摘要:《蓝耘元生代MaaS平台实践指南》摘要:本文详细介绍了蓝耘元生代MaaS平台的使用体验,该平台提供包括NLP、CV等多个领域的预训练模型服务,并赠送千万Token福利。文章涵盖从注册获取APIKey到实际应用的全流程:1)解析API工作流调用原理;2)提供Python和cURL两种调用方式示例;3)分享知识库建立和智能客服系统构建的实战经验;4)总结Token优化技巧如精简输入、参数调优等。平台通过标准化服务降低AI开发门槛,为开发者提供高效便捷的模型调用体验,助力各行业数字化转型。
1.蓝耘元生代 MaaS 平台初印象
在 AI 技术日新月异的当下,大语言模型已成为推动产业变革的中流砥柱,各类 MaaS(Model as a Service)平台如繁花般竞相涌现,而蓝耘元生代 MaaS 平台便是其中的佼佼者,备受瞩目。作为一名对前沿 AI 技术满怀热忱、时刻关注行业动态的入门博主 ,当得知蓝耘平台推出免费赠送超千万 Token 的重磅福利活动时,我内心的探索欲望瞬间被点燃,迫不及待地想要深入其中,一探究竟。
蓝耘元生代 MaaS 平台在 AI 领域的定位可谓独树一帜,它创新性地采用云计算平台模式,将训练有素、性能卓越的 AI 模型以标准化服务的形式,毫无保留地呈现给广大用户。其预训练模型库堪称一座知识的宝库,广泛涵盖了自然语言处理、计算机视觉、语音识别等多个关键领域 。这就意味着,用户无需再从零基础开始漫长而艰辛的模型训练过程,大大节省了宝贵的时间和资源,宛如为 AI 应用开发铺设了一条高速公路,极大地降低了开发门槛,让业务创新得以加速前行,为各行业的数字化转型注入了源源不断的强大动力。
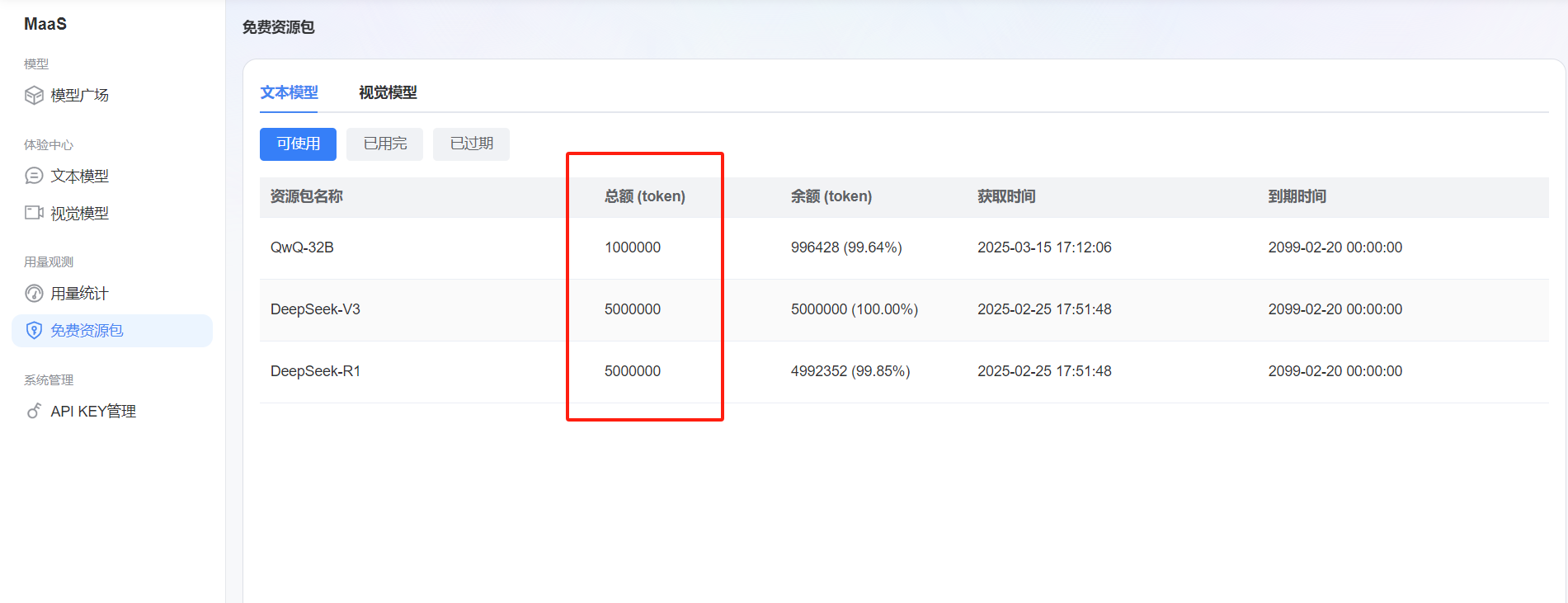
2.注册与准备,开启探索
在正式开启蓝耘元生代 MaaS 平台的探索之旅前,首先需要完成注册和一些关键的准备工作。
进入蓝耘元生代智算云平台的官方注册网站(注册入口)。在这里,需要填写一系列必要的信息,如用手机号码和验证码等。注册后可设置用户名要简洁且易于记忆,密码需设置为包含字母、数字和特殊字符的高强度组合,以保障账号安全。手机号码用于接收验证码,邮箱则会在后续用于接收平台的重要通知和操作确认邮件。
完成注册并登录后,就来到了平台的控制台。接下来,要获取至关重要的 API Key,它就像是进入 API 世界的通行证,有了它才能调用平台的各种强大功能。
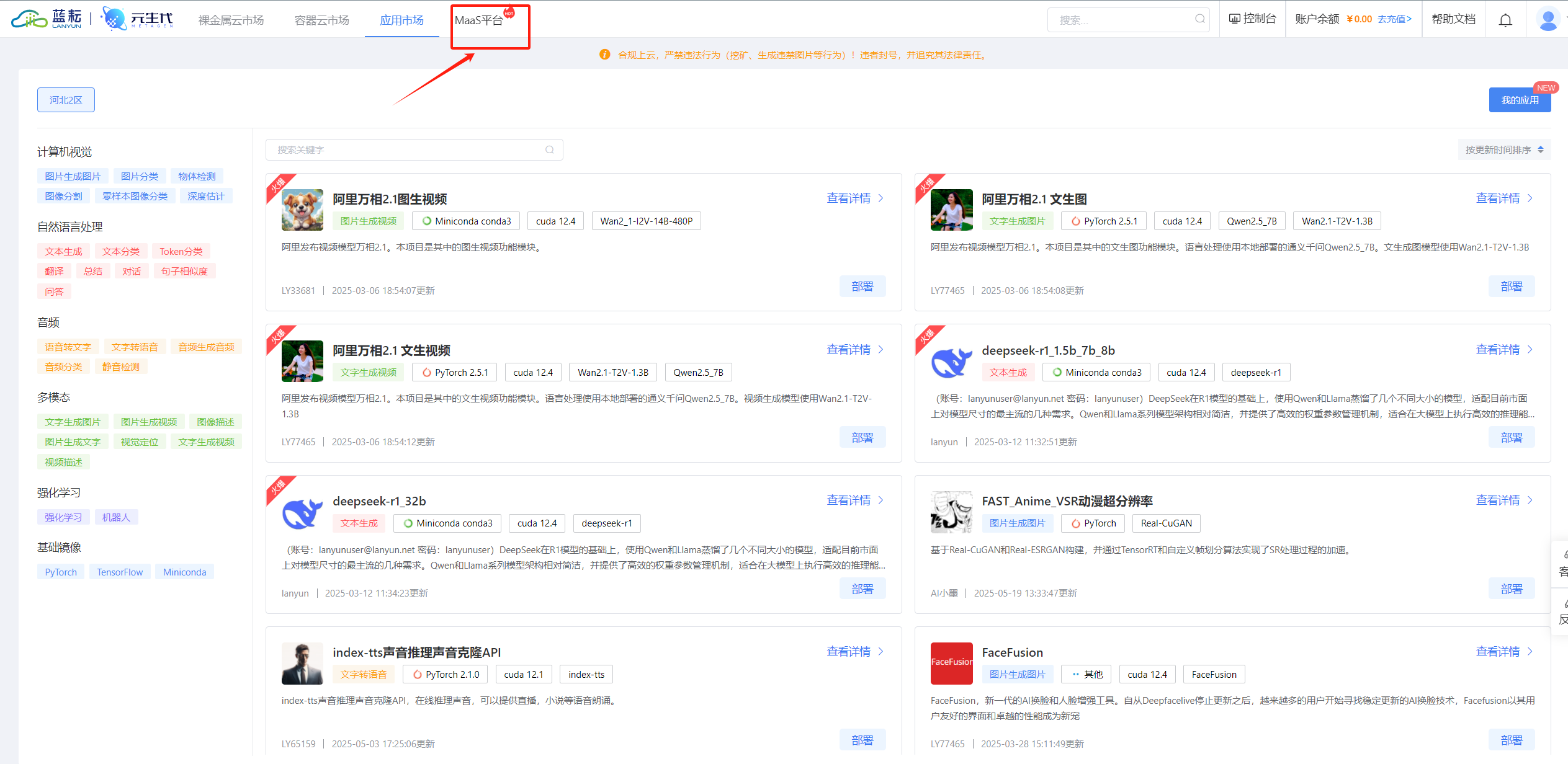 在控制台中找到 "MaaS平台" 选项,点击进入界面,在这里可以看到 "创建 API KEY" 的按钮,点击即可生成属于自己的 API Key。
在控制台中找到 "MaaS平台" 选项,点击进入界面,在这里可以看到 "创建 API KEY" 的按钮,点击即可生成属于自己的 API Key。
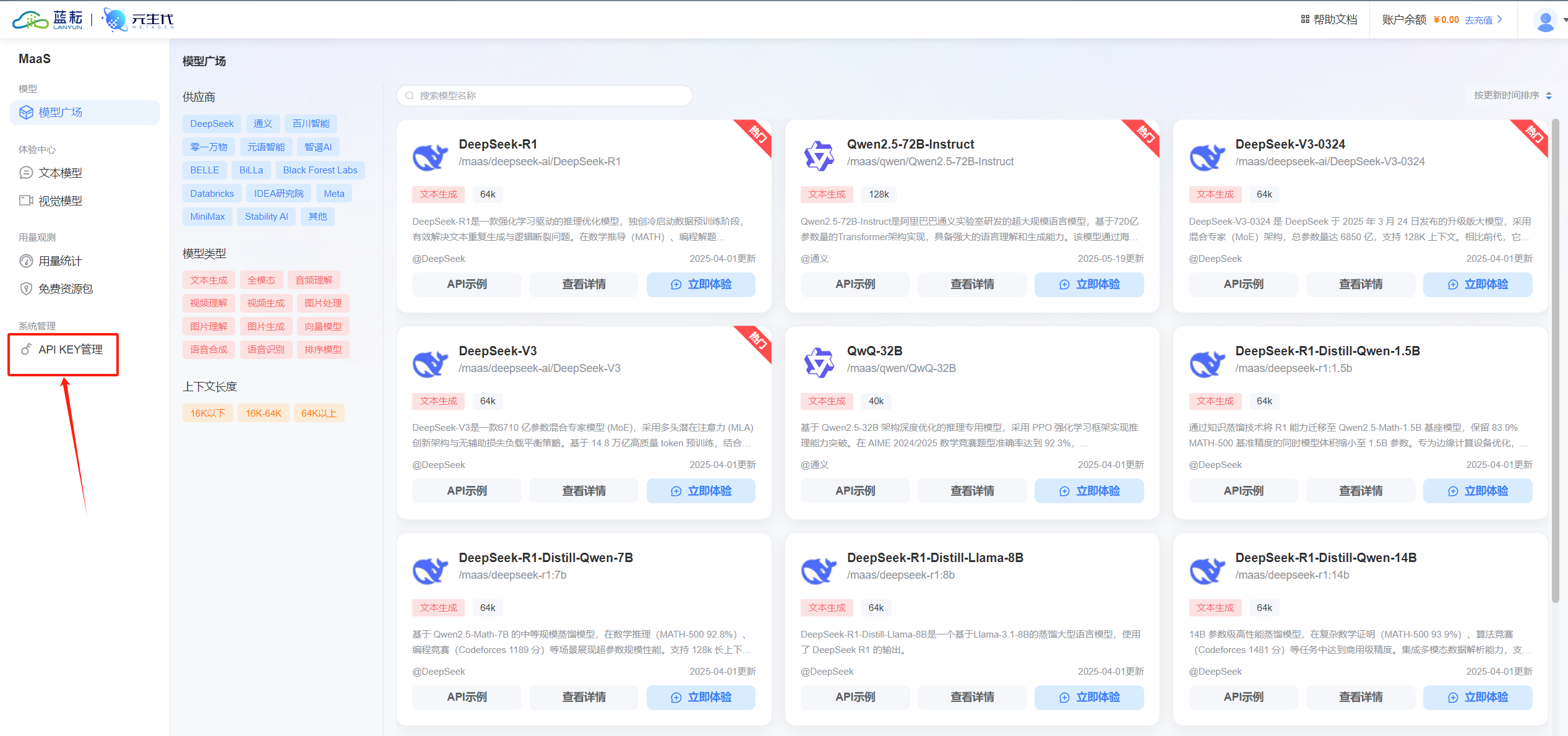
请务必妥善保管这个 Key,一旦泄露,可能会导致 API 调用权限被滥用,带来不必要的麻烦。
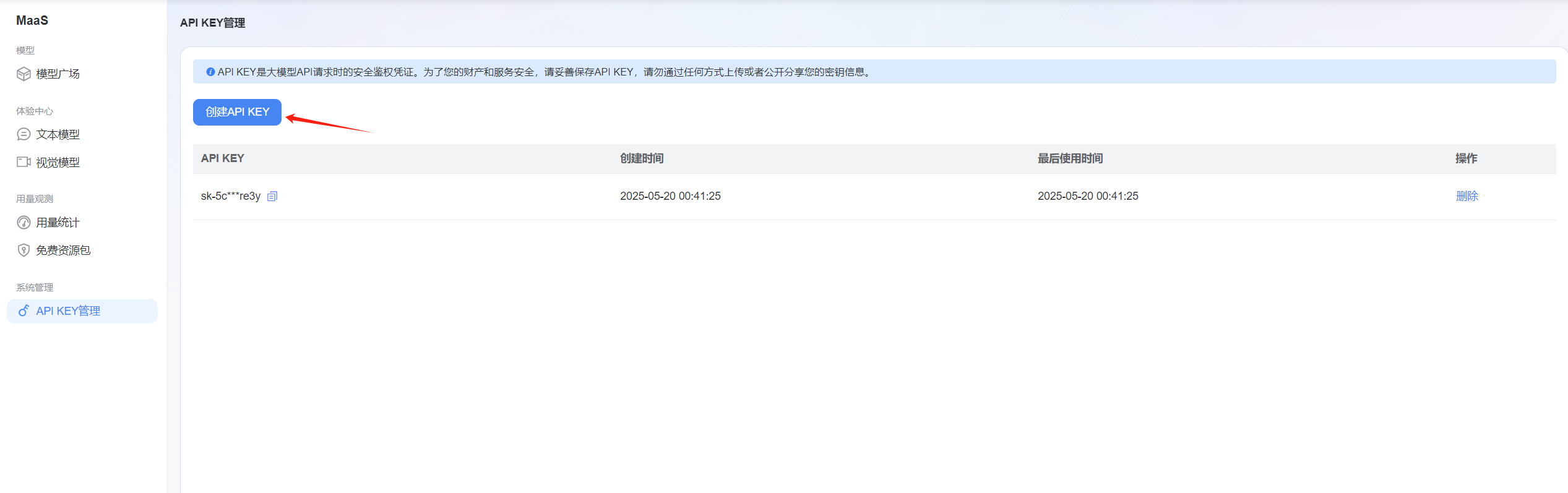
再次特别提醒,API Key 关乎账号安全与服务使用权限,务必妥善保管,绝不可通过任何方式上传或公开分享,就像守护珍贵的宝藏一样守护好它。
3.API 工作流调用核心解析
(一)调用原理深度剖析
蓝耘元生代 MaaS 平台的 API 工作流调用,本质上是一种让不同软件组件之间进行沟通协作的机制。就好比一个交响乐团,每个乐手(功能模块)都有自己独特的技能和职责,但要演奏出和谐美妙的音乐,就需要通过指挥(API 工作流)来协调。当你发出一个 API 调用请求时,就像是指挥给某个乐手发出指令,这个指令会沿着既定的路径(接口规范)传递过去。相关的功能模块接收到请求后,会根据请求的内容(参数)进行相应的处理,然后再将处理结果沿着原路返回给你。在这个过程中,数据就像是乐团演奏的音符,在不同模块之间流动。
比如在一个文本处理的场景中,你调用 API 将一段文本发送给自然语言处理模块,该模块会对文本进行分析、理解,然后返回分析结果,如文本的情感倾向、关键词等 。这种调用原理使得平台的各个功能模块能够紧密配合,实现复杂的业务逻辑,让用户能够高效地利用平台的强大功能,快速搭建和定制自己的 AI 应用。
(二)调用方式详细讲解
- Python 代码调用:Python 以其简洁易读的语法和丰富的库,成为了调用 API 的常用语言之一。在蓝耘元生代 MaaS 平台,使用 Python 调用 API 也非常便捷。首先,需要安装openai库,因为蓝耘平台提供了 OpenAI 兼容接口。可以使用pip命令进行安装:
bash
pip install openai安装完成后,就可以编写代码来调用 API 了。下面是一个简单的示例,使用蓝耘平台的 DeepSeek - R1 模型进行对话(文件名:maas-deepseek-r1.py):
python
from openai import OpenAI
# 构造client,填入你的API Key和蓝耘平台的base_url
client = OpenAI(api_key="sk-xxxxxxxxxxx", base_url="https://maas-api.lanyun.net/v1")
# 流式响应设置
stream = True
# 发起请求
chat_completion = client.chat.completions.create(
model="/maas/deepseek-ai/DeepSeek-R1",
messages=[
{"role": "user", "content": "请介绍一下Python语言的特点"}
],
stream=stream
)
if stream:
for chunk in chat_completion:
# 打印思维链内容
if hasattr(chunk.choices[0].delta,'reasoning_content'):
print(f"{chunk.choices[0].delta.reasoning_content}", end="")
# 打印模型最终返回的content
if hasattr(chunk.choices[0].delta, 'content'):
if chunk.choices[0].delta.content != None and len(chunk.choices[0].delta.content) != 0:
