RDD转换算子总结
RDD转换算子分为Value类型、双Value类型和Key - Value类型。
1 、Value类型
- map:对数据逐条映射转换,可改变数据类型或值。如 dataRDD.map(num => num * 2
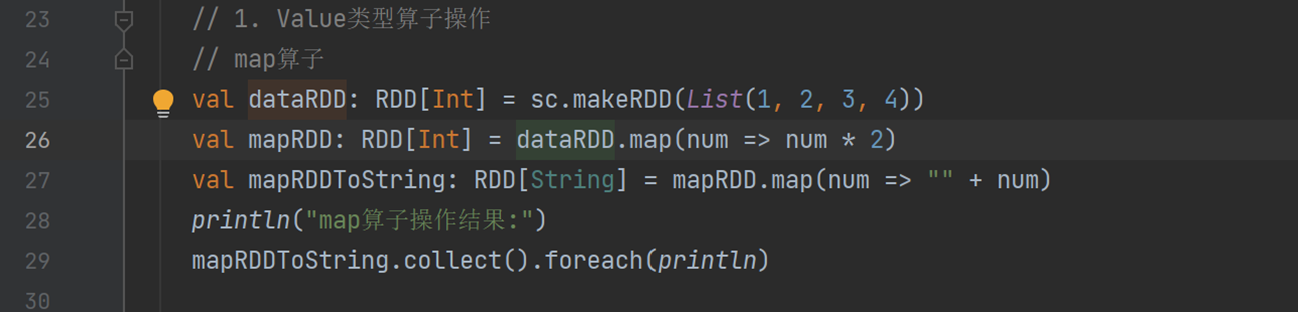
|---|------------------------------------------------------------|
| |
| |  |
|
运行结果:
2)mapPartitions:以分区为单位处理数据,可过滤数据。与 map 相比,它是批处理,性能高但可能占内存。如 dataRDD.mapPartitions(datas => datas.filter(_ == 2)) 。

运行结果:
|---|------------------------------------------------------------|
| |
| | |
3)mapPartitionsWithIndex:类似 mapPartitions ,处理时可获取分区索引。
4)flatMap:先扁平化数据再映射,会将输入对象映射为集合后连成大集合。如 dataRDD.flatMap(list => list) 。

|---|------------------------------------------------------------|
| |
| | |
运行结果:
5)glom:将分区数据转为内存数组,分区不变。

运行结果:
6)groupBy:按规则分组数据,会打乱重组(shuffle)。

运行结果:
7)filter:按规则筛选数据,可能导致数据倾斜。
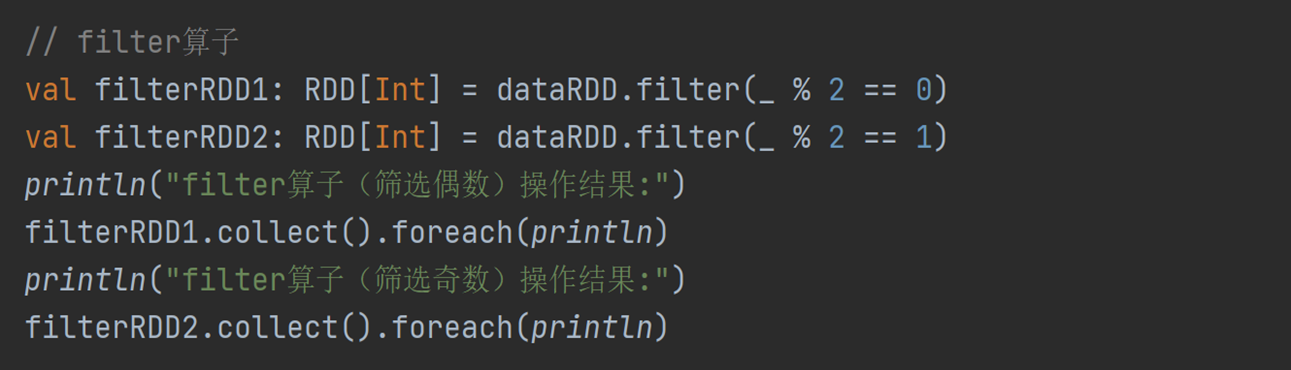
|---|------------------------------------------------------------|
| |
| | |
运行结果:
8)sample:按规则抽取数据,有放回(泊松算法)或不放回(伯努利算法)。

运行结果:
9)distinct:去重数据,可指定分区数。

运行结果:
10)coalesce:缩减分区,提高小数据集效率。

|---|------------------------------------------------------------|
| |
| | |
运行结果:
11)repartition:内部执行 coalesce ,默认 shuffle=true ,可改变分区数。
运行结果:
12)sortBy:排序数据,可指定排序规则和分区数。
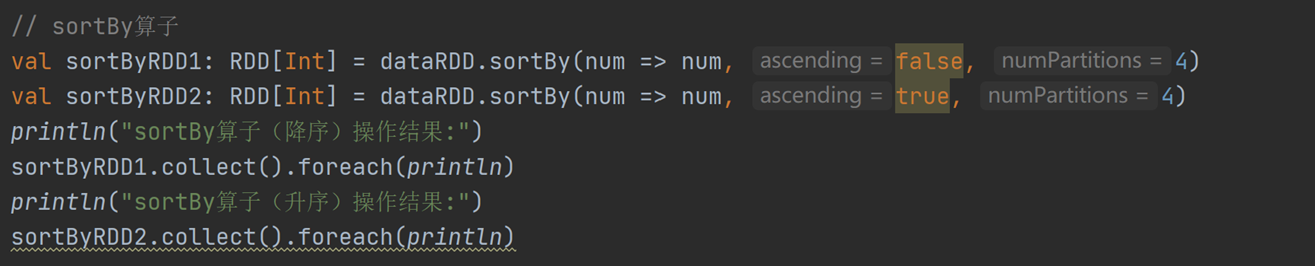
|---|------------------------------------------------------------|
| |
| | |
运算结果:
2、双Value类型
13)intersection:求两个RDD交集。

|---|------------------------------------------------------------|
| |
| | |
运行结果:
14)union:求并集,重复数据不去重。

|---|------------------------------------------------------------|
| |
| | |
运行结果:
15)subtract:求差集,保留源RDD非重复元素。
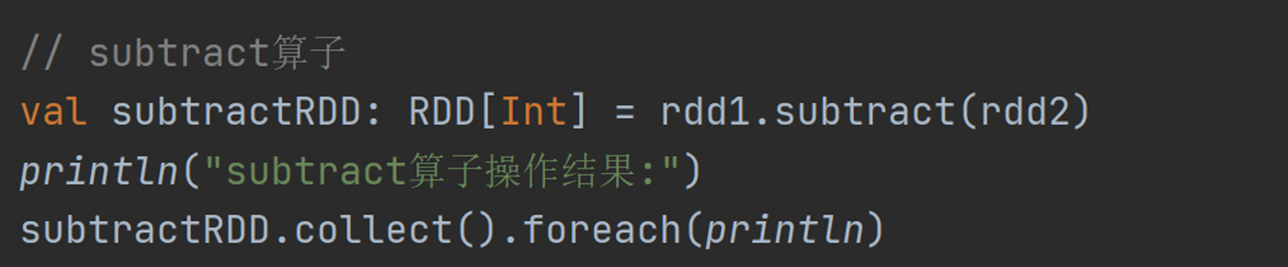
|---|------------------------------------------------------------|
| |
| | |
运行结果:
16)zip:将两个RDD元素按位置合并为键值对。
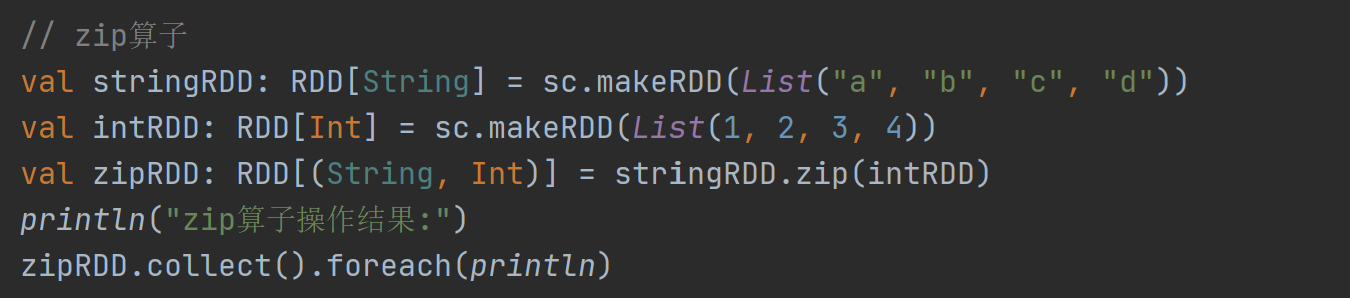
运行结果:
- Key - Value类型
17)partitionBy:按指定 Partitioner 重新分区,默认分区器为HashPartitioner 。
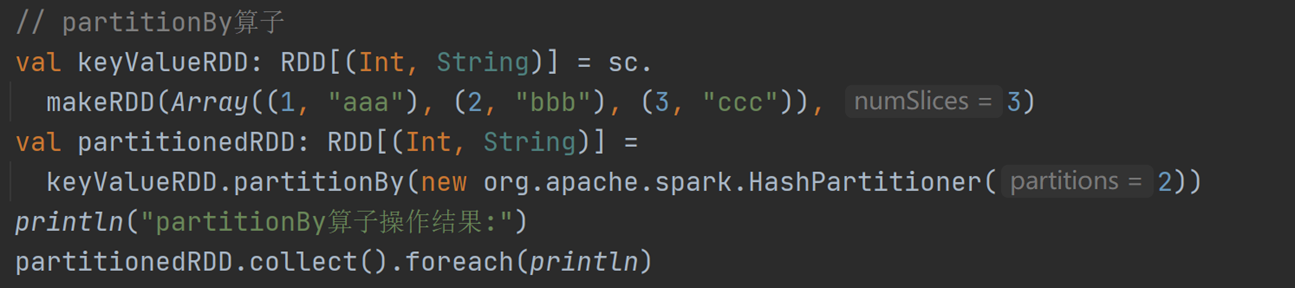
运行结果:
18)groupByKey:按 key 分组 value 。
运行结果:
19) reduceByKey:按 key 聚合 value ,可预聚合,性能高。
运行结果:
20)aggregateByKey:分区内和分区间按不同规则计算。
运行结果:
21)foldByKey:分区内和分区间计算规则相同时,是 aggregateByKey 的简化。

运行结果:
22)combineByKey:通用聚集函数,可改变数据结构。
运行结果:
23)sortByKey:按 key 排序, key 需实现 Ordered 接口。
|---|------------------------------------------------------------|
| |
| | |
运行结果:
- join:连接两个RDD中相同 key 的元素。

运行结果:
- leftOuterJoin:类似SQL左外连接。

运行结果:
- cogroup:将相同 key 的元素分组到一个RDD中。

运行结果: