
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
[1、LLM 的局限:模型知识"封闭" vs 现实知识"动态"](#1、LLM 的局限:模型知识“封闭” vs 现实知识“动态”)
[3、为什么需要"检索 + 生成"结合?](#3、为什么需要“检索 + 生成”结合?)
[二、RAG 的整体架构与流程](#二、RAG 的整体架构与流程)
[2.1、提示模板设计(Prompt Template)](#2.1、提示模板设计(Prompt Template))
[四、RAG 与传统 QA 系统的对比](#四、RAG 与传统 QA 系统的对比)
[1、检索式 QA(BM25 / Elasticsearch)](#1、检索式 QA(BM25 / Elasticsearch))
[2、生成式 QA(LLM 单独输出)](#2、生成式 QA(LLM 单独输出))
[3、RAG相比检索式 QA和生成式 QA的优势](#3、RAG相比检索式 QA和生成式 QA的优势)
一、前言
1、LLM 的局限:模型知识"封闭" vs 现实知识"动态"
🤖 大语言模型 LLM 的"大脑"怎么来的?
LLM(比如 ChatGPT)是通过"喂大量文字资料"训练出来的。
这些资料可能包括:
-
维基百科 📚
-
新闻、小说 🗞️📖
-
技术文档、网站内容 🧑💻
-
训练时截⽌于某⼀年(比如 2023 年)
✅ 优点:
- 训练完之后,它能"理解语言"和"生成回答",就像人一样 ✍️
🚫 但问题来了!
训练完之后,这些模型的知识就"封闭"了 !
就像你在 2023 年读完所有百科,然后被关进了房间...
以后就不能接触外面的新东西了 🙈
📅 现实世界是"动态"的!
现实世界每天都在变:
-
新技术、新产品 💡
-
股市波动 📉📈
-
社会新闻 📰
-
法律、政策变化 🏛️
-
你公司的文档不断更新 📂
🤔 举个例子
你问 ChatGPT:
"苹果 iPhone 16 有哪些新功能?"
-
❌ 普通 LLM(没联网)只能告诉你:
"截至训练时,最新的是 iPhone 14 或 15..."
-
✅ 使用 RAG 或联网增强的模型能回答:
"iPhone 16 加入了 AI 拍照助手、无边框屏幕..."(实时查的!)
📌 所以说...
❗ LLM 的局限:
-
它的知识是静态的、封闭的 🧱
-
无法主动感知"此时此刻"发生了什么 ⏰
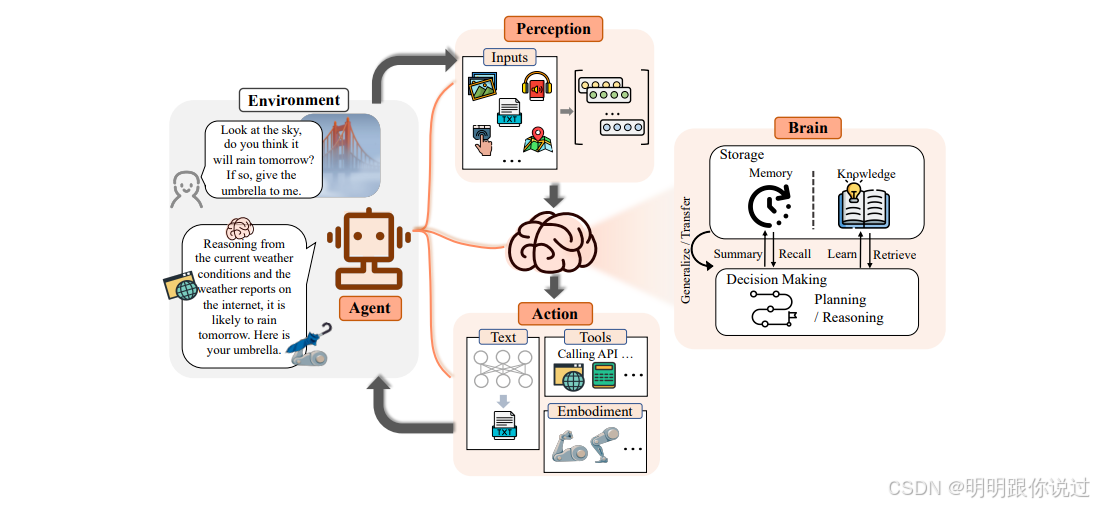
2、什么是RAG
你有没有和 ChatGPT 聊天时发现,它有时候回答得不太准确?🤔
那是因为它只靠"记忆"回答问题 ,而不是实时"查资料"。
RAG 就是来解决这个问题的!🎯
💡RAG 的全称
RAG = Retrieval-Augmented Generation
中文意思是:"检索增强生成"
听起来是不是很学术?别急,我们来举个栗子🌰
🍜 用"点外卖"举个例子
假设你在点外卖 🍱,你问:
哪家餐厅最近评价最好?
