一、引言
在信息爆炸的时代,作为科技领域的内容创作者,我每天都要花费2-3小时手动收集行业新闻、撰写摘要并发布到各个社群。直到我发现Bright Data+n8n+AI 这套"黄金组合",才真正实现了从"人工搬运"到"智能自动化"的转变。现在,我的AI新闻助手每天自动完成以下工作:
- 定时抓取VentureBeat等权威科技媒体的最新报道
- 使用AI生成简洁有力的中文摘要
- 自动发布到Telegram频道、企业微信群和邮件列表
- 同步存档到Notion知识库供后续深度分析
整个过程完全自动化,而我只需每天花5分钟检查结果。这篇文章将完整分享我的实现方案,包括技术细节和实战经验。
二、Bright Data平台深度解析:网页抓取的工业级解决方案
为什么选择Bright Data?
Bright Data(原Luminati)是全球领先的网络数据平台,被15,000多家企业使用,包括财富500强公司。它提供两大核心解决方案:
- 代理网络基础设施:覆盖195个国家、7200万IP组成的代理网络,包括住宅IP、移动IP和数据中心IP
- 自动数据采集服务:提供零代码网页数据挖掘工具和定制化采集模板
核心优势对比
| 特性 | Bright Data | 普通爬虫工具 |
|---|---|---|
| IP规模 | 7200万+全球IP | 通常有限或需自建 |
| 合规性 | GDPR/CCPA认证 | 风险较高 |
| 成功率 | 99.95% | 受反爬限制大 |
