麻省理工学院电气工程与计算机科学系Pulkit Agrawal教授,介绍了一种新方法,可以让机器人在扫描的家庭环境模拟中接受训练,为任何人都可以实现定制的家庭自动化铺平了道路。
本文将探讨通过Franka机器人在虚拟环境中训练的特点,研究人员根据手机扫描结果对家庭场景用的机器人进行模拟训练

在许多自动化愿望清单中,排在首位的是一项特别耗时的任务:家务。
有很多原因导致您在家中看不到很多真实的机器人。其中最主要的是非结构化和半结构化环境的问题。没有两个家是相同的,从布局到照明到表面到人和宠物。即使机器人可以有效地绘制每个家庭的地图,空间也总是在变化。
近几十年来,模拟已成为机器人训练的基础要素。它允许机器人在现实世界中尝试完成任务并失败数千次甚至数百万次,而这些尝试和失败所需的时间与机器人在现实世界中尝试一次所需的时间相同。
模拟失败的后果也比现实生活中的后果要低得多。想象一下,教机器人把杯子放进洗碗机需要它在这个过程中打碎 100 个现实生活中的杯子。
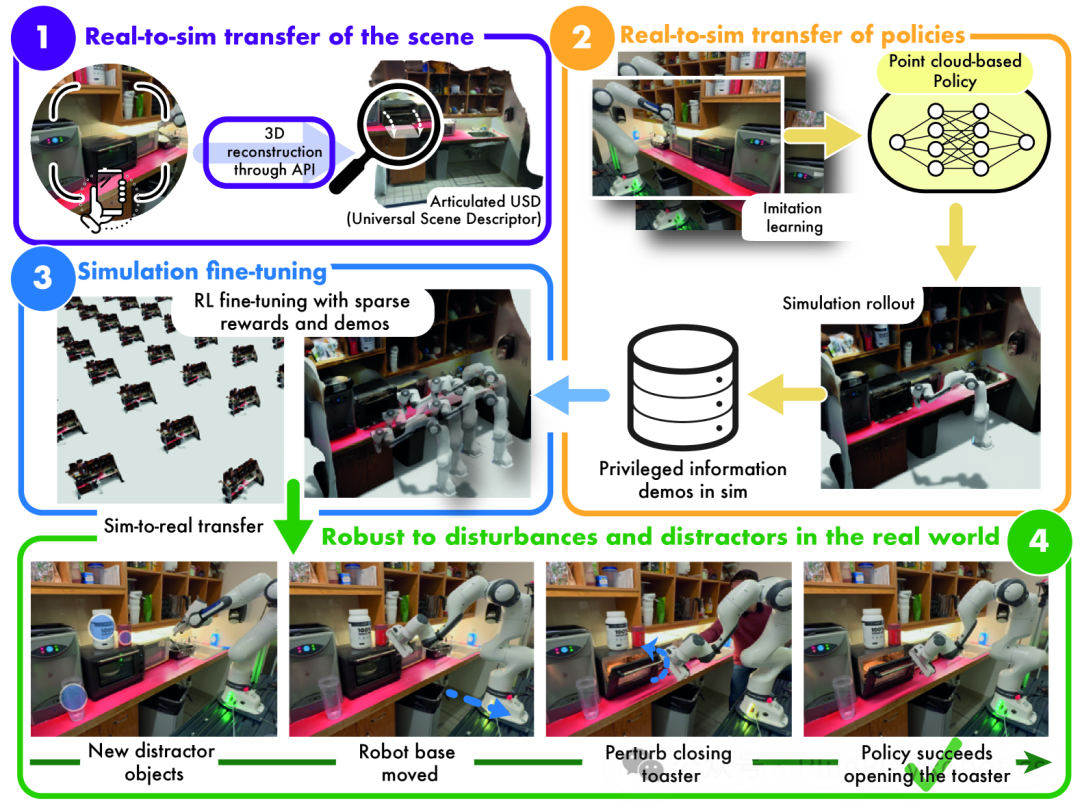
研究员 Pulkit Agrawal 在与研究相关的视频中表示:"在虚拟世界中进行模拟训练非常有效,因为机器人可以练习数百万次。它可能打碎了一千个盘子,但这并不重要,因为一切都在虚拟世界中。"然而,就像机器人本身一样,当涉及到家庭等动态环境时,模拟只能达到一定程度。使模拟变得像手机扫描一样容易,可以大大提高机器人对不同环境的适应性。
事实上,创建一个足够强大的环境数据库最终会使系统在出现某些不可避免地移位的情况时更具适应性,无论是移动一件家具还是将盘子留在厨房柜台上。
"我们的目标是让机器人在单一环境中,在干扰、干扰、不同的光照条件和物体姿势变化的情况下,都能表现出色,"麻省理工学院 CSAIL 的 Improbable AI 实验室研究助理、最近一篇关于这项工作的论文的主要作者 Marcel Torne Villasevil 说道。"我们提出了一种利用计算机视觉领域的最新进展来动态创建数字孪生的方法。只需使用手机,任何人都可以捕捉现实世界的数字复制品,而且得益于 GPU 并行化,机器人可以在模拟环境中比现实世界更快地进行训练。我们的方法通过利用一些现实世界的演示来启动训练过程,从而消除了对大量奖励工程的需求。"
当然,RialTo 比简单地挥动手机(砰!)即可让家用机器人为您服务要复杂一些。首先,它使用您的设备通过 NeRFStudio、ARCode 或 Polycam 等工具扫描目标环境。重建场景后,用户可以将其上传到 RialTo 的界面进行详细调整,为机器人添加必要的关节等。

经过改进的场景被导出并带入模拟器。在这里,目标是根据现实世界的动作和观察制定策略,例如从柜台上抓取杯子的策略。这些现实世界的演示在模拟中被复制,为强化学习提供了一些有价值的数据。"这有助于创建一个在模拟和现实世界中都行之有效的强大策略。使用强化学习的增强算法有助于指导这一过程,以确保该策略在模拟器之外应用时有效,"Torne 说。
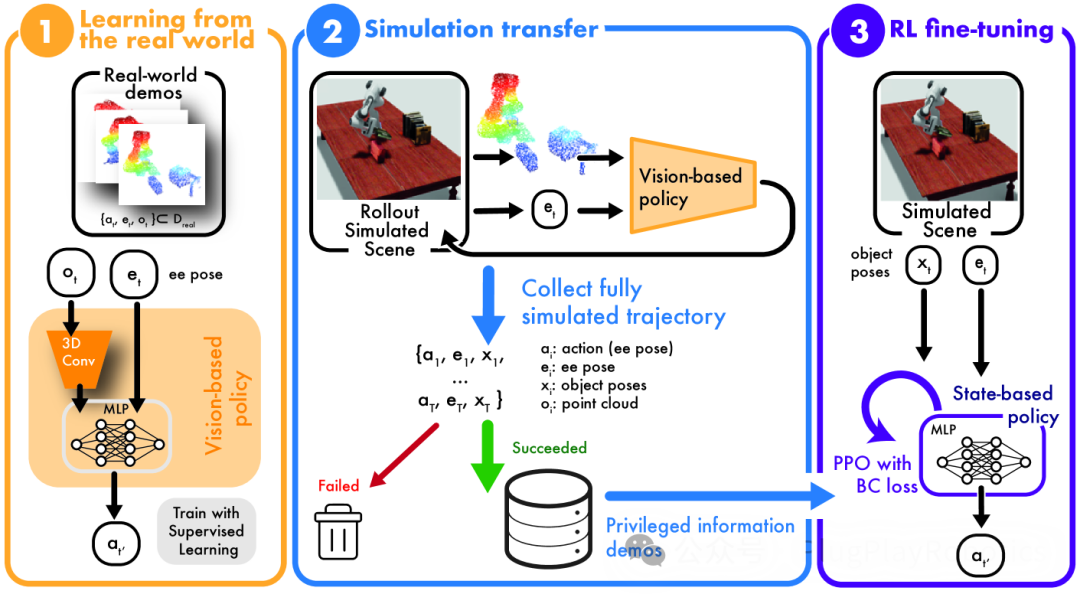
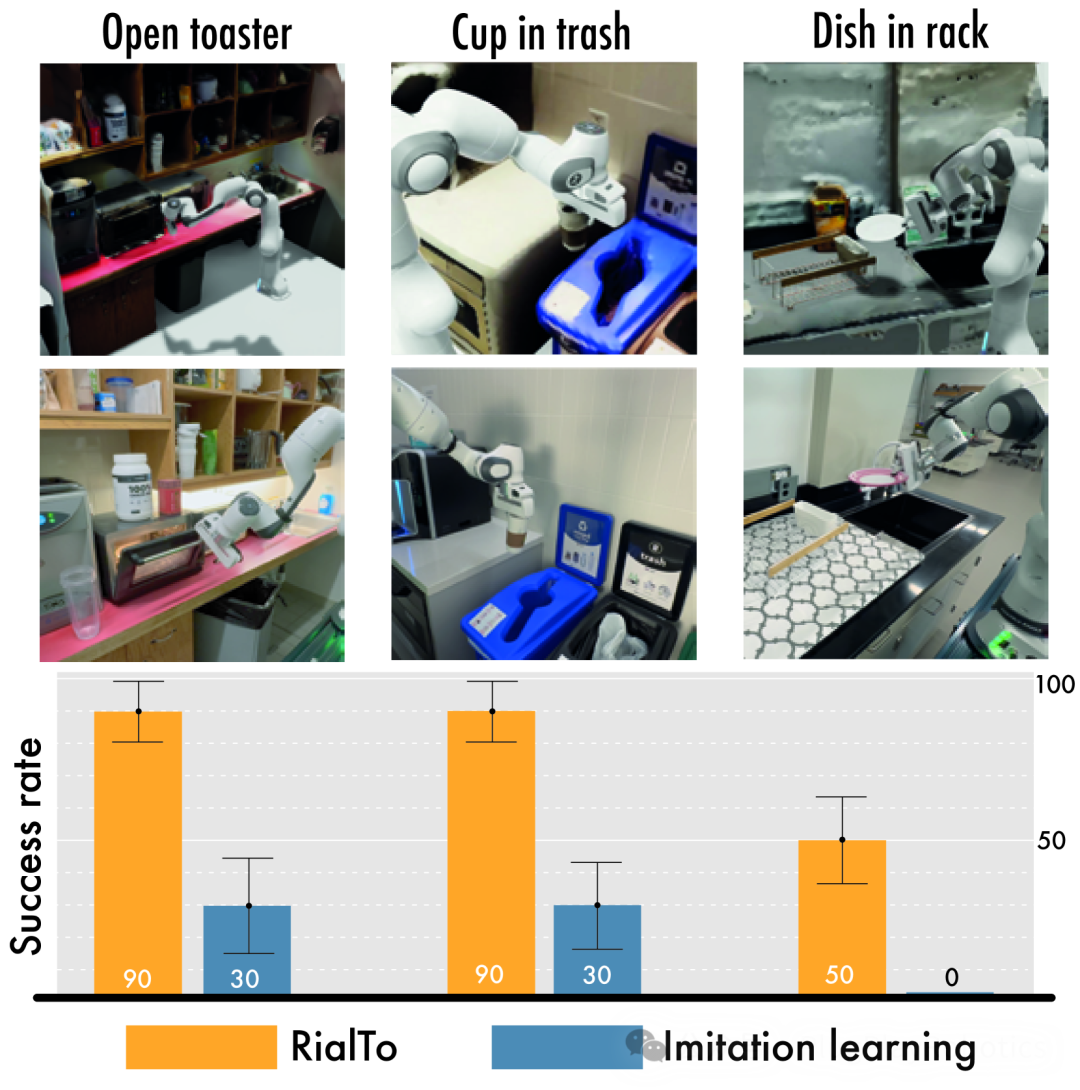
测试表明,无论是在受控的实验室环境中还是在更难以预测的现实环境中,RialTo 都能为各种任务制定强大的策略,在相同数量的演示下,其表现比模仿学习提高了 67%。这些任务包括打开烤面包机、将书放在书架上、将盘子放在架子上、将杯子放在架子上、打开抽屉和打开橱柜。对于每项任务,研究人员在三个难度不断增加的级别下测试了系统的性能:随机化物体姿势、添加视觉干扰物以及在任务执行过程中施加物理干扰。当与现实世界数据结合时,该系统的表现优于传统的模仿学习方法,尤其是在存在大量视觉干扰或物理干扰的情况下。
