前言
提起大数据,就会觉得很厉害,将众多的数据整合在一起,在有条理的呈现在屏幕前的我们。有时候可能会想到底是什么在支撑着大数据,大数据的出现,方便了我们日常生活中的方方面面。那这些海量的数据计算机是怎么存储和分析的呢,那就要引出一个大数据底层支撑平台------hadoop。hadoop具有处理海量数据,支撑多种数据格式,以及快速响应等功能,为数据的挖掘提供工具。
1、安装环境
由于资源有限,使用VMware创建虚拟机,搭建虚拟环境。ubuntu 22.04版本,hadoop3.4.0版本,Jdk8u451版本(jdk版本和hadoop版本一定相互兼容,不然很容易出问题)
hadoop和jdk的版本对照表(源自网上):
| Hadoop 版本范围 | 支持的 Java 版本 |
|---|---|
| Hadoop 3.3.x | Java 8 和 Java 11(仅运行时支持,编译需使用 Java 8) |
| Hadoop 3.0.x - 3.2.x | Java 8 |
| Hadoop 2.7.x - 2.10.x | Java 7 和 Java 8 |
| Hadoop 2.6.x及以下 | Java 6 |
| Hadoop 1.x | Java 6 |
2、安装Jdk8
2.1 本机在官网下载linux(x64位)的jdk8,然后通过ssh连接的软件(xshell或者mobaxterm),放入虚拟机ubuntu下的/opt目录,并解压至/usr/local下。jdk的官网地址:https://www.oracle.com/java/technologies/downloads/
cd /opt
mkdir /usr/local/java
tar -zxvf jdk-8u451-linux-x64.tar.gz -C /usr/local/java
cd /usr/local/java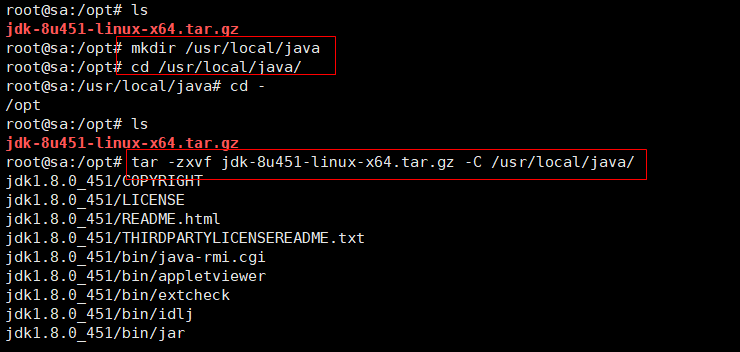
2.2 解压后,将Java加到环境变量当中,并生效
vim /etc/profile #在最末尾加上java的环境变量
#java
JAVA_HOME=/usr/local/java/jdk1.8.0_451 #java的绝对路径
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME
source /etc/profile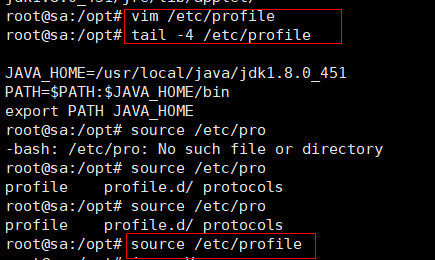
2.3 查看Java版本
java -version
3、安装hadoop
3.1 下载和解压hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
tar -zxf hadoop-3.4.0.tar.gz -C /usr/local #将hadoop的解压文件放在/usr/local下
cd /usr/local
mv ./hadoop-3.4.0 ./hadoop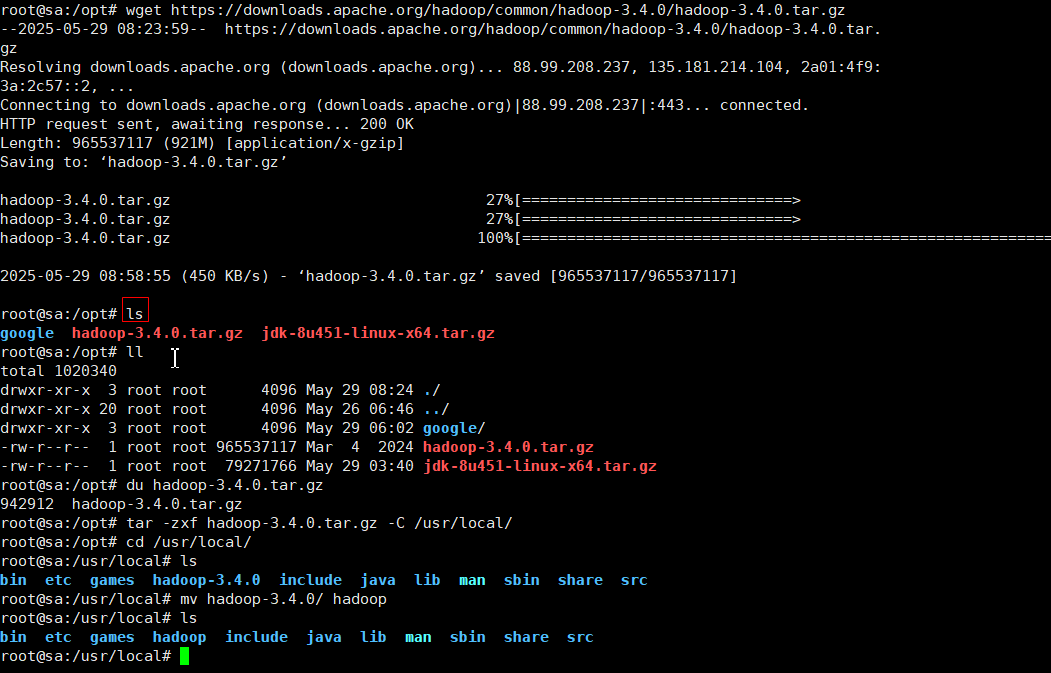
3.2 设置hadoop环境变量
vi /etc/profile
#文件内容:
export HADOOP_HOME=/usr/local/hadoop #指向hadoop的绝对路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
tail -2 /etc/profile
source /etc/profile
hadoop version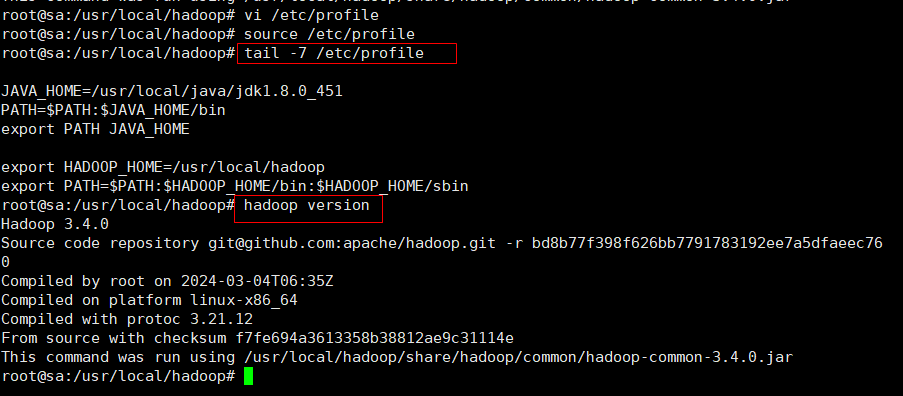
3.2 修改hadoop权限,改成普通用户。当前我的系统有一个普通用户sa
chown -R 自己选择一个用户名 ./hadoop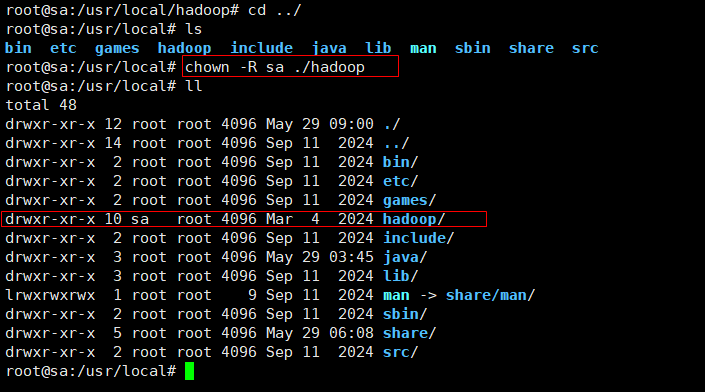
4、验证hadoop
4.1 安装完成后,Hadoop默认模式为非分布式模式, 即单java进程。运行一个grep例子,在hadoop目录下,创建输入文件夹input,并在其中添加测试文件,运行如下命令。
mkdir input
echo "dfsabc dfsefg dfsxyz dfs123" > input/file1.txt
echo "dfsabc dfsxyz dfs456" > input/file2.txt
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop- mapreduce-examples-3.4.0.jar grep input output 'dfs[a-z.]+' #在hadoop目录下执行程序

