知识点回顾:
-
resnet结构解析
-
CBAM放置位置的思考
-
针对预训练模型的训练策略
a. 差异化学习率
b. 三阶段微调
现在我们思考下,是否可以对于预训练模型增加模块来优化其效果,这里我们会遇到一个问题
预训练模型的结构和权重是固定的,如果修改其中的模型结构,是否会大幅影响其性能。其次是训练的时候如何训练才可以更好的避免破坏原有的特征提取器的参数。
所以今天的内容,我们需要回答2个问题。
- resnet18中如何插入cbam模块?
- 采用什么样的预训练策略,能够更好的提高效率?
可以很明显的想到,如果是resnet18+cbam模块,那么大多数地方的代码都是可以复用的,模型定义部分需要重写。先继续之前的代码
所以很容易的想到之前第一次使用resnet的预训练策略:先冻结预训练层,然后训练其他层。之前的其它层是全连接层(分类头),现在其它层还包含了每一个残差块中的cbam注意力层。
resnet结构解析
先复用下数据预处理+定义cbam的代码,然后看下resnet内部的结构是什么,这决定我们如何插入模块
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 定义通道注意力
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention #这个运算是pytorch的广播机制
## 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)
pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)
attention = self.conv(pool_out) # 卷积提取空间特征
return x * self.sigmoid(attention) # 特征与空间权重相乘
## CBAM模块
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 数据预处理(与原代码一致)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)使用设备: cuda
Files already downloaded and verified先通过预训练resnet18来查看模型结构
import torch
import torchvision.models as models
from torchinfo import summary #之前的内容说了,推荐用他来可视化模型结构,信息最全
# 加载 ResNet18(预训练)
model = models.resnet18(pretrained=True)
model.eval()
# 输出模型结构和参数概要
summary(model, input_size=(1, 3, 224, 224))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet [1, 1000] --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
==========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================经典的 ResNet-18 模型可以将其看作一个处理流水线,图像数据从一端进去,分类结果从另一端出来。整个过程可以分为三个主要部分: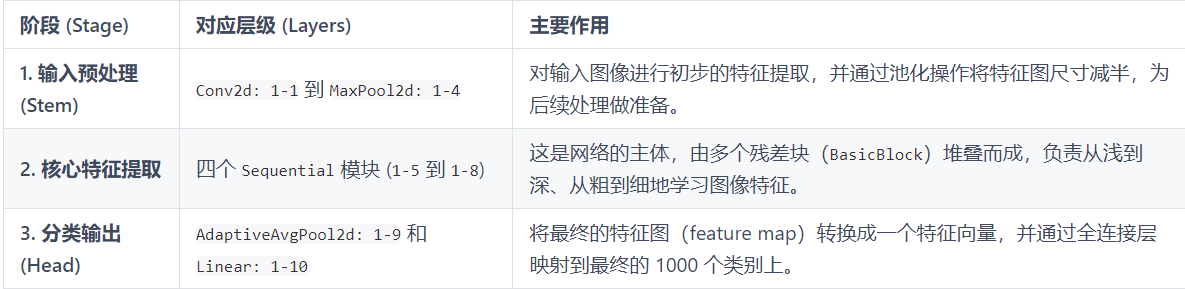 假设输入图像尺寸为
假设输入图像尺寸为 [1, 3, 224, 224] (Batch, Channels, Height, Width),具体shape变化如下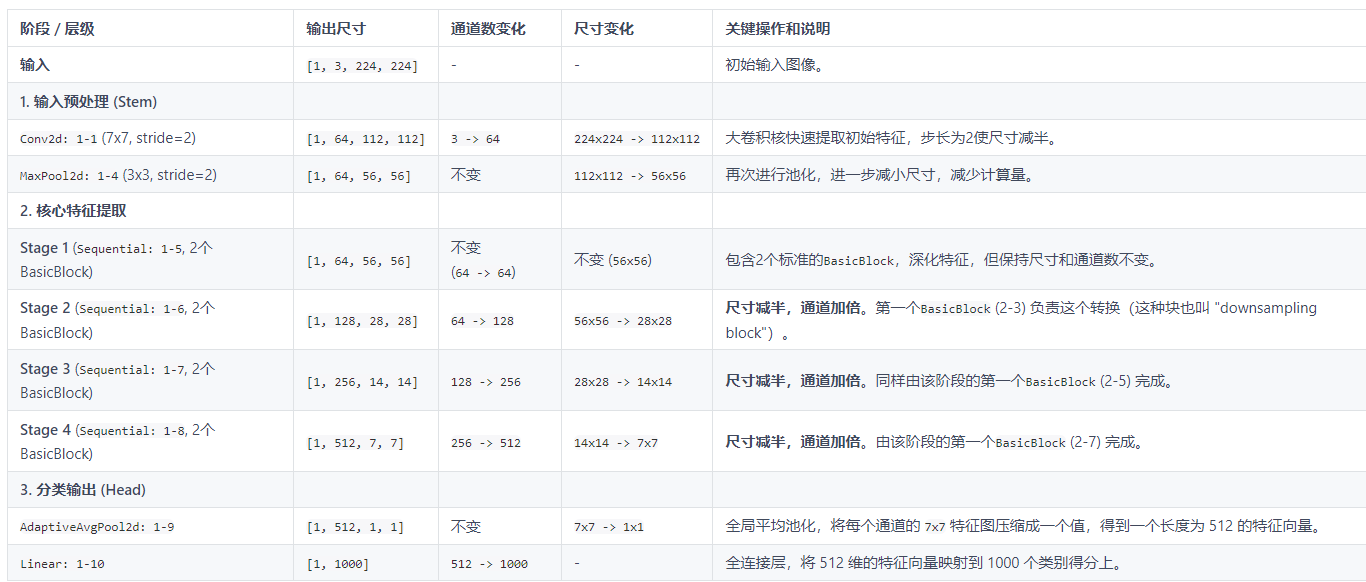
这里我们先介绍下basic block,他是残差网络最重要的思想,在 ResNet 出现之前,人们普遍认为神经网络越深,性能就越好。但实践发现,当网络堆叠到一定深度后,再增加层数,模型的准确率反而会下降。这种现象不叫"过拟合"(Overfitting),因为不光是测试集,连训练集上的准确率都在下降。这被称为 "网络退化"(Degradation) 问题。
本质是因为卷积和池化都是在做下采样的过程,越深虽然能够提取越重要的信息,但是很多重要的信息都被丢弃了。它意味着,让一个很深的网络去学习一个简单的恒等变换(即 输出 = 输入)都非常困难。
BasicBlock 的设计者何恺明博士等人提出了一个绝妙的想法:与其让网络层直接学习一个目标映射 H(x),不如让它学习这个映射与输入 x 之间的"差值",即残差(Residual)F(x) = H(x) - x。这样,原始的目标映射就变成了 H(x) = F(x) + x
这个简单的改动为什么如此强大?
-
简化学习目标:想象一个极端情况,如果某一层的最佳状态就是"什么都不做"(即恒等变换 H(x)=x),那么网络只需要让残差部分 F(x) 的输出为 0 即可。让权重趋向于 0 比让一堆非线性层拟合一个恒等变换要容易得多。
-
信息高速公路: + x 这部分操作被称为"快捷连接"(Shortcut Connection)或"跳跃连接"(Skip Connection)。它像一条高速公路,允许输入信息 x 直接"跳"到更深的层,避免了在层层传递中信息丢失或梯度消失的问题。
一个标准的 BasicBlock 通常包含两条路径
-
主路 (Main Path):这是学习"残差" F(x) 的部分。在 ResNet-18 中,它由两个 3x3 的卷积层构成。 Conv2d: 3-1 (3x3 卷积)-->BatchNorm2d: 3-2 (批归一化)-->ReLU: 3-3 (激活函数)-->Conv2d: 3-4 (3x3 卷积)-->BatchNorm2d: 3-5 (批归一化)
-
捷径 (Shortcut Path):这就是 + x 的部分,直接将输入 x 传递过来。
最后,将主路的输出和捷径的输出按元素相加,再经过一个 ReLU 激活函数,得到整个 BasicBlock 的最终输出。
cbam的放置位置
我们知道,加载预训练模型的时候,需要加载好预训练的模型架构,然后加载预训练的权重。如果修改模型的架构,比如在中间插入某个模块或层,很可能导致他后续预训练的权重失效。那么如何解决这个问题呢?
一种很容易被想到的思想是:cbam可以放置在全连接层之前,这是最简单的想法。保留了原始的信息。可以理解为在模型做出最终分类决策之前,对提取到的最高阶特征图做一次最后的"精炼"和"校准"。
但是这么做有一个弊端,注意力机制只在最后起作用,无法帮助网络在中间层构建出更好的、带有注意力信息的特征。前面的所有卷积块依然是"盲目"地提取特征。这就像一个学生直到做完整张试卷才开始划重点,而不是每做完一道题就总结一次。
但是你要注意,最后的卷积形式是 卷积--激活--池化--全连接,如果你放置前全连接前的话,cbam中的空间注意力会完全失效,因为此时空间维度不存在了,失去了寻找空间相关性的能力。只留下通道注意力仍然在作用。
实际上,被公认为正确的做法是,在每一个残差块的输出上应用CBAM注意力。你可能会想,这样不是会影响后续的输出,尤其最开始注意力权重交叉的话,很可能导致后续预训练层的权重没有价值了。
实际,CBAM模块自身的结构------初始状态接近"直通",这是最核心的技术原因导致可以采用这个结构。CBAM模块的最终操作是:return x * self.sigmoid(attention)。这里的 x 是原始特征;attention 是学到的注意力图。
- 初始状态分析:在一个模块被随机初始化(还未开始训练)时,其内部的卷积层和全连接层的权重都非常小,接近于0。因此,计算出的 attention 图的值也都会非常接近0。
- Sigmoid函数的特性:当输入为0时,sigmoid(0) 的输出是 0.5。这意味着在训练刚开始的第一步,CBAM模块的操作近似于 x * 0.5。它并没有用一个完全随机的、混乱的特征图去替换原始特征 x。它只是将原始特征 x 按比例缩小了一半。
缩小0.5只是对特征数值尺度的缩放,它完整地保留了原始特征图中的空间结构和相对关系。下游的预训练层接收到的不再是"垃圾",而是一个信号稍弱但结构完好的原始特征。这为后续的学习提供了一个非常稳定的起点。
如果CBAM无用:网络可以通过学习,让 attention 图的值都趋近于一个常数,相当于一个固定的缩放。在更理想的情况下,如果能让 attention 图的值都趋近于 sigmoid 函数的反函数中对应输出为1的值,那么CBAM就近似于一个"直通车"(x * 1 = x),网络可以选择"忽略"它。
如果CBAM有用:网络会迅速学会调整权重,让 attention 图中重要的地方值接近1,不重要的地方值接近0,从而实现特征的增强。
所以完全可以在不破坏其核心结构的情况下,将CBAM模块无缝地"注入"到预训练的ResNet中。这样做的逻辑是:
-
保留原始结构:原始的残差块负责提取核心特征。
-
增强特征:紧随其后的CBAM模块对这些提取出的特征进行"精炼",告诉模型应该"关注什么"(what - 通道注意力)和"在哪里关注"(where - 空间注意力)。
-
不破坏预训练权重:原始残差块的预训练权重得以完整保留,我们只是在其后增加了一个新的、需要从头学习的模块。
import torch import torch.nn as nn from torchvision import models # 自定义ResNet18模型,插入CBAM模块 class ResNet18_CBAM(nn.Module): def __init__(self, num_classes=10, pretrained=True, cbam_ratio=16, cbam_kernel=7): super().__init__() # 加载预训练ResNet18 self.backbone = models.resnet18(pretrained=pretrained) # 修改首层卷积以适应32x32输入(CIFAR10) self.backbone.conv1 = nn.Conv2d( in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False ) self.backbone.maxpool = nn.Identity() # 移除原始MaxPool层(因输入尺寸小) # 在每个残差块组后添加CBAM模块 self.cbam_layer1 = CBAM(in_channels=64, ratio=cbam_ratio, kernel_size=cbam_kernel) self.cbam_layer2 = CBAM(in_channels=128, ratio=cbam_ratio, kernel_size=cbam_kernel) self.cbam_layer3 = CBAM(in_channels=256, ratio=cbam_ratio, kernel_size=cbam_kernel) self.cbam_layer4 = CBAM(in_channels=512, ratio=cbam_ratio, kernel_size=cbam_kernel) # 修改分类头 self.backbone.fc = nn.Linear(in_features=512, out_features=num_classes) def forward(self, x): # 主干特征提取 x = self.backbone.conv1(x) x = self.backbone.bn1(x) x = self.backbone.relu(x) # [B, 64, 32, 32] # 第一层残差块 + CBAM x = self.backbone.layer1(x) # [B, 64, 32, 32] x = self.cbam_layer1(x) # 第二层残差块 + CBAM x = self.backbone.layer2(x) # [B, 128, 16, 16] x = self.cbam_layer2(x) # 第三层残差块 + CBAM x = self.backbone.layer3(x) # [B, 256, 8, 8] x = self.cbam_layer3(x) # 第四层残差块 + CBAM x = self.backbone.layer4(x) # [B, 512, 4, 4] x = self.cbam_layer4(x) # 全局平均池化 + 分类 x = self.backbone.avgpool(x) # [B, 512, 1, 1] x = torch.flatten(x, 1) # [B, 512] x = self.backbone.fc(x) # [B, 10] return x # 初始化模型并移至设备 model = ResNet18_CBAM().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)训练策略
差异化学习率
预训练层(ResNet部分):他们是经验丰富的资深专家。他们已经很懂得如何处理特征,不需要大的改动。 新模块(CBAM和分类头):他们是刚入职的实习生,一张白纸,需要快速学习。 你的训练策略(优化器)就像是CEO,你会这样分配任务:
给实习生(新模块) 设置一个较高的学习率(比如1e-3),让他们快速试错,快速成长。 给专家(预训练层) 设置一个极低的学习率(比如1e-5),告诉他们:"你们基本保持现状,只需要根据实习生的表现做一些微小的调整即可。"
这里我们介绍一种比较适合这里的预训练策略:
-
阶段 1(epoch 1-5): 仅解冻分类头(fc)和所有 CBAM 模块,冻结 ResNet18 的主干卷积层(layer1-4)。 目标:先让模型通过预训练特征学习新任务的分类边界,同时微调注意力模块。 学习率:1e-3(较高学习率加速分类头收敛)。 阶段 2(epoch 6-20): 解冻高层卷积层(layer3、layer4)+ 分类头 + CBAM,冻结低层卷积层(layer1、layer2)。 目标:释放高层语义特征(如 "物体类别" 相关层),适应新任务的抽象表示。 学习率:1e-4(降低学习率,避免破坏预训练权重)。 阶段 3(epoch 21-50): 解冻所有层(包括低层卷积层 layer1、layer2),端到端微调。 目标:让底层特征(如边缘、纹理)与新任务对齐,提升特征表达能力。 学习率:1e-5(最小学习率,缓慢调整全局参数)。
-
CBAM 模块集成 在每个残差块组(layer1-4)输出后添加 CBAM,确保注意力机制作用于各阶段特征图,且不影响残差块内部的跳连接。 CBAM 参数默认使用ratio=16和kernel_size=7,可根据计算资源调整(如减小ratio以降低参数量)。
-
学习率与优化器 使用Adam优化器,分阶段手动调整学习率(也可配合自动调度器如CosineAnnealingLR)。 每次解冻新层时,学习率降低一个数量级,避免梯度冲击预训练权重。 预期效果与监控 阶段 1:测试准确率应逐步提升至 20%-40%(摆脱随机猜测),损失开始下降。 阶段 2:准确率加速提升(利用高层特征),可能达到 60%-80%。 阶段 3:准确率缓慢提升并收敛(底层特征微调),最终可能超过 85%(取决于 CIFAR10 的基线表现)。 监控重点: 若阶段 1 准确率仍为 9%,检查数据预处理或标签是否正确。 若阶段 2 后准确率停滞,尝试增加正则化(如在 CBAM 后添加 Dropout)或调整 CBAM 参数。
-
在训练这里,我们采用2种训练策略
差异化学习率
把我们的模型想象成一个公司团队来执行新项目 (CIFAR-10 分类任务):
-
预训练层 (ResNet 部分) :他们是经验丰富的资深专家。他们已经很懂得如何处理通用图像特征,不需要大的改动。
-
新模块 (CBAM 和分类头) :他们是刚入职的实习生,对新任务一无所知,需要快速学习和试错。
-
作为 CEO,我们的训练策略是:
-
给 实习生 设置一个较高的学习率 (例如
1e-3),让他们快速成长。 -
给 专家 设置一个极低的学习率 (例如
1e-5),告诉他们:"保持现状,根据实习生的表现稍作微调即可。"
#### 三阶段式解冻与微调 (Progressive Unfreezing)
**1. 阶段一 (Epoch 1-5): 预热"实习生"**-
解冻部分 : 仅解冻分类头 (
fc) 和所有CBAM模块。 -
冻结部分 : 冻结 ResNet18 的所有主干卷积层 (
conv1,bn1,layer1至layer4)。 -
目标: 先利用强大的预训练特征,让模型快速学习新任务的分类边界,同时让注意力模块找到初步的关注点。
-
学习率 :
1e-3(使用较高学习率加速收敛)。 -
2. 阶段二 (Epoch 6-20): 唤醒"高层专家"
-
解冻部分 : 在上一阶段的基础上,额外解冻高层语义相关的卷积层 (
layer3,layer4)。 -
冻结部分 : 底层特征提取层 (
conv1,bn1,layer1,layer2) 仍然冻结。 -
目标: 释放模型的高层特征提取能力,使其适应新任务的抽象概念 (例如"鸟的轮廓"比"一条边"更抽象)。
-
学习率 :
1e-4(降低学习率,避免新解冻的层因梯度过大而破坏其宝贵的预训练权重)。 -
3. 阶段三 (Epoch 21-50): 全员协同微调
-
解冻部分: 解冻模型的所有层,进行端到端微调。
-
冻结部分: 无。
-
目标: 让模型的底层特征 (如边缘、纹理) 也与新任务进行对齐,做最后的精细化调整,提升整体性能。
-
学习率 :
1e-5(使用最低的学习率,在整个模型上缓慢、稳定地进行全局优化)。 -
在深度神经网络中,我们通常这样描述信息流:
-
靠近输入图像的层,称为"底层 "或"浅层"。
-
所以,"解冻高层卷积" 指的就是解冻
layer3和layer4这两组残差块。为了更直观,我们可以把ResNet18的结构想象成一个处理流水线:
输入图像->[预处理层 conv1, bn1, relu]->[layer1]->[layer2]->[layer3]->[layer4]->[分类头 avgpool, fc]->输出结果ResNet18有 4 组 核心的残差块,即
layer1,layer2,layer3,layer4。每一组layer内部又包含2个BasicBlock(每个BasicBlock包含2个卷积层)。在阶段2,我们解冻的是
layer3和layer4这两组。同时,CBAM模块和fc层保持解冻状态。而layer1和layer2以及最开始的conv1则继续保持冻结。为什么解冻后面(高层)而不解冻前面(底层)?
这是整个迁移学习和微调策略的精髓所在,核心原因在于不同层级的卷积层学习到的特征类型是不同的。
我们可以用一个生动的比喻来理解:把神经网络学习的过程看作一位画家画画。
底层网络 (layer1, layer2) ------ 学习"笔触和纹理"
-
学习内容 :这些靠近输入的层,学习的是非常通用、基础的视觉元素。就像画家首先要学会如何画出**直线、曲线、点、色彩块、明暗渐变、材质纹理(毛发、金属)**一样。
-
任务相关性 :这些特征是高度可复用的。无论你画的是猫、是汽车、还是房子,构成它们的基本笔触和纹理都是一样的。同理,无论是ImageNet中的图片,还是CIFAR-10中的图片,它们都由这些基础视觉元素构成。
-
微调策略 :因为这些知识非常宝贵且通用,我们不希望轻易改动它 。过早地用少量新数据(CIFAR-10)去训练它们,反而可能破坏("污染")这些已经学得很好的通用知识。所以,在微调初期,我们选择冻结它们。
-
高层网络 (layer3, layer4) ------ 学习"构图和概念"
-
学习内容 :这些靠近输出的层,负责将底层学到的基础元素组合成更复杂、更具语义 的部件或概念。就像画家把线条和色块组合成**"眼睛"、"车轮"、"屋顶",并最终形成"一张猫脸"、"一辆汽车的侧面"**这样的整体概念。
-
任务相关性 :这些组合方式和最终概念与具体任务高度相关。例如,在ImageNet上,模型可能学会了将"圆形"和"网格"组合成"篮球";但在CIFAR-10上,它需要学习将"圆形"和"金属光泽"组合成"汽车轮胎"。这种高层抽象知识需要针对新任务进行调整。
-
微调策略 :因为这部分知识最具有"任务特异性",所以它们是最需要被重新训练和调整 的。解冻
layer3和layer4,就是为了让模型能够利用已经学好的基础特征,去学习如何为我们的新任务(CIFAR-10分类)构建新的、专属的物体概念。 -
总结表格
 因此,"先解冻高层,后解冻底层" 的策略,是一种非常高效且稳健的微调方法,它最大限度地保留了预训练模型的泛化能力,同时又能精确地让模型适应新任务的特定需求。
因此,"先解冻高层,后解冻底层" 的策略,是一种非常高效且稳健的微调方法,它最大限度地保留了预训练模型的泛化能力,同时又能精确地让模型适应新任务的特定需求。import time # ====================================================================== # 4. 结合了分阶段策略和详细打印的训练函数 # ====================================================================== def set_trainable_layers(model, trainable_parts): print(f"\n---> 解冻以下部分并设为可训练: {trainable_parts}") for name, param in model.named_parameters(): param.requires_grad = False for part in trainable_parts: if part in name: param.requires_grad = True break def train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs): optimizer = None # 初始化历史记录列表,与你的要求一致 all_iter_losses, iter_indices = [], [] train_acc_history, test_acc_history = [], [] train_loss_history, test_loss_history = [], [] for epoch in range(1, epochs + 1): epoch_start_time = time.time() # --- 动态调整学习率和冻结层 --- if epoch == 1: print("\n" + "="*50 + "\n🚀 **阶段 1:训练注意力模块和分类头**\n" + "="*50) set_trainable_layers(model, ["cbam", "backbone.fc"]) optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3) elif epoch == 6: print("\n" + "="*50 + "\n✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)**\n" + "="*50) set_trainable_layers(model, ["cbam", "backbone.fc", "backbone.layer3", "backbone.layer4"]) optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-4) elif epoch == 21: print("\n" + "="*50 + "\n🛰️ **阶段 3:解冻所有层,进行全局微调**\n" + "="*50) for param in model.parameters(): param.requires_grad = True optimizer = optim.Adam(model.parameters(), lr=1e-5) # --- 训练循环 --- model.train() running_loss, correct, total = 0.0, 0, 0 for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step() # 记录每个iteration的损失 iter_loss = loss.item() all_iter_losses.append(iter_loss) iter_indices.append((epoch - 1) * len(train_loader) + batch_idx + 1) running_loss += iter_loss _, predicted = output.max(1) total += target.size(0) correct += predicted.eq(target).sum().item() # 按你的要求,每100个batch打印一次 if (batch_idx + 1) % 100 == 0: print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} ' f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}') epoch_train_loss = running_loss / len(train_loader) epoch_train_acc = 100. * correct / total train_loss_history.append(epoch_train_loss) train_acc_history.append(epoch_train_acc) # --- 