文章目录
- 回归任务相关损失函数
-
- [1.均方误差(Mean Squared Error,MSE)](#1.均方误差(Mean Squared Error,MSE))
- [2.平均绝对误差(Mean Absolute Error,MAE)](#2.平均绝对误差(Mean Absolute Error,MAE))
- 3.Huber损失函数
- 分类任务相关损失函数
-
- [1. 交叉熵](#1. 交叉熵)
- [2. 信息量](#2. 信息量)
- [3. 熵](#3. 熵)
- [4. 相对熵(KL散度)](#4. 相对熵(KL散度))
- [5. 交叉熵](#5. 交叉熵)
- [6. CrossEntropyLoss](#6. CrossEntropyLoss)
- [7. 二分类交叉熵binary_cross_entropy](#7. 二分类交叉熵binary_cross_entropy)
回归任务相关损失函数
1.均方误差(Mean Squared Error,MSE)
定义
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
其中:
- n n n 是样本数量
- y i y_i yi 是第 i i i 个样本的真实值
- y ^ i \hat{y}_i y^i 是第 i i i 个样本的预测值
特点
- 计算简单:只需计算预测值与真实值差值的平方平均
- 误差放大效应:平方处理放大了较大误差的影响,使模型对显著预测错误更敏感
- 性能度量:能准确反映预测值与真实值的平均差异程度
- 应用广泛:回归问题最常用的损失函数之一(又称L2损失)
- 可微性:处处可微的特性便于梯度下降优化
- 对异常值敏感:MSE的平方特性使其对异常值敏感,在存在离群点的数据中可能需要考虑其他鲁棒性更强的损失函数。
2.平均绝对误差(Mean Absolute Error,MAE)
定义
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
特点
- 鲁棒性强:直接计算绝对误差平均值,对异常值不敏感(相比MSE)
- 计算特性 :
- 未对误差平方,避免过度放大异常值影响
- 在零点不可导,可能导致某些优化算法收敛较慢
- 别称:L1损失
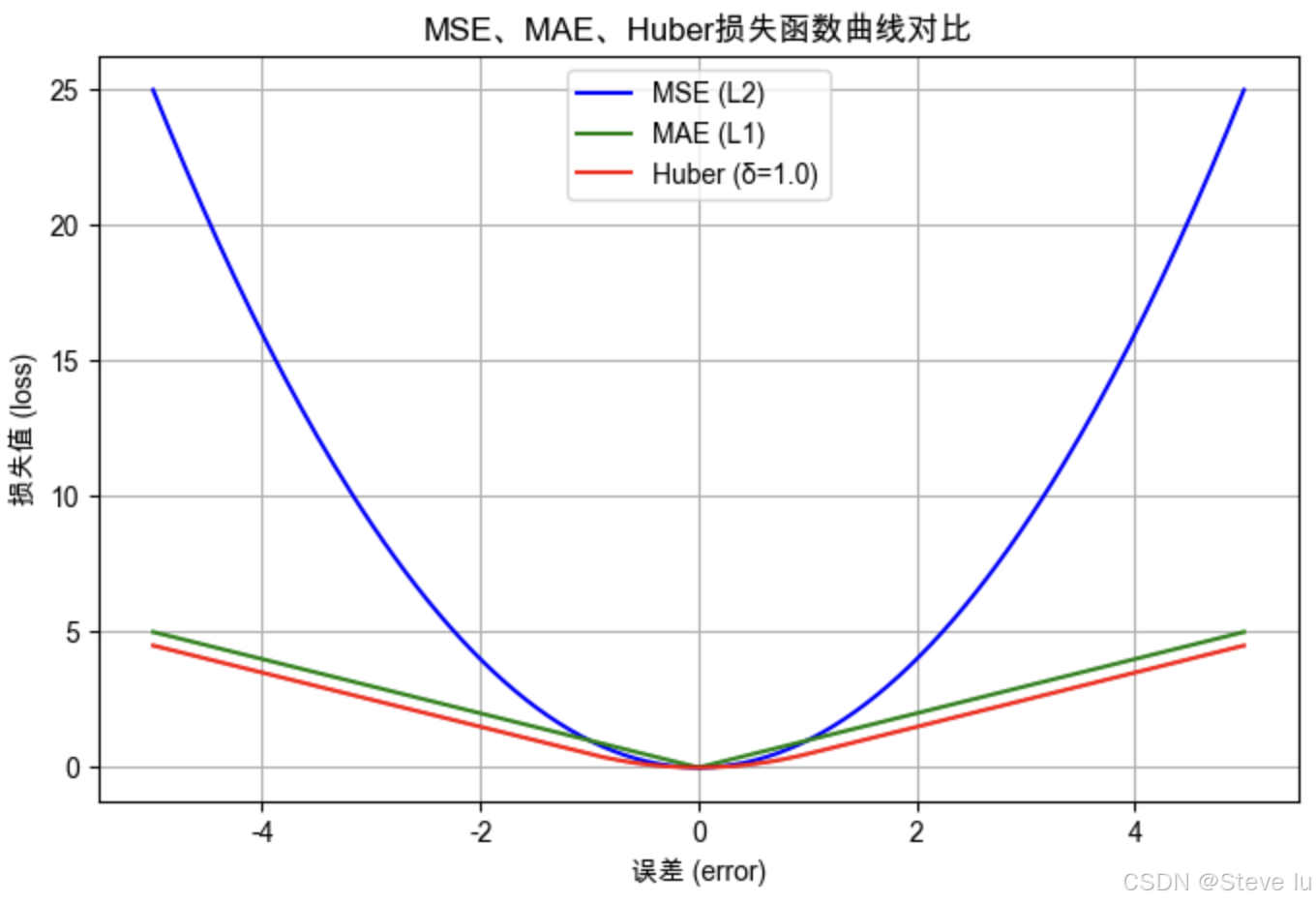
3.Huber损失函数
定义
L ( y , y ^ ) = { 1 2 ( y − y ^ ) 2 , ∣ y − y ^ ∣ ≤ δ δ ∣ y − y ^ ∣ − 1 2 δ 2 , ∣ y − y ^ ∣ > δ L(y, \hat{y}) = \begin{cases} \frac{1}{2}(y - \hat{y})^2, & |y - \hat{y}| \leq \delta \\ \delta |y - \hat{y}| - \frac{1}{2}\delta^2, & |y - \hat{y}| > \delta \end{cases} L(y,y^)={21(y−y^)2,δ∣y−y^∣−21δ2,∣y−y^∣≤δ∣y−y^∣>δ
其中 δ \delta δ 是控制误差敏感度的超参数。
特点
- 混合特性 :
- 小误差时( ∣ y − y ^ ∣ ≤ δ |y-\hat{y}| \leq \delta ∣y−y^∣≤δ)表现类似MSE,保证可导性
- 大误差时( ∣ y − y ^ ∣ > δ |y-\hat{y}| > \delta ∣y−y^∣>δ)表现类似MAE,增强鲁棒性
- 别称:Smooth L1损失
注:Huber损失需要手动设置 δ \delta δ值,通常取1.0作为默认值
分类任务相关损失函数
1. 交叉熵
熵是信息论中的⼀个概念,要想了解交叉熵的本质,需要先从最基本的概念讲起
2. 信息量
⾸先是信息量。假设我们听到了两件事,分别如下:
事件A:巴西队进⼊了2018世界杯决赛圈。
事件B:中国队进⼊了2018世界杯决赛圈。
仅凭直觉来说,显⽽易⻅事件B的信息量⽐事件A的信息量要⼤。究其原因,是因为事件A发⽣的概率很⼤,事件B发⽣的概率很⼩。所以当越不可能的事件发⽣了,我们获取到的信息量就越⼤。越可能发⽣的事件发⽣了,我们获取到的信息量就越⼩。那么信息量⼤⼩应该和事件发⽣的概率是负相关
假设 X X X 是一个离散型随机变量,其取值集合为 χ \chi χ,概率分布函数 p ( x ) = P r ( X = x ) , x ∈ χ p(x) = Pr(X = x), x \in \chi p(x)=Pr(X=x),x∈χ,则定义事件 X = x 0 X = x_0 X=x0 的信息量为:
I ( x 0 ) = − log ( p ( x 0 ) ) I(x_0) = -\log(p(x_0)) I(x0)=−log(p(x0))
由于是概率,所以 p ( x 0 ) p(x_0) p(x0) 的取值范围是 0 , 1 0, 1 0,1
3. 熵
对于某个事件,有 n n n 种可能性,每一种可能性都有一个概率 p ( x i ) p(x_i) p(xi)。这样就可以计算出某一种可能性的信息量。举一个例子,假设你拿出了你的电脑,按下开关,会有三种可能性,下表列出了每一种可能的概率及其对应的信息量:
| 序号 | 事件 | 概率 p p p | 信息量 − log ( p ) -\log(p) −log(p) |
|---|---|---|---|
| A | 电脑正常开机 | 0.7 | 0.36 |
| B | 电脑无法开机 | 0.2 | 1.61 |
| C | 电脑爆炸了 | 0.1 | 2.30 |
注:文中的对数均为自然对数
我们现在有了信息量的定义,⽽熵⽤来表⽰所有信息量的期望,即:
H ( X ) = − ∑ i = 1 n p ( x i ) log ( p ( x i ) ) H(X) = - \sum_{i=1}^n p(x_i) \log(p(x_i)) H(X)=−i=1∑np(xi)log(p(xi))
其中 n n n 代表所有的 n n n 种可能性,所以上面的问题结果就是:
H ( X ) = − p ( A ) log ( p ( A ) ) + p ( B ) log ( p ( B ) ) + p ( C ) log ( p ( C ) ) = 0.7 × 0.36 + 0.2 × 1.61 + 0.1 × 2.30 = 0.804 \begin{aligned} H(X) &= -p(A)\\log(p(A)) + p(B)\\log(p(B)) + p(C)\\log(p(C)) \\ &= 0.7 \times 0.36 + 0.2 \times 1.61 + 0.1 \times 2.30 \\ &= 0.804 \end{aligned} H(X)=−p(A)log(p(A))+p(B)log(p(B))+p(C)log(p(C))=0.7×0.36+0.2×1.61+0.1×2.30=0.804
4. 相对熵(KL散度)
相对熵又称KL散度。如果我们对于同一个随机变量 x x x 有两个单独的概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x),可以使用KL散度(Kullback-Leibler divergence)来衡量这两个分布的差异。
在机器学习中:
- P P P 表示样本的真实分布(ground truth),如 1 , 0 , 0 1,0,0 1,0,0 表示当前样本属于第一类
- Q Q Q 表示模型预测的分布,如 0.7 , 0.2 , 0.1 0.7, 0.2, 0.1 0.7,0.2,0.1
KL散度计算公式:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) D_{KL}(p||q) = \sum_{i=1}^n p(x_i) \log\left(\frac{p(x_i)}{q(x_i)}\right) DKL(p∣∣q)=i=1∑np(xi)log(q(xi)p(xi))
其中:
- n n n 为事件的所有可能性
- D K L D_{KL} DKL 值越小,表示 q q q 分布越接近 p p p 分布
PyTorch实现:KLDivLoss
5. 交叉熵
对KL散度公式变形可得:
D K L ( p ∣ ∣ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) ) − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) = − H ( p ( x ) ) + − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) \begin{aligned} D_{KL}(p||q) &= \sum_{i=1}^n p(x_i) \log(p(x_i)) - \sum_{i=1}^n p(x_i) \log(q(x_i)) \\ &= -H(p(x)) + \left-\\sum_{i=1}\^n p(x_i) \\log(q(x_i))\\right \end{aligned} DKL(p∣∣q)=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(p(x))+−i=1∑np(xi)log(q(xi))
在机器学习中:
- p p p 代表真实值
- q q q 代表预测值
- 由于 − H ( p ( x ) ) -H(p(x)) −H(p(x)) 是固定值,优化时只需关注交叉熵部分
交叉熵公式:
H ( p , q ) = − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) H(p,q) = -\sum_{i=1}^n p(x_i) \log(q(x_i)) H(p,q)=−i=1∑np(xi)log(q(xi))
6. CrossEntropyLoss
PyTorch在计算二分类或者互斥的多分类问题时,使用的是softmax交叉熵损失计算。
- 对输入进行softmax
S j = e a j ∑ k = 1 T e a k S_j = \frac{e^{a_j}}{\sum_{k=1}^{T} e^{a_k}} Sj=∑k=1Teakeaj
假设有一个数组 a a a, a i a_i ai 表示 a a a 中的第 i i i 个元素。计算的是元素的指数与所有元素指数的比值。
假设输入 a = 0.5 , 1.5 , 0.1 a=0.5,1.5,0.1 a=0.5,1.5,0.1,那么经过softmax层后就会得到 0.227863 , 0.61939586 , 0.15274114 0.227863, 0.61939586, 0.15274114 0.227863,0.61939586,0.15274114,这三个数字表示这个样本属于第1,2,3类的概率分别是 0.227863 0.227863 0.227863、 0.61939586 0.61939586 0.61939586、 0.15274114 0.15274114 0.15274114。
NumPy实现示例
python
import numpy as np
arr = np.array([[0.5,1.5,0.1]])
def softmax(x):
exp = np.exp(x)
sum_exp = np.sum(np.exp(x), axis=1, keepdims=True)
softmax = exp / sum_exp
return softmax
print(softmax(arr))[[0.227863 0.61939586 0.15274114]]通过pytorch的 softmax ⽅法可以更直接获得结果
python
import torch
tensor = torch.tensor([[0.5,1.5,0.1]])
print(tensor.softmax(1).numpy())
# 或者
from torch import nn
m = nn.Softmax(dim=1)
print(m(tensor).numpy())[[0.22786303 0.6193959 0.15274116]]
[[0.22786303 0.6193959 0.15274116]]- 计算交叉熵
交叉熵损失函数定义为:
L = − ∑ j = 1 T y j log S j L = - \sum_{j=1}^T y_j \log S_j L=−j=1∑TyjlogSj
其中:
- L L L 是损失值
- S j S_j Sj 是softmax输出向量 S S S的第 j j j个值,表示样本属于第 j j j个类别的概率
- y j y_j yj 是真实标签的one-hot编码( 1 × T 1 \times T 1×T向量,只有一个位置为1,其余为0)
由于 y y y中只有一个值为1,公式可简化为:
L = − log S j L = -\log S_j L=−logSj
即只需计算真实类别对应的概率的对数值。
PyTorch实现示例
python
tensor = torch.tensor([[0.5,1.5,0.1]])
print(tensor.log_softmax(dim=1).numpy())
# 或
m = nn.LogSoftmax(dim=1)
print(m(tensor).numpy())[[-1.4790106 -0.47901064 -1.8790107 ]]
[[-1.4790106 -0.47901064 -1.8790107 ]]由于损失函数要求得到是⼀个值,通常计算得到的,是对数平均损失。pytorch中的NLLLoss (negative log likelihood loss)完成的就是对数平均损失的计算。
python
tensor = torch.tensor([[0.5,1.5,0.1]])
m = tensor.log_softmax(dim=1)
loss = torch.nn.NLLLoss()
target = torch.empty(1, dtype=torch.long).random_(0, 3)
print(loss(m, target))tensor(1.8790)当然,最后回到我们文章开头提到的交叉熵损失 ------ cross_entropy。
PyTorch中的 cross_entropy 会自动调用上面介绍的 log_softmax 和 nll_loss 来计算交叉熵,其计算公式如下:
l o s s ( x , c l a s s ) = − log ( exp ( x c l a s s ) ∑ j exp ( x j ) ) loss(x, class) = -\log\left(\frac{\exp(xclass)}{\sum_j \exp(xj)}\right) loss(x,class)=−log(∑jexp(xj)exp(xclass))
python
tensor = torch.tensor([[0.5,1.5,0.1]])
loss = nn.CrossEntropyLoss()
target = torch.randint(3,(1,), dtype=torch.int64)
print(loss(tensor, target).numpy())0.479010647. 二分类交叉熵binary_cross_entropy
binary_cross_entropy 是二分类的交叉熵,实际上是 CrossEntropyLoss 的一种特殊情况。当多分类中类别只有两类时(即 0 或 1),就变成了二分类问题,这也是逻辑回归问题,可以使用相同的损失函数。
python
target = torch.tensor([[1., 0.], [0., 1.]])
pred = torch.tensor([[0.8,0.2], [0.4,0.6]])
loss = nn.functional.binary_cross_entropy(pred, target, reduction="mean")
print(loss.numpy())0.36698458注意:如果使用 BCEWithLogitsLoss,则不需要预先进行 softmax 处理。