循环神经网络(RNN)原理与发展
一、引言
在深度学习的众多模型中,循环神经网络(Recurrent Neural Network, RNN) 是专门为处理序列数据 而设计的一类模型。传统的前馈神经网络(Feedforward Neural Network)只能接受固定长度的输入,并且假设输入样本之间相互独立,这在图像分类等任务中表现良好。然而,对于自然语言、时间序列、语音信号等时间依赖性强的任务,这种假设显然不成立。
RNN 的出现正是为了解决这一问题------它能够让网络"记住"过去的信息,并将这些信息用于当前的预测。这使得它在自然语言处理(NLP)、语音识别、机器翻译、金融预测等任务中取得了重要应用。
二、RNN 的基本结构与原理
1. 序列建模的思路
RNN 的核心思想是:当前时刻的输出不仅依赖当前输入,还依赖之前的状态。
设输入序列为
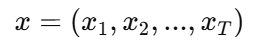
其中 (T) 为序列长度。对于每个时间步 (t),RNN 会维护一个隐藏状态 (h_t),它表示模型对到目前为止的记忆。
RNN 的基本计算公式为:
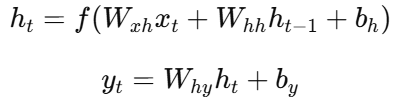
其中:
-
(x_t):当前时刻的输入;
-
(h_{t-1}):上一时刻的隐藏状态;
-
(h_t):当前隐藏状态;
-
(f(\cdot)):非线性激活函数(如 tanh 或 ReLU);
-
(W_{xh}, W_{hh}, W_{hy}):可学习参数矩阵;
-
(b_h, b_y):偏置项。
2. 循环结构
RNN 的"循环"体现在它的隐藏层结构上。每个时刻的隐藏状态会传递到下一时刻,如下图所示(展开后的时间结构):
x1 → [h1] → [h2] → [h3] → ... → [hT]
↑ ↑ ↑
| | |
x1 x2 x3这种结构使得信息可以在时间维度上传递,网络因此拥有"记忆"功能。
三、RNN 的前向传播与反向传播
1. 前向传播(Forward Pass)
在前向传播中,网络从 (t=1) 到 (t=T) 依次接收输入 (x_t),并更新隐藏状态 (h_t)。最终输出 (y_t) 可被用于预测下一词、生成序列或计算损失。
2. 反向传播(BPTT:Backpropagation Through Time)
RNN 的反向传播要跨越多个时间步,因此称为"时间反向传播"。由于每个时刻的参数是共享的,梯度需要沿着时间轴累积:
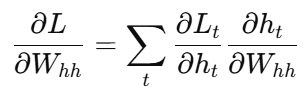
这种时间依赖使得 RNN 在训练过程中容易出现梯度消失 或梯度爆炸问题,尤其是在长序列中。
四、RNN 的主要问题
1. 梯度消失(Vanishing Gradient)
当序列较长时,梯度在时间反向传播的过程中会被不断乘上权重矩阵的导数(通常小于 1),导致梯度指数级衰减,模型无法学习到远距离依赖。
2. 梯度爆炸(Exploding Gradient)
相反,如果权重导数大于 1,则梯度会指数级增长,使模型训练不稳定。常用的解决方法包括:
-
梯度裁剪(Gradient Clipping);
-
使用更稳定的激活函数;
-
改进的循环结构(如 LSTM、GRU)。
五、RNN 的改进模型
为了解决基本 RNN 的缺陷,研究者提出了多种改进版本,最具代表性的两个是 LSTM 和 GRU。
1. LSTM(长短期记忆网络)
LSTM(Long Short-Term Memory)由 Hochreiter 和 Schmidhuber 于 1997 年提出。它通过引入**门控机制(Gate Mechanism)**来控制信息的流动,从而有效避免梯度消失。
LSTM 结构包含三个门和一个细胞状态:
-
遗忘门(Forget Gate):决定保留多少旧信息;
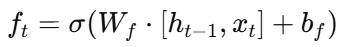
-
输入门(Input Gate):决定当前输入信息的保留程度;
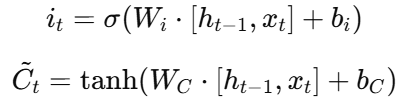
-
单元状态更新:
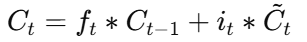
-
输出门(Output Gate) :
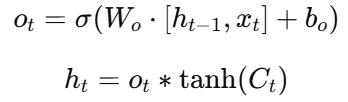
LSTM 的"细胞状态" (C_t) 类似一条信息管道,能长期保存上下文信息,从而有效建模长程依赖。
2. GRU(门控循环单元)
GRU(Gated Recurrent Unit)是 LSTM 的简化版,由 Cho 等人于 2014 年提出。它合并了遗忘门和输入门,并移除了独立的细胞状态。
GRU 的更新公式为:
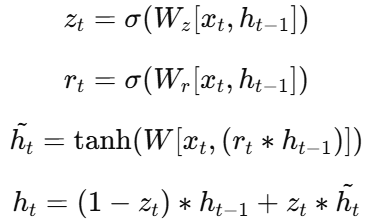
由于结构更简单,GRU 通常训练更快、效果与 LSTM 相近。
六、RNN 的应用场景
RNN 在处理时间序列或顺序相关数据时具有天然优势,常见应用包括:
-
自然语言处理(NLP)
-
语言模型(Language Model)
-
机器翻译(Machine Translation)
-
情感分析(Sentiment Analysis)
-
文本生成(Text Generation)
-
-
语音识别(Speech Recognition)
RNN 能捕捉声音的时间特征,用于语音到文本的转换。
-
时间序列预测
在金融、气象、流量等领域,用于预测未来趋势。
-
视频分析
结合 CNN(卷积神经网络)处理视频帧,再用 RNN 捕捉时间变化,用于动作识别或视频描述生成。
七、RNN 的发展方向与替代模型
虽然 RNN 在序列任务中曾占据主导地位,但随着 Transformer 的崛起,它的地位逐渐被取代。
Transformer 使用**自注意力机制(Self-Attention)**来捕捉序列中任意位置的依赖关系,避免了 RNN 的串行计算瓶颈。与 RNN 相比,Transformer:
-
并行性更强;
-
训练速度更快;
-
对长序列依赖建模能力更好。
然而,RNN 仍在某些小样本、低延迟、实时预测任务中保持优势,例如:
-
嵌入式设备上的在线语音识别;
-
小型时间序列预测;
-
低功耗传感器数据处理。
八、PyTorch 中的 RNN 实现示例
以下是一个使用 PyTorch 实现简单 RNN 的示例:
import torch
import torch.nn as nn
# 定义一个简单的RNN模型
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, h = self.rnn(x)
out = self.fc(out[:, -1, :]) # 取最后时刻输出
return out
# 超参数
input_size = 10
hidden_size = 32
output_size = 1
# 模型实例
model = SimpleRNN(input_size, hidden_size, output_size)
# 测试输入
x = torch.randn(16, 5, 10) # batch=16, seq_len=5, input_dim=10
y = model(x)
print(y.shape) # 输出:[16, 1]该模型通过 nn.RNN 模块实现循环网络结构,可轻松替换为 nn.LSTM 或 nn.GRU 以使用更强的门控版本。
九、总结
循环神经网络(RNN)是深度学习中里程碑式的结构之一,它首次让神经网络具备了"记忆"的能力,为时间序列建模提供了强大工具。
从最初的 RNN 到 LSTM、GRU,再到如今的 Transformer,序列建模经历了从时间依赖 到全局注意力的演化。
尽管在现代 NLP 中 Transformer 占据主导地位,但 RNN 的思想仍深刻影响着后续模型设计。理解 RNN,不仅是掌握深度学习的必经之路,更是理解时序智能的基础。