测试循环 --- model.eval() test_loss, correct_test, total_test = 0, 0, 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += criterion(output, target).item() _, predicted = output.max(1) total_test += target.size(0) correct_test += predicted.eq(target).sum().item() epoch_test_loss = test_loss / len(test_loader) epoch_test_acc = 100. * correct_test / total_test test_loss_history.append(epoch_test_loss) test_acc_history.append(epoch_test_acc) # 打印每个epoch的最终结果 print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%') # 训练结束后调用绘图函数 print("\n训练完成! 开始绘制结果图表...") plot_iter_losses(all_iter_losses, iter_indices) plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history) # 返回最终的测试准确率 return epoch_test_acc # ====================================================================== # 5. 绘图函数定义 # ====================================================================== def plot_iter_losses(losses, indices): plt.figure(figsize=(10, 4)) plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss') plt.xlabel('Iteration(Batch序号)') plt.ylabel('损失值') plt.title('每个 Iteration 的训练损失') plt.legend() plt.grid(True) plt.tight_layout() plt.show() def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss): epochs = range(1, len(train_acc) + 1) plt.figure(figsize=(12, 4)) plt.subplot(1, 2, 1) plt.plot(epochs, train_acc, 'b-', label='训练准确率') plt.plot(epochs, test_acc, 'r-', label='测试准确率') plt.xlabel('Epoch') plt.ylabel('准确率 (%)') plt.title('训练和测试准确率') plt.legend(); plt.grid(True) plt.subplot(1, 2, 2) plt.plot(epochs, train_loss, 'b-', label='训练损失') plt.plot(epochs, test_loss, 'r-', label='测试损失') plt.xlabel('Epoch') plt.ylabel('损失值') plt.title('训练和测试损失') plt.legend(); plt.grid(True) plt.tight_layout() plt.show() # ====================================================================== # 6. 执行训练 # ====================================================================== model = ResNet18_CBAM().to(device) criterion = nn.CrossEntropyLoss() epochs = 50 print("开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练...") final_accuracy = train_staged_finetuning(model, criterion, train_loader, test_loader, device, epochs) print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%") # torch.save(model.state_dict(), 'resnet18_cbam_finetuned.pth') # print("模型已保存为: resnet18_cbam_finetuned.pth") 开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练... ================================================== 🚀 **阶段 1:训练注意力模块和分类头** ================================================== ---> 解冻以下部分并设为可训练: ['cbam', 'backbone.fc'] Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.7485 | 累计平均损失: 2.0810 Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.6740 | 累计平均损失: 1.9501 Epoch: 1/50 | Batch: 300/782 | 单Batch损失: 1.9060 | 累计平均损失: 1.8818 Epoch: 1/50 | Batch: 400/782 | 单Batch损失: 1.7339 | 累计平均损失: 1.8351 Epoch: 1/50 | Batch: 500/782 | 单Batch损失: 1.4724 | 累计平均损失: 1.8033 Epoch: 1/50 | Batch: 600/782 | 单Batch损失: 1.5032 | 累计平均损失: 1.7749 Epoch: 1/50 | Batch: 700/782 | 单Batch损失: 1.4728 | 累计平均损失: 1.7500 Epoch 1/50 完成 | 耗时: 34.61s | 训练准确率: 