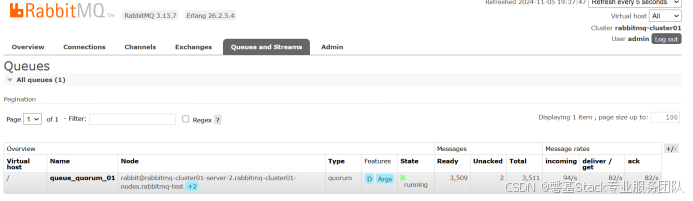
此时如果继续删除第2个pod节点,模拟3节点集群中2个节点宕机的故障,在k8s中使用operator部署的RabbitMQ集群,在手动执行删除第2个pod是,命令将被挂起(无反应)直到operator通过内容部控制机制将第1个删除的pod重启成功,才会继续执行第2个pod的删除操作。
此时Rabbimq服务是正常状态(如果客户端连接的是被删除pod节点,连接会被断开,重连后连接被svc 负载到其他pod节点,可以正常读写数据)。这应该是RabbitMQ operator控制的效果,在3节点的集群中,确保同时只能1个pod节点宕机,服务不受影响。

在此期间,消息队列中的数据不会丢失。
另外在裸金属部署的3节点RabbitMQ集群中进行了类似测试,使用"rabbitmq stop_app"同时停止2个节点(非读写客户端正在连接的节点),此时RabbitMQ处于"minority"(少数)状态,这正是quorum队列需要超过半数节点正常才能正常工作的工作机制。

此时,写客户端(producer)的连接状态虽然为'running'但实际测试是没有数据写入到服务器,读客户端(consumer)的连接状态为"flow",也不能从服务器获取数据。
