文章目录
一、支持向量机简述
1.概念
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
2.基本概念
超平面:超平面是SVM中用于分割不同类别数据的决策边界。在线性可分的情况下,SVM试图找到一个超平面,使得不同类别之间的间隔最大化。这个最大间隔确保了模型具有良好的泛化能力,即使面对未知数据也能做出准确的分类
支持向量:支持向量机的核心概念之一是支持向量。在SVM中,支持向量是指距离超平面最近的几个数据点,这些点正是最难分类的数据点,同时也是对决策边界最有影响力的点。如果这些支持向量发生变化,那么超平面的位置也会随之改变,从而影响整个模型的分类效果。
3.算法介绍
在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。
4.线性可分
对于一个数据集合可以画一条直线将两组数据点分开,这样的数据成为线性可分(linearly separable),如下图所示:
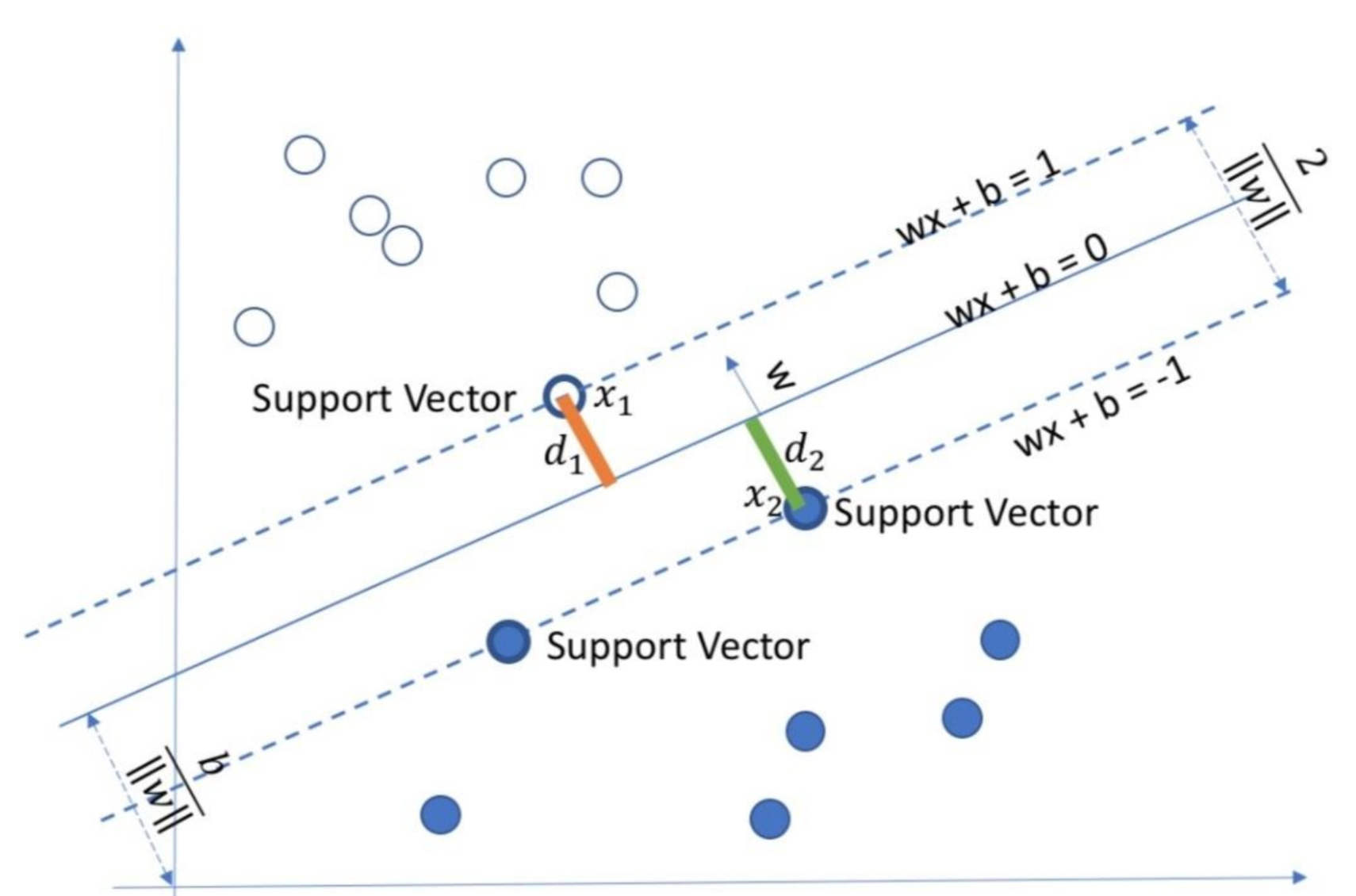
分割超平面 :将上述数据集分隔开来的直线成为分隔超平面。对于二维平面来说,分隔超平面就是一条直线。对于三维及三维以上的数据来说,分隔数据的是个平面,称为超平面,也就是分类的决策边界。
间隔 :点到分割面的距离,称为点相对于分割面的间隔。数据集所有点到分隔面的最小间隔的2倍,称为分类器或数据集的间隔。论文中提到的间隔多指这个间隔。SVM分类器就是要找最大的数据集间隔。
支持向量 :离分隔超平面最近的那些点。
SVM所做的工作就是找这样个超平面,能够将两个不同类别的样本划分开来,但是这种平面是不唯一的,即可能存在无数个超平面都可以将两种样本分开。
Vapnik提出了一种方法,对每一种可能的超平面,我们将它进行平移,直到它与空间中的样本向量相交。我们称这两个向量为支持向量,之后我们计算支持向量到该超平面的距离d,分类效果最好的超平面应该使d最大。
5.算法流程
(1)收集数据
(2)准备数据:需要数值型数据
(3)分析数据:有助于可视化分割超平面
(4)训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优
(5)测试算法
(6)使用算法:解决分类问题
二、实验
1.代码介绍
python
def process_email(email_contents):
# 转换为小写
email_contents = email_contents.lower()
# 移除HTML标签、处理URLs、电子邮件地址等
email_contents = re.sub(r'<[^<>]+>', ' ', email_contents)
email_contents = re.sub(r'(http|https)://[^\s]*', 'httpaddr', email_contents)
# ... 其他替换规则 ...
# 分词处理
words = re.split(r'[@$/#.-:&*+=\[\]?!(){},\'\">_<;% ]', email_contents)
# 初始化单词索引列表
word_indices = []
# 读取词汇表并处理每个单词
vocab_list = get_vocab_list()
for word in words:
# 移除非字母字符并检查单词长度
word = re.sub(r'[^a-zA-Z0-9]', '', word)
if len(word) < 1:
continue
# 获取单词在词汇表中的索引
if word in vocab_list:
word_indices.append(vocab_list[word])
return word_indices功能:将原始邮件文本转换为词汇表中的索引列表。
步骤:
转换为小写,移除 HTML 标签,替换 URL、邮箱地址等特殊格式
按非字母数字字符分割邮件内容
将每个单词映射到词汇表中的索引(如果存在)。
python
def email_features(word_indices):
# 获取词汇表大小
vocab_list = get_vocab_list()
n = len(vocab_list)
# 初始化特征向量
x = np.zeros(n)
# 设置对应索引的特征为1
for idx in word_indices:
x[idx-1] = 1 # 词汇表索引从1开始,特征向量索引从0开始
return x功能:将邮件的单词索引列表转换为特征向量(词袋模型)。
实现:
创建一个长度为词汇表大小的向量,每个位置表示一个单词。
如果某个单词在邮件中出现,则对应位置为 1,否则为 0。
python
def train_spam_classifier():
# 加载训练数据
data = sio.loadmat('spamTrain.mat')
X = data['X'] # 特征矩阵 (4000, 1899)
y = data['y'].ravel() # 标签向量
# 训练SVM分类器(线性核,C=0.1)
clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(X, y)
# 计算训练集准确率
p = clf.predict(X)
print(f'训练集准确率: {np.mean(p == y) * 100:.2f}%')
return clf
def test_spam_classifier(clf):
# 加载测试数据
data = sio.loadmat('spamTest.mat')
Xtest = data['Xtest']
ytest = data['ytest'].ravel()
# 计算测试集准确率
p = clf.predict(Xtest)
print(f'测试集准确率: {np.mean(p == ytest) * 100:.2f}%')功能:使用 SVM 训练分类器并评估性能。
关键点:
数据格式:X 是 4000×1899 的矩阵(4000 封邮件,1899 个特征)。
SVM 参数:
C=0.1:控制正则化强度,较小的值减少过拟合。
kernel='linear':线性核适合高维稀疏数据(如文本)。
python
def top_predictors(clf):
# 获取词汇表和SVM权重
vocab_list = get_vocab_list()
weights = clf.coef_[0]
# 获取权重排序后的索引(降序)
indices = np.argsort(-weights)
# 打印前15个预测能力最强的词汇
print('\nTop predictors of spam:')
for i in range(15):
for word, idx in vocab_list.items():
if idx == indices[i] + 1:
print(f'{word:15} {weights[indices[i]]:.6f}')
break功能:找出对预测垃圾邮件贡献最大的词汇。
原理:
SVM 的线性权重表示每个特征(单词)对分类的重要性。
权重越大,该单词越可能指示邮件是垃圾邮件。
python
def classify_new_email(clf, email_filename):
# 读取邮件内容并预处理
with open(email_filename, 'r') as f:
email_contents = f.read()
# 预处理邮件 → 特征向量 → 预测
word_indices = process_email(email_contents)
x = email_features(word_indices)
prediction = clf.predict(x.reshape(1, -1))
print(f'\n处理邮件: {email_filename}')
print(f'预测结果: {"垃圾邮件" if prediction[0] == 1 else "非垃圾邮件"}')功能:对新邮件进行分类预测。
流程:
读取邮件文本。
通过 process_email 转换为单词索引。
通过 email_features 转换为特征向量。
使用训练好的 SVM 模型预测类别。
2.模型流程
1.数据准备:
vocab.txt:包含 1899 个常用单词的词汇表。
spamTrain.mat 和 spamTest.mat:预提取的特征矩阵和标签。
2.训练阶段:
加载训练数据 → 训练 SVM 模型 → 评估训练集准确率。
3.测试阶段:
加载测试数据 → 评估测试集准确率。
4.预测阶段:
对新邮件进行预处理 → 提取特征 → 预测类别。
3.实验结果
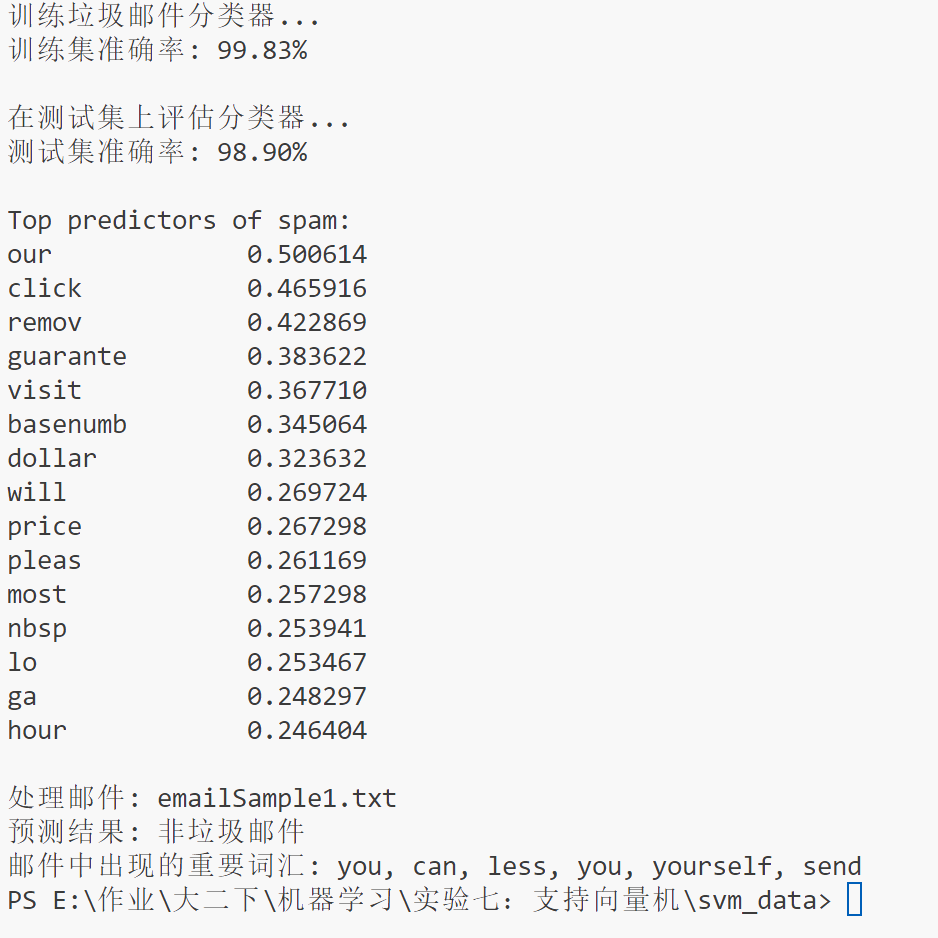
训练集准确率(99.83%)
在用于训练模型的数据集(spamTrain.mat 中提供的数据 )上,模型预测正确的样本数占总样本数的比例高达 99.83% 。这表明模型在学习训练数据的模式和规律方面表现极为出色,能够很好地对训练集中的垃圾邮件和非垃圾邮件进行区分。
测试集准确率(98.90%)
在未参与模型训练的测试数据集(spamTest.mat 中的数据 )上,模型预测正确的比例为 98.90% 。测试集准确率是衡量模型泛化能力的重要指标,说明模型在面对新的、未见过的数据时,也能较为准确地判断邮件是否为垃圾邮件。
与训练集准确率对比
测试集准确率略低于训练集准确率,但差距不大,这是比较理想的情况。一定程度的差距是正常的,因为训练集和测试集数据存在差异,只要差距不显著,就表明模型没有严重的过拟合问题,泛化性能良好。
Top predictors of spam
列出了对判断邮件是否为垃圾邮件贡献最大的词汇及其对应的权重。权重反映了该词汇在 SVM 模型决策过程中的重要性,权重越大,说明该词汇越倾向于指示邮件是垃圾邮件。
比如 "our" 权重为 0.500614 ,"click" 权重为 0.465916 ,意味着在模型看来,邮件中出现这些词时,更有可能是垃圾邮件。像 "click" 常出现在垃圾广告邮件诱导用户点击链接的场景中,"guarante"也常出现在虚假承诺的垃圾推销邮件里。
对新邮件的分类结果 (emailSample1.txt )
预测结果:判断 emailSample1.txt 为非垃圾邮件 。这是模型基于对该邮件文本进行预处理、特征提取后,通过已训练的 SVM 分类器进行预测得到的结论。
重要词汇:列出了邮件中出现的部分重要词汇,这些词汇在模型判断过程中具有一定作用。虽然它们整体上没有让模型判定该邮件为垃圾邮件,但这些词汇的出现情况也是模型决策的依据之一 。
4.实验小结
本次实验运用 SVM 构建垃圾邮件分类器。训练集准确率达 99.83% ,测试集准确率为 98.90% ,模型展现出良好的学习与泛化能力。通过合理设置 SVM 参数,结合有效的文本预处理及特征提取,使其能精准捕捉垃圾邮件特征。
从关键预测词汇看,"click""guarante" 等高频于垃圾邮件场景的词权重较高,为模型判断提供依据。对新邮件emailSample1.txt 的成功分类,验证了模型实际应用的有效性。但仍可在特征工程、参数调优上深入探索,进一步提升模型性能与适应性。