| 定位精度 | 可定位到城市级 | 通常国家级别 |
| 数据清洗 | 自动结构化 | 需手动处理 |
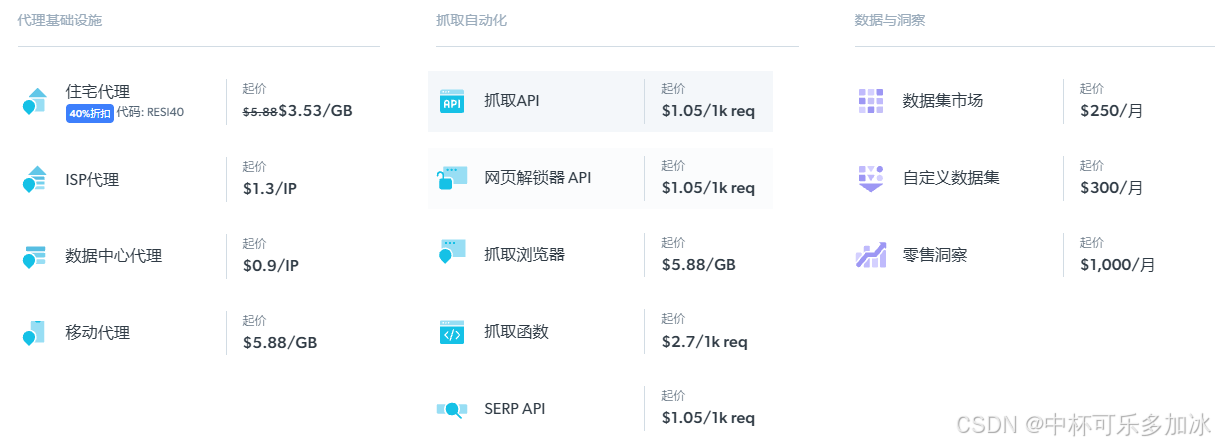
定价方案入门建议
对于个人开发者和小团队,我推荐从抓取API开始试用。当然若有任务需求,还需自行选择。
三、实战:用Bright Data爬取VentureBeat科技新闻
配置爬虫任务
1.注册Bright Data账号:访问官网完成--->注册
注册成功后,我们选择浏览器API
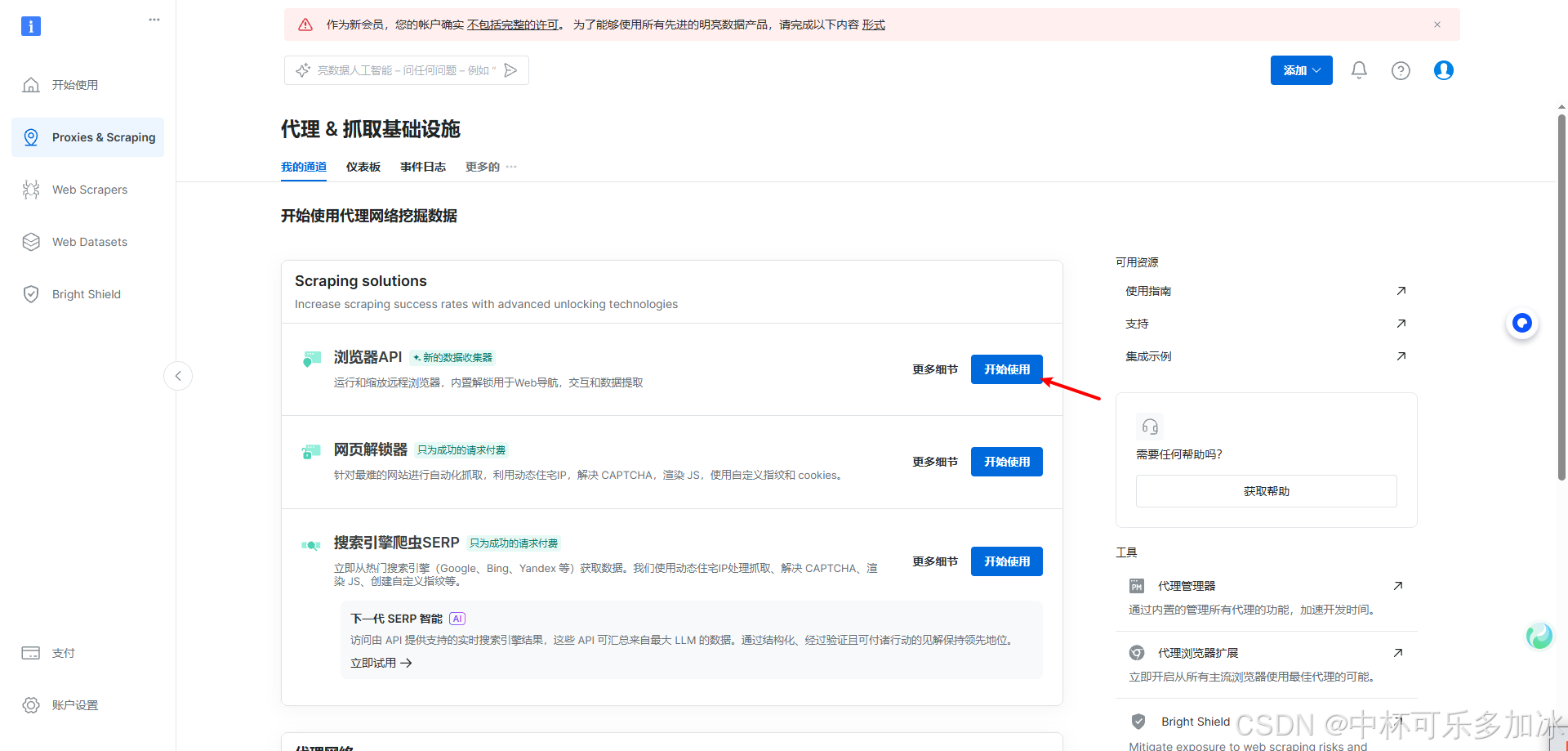
上面可以选择默认,最后我们选择添加:
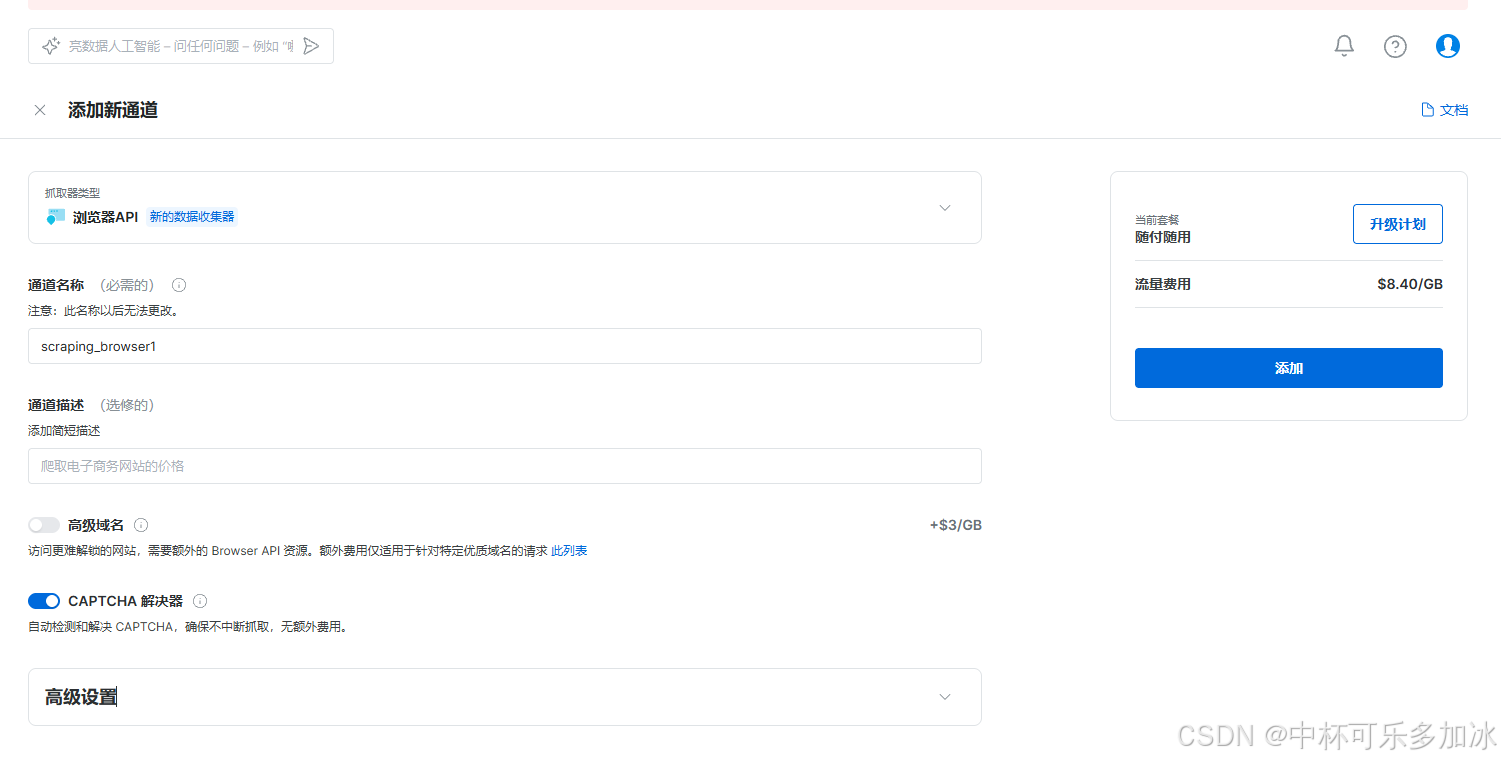
接下来我们等待片刻,在详情里面可以查看到自己的用户名和密码等信息
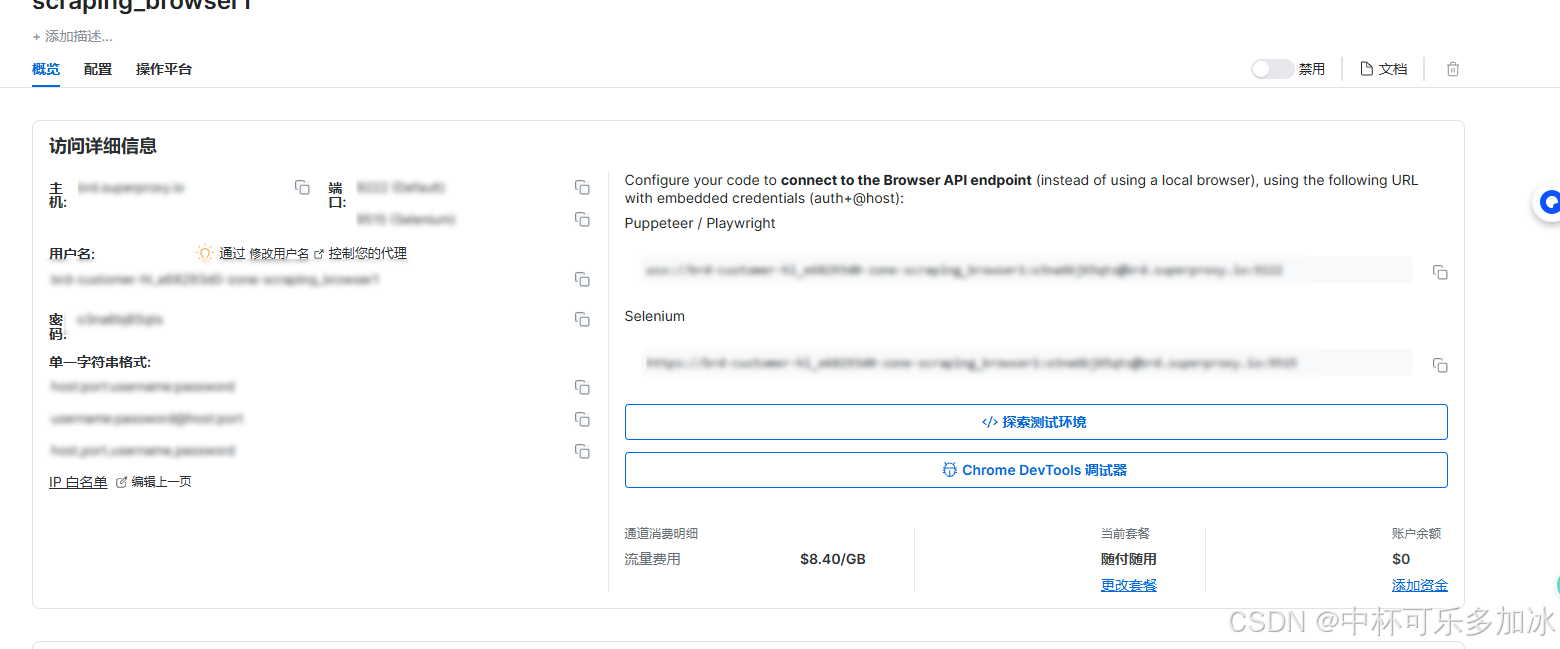
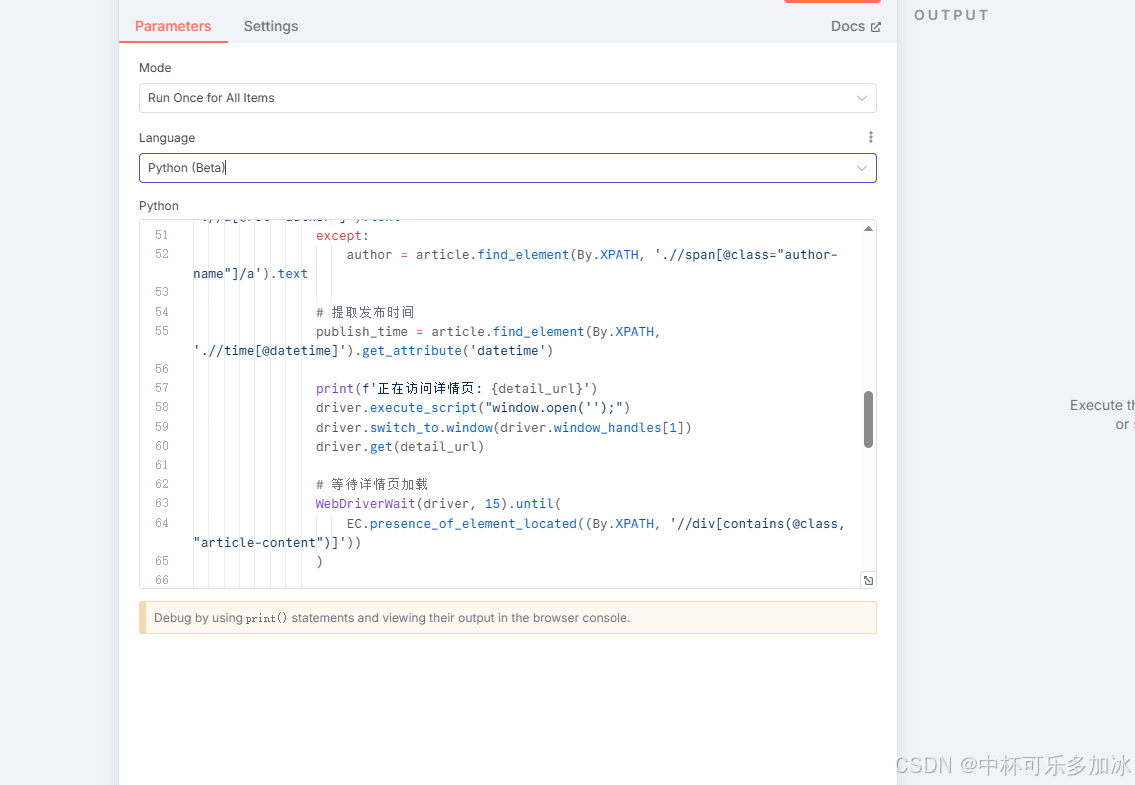
接下来我们使用Python代码进行获取数据
- 设置目标网站:输入VentureBeat的AI/IT板块URL(如https://venturebeat.com/ai/)
- 定义抓取字段:文章标题、发布时间、作者信息、正文内容
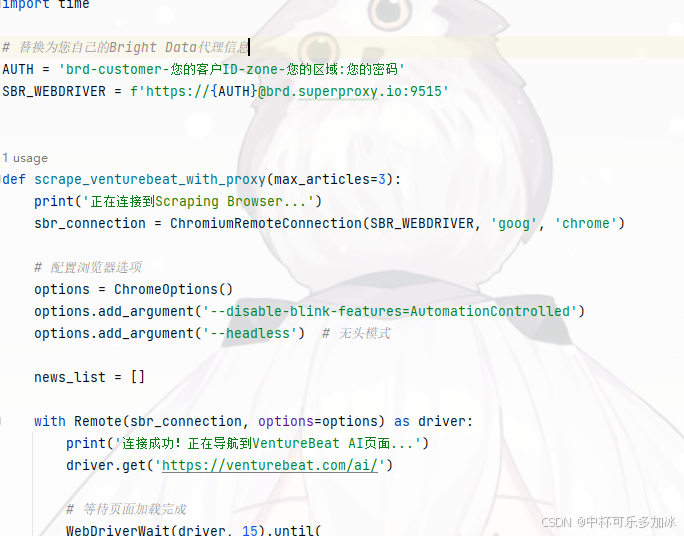
详情代码如下:
python
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.common.by import By
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import json
import time
# 替换为您自己的Bright Data代理信息
AUTH = 'brd-customer-您的客户ID-zone-您的区域:您的密码'
SBR_WEBDRIVER = f'https://{AUTH}@brd.superproxy.io:9515'
def scrape_venturebeat_with_proxy(max_articles=3):
print('正在连接到Scraping Browser...')
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
# 配置浏览器选项
options = ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--headless') # 无头模式
news_list = []
with Remote(sbr_connection, options=options) as driver:
print('连接成功!正在导航到VentureBeat AI页面...')
driver.get('https://venturebeat.com/ai/')
# 等待页面加载完成
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.XPATH, '//article'))
)
print('页面加载完成!正在提取新闻数据...')
# 获取新闻文章列表
articles = driver.find_elements(By.XPATH, '//article[contains(@class, "article")]')[:max_articles]
for idx, article in enumerate(articles):
try:
print(f'正在处理第 {idx + 1} 篇文章...')
# 提取标题和详情URL
title_element = article.find_element(By.XPATH, './/h2/a')
title = title_element.text
detail_url = title_element.get_attribute('href')
# 提取作者
try:
author = article.find_element(By.XPATH, './/a[@rel="author"]').text
except:
author = article.find_element(By.XPATH, './/span[@class="author-name"]/a').text
# 提取发布时间
publish_time = article.find_element(By.XPATH, './/time[@datetime]').get_attribute('datetime')
print(f'正在访问详情页: {detail_url}')
driver.execute_script("window.open('');")
driver.switch_to.window(driver.window_handles[1])
driver.get(detail_url)
# 等待详情页加载
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.XPATH, '//div[contains(@class, "article-content")]'))
)
# 提取正文内容
content_elements = driver.find_elements(By.XPATH, '//div[contains(@class, "article-content")]//p')
content = "\n".join([p.text for p in content_elements if p.text.strip()])
# 关闭详情页标签
driver.close()
driver.switch_to.window(driver.window_handles[0])
# 添加到结果列表
news_list.append({
"title": title,
"author": author,
"publish_time": publish_time,
"url": detail_url,
"content": content
})
# 添加延迟避免被封
time.sleep(2)
except Exception as e:
print(f'处理第 {idx + 1} 篇文章时出错: {str(e)}')
# 确保回到主窗口
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(driver.window_handles[0])
continue
# 保存为JSON
with open('venturebeat_latest_news.json', 'w', encoding='utf-8') as f:
json.dump(news_list, f, ensure_ascii=False, indent=2)
print(f'成功爬取 {len(news_list)} 篇最新新闻,已保存到 venturebeat_latest_news.json')
if __name__ == '__main__':
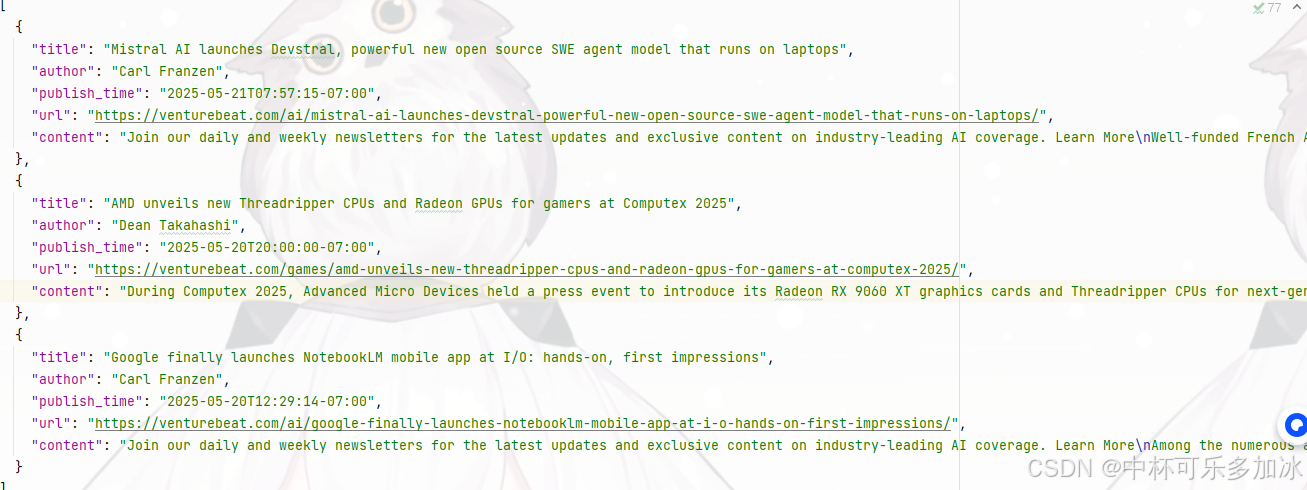
scrape_venturebeat_with_proxy(max_articles=3)最后我们就可以爬取到 网站前三条的新闻信息了
