2024年认证杯SPSSPRO杯数学建模
D题 AI绘画带来的挑战
原题再现:
2023 年开年,ChatGPT 作为一款聊天型AI工具,成为了超越疫情的热门词条;而在AI的另一个分支------绘图领域,一款名为Midjourney(MJ)的软件,热度完全不亚于ChatGPT。AI绘画技术可以模仿设计师的风格和技巧,自动生成类似于人类设计师的设计作品。AI绘画技术可以应用于各种领域,包括绘画、插画、平面设计等,具有较高的效率和精度,能够大大提高创作效率和创作质量。然而,AI绘画技术也带来了一些挑战和风险。比如对于一些传统的美术设计类赛事组织方来说,AI绘画技术就带来了评奖公平性的挑战,由于一些设计作品很难快速判断出究竟是由AI设计的,还是由人类设计师设计的,所以赛事评奖工作变得异常复杂,当参赛作品较多的时候,很难保证最终的结果公平性,附图就是几幅由MJ软件设计的建筑图片,即使业内人士也不能保证做出准确的判断。请你和你的团队建立合理的数学模型以解答如下问题。
第二阶段问题:
1. 我们可以利用MJ软件来生成大量的AI设计图来作为识别AI设计的样本数据集,如果这种思路可行,你认为需要构建一个多大的数据集才能保证识别率超过80%?
2. 如果在今后的设计比赛中,使用AI进行设计辅助已经是不可避免,那么人的参与频次、参与深度、人与AI的信息交互内容等指标将成为打分的关键依据,请你结合第一阶段的模型,构建一个打分系统,通过一定的问卷调研数据来对设计作品进行评价。
整体求解过程概述(摘要)
本文详细分析了AI绘画带来的挑战。这一挑战主要涉及如何准确地从数学和技术角度区分AI和人类设计的作品,以及如何建立一个公正的评分系统来评估由AI辅助的设计作品。
随着AI工具如ChatGPT和Midjourney在设计领域的广泛应用,其高效、精准的模仿能力虽然提高了创作效率,但同时也给设计赛事的公平性评判带来了挑战。尤其是在判断作品的真实创作来源------是AI还是人类设计师------这一问题上,确保评奖的公正性显得尤为重要。
针对问题一,文章详细描述了如何确定构建一个足够大的样本数据集以确保超过80%的AI 与人类作品识别准确率。通过深入研究现有文献,采用图像特征提取技术(包括颜色分布、纹理分析、几何形状识别)和深度学习方法,开发了一个基于CNN的多输入判别模型。该模型通过多次交叉验证和使用不同的正则化技术来避免过拟合,并通过数据集大小的学习曲线来拟合所需的样本量,最终确定需要14745个样本来达到所需的识别准确率。
针对问题二:为了评估AI辅助设计作品的质量,我们构建了一个综合评分系统,涵盖设计质量评分(Qd)、人工与AI的交互频次(Fa)、人工参与的深度(Da)、交互内容质量(Cq)和综合技术指标(Tq)五个维度,使用加权平均法确定各指标的权重。通过设计问卷,专业评委对Qd和Tq进行评分,设计者对Fa、Da和Cq进行自评,然后我们自行设计了三幅建筑设计作品,控制不同的AI交互频次和人工参与深度,并结合所有评分数据,计算每幅作品的综合评分。结果表明,合理平衡AI与人工的作用,确保适当的交互频次和参与深度,可以有效提升设计作品的整体质量。
总体而言,文章为解决AI在设计领域带来的挑战提供了一个结构化和科学的方法,不仅增强了识别AI与人类设计作品的能力,还建立了一个公正的评分系统来评估AI 辅助的设计作品。这些方法不仅提高了评估的准确性,也确保了设计比赛的公平性和透明度。
问题分析:
问题一分析
在解决问题一,即确定构建多大的数据集以确保识别准确率超过80%的情况下,我们采取了多方面的分析和实验步骤。首先,通过研究相关文献并参考现有的资料,我们设计并实现了一系列用于判断AI绘图的模块。这些模块基于图像特征的提取,例如颜色分布、纹理分析和几何形状,是构建有效判别模型的基础。此外,我们还引入了基于深度学习的特征提取,如预训练神经网络的中间层输出,以捕获更复杂的图像特征。
接下来,我们在不同规模的数据集上训练了基于CNN的多输入判别模型。模型的训练和验证过程中,我们使用了交叉验证方法来确保评估结果的可靠性和模型的泛化能力。为了防止过拟合,我们还引入了dropout和L2正则化技术。通过这些模型,我们绘制了学习曲线,观察模型性能随数据集大小的变化。通过这些数据集的准确率绘制了模型的学习曲线图,然后通过三种方法(线性外推,三次多项式拟合,集成学习)预估了数据集的大小。
最终,通过综合考虑三种预估方法得优缺点以及多个机器学习模型的学习曲线,构建了数据集预估算法,得到当准确率达到80%时,所需要的数据集大小为14745
问题二的分析
随着人工智能(AI)技术在设计领域的广泛应用,设计比赛中使用AI进行设计辅助已成为不可避免的趋势。然而,如何公平地评估这些AI辅助设计作品,成为新的挑战。为了全面、公正地评价这些设计作品,本文结合5个维度的指标:
1. 设计质量评分(Qd):由专业评委对作品的美学质量、创新性、实用性和细节处理进行评分。
2. 人工与AI的交互频次(𝐹a):衡量设计者在设计过程中与AI交互的次数。
3. 人工参与的深度(𝐷a):量化设计者在设计过程中的参与深度。
4. 交互内容质量(𝐶q):评估设计者在与AI交互过程中内容的有效性和创造性。
5. 综合技术指标(Tq):包括纹理一致性、光影处理、透视准确性和色彩一致性。 然后通过加权平均法确定各指标的权重,最终建立一个综合评分公式:
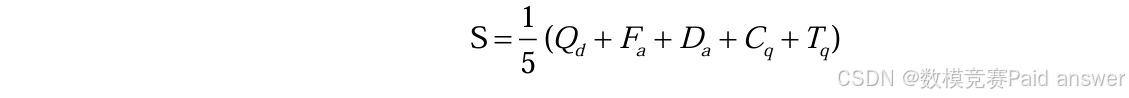
该综合评分系统能够科学、公正地评估 AI 辅助设计的作品,确保评分过程的公平性和准确性。然后再针对设计质量评分(Qd),综合技术指标(Tq)这2个部分设计一份问卷给专业评委打分,其中综合技术的部分指标结合第一阶段确定的特征提取的方法进行打分,人工与AI的交互频次(𝐹a),人工参与的深度(𝐷a),交互内容质量(𝐶q)则设计问卷给设计者自评。
模型假设:
特征差异性假设:
假设AI和人类设计师生成的作品在几何一致性、纹理细节、色彩搭配、透视准确性以及风格特征上存在可识别的差异。这些差异可以通过适当的图像处理技术和特征提取算法捕捉到。
独立同分布假设:
假设训练数据和将要预测的数据是独立同分布的。这意味着训练集中的数据分布与实际应用中遇到的数据分布相同,保证模型在实际应用中的有效性。
评价系统公正性假设:
在对AI辅助设计作品进行评分时,假设评价标准公正、客观,能够真实反映作品的设计质量和技术水平。此外,假设评分过程中人的主观判断与AI分析结果的结合是合理的,可以准确评估作品的质量。
完整论文缩略图

全部论文请见下方" 只会建模 QQ名片" 点击QQ名片即可
部分程序代码:
python
import cv2
import numpy as np
def extract_geometric_features(image_path):
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
# 使用霍夫变换检测线条
lines = cv2.HoughLinesP(edges, 1, np.pi/180, threshold=50,
minLineLength=100, maxLineGap=10)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(image, (x1, y1), (x2, y2), (255, 0, 0), 2)
return image
# 使用函数
result_image = extract_geometric_features('path_to_your_image.jpg')
cv2.imshow('Geometric Features', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
def analyze_light_shadow_features(image_path):
image = cv2.imread(image_path)
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
lightness = hsv[:, :, 2].mean() # 获取亮度通道的平均值
contrast = image.std() # 计算标准差以评估对比度
return lightness, contrast
def color_histogram_features(image_path):
image = cv2.imread(image_path)
hist = cv2.calcHist([image], [0, 1, 2], None, [256, 256, 256], [0, 256,
0, 256, 0, 256])
cv2.normalize(hist, hist)
return hist.flatten()
from tensorflow.keras.applications.vgg19 import VGG19, preprocess_input
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
def extract_texture_features(image_path):
model = VGG19(weights='imagenet', include_top=False)
model = Model(inputs=model.inputs,
outputs=model.get_layer('block5_conv4').output)
img = image.load_img(image_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
features = model.predict(img_array)
return features.mean(axis=(0, 1, 2))
# 继续使用 VGG19 模型进行风格特征的提取
def extract_style_features(image_path):
# 同上使用 VGG19 的某层输出进行风格特征分析
return extract_texture_features(image_path) # 使用相同的方法,目标层可能有所不同
import cv2
import numpy as np
from tensorflow.keras.models import load_model
def extract_structure_and_proportion_features(image_path):
# 加载预训练的模型(此处假设模型已加载)
model = load_model('path_to_your_pretrained_model.h5')
image = cv2.imread(image_path)
image_resized = cv2.resize(image, (224, 224))
# 对图像进行预处理并进行预测
img_array = np.expand_dims(image_resized, axis=0)
detections = model.predict(img_array)
# 解析检测结果,提取结构和比例特征
features = []
for detection in detections:
# 假设detection 包括边界框和类别标签
x, y, width, height, label = detection
features.append((label, x, y, width, height))
return features
from tensorflow.keras.applications.vgg19 import VGG19, preprocess_input
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
def extract_layout_features(image_path):
model = VGG19(weights='imagenet', include_top=False)
model = Model(inputs=model.inputs,
outputs=model.get_layer('block5_pool').output)
img = image.load_img(image_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
# 这将给出图像的高级特征,可以用于理解图像布局
features = model.predict(img_array)
layout_features = features.mean(axis=(0, 1, 2))
return layout_features
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dense, Flatten, Dropout
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
# 加载预训练的VGG16模型,不包括顶层
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224,
224, 3))
# 冻结基模型的所有层,这些层不会在训练中更新
for layer in base_model.layers:
layer.trainable = False
# 添加新的顶层
x = Flatten()(base_model.output)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(1, activation='sigmoid')(x)
# 构建整个模型
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer=Adam(lr=0.0001), loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(
train_generator,
epochs=10,
validation_data=validation_generator
)
model.save('path_to_save_model.h5')
from tensorflow.keras.layers import Input, Dense, concatenate
from tensorflow.keras.models import Model
# 假设特征维度
input_geom = Input(shape=(geom_feature_size,))
input_color = Input(shape=(color_feature_size,))
input_texture = Input(shape=(texture_feature_size,))
# 可以为每种特征单独添加处理层
x_geom = Dense(64, activation='relu')(input_geom)
x_color = Dense(64, activation='relu')(input_color)
x_texture = Dense(64, activation='relu')(input_texture)
# 合并特征
combined_features = concatenate([x_geom, x_color, x_texture])
# 添加更多层
x = Dense(128, activation='relu')(combined_features)
output = Dense(1, activation='sigmoid')(x)
# 创建模型
model = Model(inputs=[input_geom, input_color, input_texture],
outputs=output)
model.fit(
[train_geom_features, train_color_features, train_texture_features],
train_labels,
validation_data=([val_geom_features, val_color_features,
val_texture_features], val_labels),
epochs=10,
batch_size=32
)
from tensorflow.keras.layers import Input, Dense, concatenate, Dropout
from tensorflow.keras.models import Model