在线推荐、广告投放等场景中,强化学习推荐系统需要依据当前的用户与环境信息(上下文)即时选择最合适的动作,也就是决定展示哪条新闻或广告。微软研究院发表的论文《Making Contextual Decisions with Low Technical Debt》针对这类"上下文决策"问题,提出了一套通用的决策服务框架------Decision Service。论文链接如下:
- Microsoft Research Lab:https://www.microsoft.com/en-us/research/publication/making-contextual-decisions-with-low-technical-debt/
- arXiv:https://arxiv.org/abs/1606.03966v2
Decision Service框架将整条强化学习链路拆解为探索(Explore)、记录(Log)、学习(Learn)、部署(Deploy)四个可独立演进却首尾相接的模块:
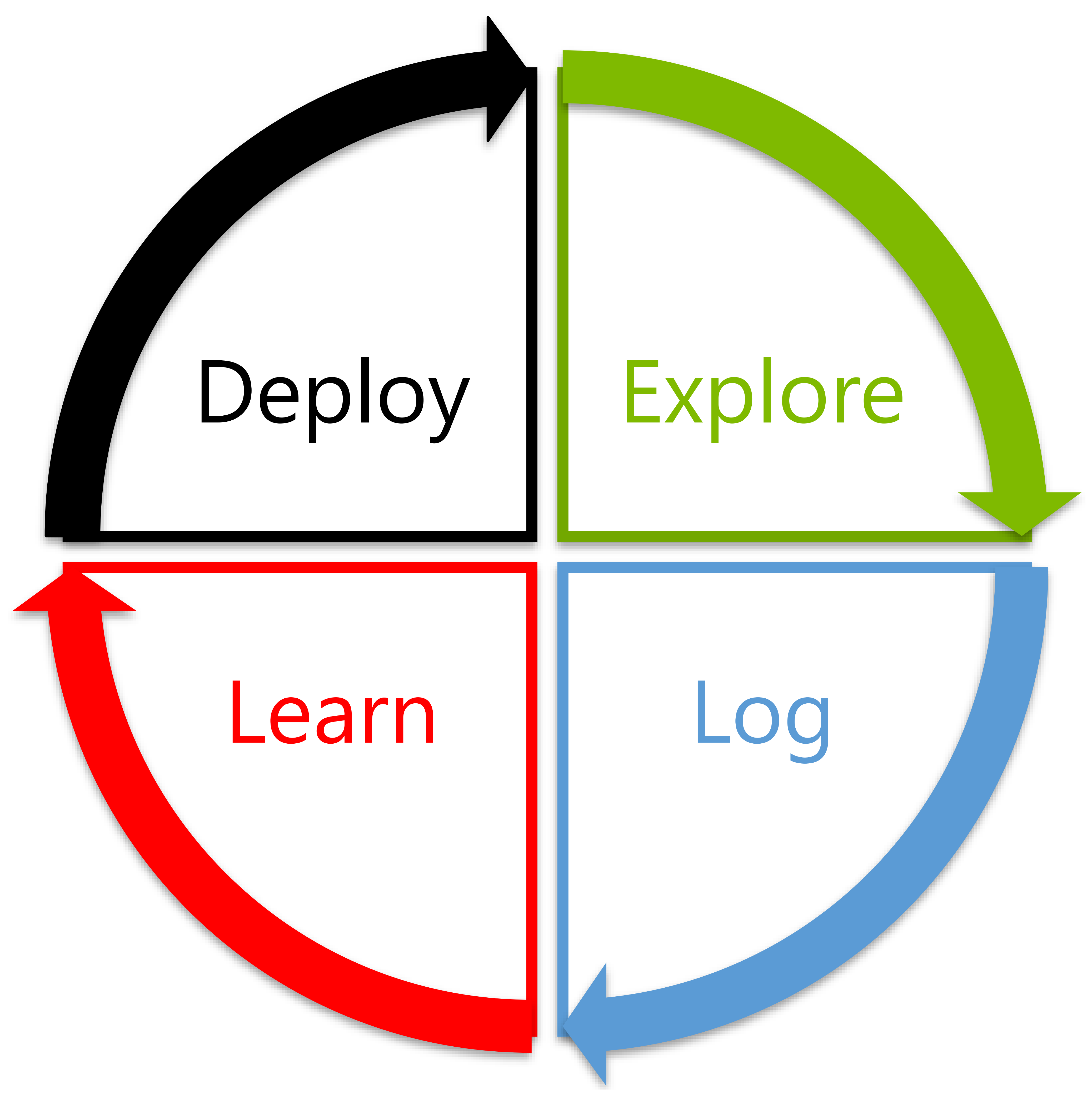
图1. 使用Decision Service框架进行有效的上下文学习的完整循环
1. 引言
在监督学习里,流程是线性的:先拿到完整的情境,接着让模型做出预测,最后拿到真实标签。因为真实标签对"所有可能的预测"都是已知的,因此可以直接衡量每个预测的好坏,并据此训练模型。
推荐系统这样的"上下文决策"场景则完全不同。系统必须先看用户当前的上下文(年龄、地域、兴趣等等),再从若干可选动作里挑一个,决定把政治新闻还是体育新闻摆在首页最显眼的位置。向用户展示的新闻最终会产生用户点击或不点击的反馈,其余未展示的新闻怎样就没人知道了。这种"部分反馈",让问题瞬间升级为强化学习难度。
首先,系统必须主动"探索"未被选中的动作,否则永远学不到它们的效果;其次,当前策略会影响未来收集到的数据,引入反馈偏差;最后,奖励往往还是延迟到来的(点击、购买、观看时长),进一步增加了数据不一致的风险。
所以说想要学到"成年人偏好政治新闻、青少年偏好体育新闻"这类映射,就不能再用传统监督学习的思路,而需要借助上下文多臂赌博机(contextual bandit)等强化学习方法,通过精心涉及的系统来解决探索、偏差和延迟带来的挑战。
2.系统架构
完整的决策服务架构如下图所示:
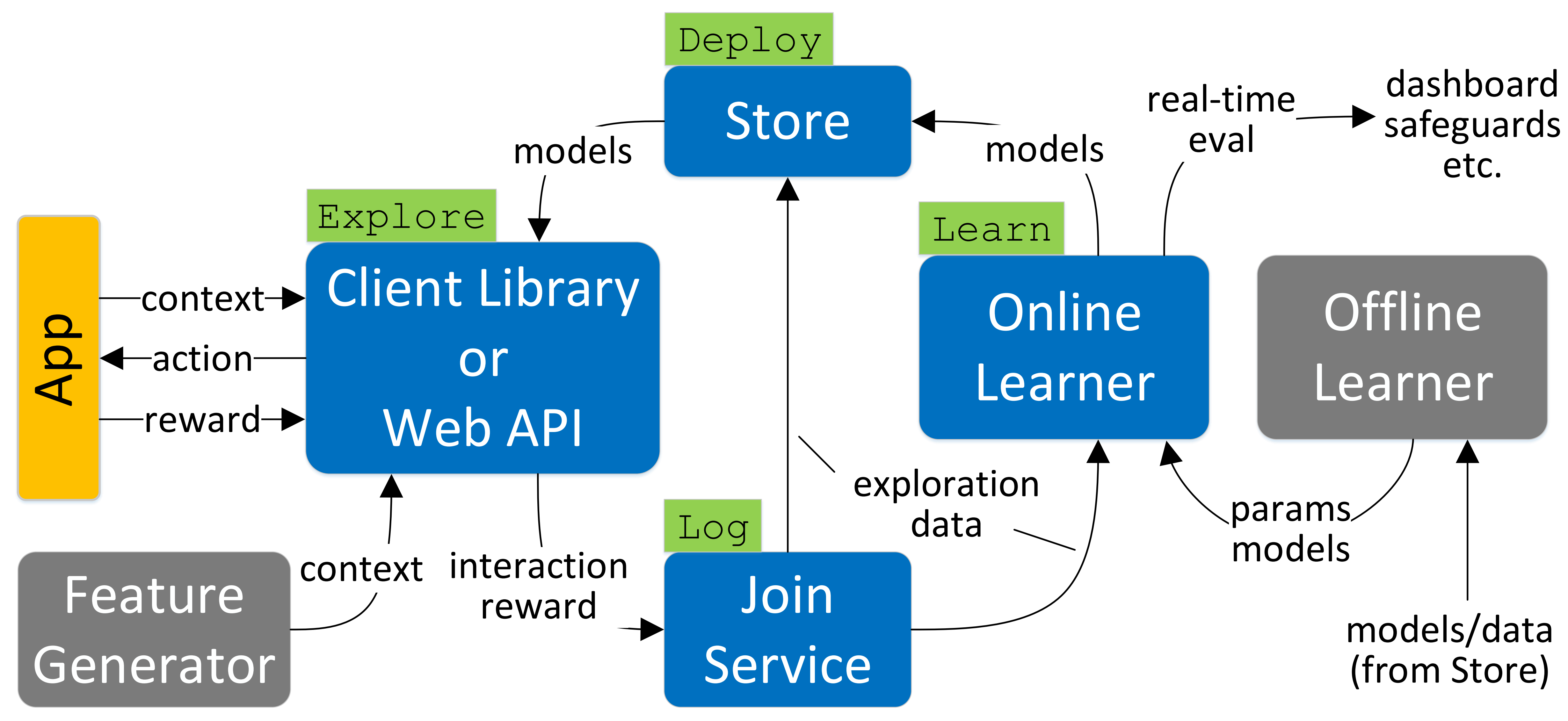
图2. Decision Service的架构
各个组件的作用是:
- 探索(Explorer) :探索组件负责与应用程序交互,它接收上下文特征 x x x(如用户信息、设备特征、候选项目等)和唯一标识符 k k k作为输入,根据当前的探索策略输出具体的动作a(如推荐的文章、广告等)。同时,该组件将包含决策信息的元组 < k , ( x , a , p ) > <k,(x, a, p)> <k,(x,a,p)>发送给Log组件进行记录,其中 p p p表示探索策略选择动作 a a a的概率。当应用程序后续收到用户反馈时,会将奖励 r r r,会形成 < k , ( r ) > <k,(r)> <k,(r)>一起传递给Log组件。
- 记录(Log) :记录组件用于将决策数据与奖励信息进行匹配,生成完整的探索数据集。考虑到奖励信息往往存在延迟到达的情况,Log组件接收带有标识符的观测数据流 ( k , o ) (k,o) (k,o),并输出拼接的观测数据流。对于具有相同标识符k的观测数据,若它们在时间窗口 t t t, t t t+exp_unit内到达( t t t为该标识符首次出现的时间),则会被连接成完整的训练样本;若在窗口期内未收到奖励信息,则默认赋值为0。
- 学习(Learn):学习组件负责在线策略训练,它持续接收来自Log组件的探索数据流,利用强化学习算法(上下文多臂机)进行增量学习,并输出带有唯一标识的模型(id, model)。系统可以在每接收到新数据后立即更新模型,也可以采用批量处理方式定期更新。
- 部署(Deploy):部署组件通过标准的get/put接口管理模型版本,Learn组件通过put操作将新训练的模型(id, model)存储到系统中,而Explorer组件则通过get操作获取指定版本的模型进行决策。当未指定模型版本时,系统自动返回最新的可用模型,确保决策过程始终使用最优策略。
客户端库(Client Library)是探索的实现,集成了多种探索策略,能够有效解决了部分反馈和偏差的问题,并确保向Log组件记录准确的数据从而解决数据采集错误问题。该库严格执行"在决策点进行日志记录"的原则(详见原文4.1节)。客户端库会以可配置的频率从部署组件中下载最新模型;在首个模型可用之前,系统执行默认策略或默认动作。为满足不同应用场景的需求,客户端库可以直接链接到以实现低延迟决策,也可以通过可移植、可扩展的 Web API 访问。

图3. Decision Service API可以通过跨平台web API(左)或低延迟客户端库(右)访问
连接服务(Join Service)通过将奖励信息与对应的决策数据进行匹配连接,生成正确的探索数据集,有效解决了数据采集错误问题。同时,在向学习组件发布数据前会强制实施统一的延迟等待机制(exp_unit),避免因奖励到达时间差异而产生的偏差,进一步解决了部分反馈和偏差问题。此外,生成的探索数据会同步复制到存储系统中,为后续的离线实验提供数据支持。
在线学习器(Online Learner)采用支持上下文多臂机在线学习的机器学习框架来实现。它能够持续整合新到达的数据,并按可配置的频率将训练好的模型检查点保存到部署组件中,实现了持续学习的目标并能够有效应对环境变化问题。为确保系统兼容性,客户端库必须使用兼容的机器学习框架来调用这些模型进行预测。在线学习器基于逆倾向评分(IPS)公式实现了对任意策略的实时评估能力,这正是多世界测试(MWT)功能的核心。这些实时统计信息为高级监控和安全保障机制提供了支撑,有效解决了监控调试问题。
ips ( π ) = 1 N ∑ t = 1 N I { π ( x t ) = a t } r t / p t ( 1 ) \text{ips}(\pi)=\frac{1}{N}\sum_{t=1}^{N}\mathbb{I}\{\pi(x_t)=a_t\}r_t/p_t\ (1) ips(π)=N1t=1∑NI{π(xt)=at}rt/pt (1)
公式(1)是Decision Service通过重要性加权来估计任意策略 π \pi π的平均奖励。其中,π表示待评估的策略; N N N表示探索数据的总数量;指示函数表示当策略 π \pi π在 t t t时刻的上下文 x x x下选择的动作与实际记录的动作 a a a相同时为1,否则为0。
存储系统(Store)为模型和数据提供统一的存储服务。离线学习器利用存储的数据进行各类离线实验,包括超参数调优、不同学习算法或策略类别的评估、奖励指标的调整等。这些离线实验具有反事实准确性保证。通过使用新的策略或参数设置重启在线学习器,即可将离线实验的改进成果无缝集成到在线学习循环中,这提升了系统的可用性和可定制性。
特征生成器(Feature Generator)通过为特定类型的内容自动生成特征,进一步降低了系统的使用门槛,提升了易用性。