1.markdown内容如下:
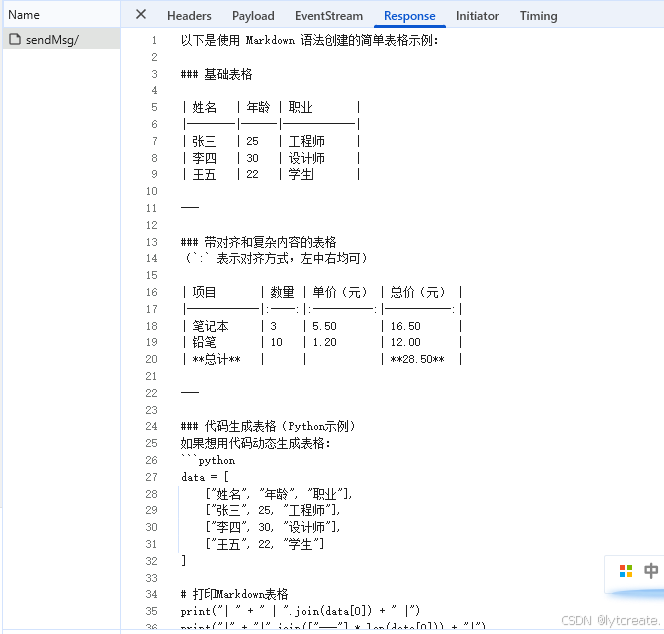
2.转换后的内容如下:

3.附上代码:
import argparse
import os
from markdown import markdown
from bs4 import BeautifulSoup
from docx import Document
from docx.shared import Inches
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
def convert_md_to_docx(input_file, output_file=None):
# 若未指定输出文件,从输入文件路径推断
if not output_file:
base_name, _ = os.path.splitext(input_file)
output_file = f"{base_name}.docx"
# 读取 Markdown 文件内容
try:
with open(input_file, 'r', encoding='utf-8') as f:
md_content = f.read()
except FileNotFoundError:
print(f"错误:找不到文件 '{input_file}'")
return
except Exception as e:
print(f"错误:读取文件时出错 '{input_file}': {e}")
return
# 将 Markdown 转换为 HTML
html_content = markdown(md_content, extensions=['markdown.extensions.fenced_code',
'markdown.extensions.tables',
'markdown.extensions.nl2br'])
# 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
# 创建 Word 文档
doc = Document()
# 处理 HTML 内容并添加到 Word 文档
process_soup_elements(soup, doc)
# 保存 Word 文档
try:
doc.save(output_file)
print(f"成功:已将 Markdown 文件 '{input_file}' 转换为 Word 文档 '{output_file}'")
except Exception as e:
print(f"错误:保存文件时出错 '{output_file}': {e}")
def process_soup_elements(soup, doc):
"""处理 BeautifulSoup 对象中的所有元素"""
# 如果 soup 直接包含内容(没有 html/body 标签)
if soup.name is None or soup.name != 'html':
for element in soup.children:
process_element(element, doc)
else:
# 处理标准的 html 结构
for element in soup.children:
if element.name == 'html':
for html_child in element.children:
if html_child.name == 'body':
for body_child in html_child.children:
process_element(body_child, doc)
elif html_child.name == 'head':
# 通常忽略 head 部分,但可以根据需要处理
pass
else:
# 处理不在 body 中的元素
process_element(html_child, doc)
else:
process_element(element, doc)
def process_element(element, doc):
"""处理单个 HTML 元素并添加到 Word 文档"""
if element.name is None:
# 处理文本节点
if element.strip():
doc.add_paragraph(element.strip())
return
if element.name == 'h1':
# 处理一级标题
doc.add_heading(element.get_text(), level=1)
elif element.name == 'h2':
# 处理二级标题
doc.add_heading(element.get_text(), level=2)
elif element.name == 'h3':
# 处理三级标题
doc.add_heading(element.get_text(), level=3)
elif element.name == 'p':
# 处理段落
p = doc.add_paragraph()
for child in element.children:
if child.name is None:
p.add_run(str(child))
elif child.name == 'strong':
p.add_run(child.get_text()).bold = True
elif child.name == 'em':
p.add_run(child.get_text()).italic = True
elif child.name == 'code':
p.add_run(child.get_text()).font.name = 'Courier New'
elif child.name == 'a':
p.add_run(child.get_text())
elif element.name == 'ul':
# 处理无序列表
for li in element.find_all('li'):
doc.add_paragraph(li.get_text(), style='List Bullet')
elif element.name == 'ol':
# 处理有序列表
for li in element.find_all('li'):
doc.add_paragraph(li.get_text(), style='List Number')
elif element.name == 'pre':
# 处理代码块
if element.code:
code_text = element.code.get_text()
p = doc.add_paragraph()
p.add_run(code_text).font.name = 'Courier New'
elif element.name == 'table':
# 处理表格
table = doc.add_table(rows=1, cols=len(element.find('tr').find_all(['th', 'td'])))
hdr_cells = table.rows[0].cells
# 添加表头
for i, th in enumerate(element.find('tr').find_all('th')):
hdr_cells[i].text = th.get_text()
# 添加表格内容
for row in element.find_all('tr')[1:]:
row_cells = table.add_row().cells
for i, td in enumerate(row.find_all('td')):
row_cells[i].text = td.get_text()
elif element.name == 'img':
# 处理图片
img_src = element.get('src')
if img_src and os.path.exists(img_src):
try:
doc.add_picture(img_src, width=Inches(5.0))
last_paragraph = doc.paragraphs[-1]
last_paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
except Exception as e:
print(f"警告:无法添加图片 '{img_src}': {e}")
if __name__ == "__main__":
convert_md_to_docx('E:\work\\tempProject\pythonProject\zhuan\\123.md')