print(chunk.choices[0].delta.content, end="")
else:
result = chat_completion.choices[0].message.content在这段代码中,首先创建了一个OpenAI客户端实例,设置了 API Key 和平台的基础 URL。然后通过client.chat.completions.create方法发起对话请求,指定使用的模型、输入的消息以及是否采用流式响应。如果是流式响应,就可以逐块地处理模型返回的结果。
2.cURL 命令调用:cURL 是一个命令行工具,用于发送 HTTP 请求,也可以方便地用于调用 API。以下是使用 cURL 调用蓝耘平台 API 的命令示例
python
curl https://maas-api.lanyun.net/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxx" \
-d '{
"model": "/maas/deepseek-ai/DeepSeek-R1",
"messages": [
{"role": "user", "content": "请介绍一下Python语言的特点"}
]
}'在这个命令中:
- https://maas-api.lanyun.net/v1/chat/completions 是 API 的端点,表示要访问的具体接口地址。
- -H "Content-Type: application/json" 用于设置请求头,表明发送的数据是 JSON 格式。
- -H "Authorization: Bearer sk-xxxxxxxxxxx" 用于设置身份验证,sk-xxxxxxxxxxx 是之前获取的 API Key,Bearer 是一种常见的认证方式 。
- -d '{...}' 用于传递请求体数据,包含了要使用的模型以及输入的消息内容。
4.实际应用场景实操
(一)知识库建立实战
-
资料采集与清洗 :在建立知识库时,资料采集是第一步。我从多个渠道收集资料,包括公司内部文档、行业报告、学术论文以及在线论坛等。这些资料的格式各不相同,有 PDF、Word、Excel,还有网页格式 。为了将这些资料转化为平台可处理的格式,我使用了一些开源工具。比如,对于 PDF 文件,我使用pdfminer库将其转换为文本;对于 Word 文件,则使用python - docx库进行处理。在清洗资料时,我遇到了很多问题,像文本中存在大量的无用空格、特殊字符以及重复内容等。为了解决这些问题,我借助正则表达式进行处理。例如,使用re.sub(r'\s+', ' ', text)去除多余的空格,其中r'\s+'表示匹配一个或多个空白字符,' '表示替换成一个空格。对于重复内容,我先将文本按行分割,然后使用集合(set)数据结构去除重复行,代码如下:
pythonlines = text.split('\n') unique_lines = list(set(lines)) cleaned_text = '\n'.join(unique_lines) -
