文章目录
- 第一部分:损失函数与反向传播
-
-
- 常用损失函数详解
-
- [1. L1 Loss (绝对值损失)](#1. L1 Loss (绝对值损失))
- [2. MSE Loss (均方误差损失)](#2. MSE Loss (均方误差损失))
- [3. Cross-Entropy Loss (交叉熵损失)](#3. Cross-Entropy Loss (交叉熵损失))
- 在训练循环中使用损失函数
- 反向传播:如何利用损失进行学习
-
- 优化器
- 现有网络模型的使用及修改
- 网络模型的保存与读取
第一部分:损失函数与反向传播
在训练神经网络时,我们需要一个指标来衡量模型预测的好坏。这个指标就是损失函数(Loss Function) 。简单来说,损失函数计算的是模型实际输出(output) 与 真实目标(target之间的差距。这个差距,我们称之为"损失(Loss)"。

如上图所示,损失函数的核心思想非常直观。它将模型对不同任务(选择、填空、解答)的预测得分(output)与它们的标准答案得分(target)进行比较,然后将这些差值汇总起来,得到一个量化的总损失值(Loss=70)。
计算损失有两个核心目的:
- 量化差距:通过一个具体的数值来表示当前模型的预测有多么不准确。
- 提供更新依据:这个损失值是模型优化的起点。通过一个名为**反向传播(Backpropagation)**的机制,我们可以根据损失值来调整网络中的参数(权重),从而让模型在下一次预测时产生更接近真实目标的输出。
下面,我们将详细介绍几种在PyTorch中常用的损失函数,并通过代码来解析它们的具体计算过程。
常用损失函数详解
在PyTorch中,大部分损失函数都可以在 torch.nn 模块中找到。我们主要关注三种:L1Loss、MSELoss和CrossEntropyLoss。
1. L1 Loss (绝对值损失)
L1 Loss计算的是预测值与目标值之间差值的绝对值。当我们需要计算一个批次中所有样本的总体损失时,可以将每个样本的损失求和(sum)或求平均(mean)。
我们来看一个具体的代码示例。假设我们的模型输出为 [1, 2, 3],而真实目标为 [1, 2, 5]。
python
# -*- coding: utf-8 -*-
import torch
from torch.nn import L1Loss
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
print(result)代码解析:
- 我们首先定义了预测值
inputs和目标值targets。 - 关键在于
loss = L1Loss(reduction='sum')这一行。参数reduction='sum'指定了损失的计算方式为求和。 - 因此,代码的计算过程为:
|1 - 1| + |2 - 2| + |3 - 5| = 0 + 0 + 2 = 2。最终打印出的result张量的值就是2。

现在我们来看这张图。图中 L1loss 的计算方式是 (0+0+2)/3=0.6,这里计算的是平均值 。这对应于 L1Loss 的默认行为,即 reduction='mean'。如果我们将上面代码中的 reduction='sum' 改为 'mean',就会得到和图中一样的结果。
2. MSE Loss (均方误差损失)
MSE Loss (Mean Squared Error Loss) 计算的是预测值与目标值之差的平方的平均值。与L1 Loss相比,MSE Loss对较大的误差给予更高的"惩罚"。
python
# -*- coding: utf-8 -*-
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
# MSE Loss
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
print(result_mse)代码解析:
loss_mse = nn.MSELoss()实例化了均方误差损失。默认情况下,它计算的是平均值。- 其计算过程也与上一张图中
MSE的计算过程完全一致:((1 - 1)² + (2 - 2)² + (5 - 3)²) / 3 = (0 + 0 + 4) / 3 = 1.333...
3. Cross-Entropy Loss (交叉熵损失)
交叉熵损失在分类问题中应用最为广泛。它衡量的是模型预测的概率分布与真实的概率分布之间的差异。

这张图清晰地展示了交叉熵损失的应用场景:
- 输入:一张哈士奇图片。
- 模型:经过一个深度神经网络。
- 输出 :网络输出一个原始的数值向量(logits),例如
[0.1, 0.2, 0.3],分别对应[person, dog, cat]三个类别的得分。 - 目标 :真实目标(Target)是
1,代表正确的类别是dog(索引从0开始)。 - 损失计算 :
CrossEntropyLoss函数会基于模型的输出和真实目标,通过图中所示的公式计算出最终的损失值。这个公式内部实际上包含了Softmax转换和负对数似然计算两个步骤。
下面的代码演示了这一过程:
python
import torch
import torch.nn as nn
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)代码解析:
x = torch.tensor([0.1, 0.2, 0.3])对应了图中的output。y = torch.tensor([1])对应了图中的Target。loss_cross = nn.CrossEntropyLoss()实例化了交叉熵损失函数。它会自动处理Softmax等内部计算,我们只需要将模型的原始输出和目标传入即可。
在训练循环中使用损失函数
了解了单个损失函数的计算方法后,我们来看看它在实际的神经网络训练中是如何发挥作用的。
首先,我们需要定义一个神经网络模型。
python
# 文件: nn_loss_network.py
import torch.nn as nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x然后,在训练脚本中,我们实例化模型和损失函数,并在循环中调用它们。
python
# 文件: nn_loss.py (训练脚本部分)
import torch.nn as nn
# 假设 DataLoader 和 Tudui 模型已经定义和导入
# from nn_loss_network import Tudui
# from torch.utils.data import DataLoader
# 1. 实例化模型和损失函数
loss = nn.CrossEntropyLoss()
tudui = Tudui()
# 2. 准备数据加载器 (dataloader)
# dataloader = DataLoader(dataset, batch_size=1) # 示例
# 3. 开始训练循环
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
# 在这里会进行反向传播和优化
# result_loss.backward()
# optimizer.step()
print(result_loss)代码解析:
- 定义模型与损失函数 :我们先创建了
CrossEntropyLoss的实例和Tudui模型的实例。 - 遍历数据 :
for data in dataloader:从数据加载器中批量获取图像imgs和对应的标签targets。 - 正向传播 :
outputs = tudui(imgs)将图像输入模型,得到预测结果。 - 计算损失 :
result_loss = loss(outputs, targets)将预测结果和真实标签传入损失函数,计算出当前批次的损失。
反向传播:如何利用损失进行学习
计算出损失值 result_loss 只是第一步。更关键的是,如何利用这个损失值来让模型变得更好?答案就是反向传播(Backpropagation)。
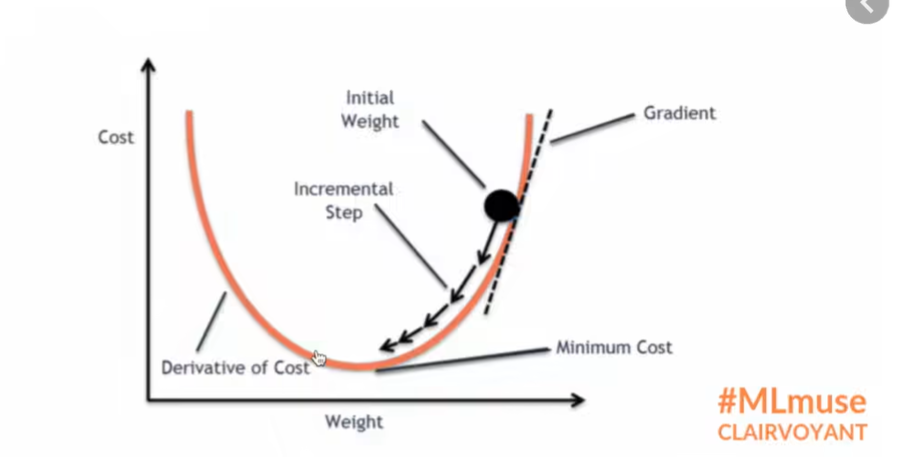
这张图形象地展示了模型优化的核心思想------梯度下降(Gradient Descent):
- 坐标轴:横轴代表模型中的一个权重(Weight),纵轴代表对应的成本或损失(Cost)。曲线表示损失值随着权重的变化而变化。
- 目标:我们的目标是找到使损失最小化的权重值,即曲线的最低点(Minimum Cost)。
- 优化过程 :
- 我们从一个随机的**初始权重(Initial Weight)**开始,此时的损失值通常比较高。
- 在该点,我们计算损失函数关于权重的梯度(Gradient) 。梯度可以理解为曲线在该点的切线斜率,它指明了损失增长最快的方向。
- 为了减小 损失,我们需要沿着梯度的相反方向 更新权重。如图中箭头所示,我们进行一次增量步骤(Incremental Step)。
- 重复这个过程,权重会一步步地向损失最小化的方向移动,最终达到或接近最低点。
反向传播 正是一种高效计算网络中所有参数(权重和偏置)梯度的算法。在PyTorch中,我们只需在计算出损失后调用 result_loss.backward(),PyTorch就会自动完成所有梯度的计算。随后,优化器(Optimizer)会使用这些梯度来更新参数,从而完成一次学习过程。
通过不断重复"正向传播计算损失 -> 反向传播计算梯度 -> 更新权重"这个循环,模型将逐渐学会如何做出更准确的预测,从而使损失值越来越小。
优化器
在上一部分中,我们了解了如何通过损失函数计算出损失(Loss),以及如何调用 loss.backward() 来计算模型中所有参数的梯度(Gradient)。梯度告诉了我们参数应该朝着哪个方向更新才能让损失变小,但这还不够。我们还需要知道**"更新多大的幅度"**。
这就是优化器的作用。优化器 (Optimizer) 是一种算法,它根据计算出的梯度来更新模型的参数(权重和偏置),从而最小化损失函数。它实现了梯度下降过程中的"更新权重"这一关键步骤。
优化器的使用方法
在PyTorch中,所有的优化器都在 torch.optim 模块中。使用一个优化器的基本步骤非常固定:
- 实例化优化器 :在训练开始前,选择一个优化器(例如
SGD),并用模型的参数 (model.parameters()) 和学习率 (lr) 等超参数来创建它的实例。 - 梯度清零 :在每一次训练迭代开始时,必须调用
optimizer.zero_grad()来清除上一步计算得到的梯度。这是因为PyTorch默认会累积梯度,如果不清零,新的梯度会叠加在旧的梯度上,导致错误的更新方向。 - 计算梯度 :调用
loss.backward(),根据当前批次的损失计算所有参数的梯度。 - 更新参数 :调用
optimizer.step(),优化器会根据内部存储的梯度和自身的更新算法,来更新模型的所有参数。
这个流程 optimizer.zero_grad() -> loss.backward() -> optimizer.step() 是PyTorch训练循环的"三部曲",是固定不变的核心。
深入理解SGD优化器
我们将以最基础也是最重要的优化器之一------**随机梯度下降(Stochastic Gradient Descent, SGD)**为例,来详细讲解它的参数。
torch.optim.SGD 的定义如下:
python
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)-
params(iterable):必须提供的参数 。这是模型中需要被优化的参数的集合,通常通过调用model.parameters()来获取。优化器会"注册"这些参数,并在调用.step()时更新它们。 -
lr(float):必须提供的参数 ,代表学习率(Learning Rate)。这是优化器中最重要的超参数。它决定了每次参数更新的步长。- 如果
lr太大,模型可能会在损失函数的最小值附近来回"震荡",难以收敛。 - 如果
lr太小,模型的收敛速度会非常慢,需要更多时间来训练。
- 如果
-
momentum(float, optional):动量。这个参数可以帮助加速SGD在正确的方向上收敛,并抑制震荡。它的值通常在0到1之间(例如0.9)。引入动量后,每次更新不仅会考虑当前的梯度,还会以一定的比例保留上一次的更新方向,就像一个有惯性的小球滚下山坡,速度会越来越快。 -
weight_decay(float, optional):权重衰减(L2正则化) 。这是一个用来防止模型过拟合 的技术。它通过在损失函数中增加一个与权重大小相关的惩罚项,来限制模型权重的值,使得模型更简单。一个非零的weight_decay值(例如1e-4)会使优化器在更新时,让权重值逐渐"衰减"变小。 -
dampening(float, optional):动量的阻尼。这个参数用于控制动量的衰减。在没有阻尼时,动量项会完全保留上一次的更新;有阻尼时,动量会受到一定程度的"抑制"。通常情况下,这个参数保持默认值0即可。 -
nesterov(bool, optional):是否使用Nesterov动量 。这是对传统动量的一种改进。标准的动量法是先计算当前梯度,再结合之前的动量进行更新。而Nesterov动量会先"预估"一下按照当前动量更新后的大致位置,然后计算那个"预估位置"的梯度,再用这个梯度来进行修正。这种"向前看一步"的策略使得它在很多任务上表现得比标准动量更好。如果设置为True,则必须提供一个大于0的momentum值。
代码实战
下面的代码整合了数据加载、模型定义、损失函数和优化器,构成了一个完整的训练流程。
python
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# -------------------- 1. 准备数据集 --------------------
# 下载CIFAR10训练集。transform=ToTensor()会将PIL图像或numpy数组转换为torch.FloatTensor
# 并且会将像素值从 [0, 255] 缩放到 [0.0, 1.0]
dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 创建数据加载器,用于分批次加载数据
dataloader = DataLoader(dataset, batch_size=1)
# -------------------- 2. 定义神经网络模型 --------------------
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
# -------------------- 3. 实例化模型、损失函数和优化器 --------------------
# 创建模型实例
tudui = Tudui()
# 定义损失函数,这里使用交叉熵损失,适用于多分类问题
loss = nn.CrossEntropyLoss()
# 定义优化器
# torch.optim.SGD 是随机梯度下降优化器
# tudui.parameters() 会将模型Tudui中所有需要更新的参数(权重和偏置)传递给优化器
# lr=0.01 设置学习率为0.01
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# -------------------- 4. 完整的训练循环 --------------------
for epoch in range(20): # 假设我们训练20轮
running_loss = 0.0
for data in dataloader:
# 从dataloader中获取一批图像和对应的标签
imgs, targets = data
# 1. 梯度清零:清除上一轮迭代中残留的梯度
optim.zero_grad()
# 2. 正向传播:将图像输入模型,得到预测输出
outputs = tudui(imgs)
# 3. 计算损失:用预测输出和真实标签计算损失
result_loss = loss(outputs, targets)
# 4. 反向传播:根据损失计算梯度
result_loss.backward()
# 5. 更新参数:调用优化器,根据梯度更新模型的所有参数
optim.step()
running_loss += result_loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(dataloader)}")代码详细讲解
- 准备工作 :我们首先加载了
CIFAR10数据集,并用DataLoader进行包装,以便后续可以方便地按批次读取数据。 - 模型定义 :
Tudui类的定义与上一节完全相同。 - 实例化 :
tudui = Tudui()创建了我们的网络模型。loss = nn.CrossEntropyLoss()创建了损失函数。optim = torch.optim.SGD(tudui.parameters(), lr=0.01)是本节的核心。我们创建了一个SGD优化器,并将tudui模型的所有可训练参数 (tudui.parameters()) 交给它管理。同时,我们设置了学习率lr为0.01。从这一刻起,optim就知道它需要更新哪些参数,以及更新的基本步长。
- 训练循环 :
- 我们用一个
for循环来遍历dataloader中的所有数据。 optim.zero_grad():这是循环的第一步。在计算新一轮的梯度之前,必须将优化器中存储的旧梯度清零。outputs = tudui(imgs)和result_loss = loss(outputs, targets):这两步是正向传播和计算损失,与上一节一致。result_loss.backward():这是关键的反向传播步骤。PyTorch会自动计算出result_loss相对于网络中每一个参数的梯度,并将这些梯度值保存在各个参数的.grad属性中。optim.step():这是最后一步。当optim.step()被调用时,优化器会检查它所管理的所有参数,并利用这些参数的.grad属性中存储的梯度值,以及初始化时设置的学习率lr等超参数,来对参数的值进行更新。
- 我们用一个
通过不断重复这个循环,模型就在数据上进行了学习,其参数被优化器持续调整,以期让损失值越来越小。
现有网络模型的使用及修改
从头开始训练一个深度神经网络不仅需要大量的计算资源(如高性能GPU)和时间,还需要海量的标注数据。幸运的是,研究社区已经为我们提供了一系列在超大型数据集(如ImageNet)上训练好的模型。这些模型已经学会了如何提取图像的通用特征(如边缘、纹理、形状等)。我们可以利用这些预训练好的模型,通过一种名为**迁移学习(Transfer Learning)**的技术,快速地将它们应用到我们自己的任务上。
PyTorch的torchvision.models模块中内置了许多著名的计算机视觉模型,如VGG, ResNet, MobileNet等。我们可以非常方便地加载并使用它们。
