1.转化器和估计器的概念
转化器是用于对数据进行转换或预处理的工具,其核心功能是将输入数据从一种表示形式转换为另一种形式,以便于模型更好地学习或分析。转化器通常需要满足以下特点:
(1)拟合(Fit)和转换(Transform):先通过拟合数据学习转换规则(如均值、方差),再应用规则对数据进行转换。
(2)无监督或有监督:多数转化器是无监督的(如特征缩放),少数可能依赖标签(如标签编码)。
常见类型与场景:
(1)数据预处理
特征缩放:如标准化(StandardScaler)、归一化(MinMaxScaler),将特征值缩放到特定范围。
特征编码:如独热编码(OneHotEncoder)、标签编码(LabelEncoder),将类别型数据转换为数值型。
缺失值处理:如 SimpleImputer,用均值、中位数或众数填充缺失值。
(2)特征工程
多项式特征生成(PolynomialFeatures):从原始特征生成多项式组合特征。
文本向量化:如 TF-IDF Vectorizer,将文本转换为数值型特征矩阵。
估计器是用于从数据中学习模型参数并进行预测的算法或模型,其核心功能是通过拟合训练数据,建立输入特征(X)与输出标签(y)之间的映射关系。估计器通常需要实现以下方法:
(1)fit(X, y):用训练数据拟合模型,学习参数。
(2)predict(X):用拟合好的模型对新数据进行预测。
常见类型与场景
(1)监督学习模型
分类器:如逻辑回归(Logistic Regression)、支持向量机(SVM)、随机森林(Random Forest),用于预测离散标签。
回归器:如线性回归(Linear Regression)、梯度提升树(Gradient Boosting Regressor),用于预测连续数值。
(2)无监督学习模型
聚类算法:如 K 均值(K-Means)、DBSCAN,用于发现数据中的簇结构。
密度估计:如高斯混合模型(GMM),用于估计数据的概率分布。
2.管道工程
在机器学习中,** 管道工程(Pipeline)** 是一种将数据预处理、特征工程和模型训练等多个步骤串联成一个完整工作流的技术。通过管道,开发者可以以标准化、模块化的方式管理整个机器学习流程,避免代码冗余,防止数据泄漏,并简化模型调优和部署。
(1)为什么需要管道?
简化工作流:将数据清洗、特征转换、模型训练等步骤整合为一个对象,避免分步处理的繁琐。
防止数据泄漏(Data Leakage):确保预处理步骤仅在训练集上拟合(fit),再应用于测试集,避免信息从测试集 "泄漏" 到训练阶段。
方便调参与复用:可将整个管道作为单一模型进行超参数搜索(如网格搜索),并方便地保存和复用整个流程。
代码整洁性:用统一接口管理多个步骤,减少重复代码,提升可读性。
(2)管道的核心组件
管道由一系列有序的步骤组成,每个步骤是一个元组(step_name, step_object),其中:
前序步骤:必须是转化器(Transformer),需实现fit()和transform()方法(如数据缩放、特征编码)。
最后一步:必须是估计器(Estimator),需实现fit()和predict()方法(如分类器、回归器)。
3.ColumnTransformer和Pipeline类
ColumnTransformer:混合特征的差异化预处理
核心作用
当数据包含多种类型的特征(如数值型、类别型、文本型、日期型等)时,不同特征往往需要不同的预处理方法。例如:
数值型特征:需要标准化(StandardScaler)或归一化(MinMaxScaler);
类别型特征:需要独热编码(OneHotEncoder)或目标编码(TargetEncoder);
文本型特征:需要词向量化(TfidfVectorizer)。
ColumnTransformer 允许为不同的列(特征)定义独立的预处理逻辑,并将结果合并为一个特征矩阵,最终输出给模型使用。
关键参数与用法
ColumnTransformer 的构造函数主要参数如下:
from sklearn.compose import ColumnTransformer
transformer = ColumnTransformer(
transformers=[ # 定义各列的处理方式(列表中的每个元素是一个元组)
("name1", transformer1, columns1), # 元组格式:(步骤名, 转化器, 列选择)
("name2", transformer2, columns2),
],
remainder="drop" # 未指定列的处理方式(默认"drop",可选"passthrough"保留)
)transformers:核心参数,每个元素是一个三元组 (name, transformer, columns),其中:
name:步骤名(用于后续参数调优时的命名空间);
transformer:具体的转化器(如 StandardScaler、OneHotEncoder);
columns:需要应用该转化器的列(可以是列名列表、索引列表,或 slice 对象)。
remainder:未被 transformers 覆盖的列的处理方式:
"drop"(默认):丢弃这些列;
"passthrough":保留这些列(不做任何处理);
也可以传入一个自定义转化器,对剩余列进行处理。
Pipeline:全流程标准化串联
核心作用
Pipeline 用于将多个数据处理步骤和模型训练步骤串联成一个单一对象,确保:
数据预处理(转化器)和模型训练(估计器)的流程标准化;
防止数据泄漏(仅在训练集上拟合预处理参数,测试集使用相同参数转换);
方便模型调优(将整个流程作为单一对象进行超参数搜索)。
前 N-1 步必须是转化器(实现 fit() 和 transform()),最后一步必须是估计器(实现 fit() 和 predict())。
接口统一:Pipeline 对象对外提供与估计器一致的接口(fit()、predict()、score() 等),内部自动按顺序执行各步骤。
关键参数与用法
Pipeline 的构造函数接受一个步骤列表,每个步骤是 (name, estimator) 元组:
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
("preprocessor", ColumnTransformer(...)), # 预处理步骤(转化器)
("classifier", LogisticRegression()) # 模型步骤(估计器)
])ColumnTransformer 解决混合特征的差异化预处理问题,而 Pipeline 解决全流程标准化问题,二者结合可构建完整的机器学习工作流:
典型流程
数据输入:原始数据集(包含多种类型特征);
ColumnTransformer 预处理:对不同列应用不同的转化器(如标准化、独热编码、文本向量化),输出统一的特征矩阵;
Pipeline 串联:将 ColumnTransformer 作为 Pipeline 的预处理步骤,后续接入模型(估计器);
训练与预测:通过 Pipeline.fit() 完成预处理参数学习和模型训练,通过 Pipeline.predict() 完成测试数据的预处理和预测。
4.代码
# 导入基础库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time # 导入 time 库
import warnings
# 忽略警告
warnings.filterwarnings("ignore")
# 设置中文字体和负号正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 导入 Pipeline 和相关预处理工具
from sklearn.pipeline import Pipeline # 用于创建机器学习工作流
from sklearn.compose import ColumnTransformer # 用于将不同的预处理应用于不同的列
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于数据预处理(有序编码、独热编码、标准化)
from sklearn.impute import SimpleImputer # 用于处理缺失值
# 导入机器学习模型和评估工具
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import classification_report, confusion_matrix # 用于评估分类器性能
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
# --- 加载原始数据 ---
# 我们加载原始数据,不对其进行任何手动预处理
data = pd.read_csv('data.csv')
print("原始数据加载完成,形状为:", data.shape)
# --- 分离特征和标签 (使用原始数据) ---
y = data['Credit Default'] # 标签
X = data.drop(['Credit Default'], axis=1) # 特征 (axis=1 表示按列删除)
print("\n特征和标签分离完成。")
print("特征 X 的形状:", X.shape)
print("标签 y 的形状:", y.shape)
# --- 划分训练集和测试集 (在任何预处理之前划分) ---
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
print("\n数据集划分完成 (预处理之前)。")
print("X_train 形状:", X_train.shape)
print("X_test 形状:", X_test.shape)
print("y_train 形状:", y_train.shape)
print("y_test 形状:", y_test.shape)
# --- 定义不同列的类型和它们对应的预处理步骤 ---
# 这些定义是基于原始数据 X 的列类型来确定的
# 识别原始的 object 列 (对应你原代码中的 discrete_features 在预处理前)
object_cols = X.select_dtypes(include=['object']).columns.tolist()
# 识别原始的非 object 列 (通常是数值列)
numeric_cols = X.select_dtypes(exclude=['object']).columns.tolist()
# 有序分类特征 (对应你之前的标签编码)
# 注意:OrdinalEncoder默认编码为0, 1, 2... 对应你之前的1, 2, 3...需要在模型解释时注意
# 这里的类别顺序需要和你之前映射的顺序一致
ordinal_features = ['Home Ownership', 'Years in current job', 'Term']
# 定义每个有序特征的类别顺序,这个顺序决定了编码后的数值大小
ordinal_categories = [
['Own Home', 'Rent', 'Have Mortgage', 'Home Mortgage'], # Home Ownership 的顺序 (对应1, 2, 3, 4)
['< 1 year', '1 year', '2 years', '3 years', '4 years', '5 years', '6 years', '7 years', '8 years', '9 years', '10+ years'], # Years in current job 的顺序 (对应1-11)
['Short Term', 'Long Term'] # Term 的顺序 (对应0, 1)
]
# 构建处理有序特征的 Pipeline: 先填充缺失值,再进行有序编码
ordinal_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')), # 用众数填充分类特征的缺失值
('encoder', OrdinalEncoder(categories=ordinal_categories, handle_unknown='use_encoded_value', unknown_value=-1)) # 进行有序编码
])
print("有序特征处理 Pipeline 定义完成。")
# 标称分类特征 (对应你之前的独热编码)
nominal_features = ['Purpose'] # 使用原始列名
# 构建处理标称特征的 Pipeline: 先填充缺失值,再进行独热编码
nominal_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')), # 用众数填充分类特征的缺失值
('onehot', OneHotEncoder(handle_unknown='ignore', sparse_output=False)) # 进行独热编码, sparse_output=False 使输出为密集数组
])
print("标称特征处理 Pipeline 定义完成。")
# 连续特征 (对应你之前的众数填充 + 添加标准化)
# 从所有列中排除掉分类特征,得到连续特征列表
# continuous_features = X.columns.difference(object_cols).tolist() # 原始X中非object类型的列
# 也可以直接从所有列中排除已知的有序和标称特征
continuous_features = [f for f in X.columns if f not in ordinal_features + nominal_features]
# 构建处理连续特征的 Pipeline: 先填充缺失值,再进行标准化
continuous_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')), # 用众数填充缺失值 (复现你的原始逻辑)
('scaler', StandardScaler()) # 标准化,一个好的实践 (如果你严格复刻原代码,可以移除这步)
])
print("连续特征处理 Pipeline 定义完成。")
# --- 构建 ColumnTransformer ---
# 将不同的预处理应用于不同的列子集,构造一个完备的转化器
# ColumnTransformer 接收一个 transformers 列表,每个元素是 (名称, 转换器对象, 列名列表)
preprocessor = ColumnTransformer(
transformers=[
('ordinal', ordinal_transformer, ordinal_features), # 对 ordinal_features 列应用 ordinal_transformer
('nominal', nominal_transformer, nominal_features), # 对 nominal_features 列应用 nominal_transformer
('continuous', continuous_transformer, continuous_features) # 对 continuous_features 列应用 continuous_transformer
],
remainder='passthrough' # 如何处理没有在上面列表中指定的列。
# 'passthrough' 表示保留这些列,不做任何处理。
# 'drop' 表示丢弃这些列。
)
print("\nColumnTransformer (预处理器) 定义完成。")
# print(preprocessor) # 可以打印 preprocessor 对象看看它的结构
# --- 构建完整的 Pipeline ---
# 将预处理器和模型串联起来
# 使用你原代码中 RandomForestClassifier 的默认参数和 random_state,这里的参数用到了元组这个数据结构
pipeline = Pipeline(steps=[
('preprocessor', preprocessor), # 第一步:应用所有的预处理 (ColumnTransformer)
('classifier', RandomForestClassifier(random_state=42)) # 第二步:随机森林分类器
])
# --- 1. 使用 Pipeline 在划分好的训练集和测试集上评估 ---
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
start_time = time.time() # 记录开始时间
# 在原始的 X_train 上拟合整个Pipeline
# Pipeline会自动按顺序执行preprocessor的fit_transform(X_train),然后用处理后的数据拟合classifier
pipeline.fit(X_train, y_train)
# 在原始的 X_test 上进行预测
# Pipeline会自动按顺序执行preprocessor的transform(X_test),然后用处理后的数据进行预测
pipeline_pred = pipeline.predict(X_test)
end_time = time.time() # 记录结束时间
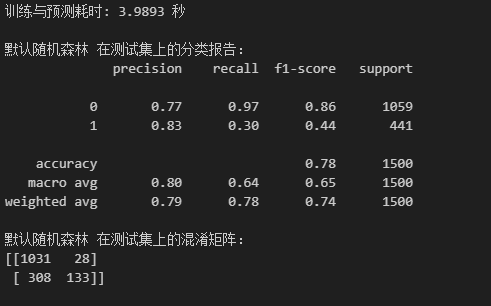
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒") # 使用你原代码的输出格式
print("\n默认随机森林 在测试集上的分类报告:") # 使用你原代码的输出文本
print(classification_report(y_test, pipeline_pred))
print("默认随机森林 在测试集上的混淆矩阵:") # 使用你原代码的输出文本
print(confusion_matrix(y_test, pipeline_pred))