知识分层与标签体系设计:为了让知识库更有条理,便于检索,我设计了一个分层结构。最底层是基础层,存储一些通用的基础知识,比如编程语言的基本语法、行业的基本概念等,这部分内容是整个知识库的基石,更新频率较低,但访问频率较高 。中间层是专业层,针对不同的业务领域或专业方向,存储更深入、更专业的知识,像特定项目的技术方案、业务流程等 。最上层是动态层,用于存放实时性较强的信息,如最新的行业动态、热点问题解答等,这部分内容需要定期更新。同时,我还根据业务需求设计了一套标签体系。比如,对于技术相关的知识,我会添加 "技术""编程""算法" 等标签;对于业务流程相关的内容,添加 "业务流程""项目管理" 等标签 。在实际应用中,一个知识条目可能会被打上多个标签,这样在检索时可以通过多个维度进行筛选,大大提高了检索的准确性和灵活性。
-
批量导入与分批策略:利用蓝耘平台的 API 进行批量导入数据时,我发现直接上传大文件可能会导致请求超时或内存溢出等问题。于是,我采用了分批上传的策略。首先,将大的文档拆分成多个小的段落或章节,每个小部分作为一个独立的记录进行上传。例如,对于一篇很长的技术文档,我会按照章节将其拆分成多个文件,然后编写 Python 脚本来实现分批上传。以下是一个简单的示例代码:
python
import requests
import json
api_key = "sk-xxxxxxxxxxx"
base_url = "https://maas-api.lanyun.net/v1/knowledgebase"
headers = {
"Content - Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data_chunks = [] # 假设已经将数据拆分成多个小部分并存储在这个列表中
for chunk in data_chunks:
data = {
"content": chunk,
"tags": ["技术", "文档"] # 为每个数据块添加相应的标签
}
response = requests.post(f"{base_url}/import", headers = headers, data = json.dumps(data))
if response.status_code != 200:
print(f"上传失败,状态码: {response.status_code},错误信息: {response.text}")在这个过程中,需要注意的是要合理控制每批上传的数据量,根据网络状况和平台的响应速度进行调整,避免因上传过于频繁或数据量过大导致接口报错。同时,要对上传结果进行实时监控,及时处理上传失败的情况,比如记录失败的批次和原因,以便后续进行重试。
(二)智能客服应答构建
- 系统设计理念与结构:智能客服系统的设计理念是为了快速、准确地回答用户的问题,提高客户服务效率和质量。其整体结构主要包括前端交互界面、意图识别模块、知识检索模块、答案生成模块以及对话管理模块。前端交互界面负责与用户进行交互,接收用户输入的问题,并将智能客服生成的回答展示给用户;意图识别模块运用自然语言处理技术,分析用户问题的意图,判断用户是在查询信息、寻求帮助还是进行投诉等;知识检索模块根据意图识别的结果,在知识库中查找相关的知识;答案生成模块将检索到的知识进行整合和处理,生成最终的回答;对话管理模块则负责管理对话的上下文,确保多轮对话的连贯性和逻辑性。
- 工作流调用设计实操:工作流调用的设计是智能客服系统的关键。当用户输入问题后,首先由意图识别模块调用蓝耘平台的自然语言处理 API 进行意图识别。例如,使用以下代码调用意图识别接口:
python
import requests
import json
api_key = "sk-xxxxxxxxxxx"
intent_url = "https://maas-api.lanyun.net/v1/nlp/intent - recognition"
headers = {
"Content - Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
user_question = "我想了解Python语言的特点"
data = {
"question": user_question
}
response = requests.post(intent_url, headers = headers, data = json.dumps(data))
if response.status_code == 200:
intent = response.json()["intent"]
else:
print(f"意图识别失败,状态码: {response.status_code},错误信息: {response.text}")得到意图后,知识检索模块根据意图在知识库中进行检索。这里会调用平台的知识库检索 API,通过传入意图和相关的关键词,获取匹配的知识内容 。最后,答案生成模块将检索到的知识进行整理,生成回答返回给用户。在这个过程中,要注意各个模块之间的数据传递和参数设置,确保工作流的顺畅运行。
- 多轮问答上下文管理:在多轮问答中,上下文管理非常重要。为了实现上下文管理,我使用了一个对话状态管理器。它会记录每一轮对话的信息,包括用户的问题、系统的回答以及当前的对话状态等。当用户进行下一轮提问时,对话状态管理器会将之前的对话信息作为上下文传递给意图识别模块和答案生成模块,以便系统更好地理解用户的问题。例如,用户第一轮提问 "苹果手机怎么设置指纹解锁?",系统回答后,用户第二轮提问 "那面部识别呢?",此时对话状态管理器会将第一轮的问题和回答作为上下文传递给意图识别模块,这样意图识别模块就能明白用户的问题是在询问苹果手机的面部识别设置,而不是一个孤立的问题。在代码实现上,可以使用一个字典来存储对话状态信息,每次对话更新字典内容,并在需要时将字典作为参数传递给相关模块。
- 代码示例与解读:以下是一个简单的智能客服系统关键代码示例(使用 Python 和 Flask 框架):
python
from flask import Flask, request, jsonify
import requests
import json
app = Flask(__name__)
api_key = "sk-xxxxxxxxxxx"
intent_url = "https://maas-api.lanyun.net/v1/nlp/intent - recognition"
knowledge_url = "https://maas-api.lanyun.net/v1/knowledgebase/search"
headers = {
"Content - Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
@app.route('/chat', methods=['POST'])
def chat():
data = request.json
user_question = data.get('question')
# 意图识别
intent_data = {
"question": user_question
}
intent_response = requests.post(intent_url, headers = headers, data = json.dumps(intent_data))
if intent_response.status_code != 200:
return jsonify({"answer": "意图识别失败,请稍后重试"}), 500
intent = intent_response.json()["intent"]
# 知识检索
knowledge_data = {
"intent": intent,
"keywords": user_question
}
knowledge_response = requests.post(knowledge_url, headers = headers, data = json.dumps(knowledge_data))
if knowledge_response.status_code != 200:
return jsonify({"answer": "知识检索失败,请稍后重试"}), 500
knowledge = knowledge_response.json()["knowledge"]
# 答案生成,这里简单返回检索到的知识,实际应用中可能需要更复杂的处理
answer = knowledge
return jsonify({"answer": answer})
if __name__ == '__main__':
app.run(debug=True)在这段代码中,Flask框架搭建了一个简单的 Web 服务,/chat路由处理用户的聊天请求。首先获取用户的问题,然后调用意图识别接口得到意图,再根据意图和问题关键词调用知识检索接口获取知识,最后将检索到的知识作为答案返回给用户。
3.异常容错与转人工设计:在智能客服系统运行过程中,难免会遇到各种异常情况,比如 API 调用失败、无法理解用户问题等。为了应对这些情况,我设计了异常容错机制。当出现 API 调用失败时,系统会记录错误信息,并返回一个友好的提示给用户,告知用户暂时无法提供服务,请稍后重试 。对于无法理解的用户问题,系统会根据预设的规则进行处理,比如提示用户重新表述问题,或者提供一些常见问题的链接供用户参考。同时,为了保证服务的质量,我还设计了自动转人工服务的功能。当系统检测到连续多次无法准确回答用户问题,或者用户主动要求转人工时,会将对话转接给人工客服。在代码实现上,可以通过设置一个计数器来记录系统回答错误的次数,当次数超过一定阈值时,触发转人工服务的逻辑。例如:
python
error_count = 0
# 在每次回答错误时,error_count加1
if response.status_code != 200:
error_count += 1
if error_count >= 3:
# 触发转人工服务逻辑,这里可以是调用转人工服务的API
return jsonify({"answer": "很抱歉,无法准确回答您的问题,已为您转接人工客服"})5.Token 使用技巧与心得
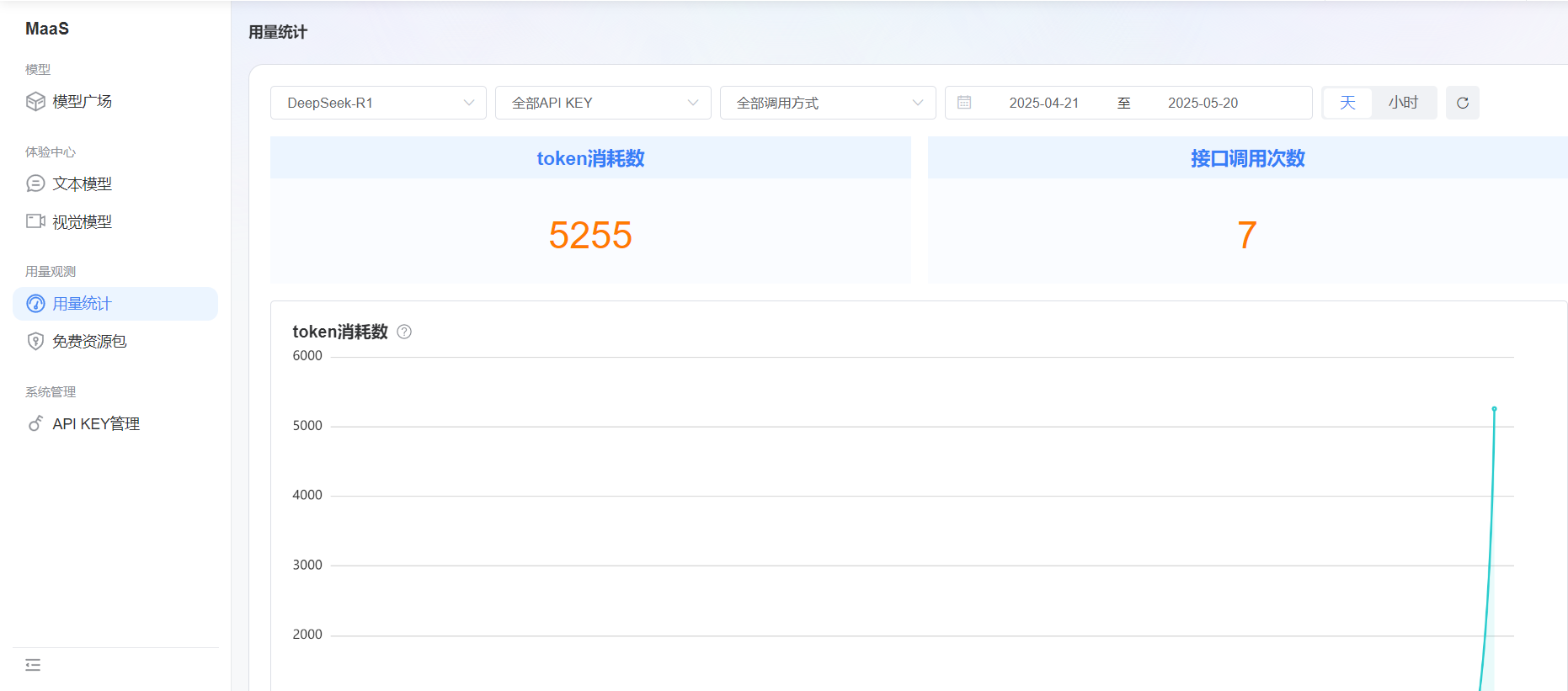
在蓝耘元生代 MaaS 平台的使用过程中,Token 作为计费的关键单位,其使用效率直接关系到使用成本和项目的可持续性。经过这段时间的实践,我总结了一些实用的 Token 使用技巧。
精简输入文本是减少 Token 消耗的有效方法之一。在向模型发送请求时,避免冗长、无关紧要的表述,确保输入的文本简洁明了,直击重点。比如在进行文本摘要时,先对原始文本进行预处理,去除重复的段落、多余的修饰词等,这样可以在不影响模型理解的前提下,大大减少输入文本的 Token 数量。
合理设置模型参数也能优化 Token 的使用。以生成文本为例,不同的温度(temperature)参数会影响模型生成文本的随机性和多样性 。当温度设置较高(如 0.8 - 1.0)时,模型生成的文本更加随机、富有创意,但往往会产生更长的回复,从而消耗更多的 Token;而将温度设置较低(如 0.2 - 0.4),生成的文本更加保守、确定性更强,回复长度相对较短,Token 消耗也会相应减少。在实际应用中,要根据具体需求来调整温度参数。如果是创作诗歌、故事等需要较高创意的场景,可以适当提高温度;而对于一些对准确性和简洁性要求较高的任务,如问答系统、信息提取等,降低温度能有效节省 Token。
在进行多轮对话时,维护好对话的上下文至关重要。蓝耘平台支持在对话中携带上下文信息,通过合理利用这一特性,可以减少重复信息的输入,从而降低 Token 的使用量。例如,在智能客服场景中,当用户进行追问时,将上一轮的对话内容作为上下文传递给模型,模型就能更好地理解用户的意图,而不需要用户再次重复描述相关背景信息。
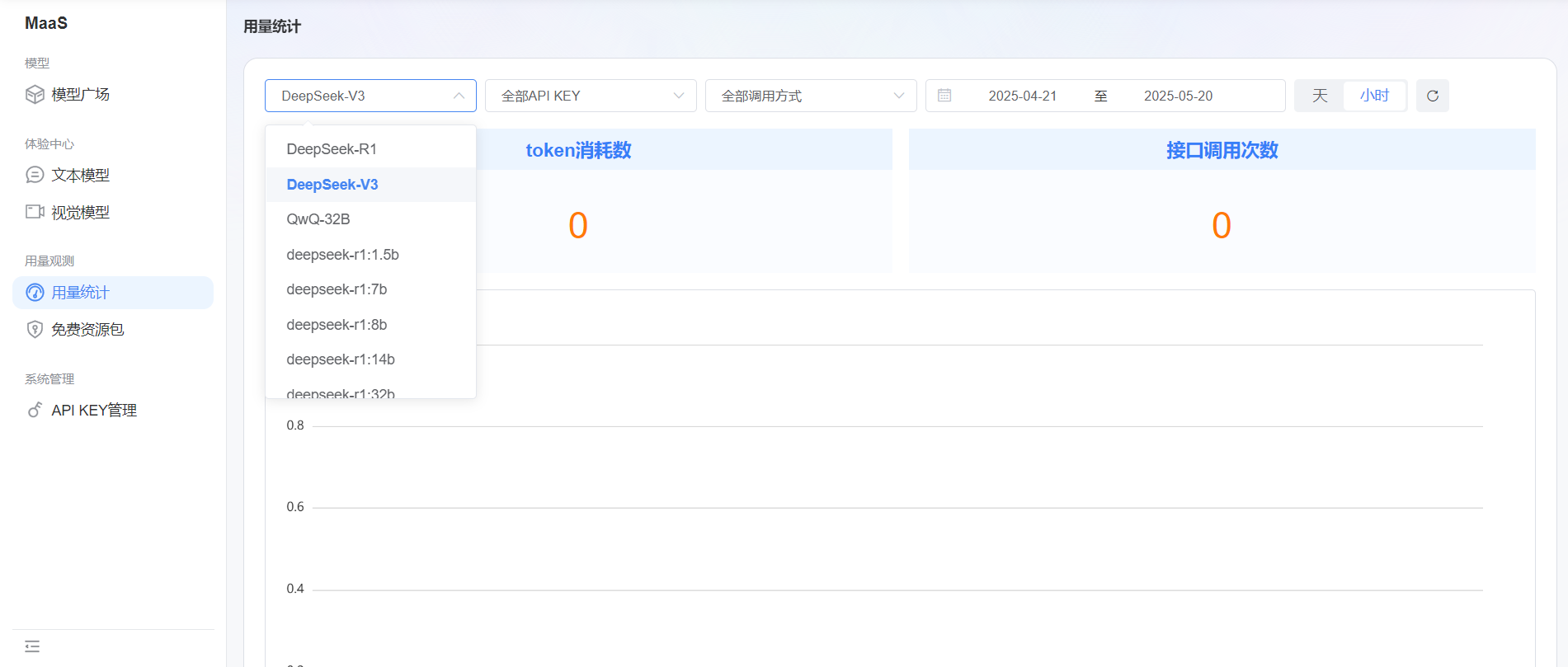
定期分析 Token 的使用情况,能帮助我们及时发现问题并调整策略。蓝耘平台提供了详细的 Token 使用记录,我们可以通过分析这些记录,了解不同任务、不同模型的 Token 消耗规律。比如发现某个特定的模型在处理某些类型的任务时,Token 消耗明显高于其他模型,就可以考虑是否更换模型或者优化任务流程。同时,根据 Token 的使用趋势,合理规划免费 Token 的使用进度,避免在项目关键阶段出现 Token 不足的情况 。

6.总结与展望
