机器学习入门核心算法:层次聚类算法(AGNES算法和 DIANA算法)
-
-
-
- 一、算法逻辑
- 二、算法原理与数学推导
-
- [1. 距离度量](#1. 距离度量)
- [2. 簇间距离计算(连接标准)](#2. 簇间距离计算(连接标准))
- [3. 算法伪代码(凝聚式)](#3. 算法伪代码(凝聚式))
- 三、模型评估
-
- [1. 内部评估指标](#1. 内部评估指标)
- [2. 外部评估指标(已知真实标签)](#2. 外部评估指标(已知真实标签))
- [3. 超参数选择](#3. 超参数选择)
- 四、应用案例
-
- [1. 生物信息学](#1. 生物信息学)
- [2. 文档主题分层](#2. 文档主题分层)
- [3. 图像分割](#3. 图像分割)
- [4. 社交网络分析](#4. 社交网络分析)
- 五、面试题及答案
- 六、相关论文
- 七、优缺点对比
- 总结
-
-
一、算法逻辑
层次聚类(Hierarchical Clustering)通过构建树状结构(树状图/Dendrogram)揭示数据内在的层次关系,分为两类:
-
凝聚式(Agglomerative)
-
自底向上:每个样本初始为一个簇 → 迭代合并最近簇 → 最终形成单一簇
-
流程 :
计算距离矩阵 → 合并最近簇 → 更新距离矩阵 → 重复至终止
-
-
分裂式(Divisive)
- 自顶向下:所有样本初始为一个簇 → 迭代分裂最异质簇 → 直至每个样本一簇
- 计算复杂度高,较少使用
核心特点:
- 无需预设聚类数
- 树状图可视化层次关系
- 合并/分裂过程不可逆
二、算法原理与数学推导
1. 距离度量
设样本 X = { x 1 , x 2 , . . . , x n } X = \{x_1, x_2, ..., x_n\} X={x1,x2,...,xn}, x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd
常用距离:
- 欧氏距离: d ( x i , x j ) = ∑ k = 1 d ( x i k − x j k ) 2 d(x_i, x_j) = \sqrt{\sum_{k=1}^d (x_{ik} - x_{jk})^2} d(xi,xj)=k=1∑d(xik−xjk)2
- 曼哈顿距离: d ( x i , x j ) = ∑ k = 1 d ∣ x i k − x j k ∣ d(x_i, x_j) = \sum_{k=1}^d |x_{ik} - x_{jk}| d(xi,xj)=k=1∑d∣xik−xjk∣
2. 簇间距离计算(连接标准)
| 类型 | 公式 | 特点 |
|---|---|---|
| 单连接 | d min ( C i , C j ) = min a ∈ C i , b ∈ C j d ( a , b ) d_{\text{min}}(C_i, C_j) = \min_{a \in C_i, b \in C_j} d(a,b) dmin(Ci,Cj)=a∈Ci,b∈Cjmind(a,b) | 易形成链式结构 |