37.31% | 测试准确率: 47.48% Epoch: 2/50 | Batch: 100/782 | 单Batch损失: 1.7628 | 累计平均损失: 1.5714 Epoch: 2/50 | Batch: 200/782 | 单Batch损失: 1.9257 | 累计平均损失: 1.5662 Epoch: 2/50 | Batch: 300/782 | 单Batch损失: 1.5004 | 累计平均损失: 1.5616 Epoch: 2/50 | Batch: 400/782 | 单Batch损失: 1.4699 | 累计平均损失: 1.5525 Epoch: 2/50 | Batch: 500/782 | 单Batch损失: 1.4514 | 累计平均损失: 1.5514 Epoch: 2/50 | Batch: 600/782 | 单Batch损失: 1.3356 | 累计平均损失: 1.5455 Epoch: 2/50 | Batch: 700/782 | 单Batch损失: 1.5402 | 累计平均损失: 1.5433 Epoch 2/50 完成 | 耗时: 34.17s | 训练准确率: 45.00% | 测试准确率: 49.78% Epoch: 3/50 | Batch: 100/782 | 单Batch损失: 1.5248 | 累计平均损失: 1.4952 Epoch: 3/50 | Batch: 200/782 | 单Batch损失: 1.3679 | 累计平均损失: 1.5002 Epoch: 3/50 | Batch: 300/782 | 单Batch损失: 1.5566 | 累计平均损失: 1.4931 Epoch: 3/50 | Batch: 400/782 | 单Batch损失: 1.3878 | 累计平均损失: 1.4883 Epoch: 3/50 | Batch: 500/782 | 单Batch损失: 1.4720 | 累计平均损失: 1.4824 Epoch: 3/50 | Batch: 600/782 | 单Batch损失: 1.2727 | 累计平均损失: 1.4808 Epoch: 3/50 | Batch: 700/782 | 单Batch损失: 1.5683 | 累计平均损失: 1.4790 Epoch 3/50 完成 | 耗时: 33.76s | 训练准确率: 47.11% | 测试准确率: 53.26% Epoch: 4/50 | Batch: 100/782 | 单Batch损失: 1.6395 | 累计平均损失: 1.4641 Epoch: 4/50 | Batch: 200/782 | 单Batch损失: 1.4799 | 累计平均损失: 1.4411 Epoch: 4/50 | Batch: 300/782 | 单Batch损失: 1.8871 | 累计平均损失: 1.4465 Epoch: 4/50 | Batch: 400/782 | 单Batch损失: 1.6204 | 累计平均损失: 1.4413 Epoch: 4/50 | Batch: 500/782 | 单Batch损失: 1.4945 | 累计平均损失: 1.4390 Epoch: 4/50 | Batch: 600/782 | 单Batch损失: 1.5670 | 累计平均损失: 1.4385 Epoch: 4/50 | Batch: 700/782 | 单Batch损失: 1.5015 | 累计平均损失: 1.4388 Epoch 4/50 完成 | 耗时: 33.73s | 训练准确率: 48.73% | 测试准确率: 54.52% Epoch: 5/50 | Batch: 100/782 | 单Batch损失: 1.3727 | 累计平均损失: 1.4345 Epoch: 5/50 | Batch: 200/782 | 单Batch损失: 1.4323 | 累计平均损失: 1.4247 Epoch: 5/50 | Batch: 300/782 | 单Batch损失: 1.3007 | 累计平均损失: 1.4216 Epoch: 5/50 | Batch: 400/782 | 单Batch损失: 1.4333 | 累计平均损失: 1.4169 Epoch: 5/50 | Batch: 500/782 | 单Batch损失: 1.5552 | 累计平均损失: 1.4156 Epoch: 5/50 | Batch: 600/782 | 单Batch损失: 1.3340 | 累计平均损失: 1.4127 Epoch: 5/50 | Batch: 700/782 | 单Batch损失: 1.5470 | 累计平均损失: 1.4127 Epoch 5/50 完成 | 耗时: 34.30s | 训练准确率: 49.86% | 测试准确率: 54.98% ================================================== ✈️ **阶段 2:解冻高层卷积层 (layer3, layer4)** ================================================== ---> 解冻以下部分并设为可训练: ['cbam', 'backbone.fc', 'backbone.layer3', 'backbone.layer4'] Epoch: 6/50 | Batch: 100/782 | 单Batch损失: 0.9357 | 累计平均损失: 1.3187 Epoch: 6/50 | Batch: 200/782 | 单Batch损失: 1.1615 | 累计平均损失: 1.2733 Epoch: 6/50 | Batch: 300/782 | 单Batch损失: 1.0210 | 累计平均损失: 1.2362 Epoch: 6/50 | Batch: 400/782 | 单Batch损失: 1.0903 | 累计平均损失: 1.1955 Epoch: 6/50 | Batch: 500/782 | 单Batch损失: 1.0774 | 累计平均损失: 1.1670 Epoch: 6/50 | Batch: 600/782 | 单Batch损失: 1.0801 | 累计平均损失: 1.1424 Epoch: 6/50 | Batch: 700/782 | 单Batch损失: 0.8669 | 累计平均损失: 1.1204 Epoch 6/50 完成 | 耗时: 39.74s | 训练准确率: 61.34% | 测试准确率: 71.71% Epoch: 7/50 | Batch: 100/782 | 单Batch损失: 0.9683 | 累计平均损失: 0.9085 Epoch: 7/50 | Batch: 200/782 | 单Batch损失: 0.8463 | 累计平均损失: 0.9039 Epoch: 7/50 | Batch: 300/782 | 单Batch损失: 0.9273 | 累计平均损失: 0.8993 Epoch: 7/50 | Batch: 400/782 | 单Batch损失: 0.7971 | 累计平均损失: 0.8936 Epoch: 7/50 | Batch: 500/782 | 单Batch损失: 0.8922 | 累计平均损失: 0.8871 Epoch: 7/50 | Batch: 600/782 | 单Batch损失: 0.9347 | 累计平均损失: 0.8812 Epoch: 7/50 | Batch: 700/782 | 单Batch损失: 0.9257 | 累计平均损失: 0.8737 Epoch 7/50 完成 | 耗时: 38.53s | 训练准确率: 69.63% | 测试准确率: 76.12% Epoch: 8/50 | Batch: 100/782 | 单Batch损失: 0.7948 | 累计平均损失: 0.7646 Epoch: 8/50 | Batch: 200/782 | 单Batch损失: 0.9495 | 累计平均损失: 0.7734 Epoch: 8/50 | Batch: 300/782 | 单Batch损失: 0.8315 | 累计平均损失: 0.7782 Epoch: 8/50 | Batch: 400/782 | 单Batch损失: 0.9908 | 累计平均损失: 0.7694 Epoch: 8/50 | Batch: 500/782 | 单Batch损失: 0.7027 | 累计平均损失: 0.7675 Epoch: 8/50 | Batch: 600/782 | 单Batch损失: 0.8308 | 累计平均损失: 0.7613 Epoch: 8/50 | Batch: 700/782 | 单Batch损失: 0.6263 | 累计平均损失: 0.7589 Epoch 8/50 完成 | 耗时: 38.28s | 训练准确率: 73.49% | 测试准确率: 79.02% Epoch: 9/50 | Batch: 100/782 | 单Batch损失: 0.7367 | 累计平均损失: 0.6974 Epoch: 9/50 | Batch: 200/782 | 单Batch损失: 0.6866 | 累计平均损失: 0.6948 Epoch: 9/50 | Batch: 300/782 | 单Batch损失: 0.6135 | 累计平均损失: 0.6950 Epoch: 9/50 | Batch: 400/782 | 单Batch损失: 0.6402 | 累计平均损失: 0.6934 Epoch: 9/50 | Batch: 500/782 | 单Batch损失: 0.7229 | 累计平均损失: 0.6906 Epoch: 9/50 | Batch: 600/782 | 单Batch损失: 0.7312 | 累计平均损失: 0.6886 Epoch: 9/50 | Batch: 700/782 | 单Batch损失: 0.7411 | 累计平均损失: 0.6887 Epoch 9/50 完成 | 耗时: 38.31s | 训练准确率: 75.77% | 测试准确率: 80.50% Epoch: 10/50 | Batch: 100/782 | 单Batch损失: 0.5954 | 累计平均损失: 0.6497 Epoch: 10/50 | Batch: 200/782 | 单Batch损失: 0.8176 | 累计平均损失: 0.6408 Epoch: 10/50 | Batch: 300/782 | 单Batch损失: 0.6548 | 累计平均损失: 0.6400 Epoch: 10/50 | Batch: 400/782 | 单Batch损失: 0.8509 | 累计平均损失: 0.6427 Epoch: 10/50 | Batch: 500/782 | 单Batch损失: 0.4540 | 累计平均损失: 0.6384 Epoch: 10/50 | Batch: 600/782 | 单Batch损失: 0.7101 | 累计平均损失: 0.6378 Epoch: 10/50 | Batch: 700/782 | 单Batch损失: 0.9033 | 累计平均损失: 0.6382 Epoch 10/50 完成 | 耗时: 38.01s | 训练准确率: 77.85% | 测试准确率: 82.01% Epoch: 11/50 | Batch: 100/782 | 单Batch损失: 0.5891 | 累计平均损失: 0.5997 Epoch: 11/50 | Batch: 200/782 | 单Batch损失: 0.5143 | 累计平均损失: 0.5899 Epoch: 11/50 | Batch: 300/782 | 单Batch损失: 0.6023 | 累计平均损失: 0.5968 Epoch: 11/50 | Batch: 400/782 | 单Batch损失: 0.7850 | 累计平均损失: 0.5965 Epoch: 11/50 | Batch: 500/782 | 单Batch损失: 0.5071 | 累计平均损失: 0.5975 Epoch: 11/50 | Batch: 600/782 | 单Batch损失: 0.7549 | 累计平均损失: 0.5962 Epoch: 11/50 | Batch: 700/782 | 单Batch损失: 0.6783 | 累计平均损失: 0.5990 Epoch 11/50 完成 | 耗时: 38.33s | 训练准确率: 79.08% | 测试准确率: 82.30% Epoch: 12/50 | Batch: 100/782 | 单Batch损失: 0.7179 | 累计平均损失: 0.5464 Epoch: 12/50 | Batch: 200/782 | 单Batch损失: 0.5231 | 累计平均损失: 0.5545 Epoch: 12/50 | Batch: 300/782 | 单Batch损失: 0.5699 | 累计平均损失: 0.5565 Epoch: 12/50 | Batch: 400/782 | 单Batch损失: 0.6491 | 累计平均损失: 0.5634 Epoch: 12/50 | Batch: 500/782 | 单Batch损失: 0.6913 | 累计平均损失: 0.5609 Epoch: 12/50 | Batch: 600/782 | 单Batch损失: 0.4590 | 累计平均损失: 0.5624 Epoch: 12/50 | Batch: 700/782 | 单Batch损失: 0.6569 | 累计平均损失: 0.5604 Epoch 12/50 完成 | 耗时: 39.76s | 训练准确率: 80.36% | 测试准确率: 83.65% Epoch: 13/50 | Batch: 100/782 | 单Batch损失: 0.6940 | 累计平均损失: 0.5201 Epoch: 13/50 | Batch: 200/782 | 单Batch损失: 0.4849 | 累计平均损失: 0.5252 Epoch: 13/50 | Batch: 300/782 | 