欢迎关注我的CSDN:https://spike.blog.csdn.net/
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。

在使用 LlamaFactory 大模型进行推理时,记录了遇到的诸多问题及解决过程,为后续应用提供经验参考。
下载地址 LLaMA-Factory:https://github.com/hiyouga/LLaMA-Factory
也可使用代理下载,注意,下载之后,需要修改 remote 地址,即:
bash
git clone https://ghfast.top/https://github.com/hiyouga/LLaMA-Factory.git
git remote set-url origin https://github.com/hiyouga/LLaMA-Factory.git当前 Commit ID: e3d5e0fa28cdf5530ca7fae6feb04f88c1807de9
安装 Conda 环境,参考:使用 Docker 配置 PyTorch 研发环境
建议使用 Docker 环境,配置环境,安装 Python 依赖,以及 llama-factory 包:
bash
cd LLaMA-Factory
pip install -r requirements.txt
# pip uninstall llamafactory
pip install -e ".[torch,metrics]"
# llamafactory-0.9.3.dev0其他,相关环境:
bash
pip install peft transformers datasets deepspeed sentencepiece
pip install vllm --timeout=120
pip install trl==0.9.6注意:TRL 库 不是最新版本,使用 0.9.6 版本。
如果使用 webui 模式推理,需要修改源码的 IP 地址与 端口,同时,要重新安装 llama-factory 包,包括3处:
src/webui.py,1处src/llamafactory/webui/interface.py,2处
python
gradio_ipv6 = is_env_enabled("GRADIO_IPV6")
# gradio_share = is_env_enabled("GRADIO_SHARE")
# server_name = os.getenv("GRADIO_SERVER_NAME", "[::]" if gradio_ipv6 else "0.0.0.0")
print("Visit http://ip:port for Web UI, e.g., http://127.0.0.1:8090")
fix_proxy(ipv6_enabled=gradio_ipv6)
create_ui().queue().launch(share=False, server_name="0.0.0.0", server_port=8090, inbrowser=True)启动WebUI界面:
bash
export DISABLE_VERSION_CHECK=1
CUDA_VISIBLE_DEVICES="0,1" llamafactory-cli webui多卡环境需要指定环境变量,否则显存溢出。
启动页面:
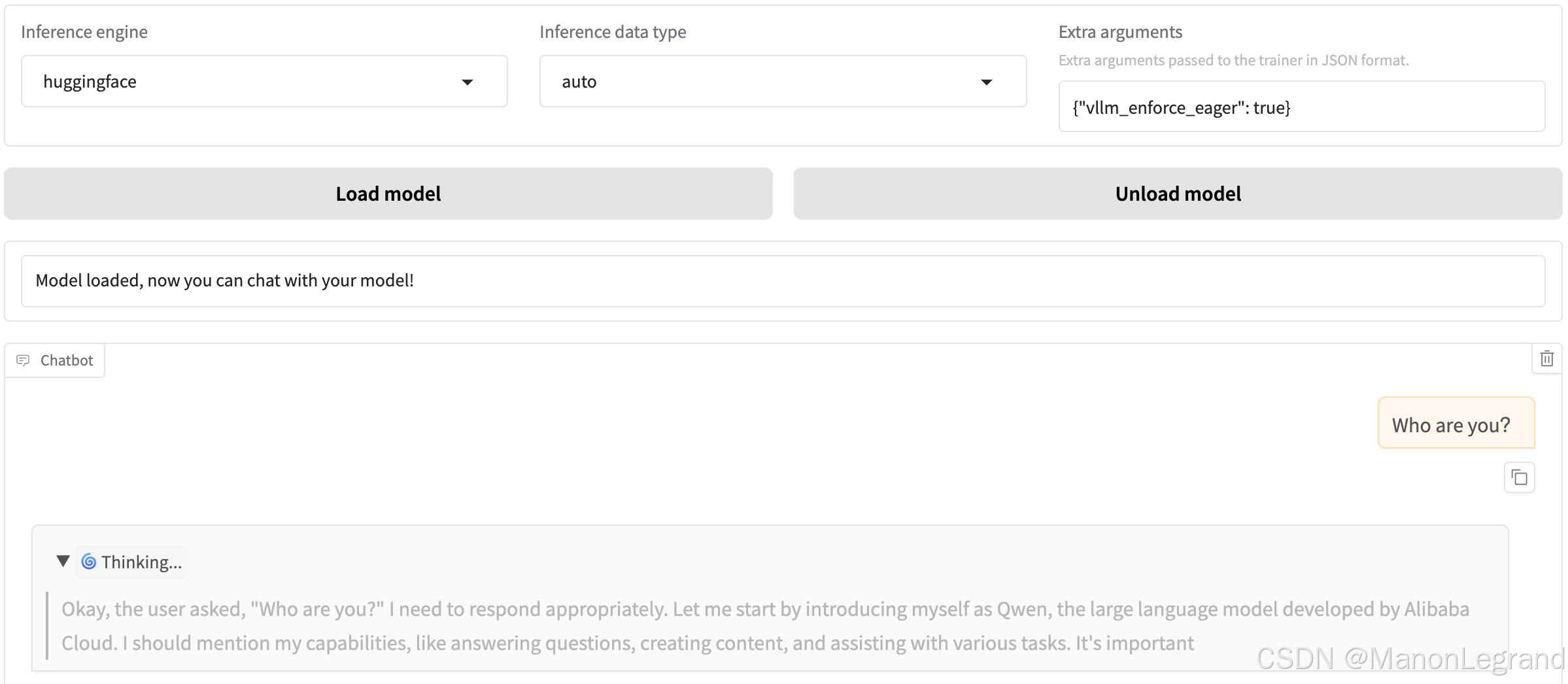
显存占用:
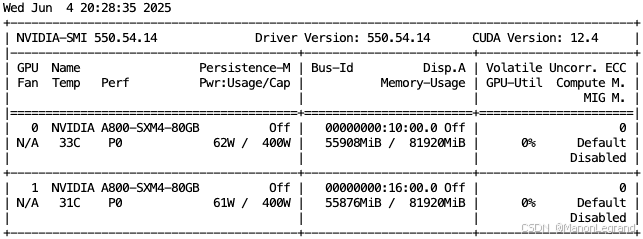
批量结束进程,即:
bash
ps -ef | grep "python3.11" | grep -v grep | awk '{print $2}'
ps -ef | grep "python3.11" | grep -v grep | awk '{print $2}' | xargs kill -9参考: