🚀 Spark 单机模式部署与启动教程(适配 Hadoop 3.1.1)
本文记录了在 Linux 环境中部署 Spark 的完整过程,使用 Standalone 单机模式,适配 Hadoop 3.1.1,最终可通过 Web 页面访问 Spark Master 状态界面。
🧱 1. 环境准备
- 操作系统:CentOS / Ubuntu / Rocky 等 Linux 发行版
- Hadoop 版本:3.1.1(已安装)
- Spark 版本:3.1.2 with Hadoop 3.2
- Java 8+
- 安装目录:
/opt/module/spark-3.1.2-bin-hadoop3.2 - 本机 IP:
192.168.0.110
📦 2. 安装 Spark
从 Apache 官方下载:
bash
wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz解压并移动到指定目录:
bash
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
mv spark-3.1.2-bin-hadoop3.2 /opt/module/⚙ 3. 配置环境变量
编辑 ~/.bashrc 或 ~/.bash_profile,添加以下内容:
bash
# Spark
export SPARK_HOME=/opt/module/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin使配置生效:
bash
source ~/.bashrc🧪 4. 启动 Spark(Standalone 模式)
4.1 启动 Master 服务:
bash
start-master.sh成功后会输出 Spark Master 的 URL,例如:
spark://192.168.0.110:70774.2 启动 Worker 服务(连接到 Master):
bash
start-worker.sh spark://192.168.0.110:7077🌐 5. 访问 Web UI
5.1 Spark Master 页面:
在浏览器访问:
http://192.168.0.110:8080可查看集群状态、Worker 数量、运行的应用等。
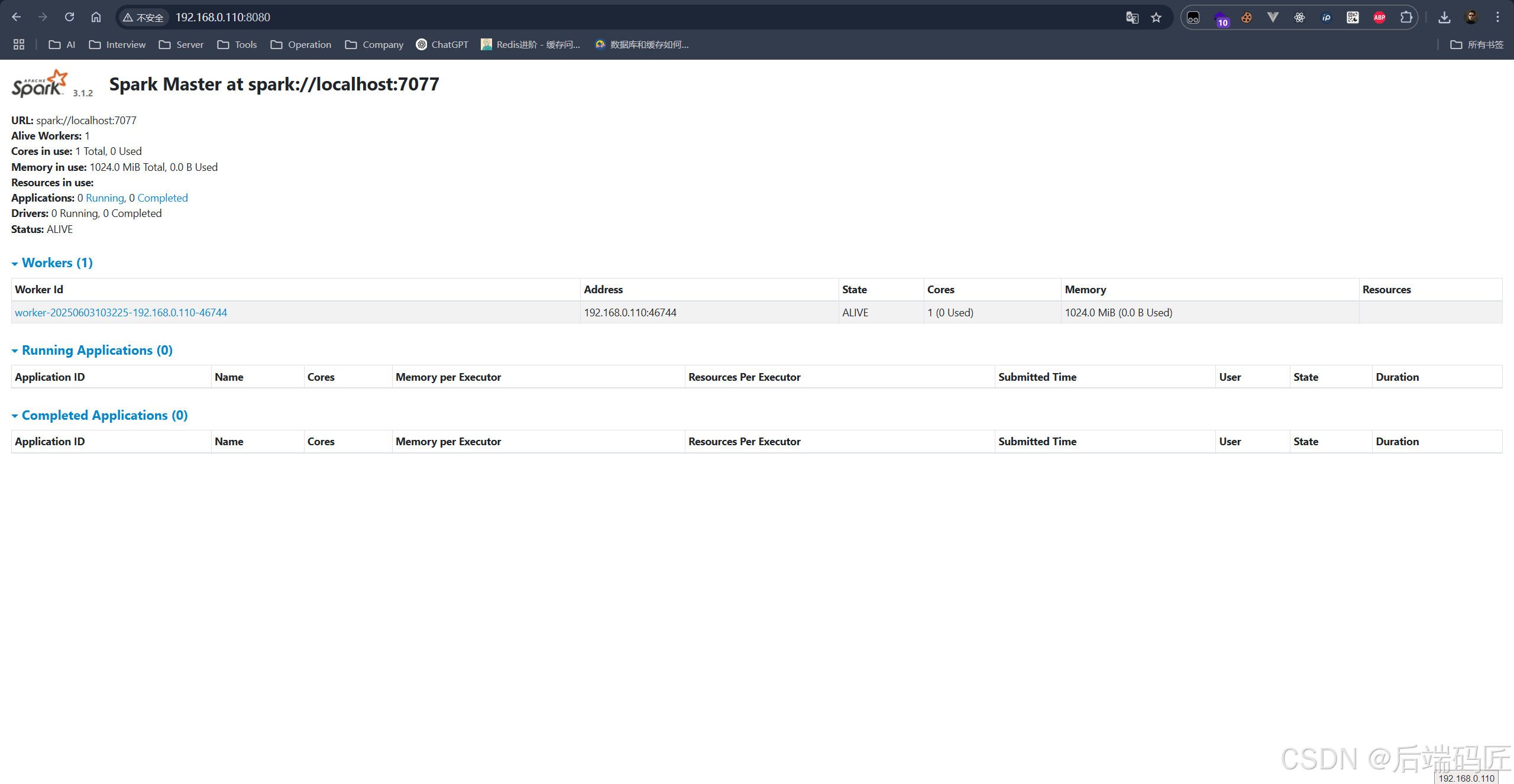
5.2 Worker 页面(默认端口 8081):
http://192.168.0.110:80815.3 Spark 应用页面(运行中):
如果你通过 spark-shell 或 spark-submit 启动应用,会自动开启:
http://192.168.0.110:4040✅ 6. 验证 Spark 可用性
bash
spark-shell进入交互式命令行,执行测试命令:
scala
val data = sc.parallelize(1 to 10)
data.reduce(_ + _)输出为 55 表示运行成功。
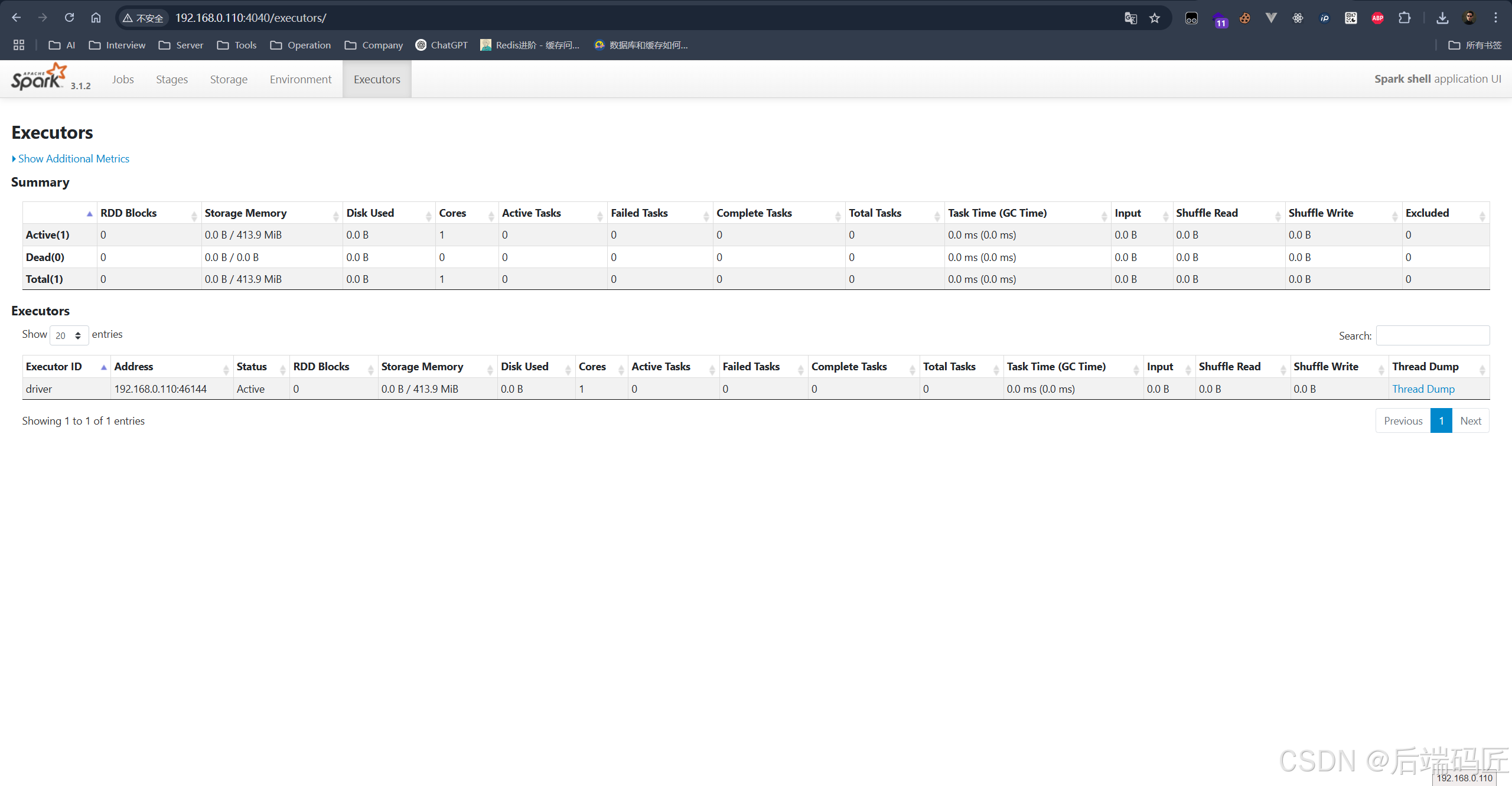
⛔ 7. 停止 Spark 服务
bash
stop-worker.sh
stop-master.sh🔐 8. 防火墙放行端口(可选)
确保你能从浏览器访问 Spark Web UI,需放通以下端口:
bash
sudo firewall-cmd --add-port=8080/tcp --permanent
sudo firewall-cmd --add-port=8081/tcp --permanent
sudo firewall-cmd --add-port=7077/tcp --permanent
sudo firewall-cmd --add-port=4040/tcp --permanent
sudo firewall-cmd --reload📌 总结
| 服务 | 启动命令 | 默认端口 | 访问地址 |
|---|---|---|---|
| Spark Master | start-master.sh |
8080 | http://192.168.0.110:8080 |
| Spark Worker | start-worker.sh spark://IP:7077 |
8081 | http://192.168.0.110:8081 |
| Spark Shell | spark-shell |
4040 | http://192.168.0.110:4040 |