在这段时间对蓝耘元生代 MaaS 平台 API 工作流调用的探索和实践中,我真切地感受到了它为 AI 应用开发带来的巨大便利和无限可能 。从简洁高效的注册流程,到丰富多样、易于理解的 API 调用方式,再到在知识库建立、智能客服应答等实际应用场景中的出色表现,蓝耘平台都展现出了强大的实力和卓越的性能 。特别是平台免费赠送的超千万 Token,大大降低了使用门槛,让更多像我这样的 AI 入门者有机会深入体验和学习,也为企业和开发者在项目初期的测试与验证提供了充足的资源,无需为高昂的成本担忧 。
在实际操作过程中,每一个环节都充满了惊喜和收获。通过不断地尝试和优化,我逐渐掌握了 API 工作流调用的技巧,能够更加灵活地运用平台的功能,实现自己的创意和想法。同时,蓝耘平台还提供了详细的文档和示例代码,以及活跃的社区支持,让我在遇到问题时能够快速找到解决方案,不断提升自己的技术能力 。
展望未来,随着 AI 技术的持续发展和应用场景的不断拓展,相信蓝耘元生代 MaaS 平台会不断进化和完善。期待平台能够推出更多先进的模型和功能,进一步优化 API 的性能和稳定性,降低调用延迟,提高响应速度;在安全性和隐私保护方面,能够提供更加强有力的保障措施,让用户更加放心地使用 。同时,希望平台能够加强与其他技术和平台的融合,打造更加开放、多元的生态系统,为开发者提供更多的创新空间和合作机会 。
如果你也对 AI 技术充满热情,渴望探索和实践,不妨加入蓝耘元生代 MaaS 平台的大家庭,亲自体验它的魅力和优势。相信你也会像我一样,在这个充满机遇和挑战的领域中,收获满满,开启属于自己的 AI 创新之旅 !
关键词解释
-
MaaS(Model as a Service):模型即服务,将训练好的 AI 模型以服务形式提供给用户,用户无需从零开始训练模型,可直接调用模型完成任务。
-
API Key:应用程序接口密钥,是调用蓝耘平台 API 的通行证,用于身份验证与权限管理。
-
Token:计费与资源管理单位,根据输入输出文本内容分割成一个个 Token 进行统计,不同模型处理相同文本消耗的 Token 数量可能不同。
-
自然语言处理(NLP):AI 领域分支,使计算机能够理解、解释和生成人类语言,如文本分析、情感判断等。
-
预训练模型:预先训练好的模型,用户可直接使用或微调,节省时间和资源,如 DeepSeek - R1 模型。
-
流式响应:API 返回结果的方式,将结果分成多个数据块逐步返回,便于实时处理和展示。
-
OpenAI 兼容接口:蓝耘平台提供的与 OpenAI 接口兼容的调用方式,方便用户使用熟悉的工具和库进行开发。
-
知识库:存储特定领域知识的数据集合,通过 API 调用模型对知识库数据进行处理,实现智能问答等功能。
-
智能客服:基于 AI 技术实现的客户服务系统,能够自动回答用户问题,提供7×24小时不间断服务。
-
断点续传:在网络中断后,从上次中断位置继续加载数据的功能,节省时间和资源。

相关文章推荐:
1、AI新势力!蓝耘DeepSeek满血版登场,500万tokens免费开薅
2、探索Maas平台与阿里 QWQ 技术:AI调参的魔法世界
3、元生代品牌建设:平台实现工作流(comfyui)创建与技术文档说明
6、BlueCloud Platform携手DeepSeek:开启AI应用新征程
8、蓝耘元生代MaaS平台API实战:解锁千万Token福利,体验DeepSeek-R1基础大模型,开启智能应用新篇
蓝耘元生代智算云平台的官方注册: