真正不懂数学就能理解机器学习其实是个神话。我认为,AI 在商业世界可以不懂数学甚至不懂编程也能应用,但对于技术人员来说,一些基础数学是必须的。本文收集了我认为理解学习本质所必需的数学基础,至少在概念层面要掌握。毕竟,机器学习的核心就是数学公式。
在本教程中,我们将涵盖机器学习中用到的所有数学概念:
- 线性代数
- 设计矩阵
- NumPy 支持
- 线性回归
- 多项式回归
- 对数
- 微积分
- 偏导数
- 梯度下降
- 求导法则(链式法则、乘积法则、商法则)
- 损失函数
- 概率与不确定性
我们会在合适的地方提供实用代码示例和可视化,帮助你理解这些概念。
线性代数
一切都始于线性代数,这是研究线性方程(如:
a 1 x 1 + ⋯ + a n x n a_1x_1 + \dots + a_nx_n a1x1+⋯+anxn
)、线性映射(如:
( x 1 , ... , x n ) ↦ a 1 x 1 + ⋯ + a n x n (x_1,\dots,x_n) \mapsto a_1x_1 + \dots + a_nx_n (x1,...,xn)↦a1x1+⋯+anxn
)及其在向量空间中通过矩阵表示(如:
\begin{bmatrix}
a_11 & a_12 & a_13\
a_21 & a_22 & a_23\
\vdots & \vdots & \vdots\
a_m1 & a_m2 & a_m3
\end{bmatrix}
)的数学分支。
设计矩阵
手写每个类似的表达式太繁琐了,所以我们用"矩阵"记法。虽然严格来说矩阵不只是记法,但它极大地简化了表达。我们用"设计矩阵"来组织数据。著名的 NumPy 库提供了各种矩阵操作。设计矩阵 (通常记为 X X X)是统计和机器学习中的基础概念,尤其在线性回归和其他线性模型中。它以便于应用线性模型的方式组织数据。
设计矩阵的关键组成
- 行:每一行代表一个观测或数据点。
- 列:每一列代表一个特征或预测变量。列可以包括:
- 自变量:用于预测因变量的特征。
- 截距项:一列全为 1 的列,用于线性模型的截距。
- 交互项:表示特征间交互的列。
- 多项式项:特征的高阶项。
设计矩阵的结构
对于有 n n n 个观测、 p p p 个特征的数据集,设计矩阵 X X X 是 n × ( p + 1 ) n\times(p+1) n×(p+1) 的矩阵(如果包含截距项)。结构如下:
X = 1 x 11 x 12 ... x 1 p 1 x 21 x 22 ... x 2 p ⋮ ⋮ ⋮ ⋱ ⋮ 1 x n 1 x n 2 ... x n p X= \begin{bmatrix} 1&x{11}&x{12}&\dots&x{1p}\\ 1&x{21}&x{22}&\dots&x{2p}\\ \vdots&\vdots&\vdots&\ddots&\vdots\\ 1&x{n1}&x{n2}&\dots&x{np}\\ \end{bmatrix} X= 11⋮1x11x21⋮xn1x12x22⋮xn2......⋱...x1px2p⋮xnp
- 第一列(全为 1)表示截距项。
- 其余列表示特征 x i j x{ij} xij, i i i 为观测编号, j j j 为特征编号。
示例
考虑一个有 3 个观测、2 个特征(Length 和 Width)的简单数据集:
| 观测 | 长度 | 宽度 |
||||
| 1 | 1 | 2 |
| 2 | 2 | 3 |
| 3 | 3 | 4 |
设计矩阵 X X X(含截距项)为:
X = 1 1 2 1 2 3 1 3 4 X= \begin{bmatrix} 1&1&2\\ 1&2&3\\ 1&3&4\\ \end{bmatrix} X= 111123234
设计矩阵的重要性
- 线性回归:设计矩阵 X X X 用于通过公式 β ^ = ( X T X ) − 1 X T y \hat{\beta}=(X^T X)^{-1}X^T y β^=(XTX)−1XTy 计算模型系数( y y y 为因变量向量)。
- 广义线性模型(GLM):设计矩阵也用于 GLM,通过链接函数将线性预测变量转换为响应变量。
- 特征工程:设计矩阵可包含多项式项、交互项等特征变换,以捕捉更复杂的关系。
- 模型解释:设计矩阵的列直接对应模型中的特征,便于解释系数。
python
"""
设计矩阵示例
| | 截距 | 长度 | 宽度 |
|-||||
|0| 1 | 1 | 2 |
|1| 1 | 2 | 3 |
|2| 1 | 3 | 4 |
"""
import numpy as np
import pandas as pd
# 示例数据
data = {
'Length': [1, 2, 3],
'Width': [2, 3, 4]
}
df = pd.DataFrame(data)
# 添加截距项(一列全为 1)
df['Intercept'] = 1
# 创建设计矩阵
X = df[['Intercept', 'Length', 'Width']]
print("设计矩阵:\n", X)设计矩阵:
Intercept Length Width
0 1 1 2
1 1 2 3
2 1 3 4矩阵的转置
矩阵的转置是指沿主对角线翻转,将行变为列、列变为行。对于矩阵 A A A,其转置记为 A T A^T AT。
例如:
- 若 A = 1 2 3 4 A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} A=1324,则 A T = 1 3 2 4 A^T = \begin{bmatrix} 1 & 3 \\ 2 & 4 \end{bmatrix} AT=1234。
简单来说,就是以左上到右下的对角线为轴旋转,行变列、列变行。
矩阵的逆
矩阵 A A A 的逆记为 A − 1 A^{-1} A−1,是一个特殊矩阵,满足 A ⋅ A − 1 = I A \cdot A^{-1} = I A⋅A−1=I, A − 1 ⋅ A = I A^{-1} \cdot A = I A−1⋅A=I,其中 I I I 为单位矩阵(对角线为 1,其余为 0)。可以理解为"反操作":
例如, A = 1 2 3 4 A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} A=1324,若其逆存在,则 A A A 不是"扁平"的(行列式不为零)。逆矩阵就像"撤销"操作。
单位矩阵
单位矩阵 I I I 是一个方阵(行列数相等),主对角线为 1,其余为 0。它在矩阵乘法中起到"1"的作用:任何矩阵与 I I I 相乘都不变。
例如:
- 2x2 单位矩阵 I = 1 0 0 1 I = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} I=1001。
- 任意 2x2 矩阵 A A A,有 A ⋅ I = A A \cdot I = A A⋅I=A, I ⋅ A = A I \cdot A = A I⋅A=A。
简单说,就是"什么都不做"的矩阵。
小结
- 设计矩阵是用于线性模型的数据结构化表示。
- 它包含多个个体的多种特征,每行对应一个个体,每列对应一个特征。
- 包含截距项、自变量、可能还有交互项或多项式项。
- 对拟合线性回归等模型、解释结果至关重要。
Numpy 矩阵操作
python
"""
设计矩阵代码示例
`numpy.matrix.T`:矩阵转置。
`numpy.matrix.I`:矩阵逆。
"""
import numpy as np
m = np.matrix('[1, 2; 3, 4]')
print(f"原始矩阵:\n {m}")
print(f"转置矩阵:\n {m.T}")
print(f"逆矩阵:\n {m.I}")
print(m * m.I)原始矩阵:
[[1 2]
[3 4]]
转置矩阵:
[[1 3]
[2 4]]
逆矩阵:
[[-2. 1. ]
[ 1.5 -0.5]]
[[1.0000000e+00 0.0000000e+00]
[8.8817842e-16 1.0000000e+00]]线性代数 numpy.linalg
这是你进入机器学习编程后离不开的包之一。
@ 运算符
@ 运算符用于 NumPy 中的矩阵乘法,等价于 np.dot(),但更简洁、可读性更好。推荐用它做矩阵(二维数组)乘法。
矩阵操作
linalg.inv(a):求矩阵的逆。numpy.linalg.matrix_power(a, n):矩阵的 n 次幂。numpy.linalg.matrix_rank(M):求矩阵秩。numpy.linalg.det(a):求行列式。numpy.linalg.eig(a):求特征值和特征向量。numpy.linalg.svd(a, full_matrices=True, compute_uv=True, hermitian=False):奇异值分解。numpy.linalg.cholesky(a):Cholesky 分解。
矩阵乘法
结果矩阵的每个元素由第一个矩阵的行与第二个矩阵的列做点积得到。
[1 2] × [5 6] = [1×5 + 2×7 1×6 + 2×8] = [19 22]
[3 4] [7 8] [3×5 + 4×7 3×6 + 4×8] [43 50]
python
import numpy as np
# 创建两个矩阵
A = np.array([[1, 2],
[3, 4]])
B = np.array([[5, 6],
[7, 8]])
# 用 @ 做矩阵乘法
C = A @ B
# 或用 np.dot()
C = np.dot(A, B)
print(C)[[19 22]
[43 50]]线性回归
现在我们在讲完线性代数后来看线性回归。回归是一种统计方法,用于建模和分析因变量(目标)与一个或多个自变量(特征)之间的关系。
线性回归用于确定最佳拟合直线(多变量时为超平面),描述自变量与因变量的关系。目标是最小化实际值与预测值之间的误差。
简单线性回归 表达式:
y = β 0 + β 1 x + ϵ y = \beta_0 + \beta_1x + \epsilon y=β0+β1x+ϵ
其中:
- y y y:因变量(目标)
- x x x:自变量(特征)
- β 0 \beta_0 β0:截距(见下)
- β 1 \beta_1 β1:斜率(系数,见下)
- ϵ \epsilon ϵ:误差项
多元线性回归:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β n x n + ϵ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \dots + \beta_nx_n + \epsilon y=β0+β1x1+β2x2+⋯+βnxn+ϵ
即多个自变量影响因变量。
线性回归的目标 是估计系数( β \beta β),使得平方误差和(实际值与预测值的差的平方和)最小,通常用最小二乘法(OLS)实现。
截距与系数
在线性回归模型中,截距和系数是定义线性关系的基本组成。
截距( β 0 \beta_0 β0 或 bias)
- 当所有自变量 x x x 都为 0 时,因变量 y y y 的值。
- 表示回归线在 y y y 轴上的起点( x = 0 x=0 x=0)。
- 可通过模型对象获得:KaTeX parse error: Expected group after '_' at position 18: ...del.intercept\\_̲
示例
假设用房价( y y y)建模房屋面积( x x x):
price = 50,000 + 200 \\times size
其中 50,000 是截距,表示房屋面积为 0 时土地价格为 50,000。
系数( β 1 , β 2 \beta_1, \beta_2 β1,β2 或权重)
- 斜率,表示自变量 x x x 每增加 1 单位, y y y 的变化量(假设其他变量不变)。
- 可通过模型对象获得:KaTeX parse error: Expected group after '_' at position 13: model.coef\\_̲
- x x x 在机器学习中称为特征。
给定:
y = model.intercept\\_ + (model.coef_0 \\times Feature1) + (model.coef_1 \\times Feature2)
其中:
- y y y 为预测值
当:
- i n t e r c e p t intercept intercept = 2
- c o e f f i c i e n t 0 coefficient_0 coefficient0 = 3
- c o e f f i c i e n t 1 coefficient_1 coefficient1 = 4
则:
- 所有特征为 0 时,预测值为 2,即截距或 β 0 \beta_0 β0 或 bias
- Feature1 每增加 1,预测值增加 3
- Feature2 每增加 1,预测值增加 4
示例
同样用房价模型:
price = 50,000 + 200 \\times size
其中系数 200 表示每增加 1 平方英尺,价格增加 200 美元。
- 系数为正, x x x 增大, y y y 也增大。
- 系数为负, x x x 增大, y y y 反而减小。
残差
残差是指实际观测值(真实目标)与模型预测值之间的差。它衡量了模型对每个数据点的预测误差。
形式定义
对于 n n n 个样本:
- y i y_i yi:第 i i i 个样本的真实值
- y ^ i \hat{y}_i y^i:模型对第 i i i 个样本的预测值
第 i i i 个样本的残差:
r i = y i − y ^ i r_i = y_i - \hat{y}_i ri=yi−y^i
残差的意义
- 模型拟合优度:残差小表示预测接近真实值,残差大表示预测差。
- 误差模式:分析残差(如绘图)可发现模式:
- 若残差随机分布在 0 附近,模型可能拟合良好。
- 若残差有系统性模式(如随预测值增大),说明模型遗漏了某些结构(如非线性或遗漏变量)。
- 假设检验:线性回归中,残差用于检验假设:
- 同方差性:残差在所有预测值水平上方差应恒定。
- 正态性:残差应近似正态分布,以便某些统计检验有效。
示例
假设用身高预测体重:
- 真实体重( y i y_i yi):70 kg
- 预测体重( y ^ i \hat{y}_i y^i):68 kg
- 残差( r i r_i ri):70 - 68 = 2 kg
另一个预测为 72 kg,则残差为 70 - 72 = -2 kg。
假设线性回归:
residuals = y - y_pred
其中 y y y 为训练数据的真实体重,y_pred 为模型预测值。残差的方差(sigma2)用于估计模型系数的不确定性,帮助量化预测的置信度。
残差的重要性
- 训练:用于计算均方误差(MSE)等指标以优化模型。
- 诊断:帮助诊断过拟合、欠拟合或模型设定问题。
- 不确定性:用于计算协方差矩阵,进而估计预测不确定性。
简言之,残差是理解和改进模型性能的基础。
不确定性
系数的不确定性指模型系数(参数)估计值的变异程度或精度。在线性回归中,系数表示设计矩阵中每个特征的权重。不确定性反映了我们对这些值的置信程度。
不确定性的影响:
- 模型置信度:高不确定性(系数方差大)说明系数可能变化范围大,对特征与目标的关系不确定。
- 低不确定性(方差小)说明系数估计更精确,模型解释性更强。
- 对预测的影响:高不确定性的系数会导致新数据预测的变异性更大。因为输入数据的微小变化会导致输出显著不同。
- 特征重要性:
- 若某系数不确定性高(置信区间包含 0),说明该特征对目标变量影响不显著。
- 低不确定性且非零系数说明特征对预测有可靠贡献。
- 数据质量与数量:高不确定性常因数据量少、噪声大或特征共线性导致。更多或更高质量数据通常能降低不确定性。
- 模型假设:不确定性估计假设模型设定正确(如线性关系)。若模型拟合不好(如残差有模式),不确定性估计可能误导。
不确定性计算(系数协方差)
系数不确定性可用系数的协方差矩阵量化。线性回归中,系数协方差矩阵为:
Cov ( β ^ ) = σ 2 ( X T X ) − 1 \text{Cov}(\hat{\beta}) = \sigma^2 (X^T X)^{-1} Cov(β^)=σ2(XTX)−1
其中:
- σ 2 \sigma^2 σ2:残差方差,表示数据噪声。
- X X X:设计矩阵。
- ( X T X ) − 1 (X^TX)^{-1} (XTX)−1:设计矩阵 Gram 矩阵的逆,依赖于输入特征的分布和相关性。可用 NumPy 的
np.linalg.inv()求逆。 - β ^ \hat{\beta} β^:系数估计向量。
- 协方差矩阵对角线元素为每个系数的方差,开方即标准误差(不确定性度量)。
- 非对角线元素表示系数间的协方差(如特征高度相关,系数协方差大)。
- 可用
multivariate_normal.rvs从该分布采样,反映估计不确定性。
残差方差 σ 2 \sigma^2 σ2 计算公式:
σ 2 = ∑ i = 1 n ( y i − y ^ i ) 2 n − p \sigma^2 = \frac{\sum_{i=1}^n (y_i - \hat{y}_i)^2}{n - p} σ2=n−p∑i=1n(yi−y^i)2
其中:
- y i y_i yi:观测值
- y ^ i \hat{y}_i y^i:预测值
- n n n:观测数
- p p p:参数数(含截距)
实践意义
- 解释:如 Length 系数为 2.5,标准误差 0.1,则很有信心其值在 2.5 左右且显著。若标准误差为 3.0,则系数可能在 -0.5 到 5.5 之间,Length 是否重要就难说。
- 决策:高不确定性可能促使你收集更多数据、简化模型(如去除共线特征)或用正则化(如 Ridge 回归)稳定系数。
- 不确定性传播:系数不确定性会传递到预测(y_pred_std),可用误差棒可视化,便于表达预测区间。
示例
假设模型预测体重,系数如下:
Length:2.0(标准误差 0.5)Width:1.5(标准误差 1.2)Height:3.0(标准误差 0.2)
不确定性估算的代码示例(续)
python
"""
用 Statsmodels 估计不确定性
Statsmodels 是强大的统计库,能提供详细回归分析,包括系数不确定性。
"""
import numpy as np
import pandas as pd
import statsmodels.api as sm
# 示例数据
data = {
'Length': [1, 2, 3, 4, 5],
'Width': [2, 3, 4, 5, 6],
'Height': [3, 4, 5, 6, 7],
'Weight': [10, 15, 20, 25, 30]
}
df = pd.DataFrame(data)
# 设计矩阵和目标变量
design_X = df[['Length', 'Width', 'Height']]
y = df['Weight']
# 添加常数项(截距)
design_X = sm.add_constant(design_X)
# 拟合 OLS 模型(最小二乘法)
model = sm.OLS(y, design_X).fit()
# 获取预测和置信区间
predictions = model.get_prediction(design_X)
pred_summary = predictions.summary_frame(alpha=0.05) # 95% 置信区间
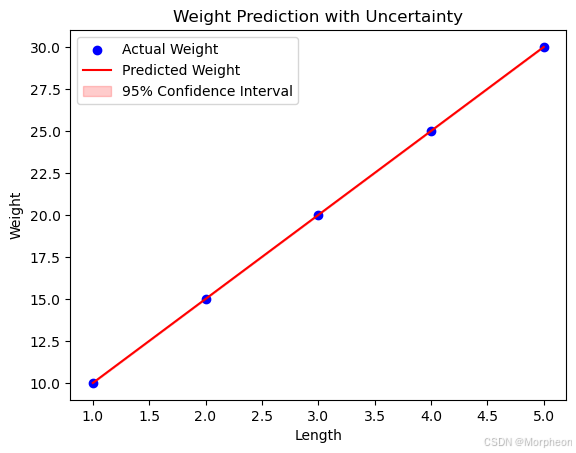
# 可视化实际值、预测值和不确定性
plt.scatter(df['Length'], y, color='blue', label='实际体重')
plt.plot(df['Length'], pred_summary['mean'], color='red', label='预测体重')
plt.fill_between(df['Length'], pred_summary['mean_ci_lower'], pred_summary['mean_ci_upper'],
color='red', alpha=0.2, label='95%置信区间')
plt.xlabel('Length')
plt.ylabel('Weight')
plt.legend()
plt.title('带不确定性的体重预测')
plt.show()
# 打印回归摘要
print(model.summary())
"""
回归摘要包括:
- 系数:每个变量(如 Length)对 Weight 的影响。
- 标准误差:不确定性的度量------如果有不同数据,这些系数可能的变化范围。误差越小,置信度越高。
- 置信区间:
- 系数区间通常以区间[a, b]表示,a为下界,b为上界。
- 置信水平:如 95%,表示重复实验时,真系数有 95% 概率落在该区间。
- P 值:检验每个变量的影响是真实的还是随机噪声(P 值低=更确定是真实影响)。
"""
python
"""
用 scikit-learn 的 BayesianRidge 进行贝叶斯线性回归
BayesianRidge 是贝叶斯线性回归模型,可为系数提供不确定性估计。
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import BayesianRidge
# 示例数据
data = {
'Length': [1, 2, 3, 4, 5],
'Width': [2, 3, 4, 5, 6],
'Height': [3, 4, 5, 6, 7],
'Weight': [10, 15, 20, 25, 30]
}
df = pd.DataFrame(data)
X = df[['Length', 'Width', 'Height']]
y = df['Weight']
# 拟合贝叶斯岭回归模型
model = BayesianRidge(compute_score=True)
model.fit(X, y)
# 打印系数及其标准差
print("系数:", model.coef_)
print("系数标准差:", np.sqrt(np.diag(model.sigma_)))
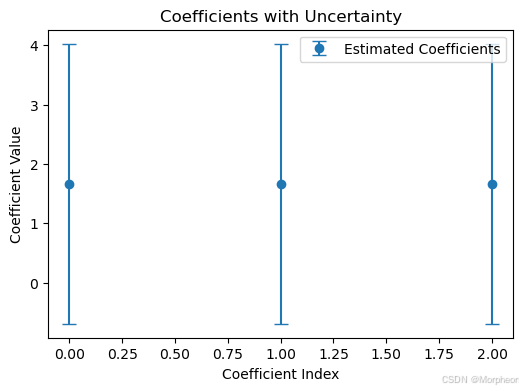
# 可视化系数及其不确定性
plt.figure(figsize=(6,4))
plt.errorbar(range(len(model.coef_)),
model.coef_,
yerr=np.sqrt(np.diag(model.sigma_)),
fmt='o', capsize=5, label='估计系数')
plt.title('带不确定性的系数')
plt.xlabel('系数索引')
plt.ylabel('系数值')
plt.legend()
plt.show()系数: 1.66666685 1.66666662 1.66666651
系数标准差: 2.35702053 2.35702053 2.35702053
python
"""
用自助法(Bootstrapping)估计不确定性
自助法是一种重采样技术,可用于估计系数的不确定性。
"""
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.utils import resample
# 示例数据
data = {
'Length1': [1, 2, 3, 4, 5],
'Width': [2, 3, 4, 5, 6],
'Height': [3, 4, 5, 6, 7],
'Weight': [10, 15, 20, 25, 30]
}
df = pd.DataFrame(data)
X = df[['Length1', 'Width', 'Height']]
y = df['Weight']
n_bootstrap_samples = 1000
bootstrap_coefs = np.zeros((n_bootstrap_samples, X.shape[1]))
for i in range(n_bootstrap_samples):
X_sample, y_sample = resample(X, y)
model = LinearRegression()
model.fit(X_sample, y_sample)
bootstrap_coefs[i] = model.coef_
mean_coefs = np.mean(bootstrap_coefs, axis=0)
std_coefs = np.std(bootstrap_coefs, axis=0)
print("均值系数:", mean_coefs)
print("系数标准差:", std_coefs)
plt.figure(figsize=(6, 4))
plt.errorbar(range(len(mean_coefs)), mean_coefs, yerr=std_coefs, fmt='o', capsize=5, label='自助法系数')
plt.title('自助法下的系数不确定性')
plt.xlabel('系数索引')
plt.ylabel('系数值')
plt.legend()
plt.show()均值系数: [1.66166667 1.66166667 1.66166667]
系数标准差: [0.09115006 0.09115006 0.09115006]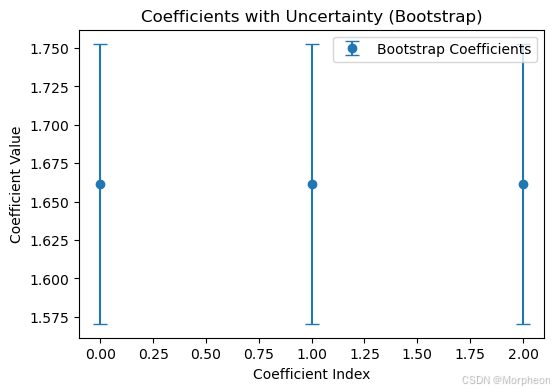
python
# 样本数据生成与线性回归示例
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
np.random.seed(42)
n_samples = 50
data = {
'Length1': np.random.uniform(1, 10, n_samples),
'Width': np.random.uniform(2, 12, n_samples),
'Height': np.random.uniform(3, 15, n_samples),
'Weight': 2 * np.random.uniform(1, 10, n_samples) + 3 * np.random.uniform(2, 12, n_samples) + np.random.normal(0, 2, n_samples)
}
df = pd.DataFrame(data)
# 划分训练集和测试集
train, test = train_test_split(df, test_size=0.2, random_state=42)
X = np.array(train[['Length1', 'Width', 'Height']])
y = train['Weight']
# 归一化设计矩阵,避免数值不稳定
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0)
X_std[X_std == 0] = 1
X_normalized = (X - X_mean) / X_std
# 拟合线性回归模型
model = LinearRegression()
model.fit(X_normalized, y)
print("模型系数:", model.coef_)
# 计算残差方差
y_pred = model.predict(X_normalized)
residuals = y - y_pred
sigma2 = np.sum(residuals**2) / (len(y) - X_normalized.shape[1] - 1)
print("残差方差:", sigma2)
# 计算 X^T X 的逆(加正则项避免奇异)
X_T_X = np.dot(X_normalized.T, X_normalized)
reg_term = 1e-6 * np.eye(X_T_X.shape[0]) # 微小正则项
X_T_X_reg = X_T_X + reg_term
X_T_X_inv = np.linalg.inv(X_T_X_reg)
# 检查协方差矩阵是否有 NaN 或 Inf
cov_matrix = sigma2 * X_T_X_inv
if np.any(np.isnan(cov_matrix)) or np.any(np.isinf(cov_matrix)):
raise ValueError("协方差矩阵包含 NaN 或 Inf。请调整正则项或数据。")
print("系数的协方差矩阵:\n", cov_matrix)
# 从多元正态分布采样多组系数
num_samples = 1000
coefficients_samples = multivariate_normal.rvs(mean=model.coef_, cov=cov_matrix, size=num_samples)
# 用采样系数对测试集做预测
X_test = np.array(test[['Length1', 'Width', 'Height']])
X_test_normalized = (X_test - X_mean) / X_std # 用训练集均值方差归一化
y_pred_samples = np.dot(X_test_normalized, coefficients_samples.T)
# 计算预测均值和标准差
y_pred_mean = np.mean(y_pred_samples, axis=1)
y_pred_std = np.std(y_pred_samples, axis=1)
# 绘制带不确定性的预测
plt.errorbar(y_pred_mean, test['Weight'], xerr=y_pred_std, fmt='o', color='blue', ecolor='lightgray', capsize=5)
plt.xlabel('预测体重')
plt.ylabel('实际体重')
plt.title('带不确定性的预测')
plt.show()模型系数: [0.20950153 0.5294286 0.39841419]
残差方差: 150.9224046839002
系数的协方差矩阵:
[[ 3.80621323 -0.15773098 0.2885645 ]
[-0.15773098 3.93382621 0.76631224]
[ 0.2885645 0.76631224 3.94916702]]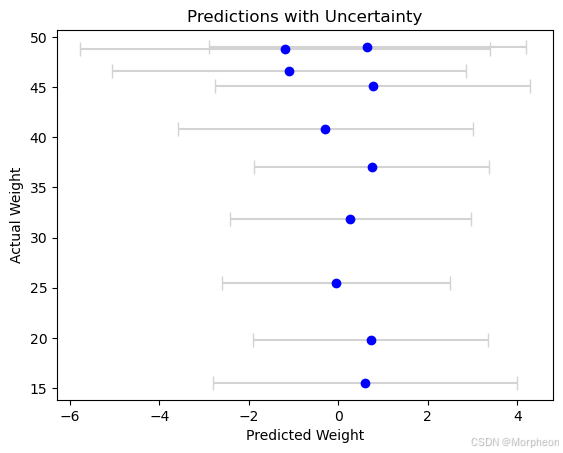
对数(Logarithm)
对数是我们小时候学过但常被遗忘的内容,但在机器学习中(如激活函数)会频繁用到,值得快速回顾。
对数是使底数 b b b 的幂等于某数 n n n 的指数。数学表达为:若 b x = n b^x = n bx=n,则 x = log b n x = \log_b n x=logbn。
例如, 2 3 = 8 2^3 = 8 23=8,所以 3 是 8 以 2 为底的对数,即 3 = log 2 8 3 = \log_2 8 3=log28。
工资的对数例子
假如你用工作年限预测工资。年限翻倍可能工资增加 10 , 000 10,000 10,000,这就是"工资对年限的对数是线性关系"。所以可以特征工程,新增一列"年限的对数",用它做回归。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 模拟数据
years_experience = np.array([1, 2, 4, 8, 16, 32])
salary = np.array([40000, 50000, 60000, 70000, 80000, 90000])
# 对数变换
log_years_experience = np.log(years_experience)
python
# 绘制原始关系和对数变换后的关系
plt.figure(figsize=(8,3))
plt.subplot(1,2,1)
plt.scatter(years_experience, salary, color='red')
plt.xlabel("工作年限")
plt.ylabel("工资")
plt.title("未对数变换(非线性)")
plt.subplot(1,2,2)
plt.scatter(log_years_experience, salary, color='green')
plt.xlabel("log(工作年限)")
plt.ylabel("工资")
plt.title("对数变换后(线性)")
plt.show()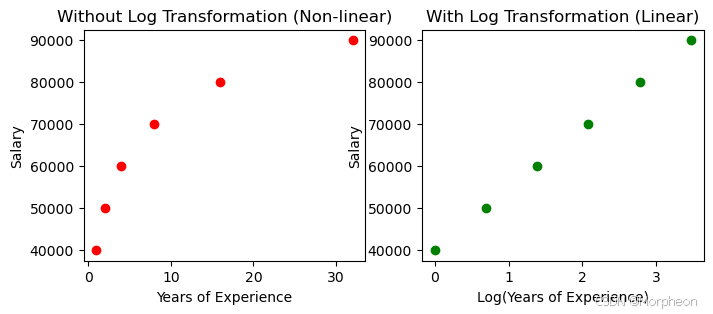