-
如果是普通大模型(没有 RAG):
它会靠以前学过的资料 告诉你:
"大众点评上XX餐厅评价不错哦~"
-
如果是带 RAG 的模型:
它会先去实时搜索 :
"当前最新的餐厅评价",
然后结合自己的理解,告诉你答案!
✅是不是更靠谱了!

3、为什么需要"检索 + 生成"结合?
简单说一句话:
👉 "检索"找资料,"生成"来表达
合在一起,就成了聪明又靠谱的问答助手 🧠✨
🎓 一句话区分两者
| 模块 | 是谁 | 作用 |
|---|---|---|
| 🔍 检索 | 类似 Google、百度 | 从知识库里"找答案" |
| ✍️ 生成 | 类似 ChatGPT、文心一言 | 把资料"说人话"告诉你 |
📦 为什么不能只靠"生成"?
生成模型(LLM)很强大,但有两个大问题:
-
知识是封闭的
它只能回答训练时学过的内容,不能访问新数据 📅
-
可能张口就来(幻觉)
它有时会"瞎编"一个听起来像真的答案 🤯
"Python 6.0 已发布"❌(其实根本没有)
🔍 那只用"检索"行不行?
只用检索就像自己去 Google 搜资料:
-
你得自己读、自己理解 🧾
-
内容零碎,用户体验不好 😩
✅ 所以"检索 + 生成"强在哪?
它把 两者的优点结合起来:
| 模块 | 优点 |
|---|---|
| 检索 | 提供实时、可靠、准确的"资料来源" 📚 |
| 生成 | 自动理解内容,用自然语言表达答案 ✨ |
就像你有了个聪明秘书👇
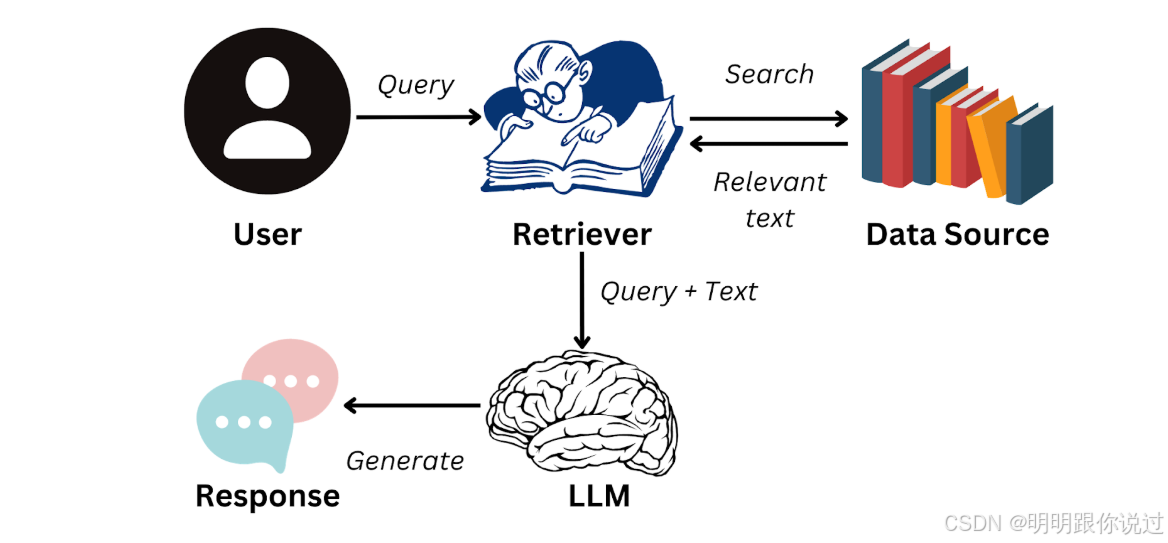
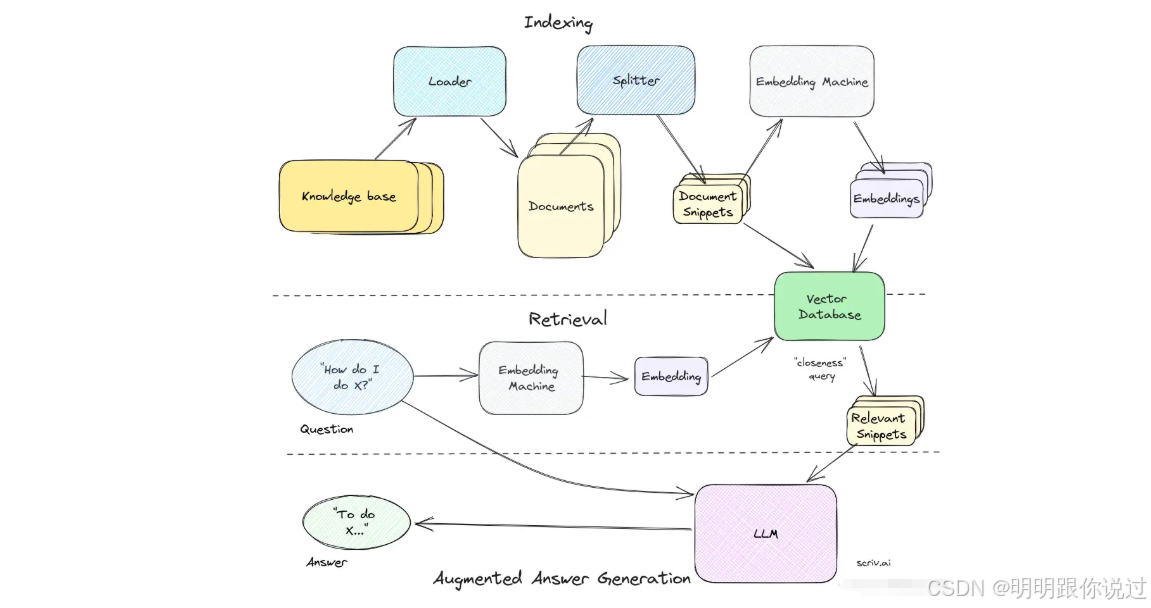
二、RAG 的整体架构与流程
1、检索增强生成的基本结构
🧱 RAG 的基本结构组成
用户问题
↓
🔍 检索模块(Retriever)
↓
📄 相关文档(Document Store / 向量数据库)
↓
🤖 生成模块(LLM)
↓
✅ 最终回答
1️⃣ 用户问题(User Query)🗣️
用户提出一个自然语言的问题,比如:
"我们公司今年的假期安排是怎样的?"
2️⃣ 检索模块(Retriever)🔍
它会把这个问题变成"向量"或关键词,
去知识库里找"相关资料",比如 Word 文档、PDF、数据库记录等。
常用方式有:
-
向量搜索(embedding 检索)🔢
-
关键词搜索(BM25等)🔡
3️⃣ 文档库 / 知识源(Document Store)📚
这是你提供给系统的"专属资料库":
可以是:
-
内部文档系统(如 Confluence)
-
产品手册、公司制度文档
-
FAQ 问答库
-
向量数据库(如 Faiss、Weaviate、Pinecone)
4️⃣ 生成模块(LLM)✍️
将检索到的资料 + 用户问题
一起输入给大语言模型(如 GPT-4)
👉 它会生成一个贴合问题、参考资料的自然语言答案。
5️⃣ 最终输出 ✅
模型输出的回答结合了"当前资料"与语言表达能力,
能给出"有依据、不瞎编"的智能答复。
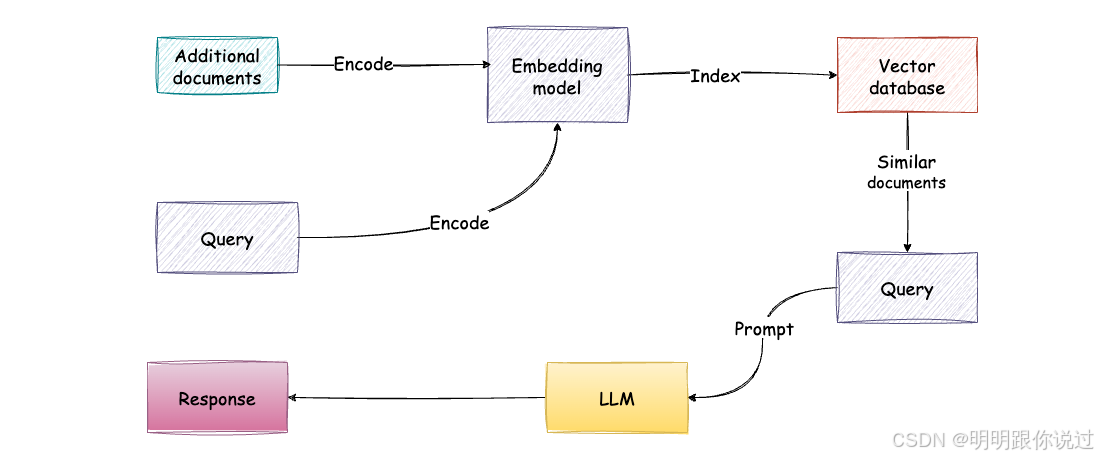
2、核心流程
🧭 1. 用户输入 query(提问)💬
用户输入自然语言问题,比如:
"公司 VPN 连不上怎么处理?"
🔍 2. 检索相关文档(Retriever)📂
将用户问题转化为向量(或关键词),
在知识库中查找相关资料片段,如:
-
公司 IT 支持文档
-
网络故障手册
-
FAQ 问答库
🔸 输出:若干条相关内容(上下文)
🧠 3. 拼接上下文 + 问题输入 LLM(Generator)🧾
把这些检索到的内容 + 用户问题
打包送入大语言模型(如 GPT-4)
🔸 模型可以"理解"上下文,结合已有知识进行回答。
✅ 4. 返回回答结果 ✨
LLM 输出一个贴合上下文、语义流畅的回答,例如:
"您好,请尝试重启 VPN 客户端,若仍无法连接,请联系 IT 支持人员并提供错误码。"
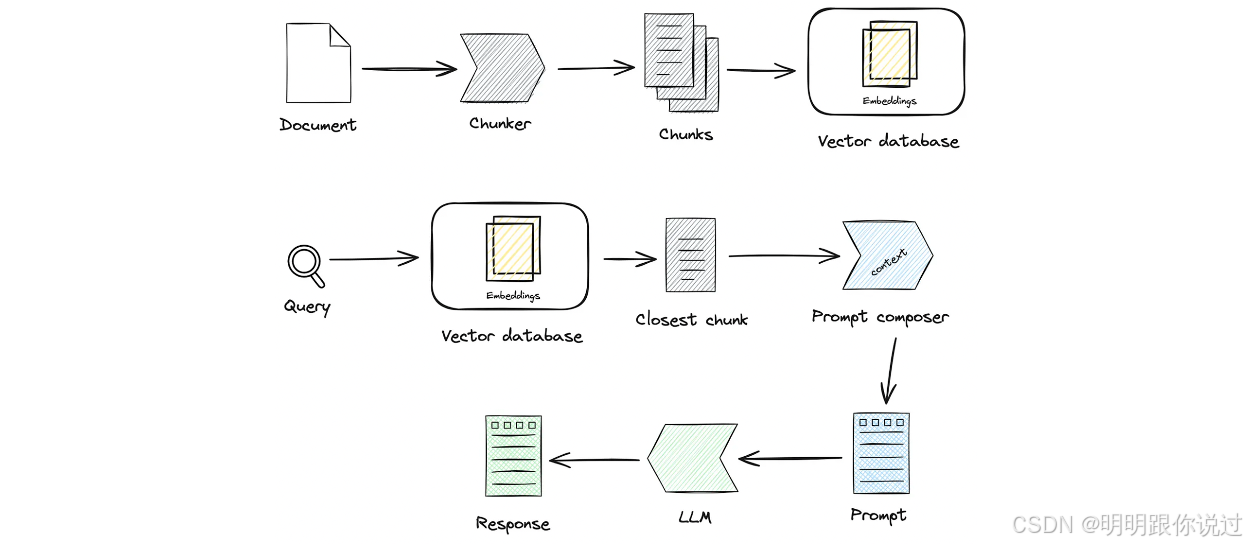
三、核心模块解析
1、向量检索模块(Retriever)
1.1、文档预处理与切分(Chunking)
🧐 为什么要切分文档?
我们不能直接把整本 PDF、整篇网页丢给模型或向量数据库!
因为:
-
太大,无法一次处理(LLM 有长度限制)📏
-
不利于精确匹配关键词或语义 🎯
所以要把大文档 ✂️ 切成小块(Chunk)!
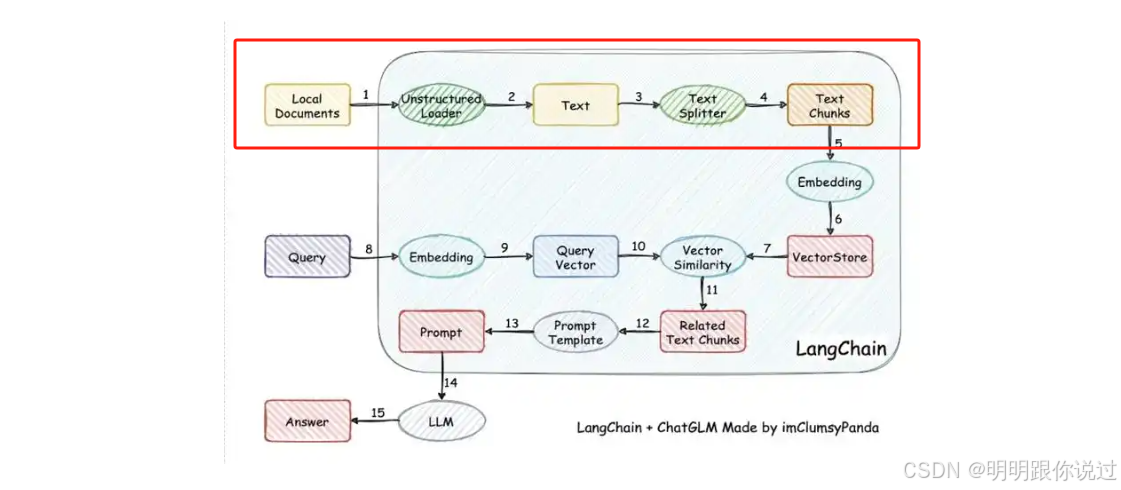
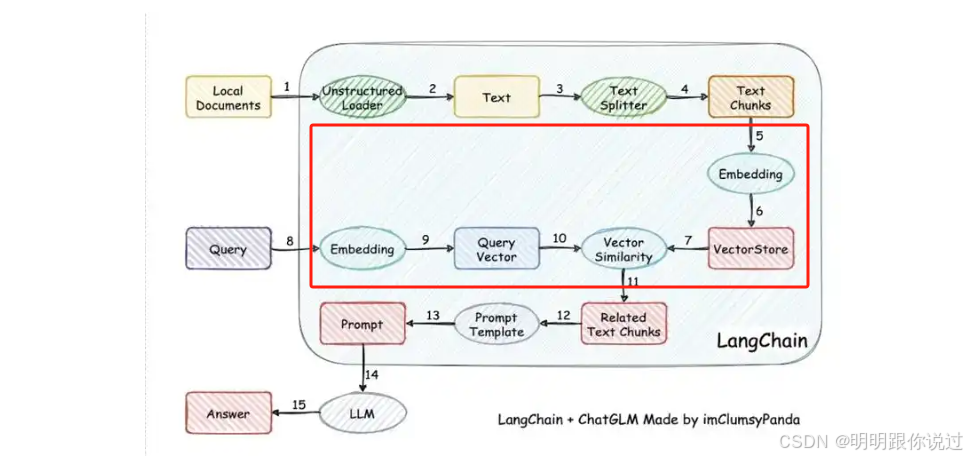
🔨 文档预处理与切分流程
原始文档(PDF / Word / 网页等)📄
↓
- 文本提取(OCR / Parser)🔍
↓
- 清洗格式(去除 HTML 标签、多余空格等)🧼
↓
- 切分成小段(Chunking)✂️
↓
- 生成每段的向量 Embedding(文本 → 数字)🔢
↓
存入向量数据库(如 Faiss / Weaviate / Milvus)📦
1.2、向量化(Embedding)原理
🎯 一句话理解:
把一句话或一段文字 ✍️
转换成一个可以在"数字世界"中比大小、量距离的 向量 📍
👉 方便让机器"理解语义"和"做相似度检索"!
🧠 举个例子:
| 原始文本 | 向量化后 |
|---|---|
| "猫是一种动物" | [0.12, -0.85, 0.33, ..., 0.05] |
| "狗是哺乳动物" | [0.11, -0.80, 0.30, ..., 0.07] |
| "咖啡是一种饮料" | [0.95, 0.02, -0.30, ..., 0.88] |
📌 可以看到:"猫"和"狗"的向量相近 ,说明语义上相关。
"咖啡"离它们就远了,语义无关 🧭
🧩 Embedding 是怎么做的?
过程如下图(概念流程):
输入文本:"如何重置公司邮箱密码?"
↓
🔤 分词(Tokenizer)
↓
🔢 编码(Embedding 模型)
↓
输出一个 N 维向量:0.23, -0.45, 0.88, ..., -0.19
✅ 每一维都代表了某种"语义特征",比如技术性、办公场景、问题类型等。
🚀 常见的文本向量模型(Embedding Models)
| 模型 | 来源 | 特点 |
|---|---|---|
OpenAI text-embedding-3-small |
GPT家族 | 准确度高、商用常用 |
bge-small / bge-large |
BAAI(北京智源) | 中文支持优秀 🇨🇳 |
E5 / Instructor |
Hugging Face 社区 | 多语言、检索效果好 |
MiniLM / MPNet |
微软 | 轻量快、适合端侧部署 |
🧭 向量的价值在哪?
-
✅ 可以通过"距离"判断文本间的语义相似度
- 常见方式:余弦相似度 cosine similarity
例如:
"公司如何申请年假?" 与 "怎样请假?"
向量距离近,说明意思接近,Retriever 会成功召回!
1.3、向量数据库简介
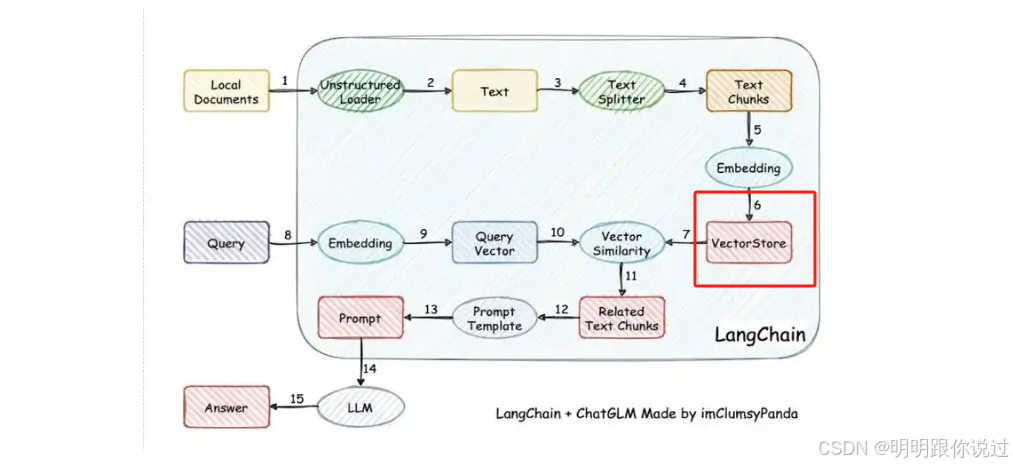
🧭 什么是向量数据库?
向量数据库是专门用来存储、管理、搜索「向量(Embedding)」的数据库 📦,
它能干的事情主要是👇:
-
✅ 存:将文本、图像等向量数据存起来
-
✅ 查:支持「相似度检索」------找出"语义最相近"的内容
-
✅ 快:可处理数百万、甚至数十亿条向量数据
-
✅ 强:支持高维向量、支持 GPU、分布式扩展能力强
🔍 所以,在 RAG 架构中,它就是连接 检索模块 和 知识库 的超级引擎!
📦 常见向量数据库介绍一览:
| 名称 | 产地 / 背景 | 优势亮点 | 使用方式 | 是否开源 |
|---|---|---|---|---|
| FAISS 🧱 | Meta / Facebook | 极快的本地向量搜索 | Python 为主,嵌入式用多 | ✅ 是 |
| Milvus 🚀 | Zilliz(国产) | 云原生、分布式强 | REST / Python / Java | ✅ 是 |
| Weaviate 🧠 | 欧洲公司 | 集成好(支持 OpenAI / Cohere 等) | RESTful API,易部署 | ✅ 是 |
| Qdrant ⚡ | 开发者友好 | 支持过滤器、打分高效 | Web UI + API 易用 | ✅ 是 |
🔹 FAISS(Facebook AI Similarity Search)
-
🌱 轻量级、单机版神器
-
🚀 支持 GPU,百万级向量检索毫秒级
-
😅 不适合做分布式、管理功能弱
-
🔧 适合离线处理、大量批量匹配任务
🔹 Milvus
-
🇨🇳 开源之光,Zilliz 维护
-
☁️ 支持云部署、分布式、多副本
-
🔌 可接 Elastic、S3、MySQL 等
-
💬 非常适合企业级大规模向量服务
🔹 Weaviate
-
🔗 天生就是为 RAG 服务的向量库
-
🎁 内置向量模型集成(OpenAI / HuggingFace)
-
🌐 提供 GraphQL/REST API,简单易上手
-
💡 适合快速搭建语义搜索原型
🔹 Qdrant
-
💻 支持结构化 + 非结构化过滤查询(很灵活)
-
🧪 拥有 Web 控制台、API 易用
-
💨 检索性能强,开源活跃
-
👍 很适合开发者 / 中小型 RAG 项目

2、生成模块(Generator)
2.1、提示模板设计(Prompt Template)
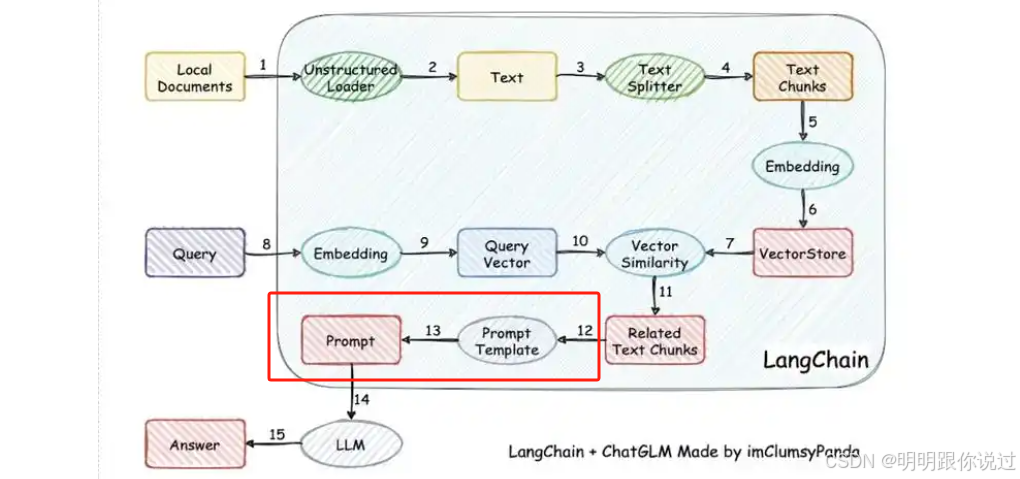
❓为什么要设计提示模板?
因为直接把检索结果 + 用户问题喂给 LLM,模型未必能「懂你想要什么」。
所以我们需要一个"引导话术",像"说明书"一样告诉模型如何回答。📋
✅ 最常见的提示结构如下:
你是一位 角色设定。
请根据以下已知信息回答用户的问题:
【已知信息】
{{context}}
【用户问题】
{{question}}
请用简洁、准确的语言回答:
📌 {``{context}} 是 Retriever 检索出来的内容
📌 {``{question}} 是用户输入的问题
💡 示例:技术支持场景
你是一名经验丰富的 IT 支持工程师。
请根据以下信息回答用户的问题:
【已知信息】
VPN 客户端连接错误代码为 809。
错误 809 常见于防火墙未开放 UDP 500 和 UDP 4500 端口。
建议联系网络管理员确认 VPN 协议设置。
【用户问题】
VPN 连接一直失败,提示错误 809,怎么解决?
请用中文简洁说明处理方案。
🔍 这个模板能让 LLM:
-
更清楚角色定位(你是谁)
-
更聚焦已知信息(别胡编)
-
更精确响应问题(不要答非所问)
2.2、插入检索内容的方式
🛠️ 插入检索内容的几种方式
1️⃣ 经典方式:直接拼接 Prompt(RAG-原始版)
👉 把检索结果(Top-K 文档)直接用 Prompt 拼到用户问题前面:
文档1内容
文档2内容
...
问题:请总结上述内容的要点。
优点:简单直接
缺点:信息可能冗余,文档质量参差不齐导致生成结果不稳定 😵
2️⃣ RAG Fusion 🧪
👉 灵感来自"多样性增强"。做法是:
-
对一个问题,向 多个不同视角的查询(Query variations) 检索文档(比如改写问题)
-
把多个检索结果合并、去重、排序
-
拼接后交给生成模块
🌟 优点:
-
检索结果更全面、不容易漏信息
-
减少模型对单一文档的偏见
📌 举例:
问题:"公司的假期制度是怎样的?"
你可能会生成多个查询:
-
"公司节假日规定"
-
"年假政策"
-
"加班与调休"
然后将多个检索结果融合为一个 Prompt。
3️⃣ RAG with Rerank 🔁
👉 在 Top-K 检索结果出来后,使用一个 重排序(Reranker)模型,对这些文档按"相关性"重新排序 ✅
流程如下:
-
原始Retriever → 拿到Top-20候选文档
-
使用Reranker模型(如 BGE-Reranker、ColBERT)评分
-
选出 Top-N 最相关文档拼 Prompt
🌟 优点:
-
提升质量,去掉干扰文档
-
对复杂问答场景更有效,比如医疗、法律
4️⃣ (加分项)Chunk Merging、信息整合式 Prompt 🧩
针对文档太长、碎片多的问题,有些系统会先:
-
对多个文档内容做摘要或融合(比如提取共同主题)
-
然后再生成回答,减少重复和冲突
| 方式 | 特点 | 适用场景 |
|---|---|---|
| 📜 原始拼接 | 简单、快速 | 小型项目、简单问答 |
| 🧪 RAG Fusion | 多视角、全面 | 信息分散型问题 |
| 🔁 Rerank | 精准提取、抗噪性强 | 复杂、高质量要求的问答 |
| 🧩 Chunk融合 | 减冗余 | 文档重复率高、大模型Token受限时 |

四、RAG 与传统 QA 系统的对比
1、检索式 QA(BM25 / Elasticsearch)
🧠 传统 QA 系统是怎么工作的?
传统 QA 系统的核心是:直接检索文档段落,作为回答返回。
🧱 架构核心:
-
用户提问:"公司的加班政策是什么?"
-
系统使用 关键词匹配算法(如 BM25)在文档库中查找最相关的段落。
-
把 相关段落原文返回给用户。
🔍 BM25 / Elasticsearch 是主力选手:
-
BM25 是一种基于词频 + 逆文档频率的打分机制(TF-IDF 的升级版)
-
Elasticsearch 是支持 BM25 的流行全文搜索引擎
📦 举个例子:
🧑💼 你问:"我们公司节假日有哪些?"
🧾 传统 QA(BM25)返回结果:
第5章 节假日安排:
元旦放假1天;
春节放假7天;
清明节放假1天;
...
✅ 优点:直接、可查证
❌ 缺点:用户得自己读、自己理解

2、生成式 QA(LLM 单独输出)
✨ 生成式 QA 是什么?
生成式问答(Generative QA)就是指:
只用大语言模型(LLM) 来回答问题,不借助外部知识库或检索系统。
也就是说,模型完全靠 自己"脑子里"的知识 来作答📦。
🧱 它的工作方式非常简单:
-
用户提问:"黑洞为什么是黑的?"
-
模型在它的训练知识中找答案(比如 GPT-4 训练时学到的物理知识)
-
生成一段自然语言的回答
📦 举个例子
🧑💬 用户问:
"牛顿三大定律分别是什么?"
🤖 生成式 QA(单独 LLM)回答:
"牛顿三大定律包括惯性定律、加速度定律和作用反作用定律,分别为:1. 物体不受外力将保持静止或匀速直线运动;2. F=ma;3. 作用力与反作用力大小相等方向相反。"
✅ 回答清晰、自然,不需要引用外部资料。
🧠 它的"知识库"来自哪里?
就是它训练时候用的大量数据,比如:
-
书籍、百科、论文
-
互联网上的网页、论坛
-
GitHub、博客、维基百科...
一旦模型训练完成,它就像一位博览群书的"闭卷考生",可以根据脑中的"印象"来作答📚🧠

3、RAG相比检索式 QA和生成式 QA的优势
三种 QA 模型的区别:
| 模型类型 | 数据来源 | 回答方式 | 是否有"理解力" | 是否会幻觉 |
|---|---|---|---|---|
| 🔍 检索式 QA | 外部文档库(如 ES / BM25) | 直接返回原文片段 | ❌ 没有,靠关键词匹配 | ❌ 基本不会 |
| 🧾 生成式 QA | 模型训练时的知识 | 自由生成 | ✅ 有语义能力 | ⚠️ 高,容易胡编 |
| 🤖 RAG | 检索结果 + LLM | 先检索再生成 | ✅ 有理解能力 | ✅ 较低,可控 |
✨ 那么,RAG 到底比它们强在哪儿?一起来看!👇
🎯 对比优势一:结合了"知识准确性"和"语言表达能力"
| 能力 | 检索式 QA | 生成式 QA | ✅ RAG |
|---|---|---|---|
| 🎯 找到正确知识 | ✅ | ❌ | ✅ |
| 🗣️ 表达自然语言 | ❌ | ✅ | ✅ |
RAG = 检索准确性(靠 Retriever) + 表达通顺性(靠 Generator)
→ 既懂又会说 💡🧠🗣️
🔍 对比优势二:支持开放域问答
传统检索式 QA 往往只适用于特定知识文档,
生成式 QA 又容易"张口就来"。
🎯 RAG 则可以面向任意问题,只要资料在知识库中,就能通过检索 + 推理生成高质量回答。
🧠 对比优势三:降低幻觉风险
幻觉 = 模型一本正经地编!
-
❌ 生成式 QA:幻觉高(完全靠记忆)
-
✅ RAG:只在模型读了真实资料后生成,幻觉概率大大降低
-
✅ 检索式 QA:无幻觉,但用户要自己读
📚 对比优势四:回答内容有"证据"可查
RAG 可将使用过的文档片段一起返回,形成"可追溯"的问答系统。
💡 示例:
问题:公司的带薪年假制度是什么?
🤖 RAG 回答:
-
🗣️ 回答:你每年有5天带薪年假,未使用的部分可延期1年。
-
📎 来源文档片段:
"员工年假为每年5个工作日,未休部分可结转至次年使用。"
✅ 回答可信 + 有出处
(相比之下,生成式 QA 没法告诉你"这句话是哪来的")
🔄 对比优势五:知识可随时更新,无需重训
| 模型 | 知识更新方式 | 难度 |
|---|---|---|
| 生成式 QA | 重训练 LLM | 😖 非常难 |
| 检索式 QA | 更新文档库 | 😀 简单 |
| ✅ RAG | 更新知识库 + 检索器 | ✅ 非常灵活! |
💡 RAG 只要更新知识库和 Embedding 就能快速响应新内容,例如法规变化、产品更新、新闻实时问答等。
🧩 总结一句话:
RAG = 检索的严谨 + 生成的聪明 🧠 + 知识的可控 📚
是目前大多数企业级智能问答系统的首选!
🎁 用表格总结一下三者对比:
| 维度 | 检索式 QA | 生成式 QA | ✅ RAG |
|---|---|---|---|
| 数据来源 | 文档库 | 模型记忆 | 文档库 |
| 回答风格 | 原文复制 | 自由生成 | 生成回答 |
| 表达能力 | ❌ 弱 | ✅ 强 | ✅ 强 |
| 知识更新 | ✅ 易更新 | ❌ 难(需重训) | ✅ 易更新 |
| 是否可溯源 | ✅ 可 | ❌ 否 | ✅ 可 |
| 幻觉概率 | ❌ 无 | ❌ 高 | ⚠️ 低 |
| 技术难度 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!