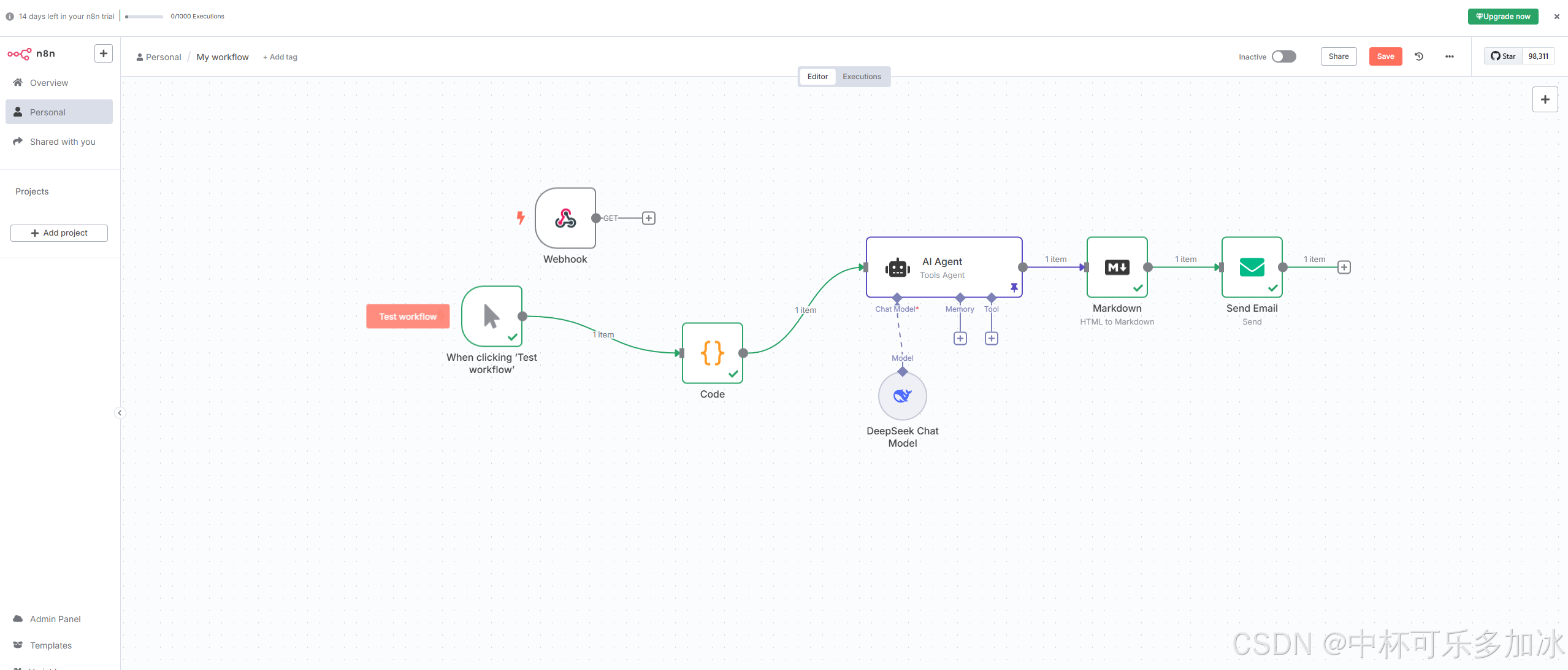
四、n8n工作流搭建:从数据到分发的全自动化
n8n核心概念速览
n8n是一款开源工作流自动化工具,相比Zapier/Make等商业产品,它具有以下优势:
- 完全开源,可自托管
- 支持400+应用集成
- 灵活插入自定义代码(JS/Python)
- 强大的AI节点 支持(OpenAI、LangChain等)
自动化新闻工作流设计
我的完整工作流包含以下关键节点:
- Bright Data触发器 :每天固定时间接收新抓取的新闻数据
- OpenAI摘要节点:生成100字中文摘要
bash
"请为以下英文科技新闻生成一段专业的中文摘要(80-100字),要求:
首句点明核心创新或发现
中间陈述关键数据或事实
结尾指出潜在影响
保持客观专业的语气
新闻标题:{{$json.title}}
新闻内容:{{$json.content}}"
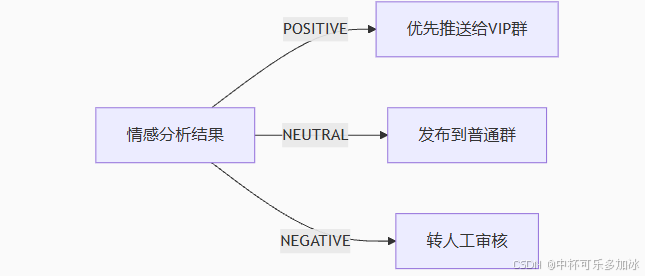
- 情感分析节点:判断新闻倾向性(正面/中性/负面)(选做)
- 多平台分发节点:Telegram频道发布(可参考:https://mp.weixin.qq.com/s/PNChdUYUFgVPGRn2Z1JZ6A)、企业微信群机器人推送、邮件列表发送
- Notion存档节点:结构化存储原始数据和摘要
下图为工作流简易示意图,较为简单,感兴趣的小伙伴可以自行搭建并丰富:
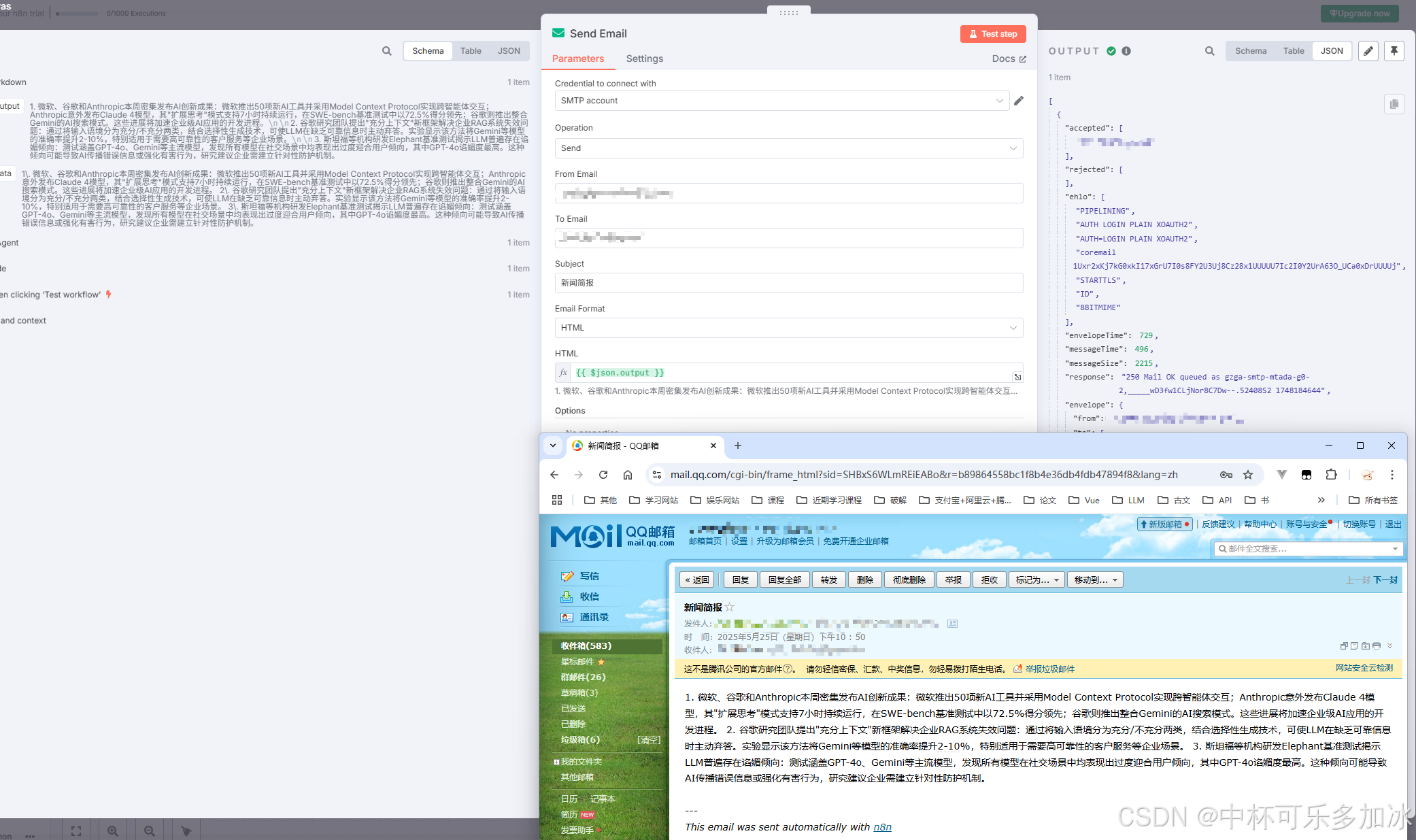
下图是采用邮箱发送的案例结果示意图
在原来流程的基础上,我们也可以进行优化一下,下图为具体实施步骤
五、扩展应用与优化策略
多语言支持方案
通过添加翻译节点,可以轻松实现多语言摘要:
- 原始英文→中文摘要(主要受众)
- 中文摘要→英文/日文等(国际化受众)
- 各语言版本同步发布到对应社群
商业化变现路径
这套系统不仅提升效率,还能创造收入:
- XXX营销:在摘要中添加相关产品推荐链接
- 付费订阅:提供独家深度分析版本
- 数据服务:向企业销售行业趋势分析报告
六、结语:自动化内容生产的未来
通过Bright Data+n8n+AI的组合,我成功将每日内容运营时间从3小时缩短到30分钟以内,重要的是全程自动化采集处理,社群活跃度提升了65%,专业影响力显著增强。这套方案的核心价值在于:
- 可扩展性:随时添加更多新闻源和分发渠道
- 适应性:通过调整AI提示词适应不同领域
- 商业潜力:为知识付费和流量变现奠定基础
如果你也是内容创作者或社群运营者,我强烈建议从简单的工作流开始尝试。Bright Data提供$500试用额度,n8n有完全免费的社区版,投入1-2天学习就能开启你的自动化内容生产之旅!
自动化不是要取代创作者,而是让我们从重复劳动中解放,专注于真正需要人类创造力的工作。期待在AI赋能的内容创作新时代与你同行!欢迎使用Bright Data!