模型评估
平均绝对误差(MAE)
M A E = 1 n ∑ k = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n} \sum_{k=1}^n |y_i - \hat{y}_i| MAE=n1k=1∑n∣yi−y^i∣
- 衡量实际值( y i y_i yi)与预测值( y ^ i \hat{y}_i y^i)的平均绝对差。
- 不像 MSE 那样对大误差惩罚更重。
均方误差(MSE)
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
- 与 MAE 类似,但对大误差更敏感。
R 2 R^2 R2(决定系数)
\begin{equation*}
R^2 = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}
\end{equation*}
- y i y_i yi:实际值
- y ^ i \hat{y}_i y^i:预测值
- y ˉ \bar{y} yˉ:实际值均值
解释:
- 衡量模型对数据方差的解释能力。
- R 2 = 1 R^2=1 R2=1:完美拟合。
- R 2 = 0 R^2=0 R2=0:与用均值预测一样差。
- R 2 < 0 R^2<0 R2<0:比用均值还差。
- 例: R 2 = 0.85 R^2=0.85 R2=0.85,说明模型解释了 85% 的方差。
多项式回归(Polynomial Regression)
在 sklearn.preprocessing 的 PolynomialFeatures 中,degree 指生成多项式特征的最高次数。它控制特征变换的复杂度,让线性模型能拟合非线性关系。
简单解释
- 设
degree = n,PolynomialFeatures会把原始特征 x x x 变成 x 1 , x 2 , . . . , x n x^1, x^2, ..., x^n x1,x2,...,xn,如果有多个特征还会生成交互项。 - 就像给模型更多"工具"去拟合弯曲的曲线,而不仅仅是直线。
示例
假设有一个特征 Length,数据为 [1, 2, 3]。
-
Degree = 1:只用原始特征。
- 输出:
[Length] Length=2时:[2]- 这是线性模型(直线)。
- 输出:
-
Degree = 2:加上平方项(默认还有常数项)。
- 输出:
[1, Length, Length^2] Length=2时:[1, 2, 4]- 可以拟合抛物线。
- 输出:
-
Degree = 3:再加立方项。
- 输出:
[1, Length, Length^2, Length^3] Length=2时:[1, 2, 4, 8]- 能拟合更复杂的曲线。
- 输出:
多特征时
如有 Length 和 Width 两个特征,degree 还包括交互项:
- Degree = 2 :
- 输出:
[1, Length, Width, Length^2, Length*Width, Width^2] Length=2, Width=3时:[1, 2, 3, 4, 6, 9]- 能捕捉特征间的交互关系。
- 输出:
为什么重要
- 低 degree(如 1)模型简单,只能拟合直线或平面。
- 高 degree(如 3 及以上)能拟合复杂非线性,但过高会过拟合噪声。
在你的 pipeline 里,degree = polyfeatures 意味着每轮循环测试更灵活的模型,寻找最平衡拟合与泛化的 degree。就像决定你的曲线能弯几次,太弯就过拟合了!
正则化(Regularization)
普通线性回归会让系数变得很大以完美拟合训练数据(甚至拟合噪声)。Ridge 和 Lasso 通过对大系数加惩罚,让模型更简单、泛化能力更强。
Ridge 和 Lasso 都是在线性回归基础上加惩罚项,防止模型过于复杂,抑制过拟合。可以理解为"自律版"线性回归。
Ridge 回归
- 把系数收缩到接近 0,但不会变成 0。
- 惩罚大系数,抑制极端拟合。
- 适合所有特征都可能有用,只是想让它们影响别太大。
Lasso 回归
- 也收缩系数,但可以让部分系数直接变成 0,相当于自动筛选特征。
- 适合你怀疑有些特征其实没用,想自动剔除。
- 区别:Ridge 保留所有特征但"软化"它们,Lasso 直接"踢掉"无用特征。
微积分(Calculus)
微积分是研究变化和累积的数学分支,分为微分 和积分两大部分。
导数(Derivative)
微分关注变化率,即函数输出随输入变化的快慢。比如 f ( x ) = x 2 f(x) = x^2 f(x)=x2,其导数 f ′ ( x ) = 2 x f'(x) = 2x f′(x)=2x,说明 x x x 越大,曲线越陡。
核心思想是极限。微分就是把曲线放大到无限小区间,变成直线,计算这条切线的斜率。这在物理(速度是位移的导数)、经济(边际成本)和机器学习(用梯度下降优化模型)中都很重要。
例 : s ( t ) = 4 t 2 s(t) = 4t^2 s(t)=4t2,微分得速度 v ( t ) = 8 t v(t) = 8t v(t)=8t, t = 2 t=2 t=2 时速度为 16。
偏导数(Partial Derivatives)
偏导数是多元微积分的概念,表示函数对某个变量的变化率,其他变量保持不变。
定义
设 z = f ( x , y ) z = f(x, y) z=f(x,y),对 x x x 的偏导记为 ∂ f ∂ x \frac{\partial f}{\partial x} ∂x∂f,对 y y y 的偏导记为 ∂ f ∂ y \frac{\partial f}{\partial y} ∂y∂f。
计算
对 f ( x , y ) = x 2 + 3 x y f(x, y) = x^2 + 3xy f(x,y)=x2+3xy,对 x x x 求偏导( y y y 看作常数):
∂ f ∂ x = 2 x + 3 y \frac{\partial f}{\partial x} = 2x + 3y ∂x∂f=2x+3y
对 y y y 求偏导( x x x 看作常数):
∂ f ∂ y = 3 x \frac{\partial f}{\partial y} = 3x ∂y∂f=3x
规则
- 幂法则: u = x n u = x^n u=xn, ∂ u ∂ x = n x n − 1 \frac{\partial u}{\partial x} = nx^{n-1} ∂x∂u=nxn−1
- 乘积法则、商法则、链式法则等同普通导数
应用
- 优化:找极值
- 物理工程:描述系统变化
- 经济学:分析边际变化
损失函数与梯度下降
损失函数 是机器学习的"计分卡",衡量模型预测与真实值的差距。比如回归常用均方误差 L = 1 n ∑ ( y true − y pred ) 2 L = \frac{1}{n} \sum (y_{\text{true}} - y_{\text{pred}})^2 L=n1∑(ytrue−ypred)2。目标就是让损失越小越好。
梯度下降是用来最小化损失函数的工具。损失函数定义了一个"地形",梯度下降用导数(梯度)指示的方向,一步步往最低点走。
- 损失函数给出目标
- 梯度下降用梯度(偏导)指示下降方向
- 每步更新参数 w = w − η ⋅ ∂ L ∂ w w = w - \eta \cdot \frac{\partial L}{\partial w} w=w−η⋅∂w∂L, η \eta η 为学习率
向量化梯度下降
梯度下降最小化 J ( w ) J(\mathbf{w}) J(w), w \mathbf{w} w 是参数向量。更新公式:
w : = w − α ⋅ ∇ J ( w ) \mathbf{w} := \mathbf{w} - \alpha \cdot \nabla J(\mathbf{w}) w:=w−α⋅∇J(w)
- w \mathbf{w} w:权重向量
- α \alpha α:学习率
- ∇ J ( w ) \nabla J(\mathbf{w}) ∇J(w):梯度(各参数的偏导数组成的向量)
梯度 ∇ J ( w ) \nabla J(\mathbf{w}) ∇J(w) 指向 J J J 增长最快的方向,减去它就是下降最快的方向。
例 1:二次函数
J ( w ) = w 1 2 + 2 w 2 2 J(\mathbf{w}) = w_1^2 + 2w_2^2 J(w)=w12+2w22, w = w 1 , w 2 \mathbf{w} = w_1, w_2 w=w1,w2
- ∂ J ∂ w 1 = 2 w 1 \frac{\partial J}{\partial w_1} = 2w_1 ∂w1∂J=2w1
- ∂ J ∂ w 2 = 4 w 2 \frac{\partial J}{\partial w_2} = 4w_2 ∂w2∂J=4w2
- 梯度 ∇ J = 2 w 1 , 4 w 2 \nabla J = 2w_1, 4w_2 ∇J=2w1,4w2
- 更新: w 1 : = w 1 − 2 α w 1 w_1 := w_1 - 2\alpha w_1 w1:=w1−2αw1, w 2 : = w 2 − 4 α w 2 w_2 := w_2 - 4\alpha w_2 w2:=w2−4αw2
例 2:三参数线性模型
J ( w ) = 1 2 ( w 1 + w 2 x + w 3 x 2 − y ) 2 J(\mathbf{w}) = \frac{1}{2} (w_1 + w_2 x + w_3 x^2 - y)^2 J(w)=21(w1+w2x+w3x2−y)2
- 设 h ( w ) = w 1 + w 2 x + w 3 x 2 h(\mathbf{w}) = w_1 + w_2 x + w_3 x^2 h(w)=w1+w2x+w3x2
- ∂ J ∂ w i = ( h − y ) ⋅ ∂ h ∂ w i \frac{\partial J}{\partial w_i} = (h - y) \cdot \frac{\partial h}{\partial w_i} ∂wi∂J=(h−y)⋅∂wi∂h
- ∂ h ∂ w 1 = 1 \frac{\partial h}{\partial w_1} = 1 ∂w1∂h=1, ∂ h ∂ w 2 = x \frac{\partial h}{\partial w_2} = x ∂w2∂h=x, ∂ h ∂ w 3 = x 2 \frac{\partial h}{\partial w_3} = x^2 ∂w3∂h=x2
- 梯度 ∇ J = ( h − y ) ⋅ 1 , x , x 2 \nabla J = (h - y) \cdot 1, x, x\^2 ∇J=(h−y)⋅1,x,x2
小结
- 梯度用微分规则计算每个方向的斜率
- 反方向更新参数,损失下降
- 学习率 α \alpha α 控制步长
- 这种向量化方法适用于任意参数数目的模型,是优化复杂模型的基础