| 全连接 | d max ( C i , C j ) = max a ∈ C i , b ∈ C j d ( a , b ) d_{\text{max}}(C_i, C_j) = \max_{a \in C_i, b \in C_j} d(a,b) dmax(Ci,Cj)=a∈Ci,b∈Cjmaxd(a,b) | 对噪声敏感 |
| 质心法 | d cent ( C i , C j ) = d ( μ i , μ j ) d_{\text{cent}}(C_i, C_j) = d(\mu_i, \mu_j) dcent(Ci,Cj)=d(μi,μj) | 可能导致逆反(Inversion) |
其中 μ i = 1 ∣ C i ∣ ∑ x ∈ C i x \mu_i = \frac{1}{|C_i|}\sum_{x \in C_i} x μi=∣Ci∣1∑x∈Cix 为簇质心, Δ SSE \Delta \text{SSE} ΔSSE 为合并后的簇内平方和增量。
3. 算法伪代码(凝聚式)
python
输入: 数据集 X, 连接标准
输出: 树状图
1. 初始化 n 个簇,每个簇包含一个样本
2. 计算所有簇对的距离矩阵 D
3. for k = n to 1:
4. 找到 D 中最小距离的簇对 (C_i, C_j)
5. 合并 C_i 和 C_j 为新簇 C_{new}
6. 更新距离矩阵 D(移除 C_i, C_j,添加 C_{new})
7. 记录合并高度(距离)
8. 生成树状图 三、模型评估
1. 内部评估指标
- 轮廓系数(Silhouette Coefficient) :
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}} s(i)=max{a(i),b(i)}b(i)−a(i)
a ( i ) a(i) a(i):样本 i i i 到同簇其他点的平均距离, b ( i ) b(i) b(i):到最近其他簇的平均距离。 s ( i ) ∈ − 1 , 1 s(i) \in -1,1 s(i)∈−1,1,越大越好。 - 共表型相关(Cophenetic Correlation) :
衡量树状图距离与原始距离的一致性(值接近1表示层次结构保留良好)
2. 外部评估指标(已知真实标签)
- 调整兰德指数(Adjusted Rand Index, ARI)
- Fowlkes-Mallows Index(FMI)
3. 超参数选择
- 切割高度选择:通过树状图的"最长无交叉垂直边"确定聚类数
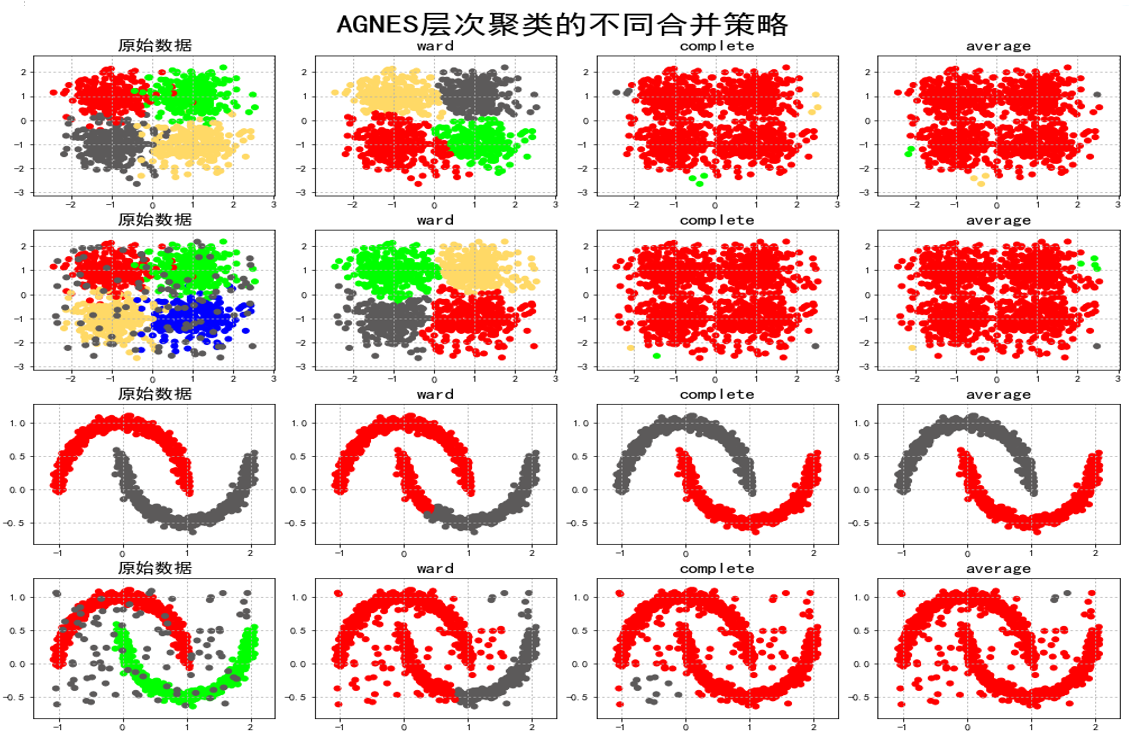
- 连接标准选择 :
- 单连接:适合非凸形状
- Ward法:适合凸簇且噪声少
四、应用案例
1. 生物信息学
- 基因表达聚类:对RNA-seq数据聚类,识别功能相似的基因模块
- 工具:GenePattern、Cluster 3.0
2. 文档主题分层
- 步骤 :
- 文档→TF-IDF向量
- 余弦距离 + 平均连接
- 切割树状图得到主题层级(如:科技→AI→CV/NLP)
3. 图像分割
- 流程 :
像素→颜色+坐标特征 → Ward法聚类 → 合并相似区域 - 优势:保留空间连续性
4. 社交网络分析
- 用户行为数据聚类 → 发现社区层级结构(如:核心用户群→子兴趣组)
五、面试题及答案
常见问题
-
Q : 层次聚类与K-means的本质区别?