加载预训练模型
在使用torchvision中的模型时,通常会遇到一个非常关键的参数:pretrained。
pretrained(bool):- 如果设置为
pretrained=True,PyTorch会自动下载该模型在ImageNet数据集上训练好的权重参数。这意味着你得到的不是一个随机初始化的"空"模型,而是一个已经具备强大图像识别能力的"成品"模型。 - 如果设置为
pretrained=False(默认值),你将得到一个结构相同但权重是随机初始化的模型。你需要从零开始在自己的数据集上训练它。
- 如果设置为
安装与准备
torchvision库在处理图像时可能依赖于其他库,例如Pillow和SciPy。为确保所有功能正常,可以通过pip进行安装:
bash
pip install torchvision pillow scipy代码实战:使用并修改VGG16模型
我们以经典的VGG16模型为例,演示如何加载它,并修改其结构以适应我们自己的分类任务(例如,将1000类的ImageNet分类任务改为10类的CIFAR10分类任务)。
VGG
python
import torch
import torchvision
from torch import nn
# -------------------- 1. 加载VGG16模型 --------------------
# 加载一个随机初始化的VGG16模型结构
# pretrained=False 表示我们只使用这个模型的结构,不加载预训练权重
vgg16_false = torchvision.models.vgg16(pretrained=False)
# 加载一个在ImageNet上预训练好的VGG16模型
# pretrained=True 会自动下载模型的权重参数
# 注意:第一次运行时,会有一个从网络下载权重的过程,需要稍等片刻
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("----------- 未经修改的预训练VGG16 -----------")
print(vgg16_true)
# -------------------- 2. 修改模型的分类层 --------------------
# VGG16的原始设计是用于ImageNet的1000类分类。
# 如果我们的任务(例如CIFAR10)只有10个类别,就需要修改模型的最后一层。
# --- 方法一:使用 add_module() 在末尾添加一个新的层 ---
# 这种方法是在现有分类器的基础上,再追加一个新的线性层。
# vgg16_true.classifier 是VGG16的分类器部分。
# 我们可以看到它的最后一层输出是1000个特征。
# 我们可以在这1000个特征后面再接一个线性层,将其映射到我们需要的10个类别。
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
print("\n----------- 使用add_module修改后的VGG16 -----------")
print(vgg16_true)
# --- 方法二:直接替换分类器中的某一层 ---
# 这是更常用、更直接的方法。VGG16的分类器是一个Sequential模块,我们可以像操作列表一样操作它。
# 我们可以先打印出分类器的结构,找到需要替换的层。
print("\n----------- VGG16原始分类器结构 -----------")
print(vgg16_false.classifier)
# 从打印结果中我们可以看到,索引为[6]的层是最后一个线性层:Linear(in_features=4096, out_features=1000, bias=True)
# 我们直接用一个新的线性层替换掉它。
# 输入特征数(in_features)必须与前一层匹配,仍然是4096。
# 输出特征数(out_features)改为我们任务所需的类别数,这里是10。
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print("\n----------- 直接替换[6]号层修改后的VGG16 -----------")
print(vgg16_false)代码详细讲解
-
加载模型:
- 我们分别创建了两个VGG16实例:
vgg16_false(权重随机)和vgg16_true(权重经过预训练)。 - 当你打印
vgg16_true时,你会看到它清晰的层次结构,主要分为两大部分:features(包含一系列卷积层和池化层,用于提取图像特征)和classifier(包含一系列全连接层,用于根据提取的特征进行分类)。
- 我们分别创建了两个VGG16实例:
-
修改模型:
- 我们的目标 :VGG16的分类器
classifier最后输出的是1000个类别。假设我们的新任务只有10个类别,我们就必须修改网络,让它的最终输出维度是10。 - 方法一
add_module:vgg16_true.classifier指向模型的分类器部分。.add_module('add_linear', nn.Linear(1000, 10))的作用是在classifier这个Sequential模块的末尾 ,添加一个名为'add_linear'的新层。- 这个新层是一个线性层
nn.Linear,它的输入维度是1000(正好承接上一层的1000个输出),输出维度是10(我们新任务的类别数)。 - 修改后,你会看到分类器的层数增加了,最后多了一个我们添加的
add_linear层。
- 方法二 直接替换 :
- 这种方法更加灵活和常用。我们首先通过打印
vgg16_false.classifier来观察其内部结构,发现它是一个包含7个层的序列。 classifier[6]就是最后一个全连接层Linear(in_features=4096, out_features=1000, bias=True)。vgg16_false.classifier[6] = nn.Linear(4096, 10)这行代码的含义是:创建一个新的线性层,其输入维度in_features与原层保持一致(4096),输出维度out_features改为我们需要的10,然后用这个新层直接替换掉原来在索引6位置的层。- 修改后,你会发现分类器的总层数没变,但最后一层的输出维度已经变成了10。
- 这种方法更加灵活和常用。我们首先通过打印
- 我们的目标 :VGG16的分类器
通过这两种方法,我们就能成功地将一个为ImageNet设计的强大模型,改造为适用于我们自己特定任务的新模型。接下来,就可以用这个修改后的模型和我们自己的数据,进行后续的训练了。通常,在使用预训练模型时,我们会选择"冻结"features部分的权重(因为它们已经学会了通用特征提取),只训练我们修改过的classifier部分,这种方法被称为微调(Fine-tuning)。
网络模型的保存与读取
在PyTorch中,模型的保存和读取操作主要依赖于torch.save()和torch.load()两个函数。通常有两种主流的保存方式:一种是保存整个模型,另一种是仅保存模型的参数。官方推荐使用第二种方法,因为它更灵活、更安全。
保存模型的两种方式
我们先创建一个model_save.py文件来演示如何保存模型。
python
# 文件: model_save.py
import torch
import torchvision
# 1. 准备一个模型实例
# 我们以VGG16为例,pretrained=False表示我们只使用它的结构,权重是随机初始化的。
vgg16 = torchvision.models.vgg16(pretrained=False)
# -------------------- 方法1: 保存模型结构 + 模型参数 --------------------
# 使用torch.save()直接保存整个vgg16模型对象。
# 这种方法会将模型的类、结构、以及所有参数都序列化到一个文件中。
# 优点是简单直接。
torch.save(vgg16, "vgg16_method1.pth")
# -------------------- 方法2: 仅保存模型参数 (官方推荐) --------------------
# model.state_dict() 会返回一个字典,其中包含了模型所有可学习的参数(权重和偏置)。
# 我们只保存这个参数字典。
# 优点是文件更小,更灵活,且更安全,因为它不包含任何具体的类定义或代码。
torch.save(vgg16.state_dict(), "vgg16_method2.pth")代码讲解
-
方法1 (
torch.save(vgg16, ...)):- 这行代码使用了Python的
pickle技术,将vgg16这个完整的对象打包成一个文件。 - 这个文件不仅包含了所有的权重数据,还包含了模型的网络结构定义。
- 虽然方便,但缺点是加载时代码的依赖性强,如果你的项目结构发生变化,可能会导致加载失败。
- 这行代码使用了Python的
-
方法2 (
torch.save(vgg16.state_dict(), ...)):vgg16.state_dict()是关键。它会提取出模型中所有具有可学习参数的层(如卷积层、线性层),并将它们的参数(weight和bias)以字典的形式组织起来。- 这种方式只保存了模型的"状态"(即参数),而没有保存模型的结构。
- 这是推荐的做法,因为它使得保存的文件与代码本身解耦。只要你有模型的类定义,就可以加载这些参数来恢复模型状态,这在分享模型或进行代码重构时非常有用。
加载模型的两种方式
现在,我们创建一个model_load.py文件来演示如何加载刚才保存的模型。
python
# 文件: model_load.py
import torch
import torchvision
# 如果要加载自定义的模型,需要确保其类定义可见
# from model_save import Tudui
# -------------------- 加载方法1 --------------------
# 直接加载通过方法1保存的文件
# 在较新版本的PyTorch中,为了安全起见,加载包含Python对象的文件时
# 建议显式设置 weights_only=False,以确认你知晓这可能执行文件中的代码。
model_1 = torch.load('vgg16_method1.pth', weights_only=False)
# print(model_1)
# -------------------- 加载方法2 --------------------
# 1. 首先,需要手动创建一个与保存时结构完全相同的模型实例。
vgg16 = torchvision.models.vgg16(pretrained=False)
# 2. 加载参数字典。torch.load()可以直接读取这个字典文件。
state_dict = torch.load("vgg16_method2.pth")
# 3. 将加载的参数字典应用到模型实例上。
vgg16.load_state_dict(state_dict)
# print(vgg16)代码讲解
-
加载方法1:
model_1 = torch.load(...)一行代码就完成了所有工作,因为它从文件中恢复了完整的模型对象。weights_only=False:这是一个重要的安全参数。当torch.load加载的文件是用pickle序列化的Python对象时(如方法1保存的模型),文件本身可能包含可执行代码。设置weights_only=False表示你信任该文件的来源,并允许PyTorch重建这些对象。如果只加载参数字典(如方法2),则可以将此参数设置为True或省略,会更安全。
-
加载方法2:
- 关键步骤 :加载参数前,必须先有一个模型的"骨架"。所以我们先
vgg16 = torchvision.models.vgg16(pretrained=False)创建了一个结构正确但权重随机的模型。 - 然后,
vgg16.load_state_dict(...)将我们保存的参数字典"填充"到这个模型骨架中,用预先训练好的权重覆盖掉随机初始化的权重。 - 这个过程清晰地体现了"结构"与"参数"分离的思想。
- 关键步骤 :加载参数前,必须先有一个模型的"骨架"。所以我们先
一个需要注意的陷阱
方法1虽然简单,但存在一个巨大的陷阱:加载模型时,必须能够访问到模型的原始类定义。
让我们在model_save.py中添加一个自定义模型并保存它:
python
# 文件: model_save.py (追加内容)
from torch import nn
# 定义一个简单的自定义模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
# 使用方法1保存自定义模型
tudui = Tudui()
torch.save(tudui, "tudui_method1.pth")现在,如果在model_load.py中直接尝试加载它,而没有Tudui类的定义,就会报错:
python
# 文件: model_load.py (错误演示)
import torch
# 尝试直接加载,此时Python环境中没有Tudui类的定义
# 这会导致一个错误,因为torch.load不知道如何重建Tudui这个对象
model = torch.load('tudui_method1.pth', weights_only=False) # 这会抛出错误!
```**错误原因**:`torch.load`在读取文件时,发现需要创建一个`Tudui`类的实例,但它在当前的代码环境中找不到这个类的定义,因此无法继续。
**正确做法**:必须确保在调用`torch.load`之前,`Tudui`类的定义已经被执行。可以通过直接在加载脚本中定义,或者从保存它的文件中导入。
```python
# 文件: model_load.py (正确演示)
import torch
from torch import nn # 需要nn.Module来定义类
# 1. 必须先定义Tudui类,让torch.load知道如何构建模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
# 2. 现在再加载,就不会出错了
model = torch.load('tudui_method1.pth', weights_only=False)
print(model)这个陷阱进一步凸显了方法2(仅保存state_dict)的优越性。因为它不依赖于原始的类定义文件,只要你在新的项目中有同样结构的模型定义,就可以加载参数,代码更加灵活和可移植。