"这些实验表明,如果我们关心在某一特定环境中的稳健性,最好的想法是利用数字孪生,而不是试图通过在不同环境中进行大规模数据收集来获得稳健性,"不可思议的人工智能实验室主任、麻省理工学院电气工程与计算机科学 (EECS) 副教授、麻省理工学院 CSAIL 首席研究员、该研究的高级作者 Pulkit Agrawal 说。
参考完整视频 PNP机器人www.pnprobotics.com
麻省理工策略学习减轻操作员的负担缩小了 sim2real 差距
至于局限性,RialTo 目前需要三天时间才能完成全面训练。为了加快速度,该团队提到改进底层算法并使用基础模型。模拟训练也有其局限性,目前很难轻松实现模拟到现实的转移并模拟可变形物体或液体。
下一个层次
那么 RialTo 的下一步计划是什么呢?在之前努力的基础上,科学家们正在努力保持对各种干扰的稳健性,同时提高模型对新环境的适应性。"我们的下一步努力是使用预先训练的模型,加速学习过程,最大限度地减少人工输入,并实现更广泛的泛化能力,"Torne 说。

Torne 表示:"我们对我们的'即时'机器人编程概念非常热衷,机器人可以自主扫描周围环境并学习如何在模拟中解决特定任务。虽然我们目前的方法有局限性------例如需要人类进行一些初始演示,并且需要大量计算时间来训练这些策略(最多三天)------但我们认为这是实现'即时'机器人学习和部署的重要一步。""这种方法让我们更接近未来,机器人不需要预先存在的涵盖所有场景的策略。相反,它们可以在没有大量现实世界互动的情况下快速学习新任务。在我看来,与仅仅依赖通用的、包罗万象的策略相比,这一进步可以加速机器人技术的实际应用。"
"为了在现实世界中部署机器人,研究人员传统上依赖于从专家数据中进行模仿学习等方法,但这种方法成本高昂,或者强化学习可能不安全,"华盛顿大学计算机科学博士生 Zoey Chen 表示,他没有参与这篇论文。"RialTo 凭借其新颖的从真实到模拟到真实的管道,直接解决了现实世界 RL 机器人学习 的安全约束和数据驱动学习方法的有效数据约束。这种新颖的管道不仅可以确保在现实世界部署之前在模拟中进行安全而稳健的训练,还可以显著提高数据收集的效率。RialTo 有潜力显著扩大机器人学习的规模,让机器人能够更有效地适应复杂的现实世界场景。"
"通过为策略学习提供廉价、可能无限的数据,模拟在真实机器人上展现了令人印象深刻的能力,"华盛顿大学计算机科学博士生 Marius Memmel 补充道,他没有参与这项研究。"然而,这些方法仅限于一些特定场景,构建相应的模拟既昂贵又费力。RialTo 提供了一种易于使用的工具,可以在几分钟内重建真实环境,而不是几个小时。此外,它在策略学习过程中大量使用收集到的演示,最大限度地减轻了操作员的负担,并缩小了 sim2real 差距。RialTo 展示了对物体姿势和干扰的稳健性,无需大量模拟器构建和数据收集即可展示出令人难以置信的真实世界性能。"
Torne 与资深作者、华盛顿大学助理教授 Abhishek Gupta 和 Agrawal 共同撰写了这篇论文。其他四名 CSAIL 成员也获得了认可:EECS 博士生 Anthony Simeonov SM '22、研究助理 Zechu Li、本科生 April Chan 和 Tao Chen PhD '24。Improbable AI Lab 和 WEIRD Lab 成员也在开发该项目的过程中提供了宝贵的反馈和支持。
这项研究得到了索尼研究奖、美国政府和现代汽车公司的部分支持,并得到了华盛顿具身智能和机器人开发实验室 (WEIRD) 的协助。研究人员在2024年机器人科学与系统 (RSS 2024) 会议上展示了他们的研究成果。