A:- 层次聚类生成树状结构,K-means生成平面划分
- 层次聚类无需预设K,K-means需指定聚类数
- 层次聚类复杂度 O ( n 3 ) O(n^3) O(n3),K-means为 O ( n k ) O(nk) O(nk)
-
Q : Ward法的目标函数是什么?
A : 最小化合并后的簇内平方和增量:
Δ SSE = ∣ C i ∣ ∣ C j ∣ ∣ C i ∣ + ∣ C j ∣ ∥ μ i − μ j ∥ 2 \Delta \text{SSE} = \frac{|C_i||C_j|}{|C_i|+|C_j|} \|\mu_i - \mu_j\|^2 ΔSSE=∣Ci∣+∣Cj∣∣Ci∣∣Cj∣∥μi−μj∥2 -
Q : 何时选择全连接而非单连接?
A: 当需要紧凑球形簇且数据噪声较少时;单连接易受噪声影响形成链式结构。 -
Q : 如何处理大规模数据?
A:- 使用优先队列优化到 O ( n 2 log n ) O(n^2 \log n) O(n2logn)
- 采样或Mini-Batch
- 切换为BIRCH(平衡迭代规约聚类)算法
六、相关论文
-
奠基性论文:
- Ward, J. H. (1963). Hierarchical Grouping to Optimize an Objective Function
贡献:提出Ward最小方差法 - Johnson, S. C. (1967). Hierarchical Clustering Schemes
贡献:系统化连接标准
- Ward, J. H. (1963). Hierarchical Grouping to Optimize an Objective Function
-
高效优化:
- Murtagh, F. (1983). A Survey of Recent Advances in Hierarchical Clustering Algorithms
贡献 :提出 O ( n 2 ) O(n^2) O(n2) 单连接算法
- Murtagh, F. (1983). A Survey of Recent Advances in Hierarchical Clustering Algorithms
-
生物学应用:
- Eisen, M. B., et al. (1998). Cluster Analysis of Gene Expression Data
工具:开发TreeView软件
- Eisen, M. B., et al. (1998). Cluster Analysis of Gene Expression Data
七、优缺点对比
| 优点 | 缺点 |
|---|---|
| 1. 可视化强(树状图展示层次) | 1. 计算复杂度高(凝聚式 O ( n 3 ) O(n^3) O(n3)) |
| 2. 无需预设聚类数 | 2. 合并/分裂后不可逆 |
| 3. 灵活选择距离/连接标准 | 3. 对噪声和离群点敏感(尤其全连接) |
| 4. 适合层次结构数据(如生物分类学) | 4. 大样本内存消耗大 |
总结
- 核心价值:揭示数据内在层次关系(如生物进化树、文档主题树)
- 工业选择:中小规模数据用层次聚类(<10k样本),大规模用BIRCH或HDBSCAN
- 关键决策:距离度量 + 连接标准(Ward法最常用)
- 趋势:与深度学习结合(如深度层次聚类)