0.前言
参考CSDN大佬(太阳花的小绿豆)的代码,梳理了一下vit的网络结构,代码地址如下:
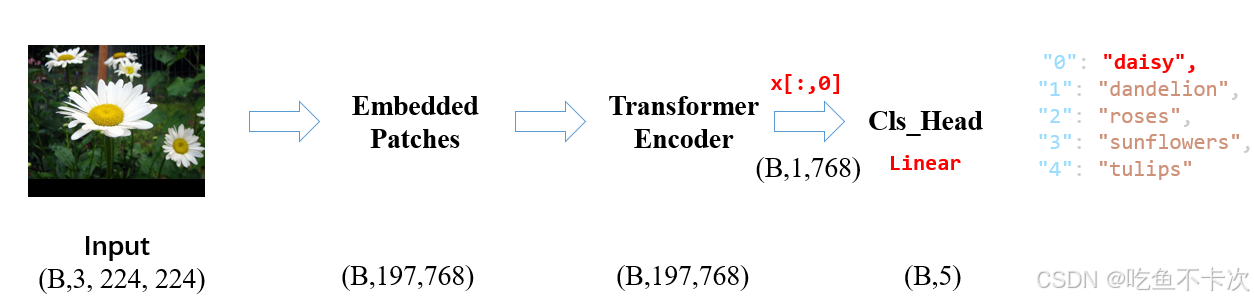
本文以ViT-Base model,img_size=224,patch_size=16为例子说明Vit的网络结构。
如下图所示,输出224x224尺寸的图片,需要依次经过Embedded Patches 、Transformer Encoder以及Cls_Head,最后输出图片对应的类别。
后面将按照这个顺序分别介绍这一过程。
1.Embedded Patches
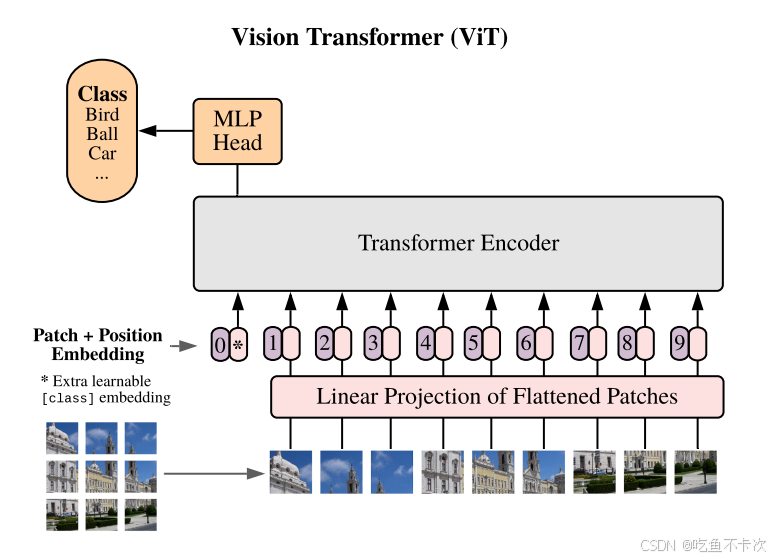
参考自Vit论文(https://arxiv.org/pdf/2010.11929)的插图,Embedded Patches的步骤如下:
(1)首先,输入一张图片,对该图片进行切分,得到互不重合的patch块,如下图所示该图片被切分成了9个patch;
(2)其次,再对这9个patch经过线性变化得到9个token;
(3)再次,在首位加上一个cls token,这个token最后是用来预测类别的,此时一共有10个token;
(4)最后,给每个token加上Position embedding位置编码后,将处理后的10个token作为Transformer Encoder模块的输入。
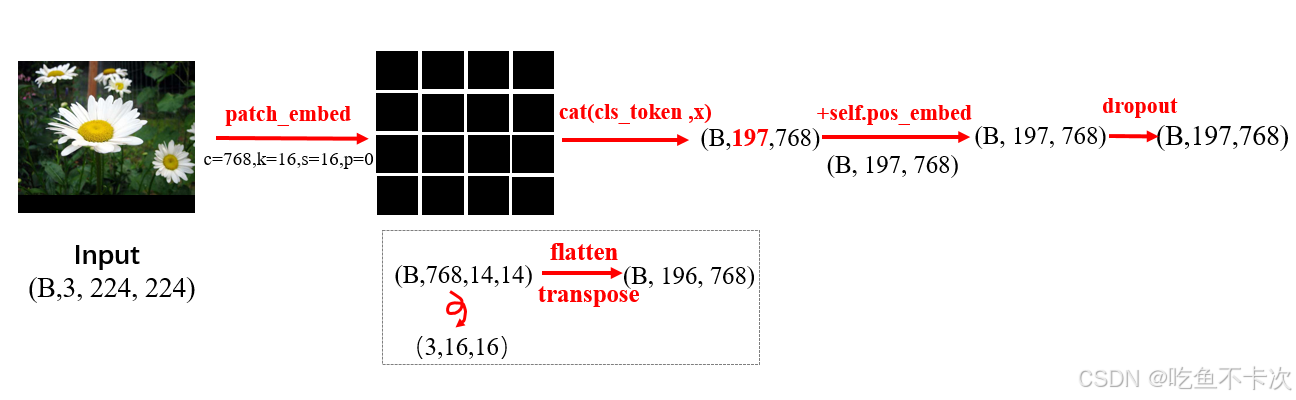
实际上在代码中,是通过卷积的方式将图片切分成一个个token,然后在首位加上一个cls token,以及给每个token补充一维位置编码信息,最后输出给Transformer Encoder模块。
下图是以ViT-Base model(img_size=224,patch_size=16)中Embedded Patches模块的处理流程,有几个需要注意的地方,path_embed和cls_token以及pose_embed,输入和输出的Shape是从(B,3,224,224)变化为(B,197,768),后面将详细来介绍这个流程。
1.1patch_embed
pathch_embed方法实现了对图片的切分及向量化(展平成一维),也就是前面的第(1)、(2)步骤,并且实现的方法也很简单,就是通过一个最常用的Conv2d卷积实现,由下图可知:该卷积核的输入、输出通道数分别为3和768,卷积核大小为16x16,步长也为16;
python
#Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)因此,输入一个Shape为(3,224,224)的数据,经过该卷积核之后,通道数从3变成了768,分辨率从(224,224)变成了(14,14),输出分辨率的计算可以参考下面这条公式,H表示输入分辨率的高,P表示padding,k表示卷积核大小,S表示步长,Hout表示输出分辨率的高。同理,输出分辨率的宽也是通过这条公式进行计算的。
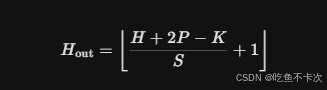
经过该卷积核之后,Shape从(3,224,224)变成了(768,14,14),至于为什么输出通道数是768,我觉得这就是人为故意设计成这样的。
patch_size=Kernel_size=stride=16
首先patch_size=16,说明了将原图划分成16x16尺寸的patch,因此水平方向上有224/16=14个patch,垂直方向上也有224/16=14个patch,一共有14x14=196个patch,并且每个patch块有3x16x16=768个参数.
其次Kernel_size=16,stride=16,说明了每次对图片进行卷积的时候不会存在重叠区域.
最后Kernel_size=16,patch_size=16,stride=16,说明了卷积核进行卷积操作的时候,卷积的区域刚好和patch的大小是一样的,因此为了保证卷积后不会导致patch的参数"丢失",卷积核的个数(输出通道数)需要刚好等于768;并且每次卷积之后滑动16个像素到下一个patch块进行下一次卷积。
在经过Conv2d卷积后得到(768,14,14),保留Batch size维度的话就是(B,768,14,14),再经过flatten和transpose得到(B,196,768),可以这么去理解这个向量化之后的数据,196是指那196个patch,768是指每个patch经过卷积后的参数量大小。
pathch_embed具体实现代码如下:
python
class PatchEmbed(nn.Module):
"""
2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
# flatten: [B, C, H, W] -> [B, C, HW]
# transpose: [B, C, HW] -> [B, HW, C]
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
return x1.2cls_token/Position embedding
cls_token和Position embedding都是可学习的参数,初始化分别对应着下面代码中的self.cls_token和self.pos_embed.
python
#torch.Size([1, 1, 768])
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
#torch.Size([1, 197, 768])
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))以下流程对应着前面的第(3)、(4)步骤:
首先来看self.cls_token,这个token作用很大,就是预测头最后用来做分类的token。
self.cls_token的Shape为(1,1,768),需要先对第0维的1进行扩充至B,得到(B,1,768),这是为了能和前面pathch_embed的(B,196,768)进行通道数拼接,在第1维进行拼接后得到(B,197,768),实现代码如下:
python
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]再来看看self.pos_embed,这个是为了让模型能够学习到每个token的位置信息,包括cls_token也有对应的位置信息,所以其Shape为(1,197,768),通过直接和前面得到的(B,197,768)张量相加的方式得到输出,最后再做一个drop_out操作,代码如下:
python
self.pos_drop = nn.Dropout(p=drop_ratio)
x = self.pos_drop(x + self.pos_embed)以上就是Embedded Patches的具体流程,可以理解为进入Transformer的预处理,因为Transformer最初是为处理自然语言(NLP)设计的,因此需要将图像数据转换成类似文本token的形式。通过Embedded Patches步骤,图像被分割成一个个patch,并转换为token向量,从而与NLP中的token处理方式相契合,为后续Transformer的处理做好准备。
1.3Dropout/DropPath
考虑到后面有DropOut和DropPath这两种Drop的方法,这里就先总结一下这两者的区别,
Dropout:
假设有一个Shape为(2,3,4)的张量,使用nn.Dropout(p=0.5)可以实现按照p=0.5的概率随机将某些元素置0,并将未置零的元素乘以1/(1-p)=2倍,如下图所示:
python
import torch
import torch.nn as nn
x=torch.randn(2,3,4)
drop_out=nn.Dropout(p=0.5)
output=drop_out(x)
DropPath:
这是在代码中自定义的一种Drop方法,代码如下:
python
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
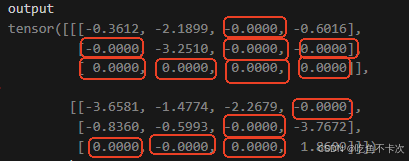
return output假设有一个Shape为(4,3,4)的张量,使用drop_path(drop_prob=0.5)可以实现按照drop_prob=0.5的概率随机将某些样本置0,并将未置零的样本乘以1/(1-drop_prob)=2倍,如下图所示:

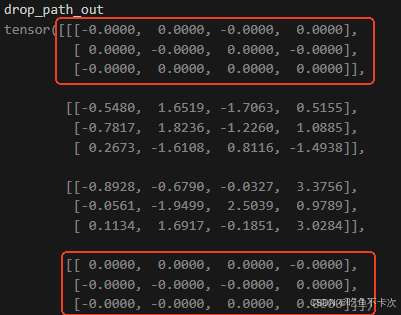
关于为什么需要放大1/(1-p)倍,下面是kimi做出的解释:

2.Transformer Encoder
下面是Transformer Encoder的结构图,输入的Shape为(B,197,768),经过Transformer Encoder模块后输出的Shape为(B,197,768),并且每一个Transformer Block的输入和输出Shape也是不改变的,这样的block有12个,当然最核心的就是Transformer Block.
是不是感觉这个和我们熟悉的SE注意力机制、CBAM注意力机制很相似,CV中的注意力机制主要是在通道维度或者是空间维度计算权重,并通过加权计算来增强重要的信息,削弱不重要的信息,并且保持输入和输出的Shape不改变。
transformer中的self-attention自注意力机制也是类似的,计算每个token与其他所有token之间的关系(计算权重),从而动态地加权每个token(增强或者削弱),并且保持输入和输出的Shape不改变。
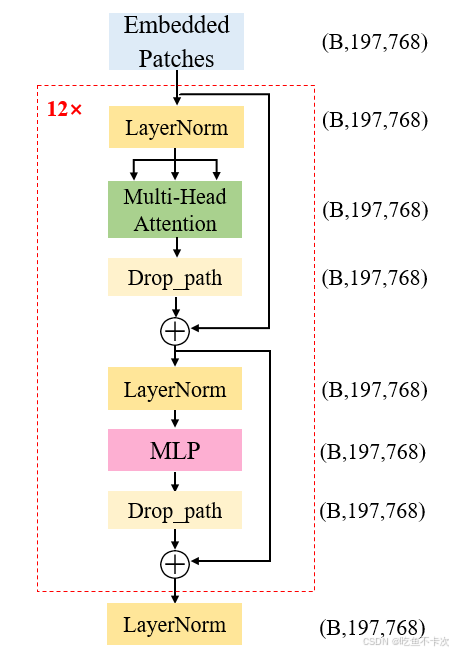
下面开始按照流程图的顺序来介绍下Transformer的各部分结构,分别是LayerNorm,Multi-Head Attention,MLP。
2.1LayerNorm
经过patch embed后的特征图Shape为(B,197,768),最先经过LayerNorm模块,LayerNorm并不会改变特征图的Shape;既然都提到了标准化了,那么来对比下BatchNorm(BN)和LayerNorm(LN).
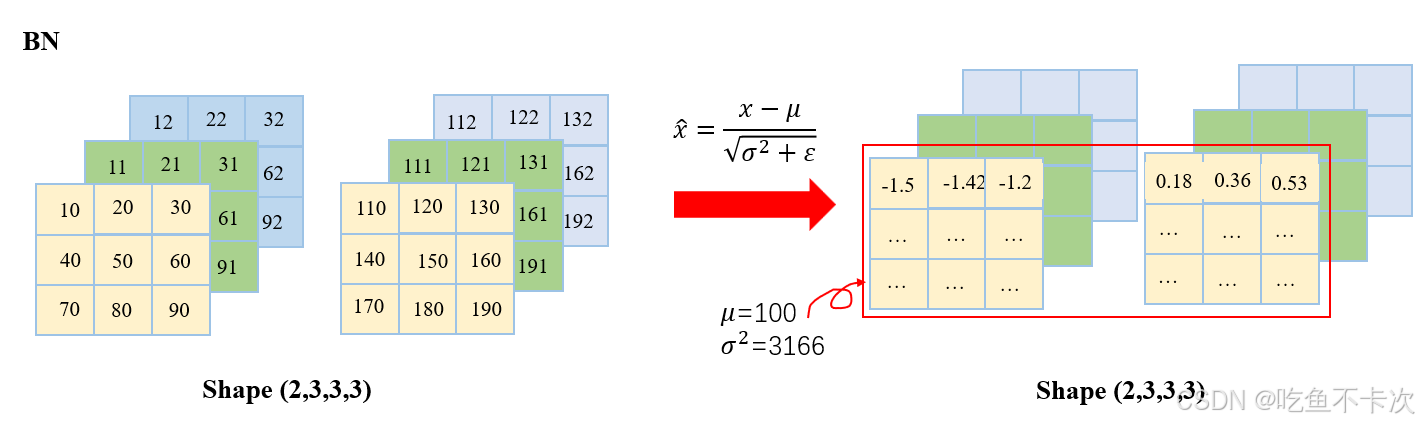
BN 是对不同样本的同一特征做标准化,还是推荐看看大佬的博客(Batch Normalization详解以及pytorch实验-CSDN博客),下面举个例子方便理解:
假设现在有两个样本,也就是batch size=2,每个样本的有3个通道,每个通道的数据都是3行3列的矩阵,因此可以使用(2,3,3,3)来表示这批数据的Shape。如果我要计算这批数据的BN,那么需要对这两个样本的同一特征求均值μ和方差σ2,同一特征也就同一个通道数,在图中就是黄色区域为通道1,绿色区域为通道2,蓝色区域为通道3。
以黄色区域的通道1为例,
均值,计算得到100;
方差,计算得到3166;
然后套入标准化公式,计算得到每个标准化之后的值,如下图所示。
同理可以计算其他通道的标准化结果,只需要注意的是标准化的时候计算哪些数据的均值和方差。
LN是对单个样本的不同特征做标准化,同样举个例子来说明一下:
LN和BN不相同的是,在创建LayerNorm层时需要指定normalized_shape,指定了normalized_shape就是对这里面的数据求均值和方差。
python
# 创建一个 LayerNorm 层
layer_norm = nn.LayerNorm(normalized_shape=[3,3,3], eps=1e-5) 当normalized_shape=3,3,3时,即对每个样本的3个通道中的三行三列数据求均值和方差。以第一个样本为例:
均值,计算得到51;
方差 ,计算得到667;
然后套入标准化公式,计算得到每个标准化之后的值,如下图所示。
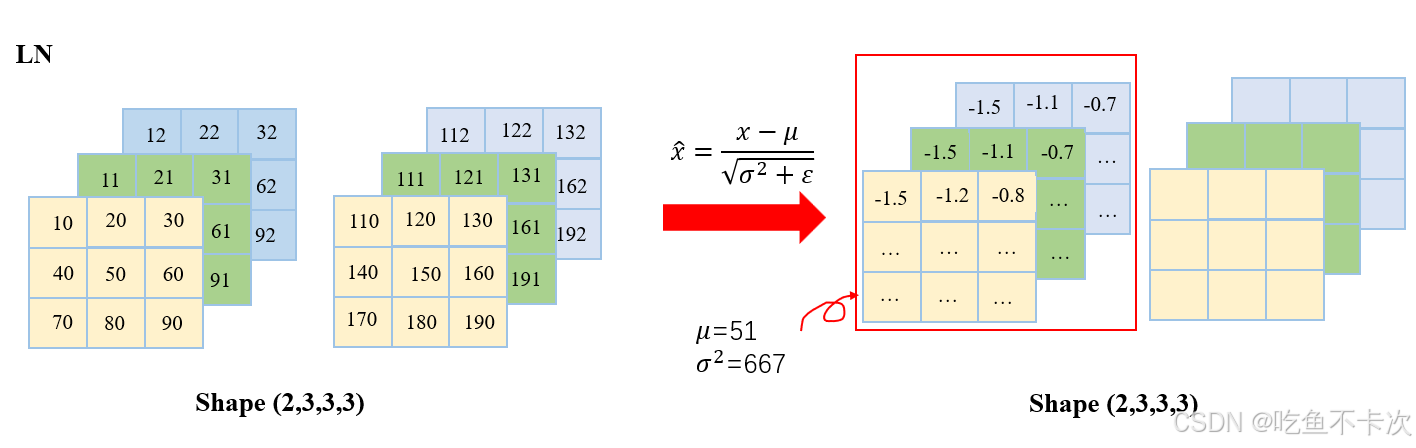
当normalized_shape=3时,默认是对最后一个维度的值求均值和方差,即(10,40,70)为一组求均值和方差再做标准化,(20,50,80)为一组求均值和方差再做标准化,依次类推。
之所以提normalized_shape=3,是因为在Transformer Encoder中的LayerNorm也是对最后一个维度求标准化的,即输入特征图的shape为(B,197,768),创建LayerNorm时normalized_shape=768,这就是对最后一个维度768个数做标准化。
python
LayerNorm((768,), eps=1e-06, elementwise_affine=True)2.2Multi-Head Attention
这是本文最重要最核心的部分,下图就是Multi-Head Attention的流程图,主要有两方面重要的内容:
(1)生成Q/K/V
(2)根据公式计算Attention
下面的内容就是主要来介绍这两部分的内容。

2.3.1生成Q/K/V
如果要将Embedded Patches输出的token用来生成Q/K/V,主要有以下几步:
(1)Q/K/V是三个矩阵,如果要从一个768维的矩阵扩展成3个768维的矩阵,可以通过一个Linear层来实现,因此将Input的Shape从(B,197,768)变成了(B,197,2304),注意这里只改变最后一维数据的维度值,现在就是有197个token,每个token的维度变成了2304维。
(2)接着要把2304维拆成3个768维的矩阵,并且对于每个768维的信息,再次进行划分出12份,每份64维,其中12就表示Multi-Head 中的12个头,64维就表示实际上每个Q/K/V的矩阵维度,现在的Shape为(B,197,3,12,64)。
(3)最后再交换下维度得到qkv,Shape变成了(3,B,12,197,64),那么Q/K/V矩阵的Shape为(B,12,197,64),且使用qkv0表示Q,qkv1表示K,qkv2表示V。
主要代码如下所示:
python
#Linear(in_features=768, out_features=2304, bias=True)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]2.3.2 Self-Attention
核心就是这条公式,前面我们已经通过Linear得到了Q/K/V矩阵了,并且还知道了每个矩阵的维度是64,也就是d=64,下面分成五步看看这条公式是如何进行计算以及Self-Attention的完整流程。
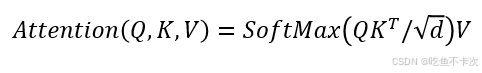
假设B=1,即只有一张图片的时候,得到Q/K/V矩阵的shape为(1,12,197,64),下面为了方便就只写后面几维,使用(12,197,64)来表示Q/K/V的Shape了。
(1)首先是Q和K'进行矩阵乘法,对于每个Head,都会得到一个shape为(197,197)的矩阵,因为有12个head,所以得到Shape为(12,197,197)的attn矩阵,也就是公式当中;
(2)接下来对attn矩阵的值进行缩放,通过除以sqrt{d}实现,是为了防止数值不稳定,然后再通过Softmax函数归一化,注意是对(12,197,197)最后一维进行Softmax处理,即对于(197,197)的矩阵,每一行的和为1,得到注意力权重;这里对应公式中的;
(3)接着经过attn_drop,实际上也是nn.Dropout(),不过默认值p=0,即不进行dropout操作;
(4)最后和V做矩阵乘法运算,得到Shape为(12,197,64)的output矩阵,再transpose和reshape成(197,768)
**注意:**如果B=n,即一次性处理多张照片时,也是相同的步骤流程,那么经过Self-Attention后会得到(B,197,768)的输出结果。
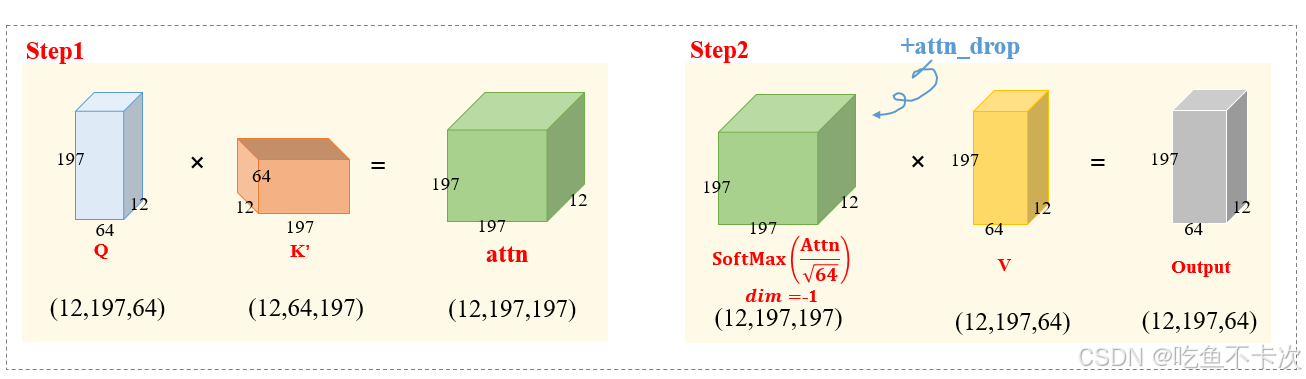
主要代码如下:
python
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)(5)self-attention还有最后一点小尾巴,就是Linear层和Dropout(同样默认p=0),代码如下所示:
python
#Linear(in_features=768, out_features=768, bias=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop_ratio)
x = self.proj(x)
x = self.proj_drop(x)2.3MLP
MLP就比较简单了,主要就是由两个Linear层和GELU激活函数构成,然后Dropout默认p=0,即不进行Dropout操作,真想吐槽一下,为啥要设置这么多的Dropout.

代码如下:
python
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x2.4总结
(1)Transformer Encoder是由12个Transformer block构成的,也就是红色虚线内的模块,每个block的输入和输出的Shape都是(B,197,768),所以如果你想缩减下网络的参数量大小,你可以通过调整block的大小来实现。
(2)Transformer block中包含有两个残差结构,其中第一个残差结构包含着最重要的Multi-Head Attention,即用来计算自注意力的模块;剩下的模块都是比较简单的LayerNorm模块和MLP模块。
(3)经过12个Transformer block后,会再次经过一个LayerNorm得到Transformer_encoder的输出X,由于下游任务是用作分类,所以最后实际上是把X:,0输出给Cls_Head,即我们再Embeded Patches中插入在最前面的Cls token作为输出,用来分类预测,Shape为(B,1,768),可以看第0章前言的插图会更加清晰整个流程。

3.Cls_Head
你没看错,Cls_Head分类头只有一层Linear层,输出维度直接就是类别数,简单直接,这里我采用的是花卉数据集,一共有五个类别。
python
#Linear(in_features=768, out_features=5, bias=True)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()4.总结
本文只是根据代码去探讨下Vit的网络结构,相信看完这块内容,对Vit的网络结构有一定的了解,但是在第2.2章节也一定会有很多的疑问,为什么要区分Q/K/V?他们到底代表着什么意思?感觉非常得抽象,后面我应该还会再整理一篇博文来探讨下transformer中QKV,尽可能可以对这部分知识实现自恰。