视频扩散技术虽发展显著,但多数驾驶数据集事故事件少,难以生成逼真车祸图像,而提升交通安全又急需逼真可控的事故模拟。为此,论文提出可控车祸视频生成模型 Ctrl-Crash,它以边界框、碰撞类型、初始图像帧等为条件,能生成反事实场景,输入微小变动就可能引发截然不同的碰撞结果。


生成不同碰撞类型的场景
这些示例说明了针对多种不同碰撞类型(描述哪些参与者涉及碰撞)的场景:

事故重建
仅使用初始地面真实帧和所有边界框帧作为输入,通过 Ctrl-Crash 预测的碰撞:

碰撞预测
使用初始帧和前 9 个边界框帧作为输入,通过 Ctrl-Crash 预测崩溃(白色帧表示边界框被遮罩):

从非崩溃数据生成崩溃
通过调节初始帧和前 9 个边界框帧,从非事故 BDD100K 数据集生成碰撞:

相关链接
论文介绍

近年来,视频扩散技术取得了显著进展;然而,由于大多数驾驶数据集中事故事件的稀缺,它们难以生成逼真的车祸图像。提高交通安全需要逼真且可控的事故模拟。
为了解决这个问题,论文提出了 Ctrl-Crash,这是一个可控的车祸视频生成模型,它以边界框、碰撞类型和初始图像帧等信号为条件。提出的方法能够生成反事实场景,其中输入的微小变化都可能导致截然不同的碰撞结果。为了支持推理时的细粒度控制,作者利用无分类器引导,每个调节信号都有独立可调的尺度。与之前基于扩散的方法相比,Ctrl-Crash 在定量视频质量指标(例如 FVD 和 JEDi)和基于人工评估的物理真实感和视频质量的定性测量方面均实现了最佳性能。
方法概述
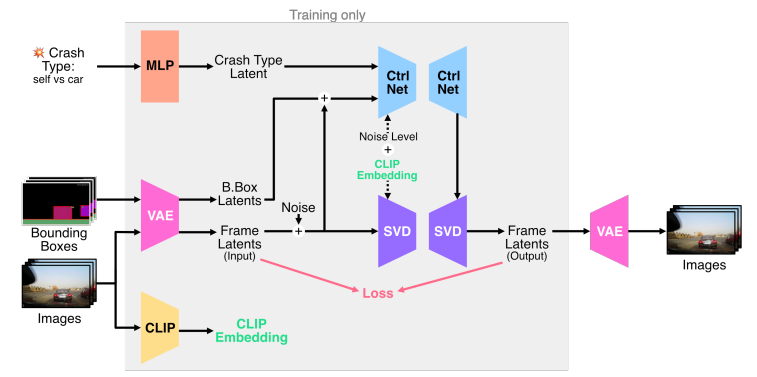
Ctrl-Crash 是一个可控的视频扩散框架,旨在通过空间和语义控制信号的引导,从单个初始帧生成逼真的车祸场景。Ctrl-Crash 基于 Ctrl-V (一个用于从渲染的边界框轨迹生成视频的框架),将其功能扩展到特定于车祸的场景,从而提供更丰富的控制和更大的灵活性。具体而言,论文引入了一种新的语义控制信号来表示车祸类型,并引入了一种改进的训练程序来处理部分和噪声条件。
实验结果

AVD2、DrivingGen、Ctrl-V 和 Ctrl-Crash 的定性结果比较。AVD2 生成的碰撞画面视觉上抖动,场景通常缺乏一致性。Driving-Gen 生成的视频质量低下且不连贯。虽然 Ctrl-V 实现了良好的视觉质量,但它无法生成逼真的碰撞事件。相比之下,Ctrl-Crash 在视觉保真度和场景一致性方面均优于所有基准,同时能够准确地建模碰撞动力学。



结论
Ctrl-Crash是一个可控的视频扩散框架,它能够从单帧生成逼真的车祸场景,在基于扩散的方法中达到了最佳性能,并通过改变空间和语义控制输入实现反事实推理。为了支持训练和评估,还开发了从车祸视频中提取边界框的处理流程,并发布了 MM-AU、RussiaCrash 和 BDD100k 的精选注释版本,以促进未来车祸模拟和生成式建模的研究。