目录
[一. 概述](#一. 概述)
[1 不同语言的词法分析](#1 不同语言的词法分析)
[2 英语的形态分析](#2 英语的形态分析)
[编辑 2.动词、名词、形容词、副词不规则变化单词的形态还原](#编辑 2.动词、名词、形容词、副词不规则变化单词的形态还原)
[3 汉语自动分词概要](#3 汉语自动分词概要)
[4 分词与词性标注结果评价](#4 分词与词性标注结果评价)
[5 汉语自动分词基本算法](#5 汉语自动分词基本算法)
[编辑 未登录词识别](#编辑 未登录词识别)
一. 概述
词是自然语言中能够独立运用的最小单位, 是自然语言处理的基本单位。自动词法分析就是利用计算机对自然语言的形态(morphology) 进行分析,判断词的结构和类别等。
**词性或称词类(Part-of-Speech, POS)**是词汇 最重要的特性,是连接词汇到句法的桥梁。
1 不同语言的词法分析
曲折语(如,英语、德语、俄语等):用词的形态变化表示语法关系,一个形态成分可以表示若干种不同的语法意义,词根和词干与语词的附加成分结合紧密。
这类词的形态变化多(如动词时态、名词单复数),重点是 单词识别 (如缩写、连字符词)和 形态还原(如将 "worked" 还原为 "work")。
- 例如:"can't" 要拆成 "can + not","studies" 还原为 "study"
分析语(孤立语)(如:汉语) :没有形态变化,核心是 自动分词(把句子拆成词),但面临很多难题:
- 分词规范模糊:比如 "花草" 是词,"担水" 是短语还是词?
- 歧义问题 :
- 交集型歧义:如 "研究生物" 可拆成 "研究 / 生物" 或 "研究生 / 物"。
- 组合型歧义:如 "门把手" 可拆成 "门 / 把手" 或 "门把手"(整体为词)。
- 未登录词:人名(如 "令计划")、地名(如 "武夷山")、新词(如 "微信")难以识别。
**黏着语(如:日语等):**分词+形态还原。 (博主只会中英所以也不懂)
2 英语的形态分析
**基本任务:**单词识别和形态还原
英语单词的形态还原(和正常英语的词法变化一样)
1.有规律变化单词的形态还原


 2.动词、名词、形容词、副词不规则变化单词的形态还原
2.动词、名词、形容词、副词不规则变化单词的形态还原

3.对于表示年代、时间、百分数、货币、序数词的数字形态还原

4.合成词的形态还原


形态分析的一般方法

3 汉语自动分词概要
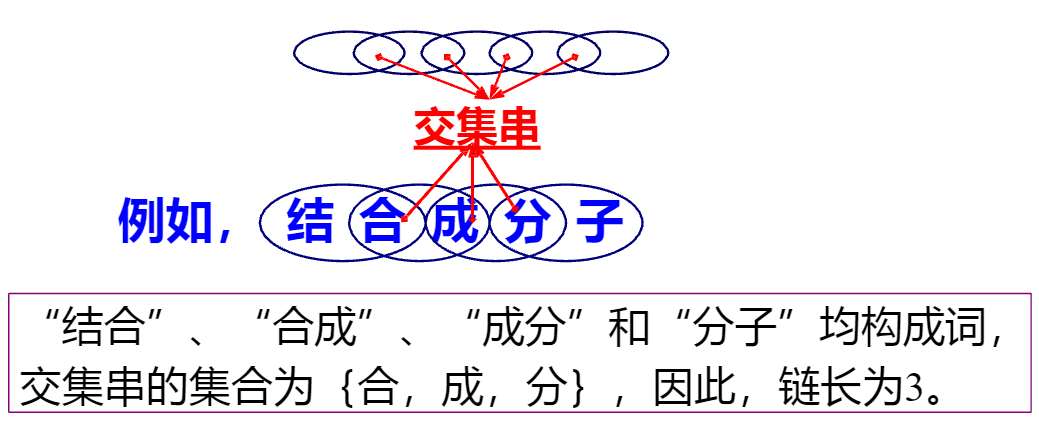
歧义切分字段处理
1.中国人为了实现自己的梦想 (交集型歧义)
中国/人为/ 了/ 实现/ 自己/ 的/ 梦想
中国人/ 为了/ 实现/ 自己/ 的/ 梦想
中/ 国人/ 为了/ 实现/ 自己/ 的/ 梦想
定义:链长 一个交集型切分歧义所拥有的交集串的集合称为交集串链,它的个数称为链长。
2、门把手弄坏了。(组合型歧义)
门/ 把/ 手/ 弄/ 坏/ 了/ 。
门/ 把手/ 弄/ 坏/ 了/ 。
例如,"将来"、"现在"、"才能"、"学生会"等,都是组合型歧义字段。
未登录词的识别

汉语自动分词的基本原则
1、语义上无法由组合成分直接相加而得到的字串应 该合并为一个分词单位。(合并原则)
例如:不管三七二十一(成语),或多或少(副词 片语),十三点(定量结构),六月(定名结构), 谈谈(重叠结构,表示尝试),辛辛苦苦(重叠结 构,加强程度),进出口(合并结构)
2、语类无法由组合成分直接得到的字串应该合并为一个分词单位。(合并原则)
(1)字串的语法功能不符合组合规律,如:好吃, 好喝,好听,好看等
(2)字串的内部结构不符合语法规律,如:游水等
汉语自动分词的辅助原则
1. 有明显分隔符标记的应该切分之(切分原则)
分隔标记指标点符号或一个词。如:
上、下课→上/ 下课
洗了个澡→洗/ 了/ 个/ 澡
2. 附着性语(词)素和前后词合并为一个分词单位 (合并原则)
例如:"吝"是一个附着语素,"不吝"、"吝于"等合并成一个词;
3. 使用频率高或共现率高的字串尽量合并为一个分词 单位 (合并原则)
如:"进出"、"收放"(动词并列);"大笑"、 "改称"(动词偏正);"关门"、"洗衣"、 "卸货"(动宾结构);"春夏秋冬"、"轻重 缓急"、"男女"(并列结构);"象牙"(名 词 偏正);"暂不"、"毫不"、"不再"等。
4. 双音节加单音节的偏正式名词尽量合并为一个分词单位 (合并原则)
如:"线、权、车、点"等所构成的偏正式名词: "国际线、分数线、贫困线"、"领导权、发言权、 知情权"、"垃圾车、交通车、午餐车"、"立足 点、共同点、着眼点"等。
5. 双音节结构的偏正式动词应尽量合并为一个分词单位 (合并原则)
本原则只适合少数偏正式动词,如:"紧追其后"、 "组建完成"等,不适合动宾及主谓式复合动词。
6.内部结构复杂、合并起来过于冗长的词尽量切分 (切分原则)
4 分词与词性标注结果评价
正确率(Correct ratio/Precision, P ): 测试结果中 正确切分或标注的个数占系统所有输出结果的比例。假设系统输出N个,其中,正确的结果为n个,那么
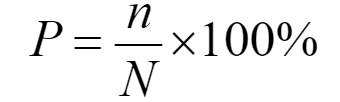



5 汉语自动分词基本算法
有词典切分/ 无词典切分
基于规则的方法/ 基于统计的方法
1. 最大匹配法 (Maximum Matching, MM) -有词典切分,机械切分
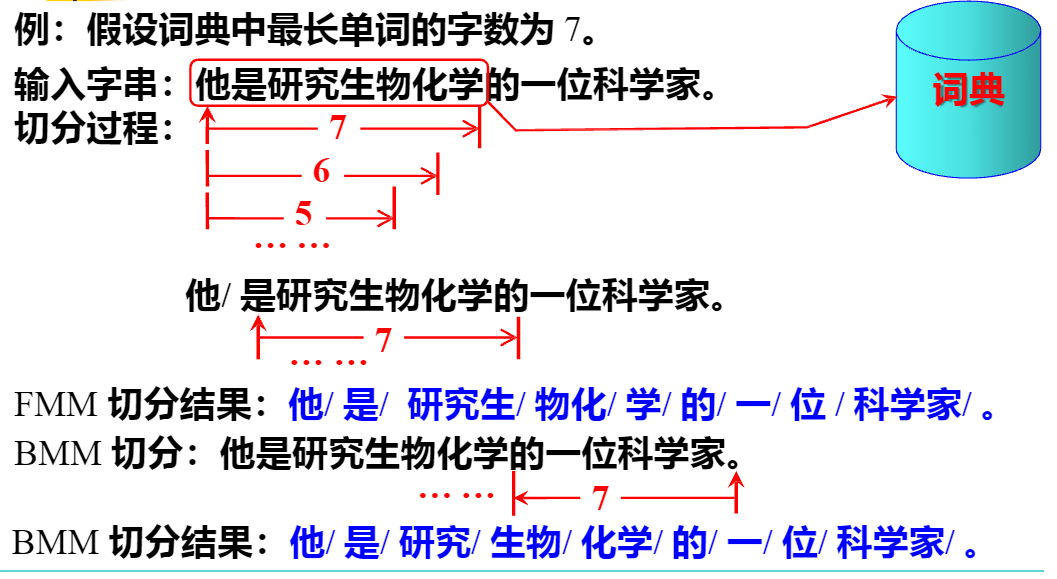


简单说,就是把句子拆成字,用词典找能组成的词,然后选拆分后词数量最少的那种结果,就像拼拼图,找最简洁的拼法 。




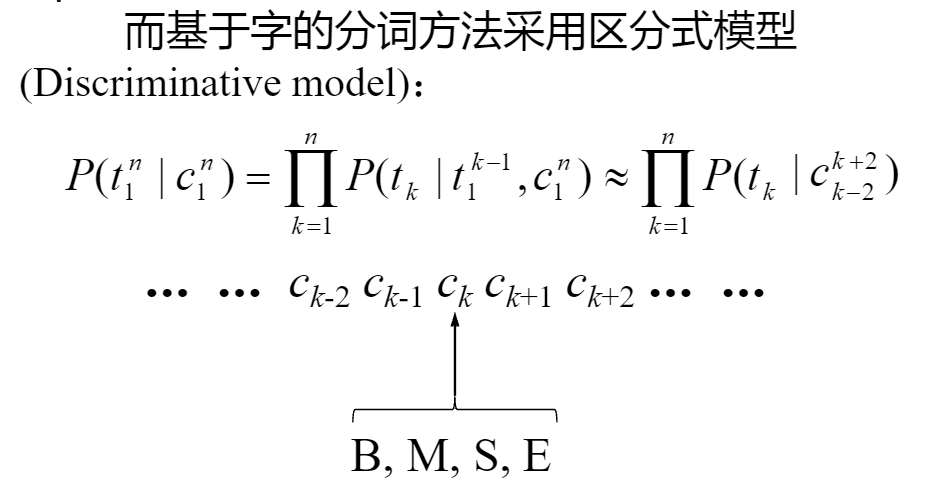 未登录词识别
未登录词识别



- 想判断 "某字符串是不是姓名",就用 概率估值公式,把 "姓的常见度" 和 "名的字的常见度" 相乘,算个数值。
- 想知道 "姓 + 名" 至少得有多 "常见" 才算合理姓名,就用 最小阈值公式,找名里最冷门的组合,再和姓的常见度相乘,得到一个 "底线数值"。
- 实际应用里,比如电脑识别姓名时,会拿计算出的 P (Cname) 和 T min(X) 比,超过阈值就认为是姓名,没超过就排除~


 如何确定地名?
如何确定地名?


