一.功能介绍
图像叠加:就是在一张图片上放上自己想要的图片,如LOGO,时间等。**有点像之前提到的OSD原理一样。**例如:下图一张图片,在左上角增加其他图片。

二.OPENCV中图像叠加常用的API
1. copyTo方法进行图像叠加
- 原理: 在图片1中选取一个 Rect 的兴趣区域(也就是自己想要放哪,放多大),然后把图2放在兴趣区域,最后输出图片1。**注意:这个兴趣区域要和图2一样大小。**例如:图1为原图,图2为杰伦。

-
API: void copyTo( OutputArray m ) const
-
代码实现:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#includeusing namespace cv;
using namespace std;int main()
{
//读取图像
Mat src_pic = imread("frame1.jpg"); //src_pic是原图像数据
Mat logo_pic = imread("mat_demo.jpg");//logo_pic是LOGO图像的数据//创建兴趣区域 Mat logo_pic_roi = src_pic(Rect(0,0,logo_pic.cols, logo_pic.rows)); //在src_pic上创建一个矩形区域,大小与logo_pic相同 //将logo_pic复制到logo_pic_roi中 logo_pic.copyTo(logo_pic_roi); //显示图像 imwrite("result.jpg", src_pic); return 0;}
2. addWeighted方法对图像数据进行图像叠加
- 原理: 和copyTo一样,只不过多了一个加权操作**(加权:1 = 图片1的权重+图片2的权重,谁的权重高,谁更清楚,更清晰)**,然后输出新图片。
- API: addWeighted(InputArray src1, double alpha, InputArray src2, double beta, double gamma, OutputArray dst, intdtype = -1);
第一个参数:src1,第一个输入的图像
第二个参数:alpha,第一个输入图像的权重值,是一个双精度浮点数
第三个参数:src2,第二个输入图像
第四个参数:beta,第二个输入图像的权重,是一个双精度浮点数
第五个参数:gamma 加权和的可选标量,通常是一个双精度浮点数,默认为 0
第六个参数:dst 输出图像,这里是存储加权图像的结果
第七个参数:输出图像的类型,默认是-1,表示的是输入图像和输出图像类型一致
上图是src1权重为0.8,下图是src1权重为0.3效果:
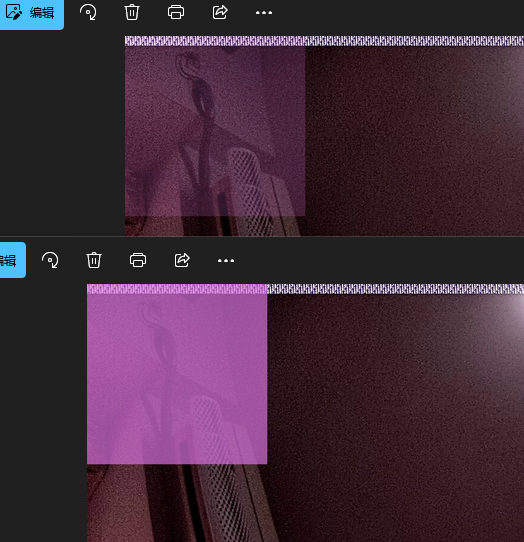
-
addWeighted的两种情况:1.两张图片大小不一样: 就是先在图片1上面创建感兴趣区域,然后融合感兴趣区域和图片2,最后输出图片1;**2.两张图片一样大:**直接融合两张图片,然后生成新图片。
-
代码实现:
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#includeusing namespace cv;
using namespace std;int main(int argc, char * argv[])
{Mat src1 = imread(argv[1]); //src1原图像的数据 Mat src2 = imread(argv[2]); //src2是LOGO图像的数据 //判断src1大小和src2大小是否相同,若不同则和copyTo函数一样操作 if(src1.size != src2.size) { //在src1中创建一个矩形区域(兴趣区域)和src2大小相同的图像 Mat image_roi = src1(Rect(0, 0, src2.cols, src2.rows)); //设置权重 double alpha = 0.8; double beta = 1 - alpha; int gamma = 0; //将src2和src1的矩形区域(兴趣区域)进行融合,并将结果存入image_roi中 addWeighted(image_roi, alpha, src2, beta, gamma, image_roi); imwrite("addweighted3.jpg", src1); } else { //src1和src2大小相同,直接进行加权操作 double alpha = 0.3; double beta = 1 - alpha; int gamma = 0; Mat dst; addWeighted(src1, alpha, src2, beta, gamma,dst); imwrite("addweighted2.jpg", dst); } return 0;}