单Batch损失: 0.6628 | 累计平均损失: 0.5222 Epoch: 13/50 | Batch: 400/782 | 单Batch损失: 0.3912 | 累计平均损失: 0.5183 Epoch: 13/50 | Batch: 500/782 | 单Batch损失: 0.5542 | 累计平均损失: 0.5212 Epoch: 13/50 | Batch: 600/782 | 单Batch损失: 0.5250 | 累计平均损失: 0.5255 Epoch: 13/50 | Batch: 700/782 | 单Batch损失: 0.5008 | 累计平均损失: 0.5268 Epoch 13/50 完成 | 耗时: 38.92s | 训练准确率: 81.54% | 测试准确率: 83.06% Epoch: 14/50 | Batch: 100/782 | 单Batch损失: 0.4900 | 累计平均损失: 0.5081 Epoch: 14/50 | Batch: 200/782 | 单Batch损失: 0.2449 | 累计平均损失: 0.5015 Epoch: 14/50 | Batch: 300/782 | 单Batch损失: 0.5278 | 累计平均损失: 0.5077 Epoch: 14/50 | Batch: 400/782 | 单Batch损失: 0.4552 | 累计平均损失: 0.5091 Epoch: 14/50 | Batch: 500/782 | 单Batch损失: 0.5959 | 累计平均损失: 0.5089 Epoch: 14/50 | Batch: 600/782 | 单Batch损失: 0.5395 | 累计平均损失: 0.5061 Epoch: 14/50 | Batch: 700/782 | 单Batch损失: 0.3625 | 累计平均损失: 0.5046 Epoch 14/50 完成 | 耗时: 38.74s | 训练准确率: 82.38% | 测试准确率: 84.87% Epoch: 15/50 | Batch: 100/782 | 单Batch损失: 0.4743 | 累计平均损失: 0.4653 Epoch: 15/50 | Batch: 200/782 | 单Batch损失: 0.5508 | 累计平均损失: 0.4706 Epoch: 15/50 | Batch: 300/782 | 单Batch损失: 0.4525 | 累计平均损失: 0.4768 Epoch: 15/50 | Batch: 400/782 | 单Batch损失: 0.3632 | 累计平均损失: 0.4771 Epoch: 15/50 | Batch: 500/782 | 单Batch损失: 0.4805 | 累计平均损失: 0.4752 Epoch: 15/50 | Batch: 600/782 | 单Batch损失: 0.3743 | 累计平均损失: 0.4752 Epoch: 15/50 | Batch: 700/782 | 单Batch损失: 0.4114 | 累计平均损失: 0.4780 Epoch 15/50 完成 | 耗时: 38.82s | 训练准确率: 83.15% | 测试准确率: 84.70% Epoch: 16/50 | Batch: 100/782 | 单Batch损失: 0.5127 | 累计平均损失: 0.4535 Epoch: 16/50 | Batch: 200/782 | 单Batch损失: 0.4509 | 累计平均损失: 0.4563 Epoch: 16/50 | Batch: 300/782 | 单Batch损失: 0.5747 | 累计平均损失: 0.4581 Epoch: 16/50 | Batch: 400/782 | 单Batch损失: 0.4282 | 累计平均损失: 0.4567 Epoch: 16/50 | Batch: 500/782 | 单Batch损失: 0.4157 | 累计平均损失: 0.4546 Epoch: 16/50 | Batch: 600/782 | 单Batch损失: 0.4103 | 累计平均损失: 0.4545 Epoch: 16/50 | Batch: 700/782 | 单Batch损失: 0.4214 | 累计平均损失: 0.4552 Epoch 16/50 完成 | 耗时: 38.26s | 训练准确率: 84.01% | 测试准确率: 85.25% Epoch: 17/50 | Batch: 100/782 | 单Batch损失: 0.3618 | 累计平均损失: 0.4283 Epoch: 17/50 | Batch: 200/782 | 单Batch损失: 0.2550 | 累计平均损失: 0.4222 Epoch: 17/50 | Batch: 300/782 | 单Batch损失: 0.4324 | 累计平均损失: 0.4275 Epoch: 17/50 | Batch: 400/782 | 单Batch损失: 0.1891 | 累计平均损失: 0.4301 Epoch: 17/50 | Batch: 500/782 | 单Batch损失: 0.3567 | 累计平均损失: 0.4339 Epoch: 17/50 | Batch: 600/782 | 单Batch损失: 0.3672 | 累计平均损失: 0.4344 Epoch: 17/50 | Batch: 700/782 | 单Batch损失: 0.3693 | 累计平均损失: 0.4373 Epoch 17/50 完成 | 耗时: 38.21s | 训练准确率: 84.50% | 测试准确率: 85.57% Epoch: 18/50 | Batch: 100/782 | 单Batch损失: 0.2888 | 累计平均损失: 0.4294 Epoch: 18/50 | Batch: 200/782 | 单Batch损失: 0.4332 | 累计平均损失: 0.4249 Epoch: 18/50 | Batch: 300/782 | 单Batch损失: 0.4769 | 累计平均损失: 0.4212 Epoch: 18/50 | Batch: 400/782 | 单Batch损失: 0.4411 | 累计平均损失: 0.4228 Epoch: 18/50 | Batch: 500/782 | 单Batch损失: 0.3433 | 累计平均损失: 0.4190 Epoch: 18/50 | Batch: 600/782 | 单Batch损失: 0.3476 | 累计平均损失: 0.4196 Epoch: 18/50 | Batch: 700/782 | 单Batch损失: 0.5196 | 累计平均损失: 0.4220 Epoch 18/50 完成 | 耗时: 38.76s | 训练准确率: 85.19% | 测试准确率: 85.74% Epoch: 19/50 | Batch: 100/782 | 单Batch损失: 0.4203 | 累计平均损失: 0.4041 Epoch: 19/50 | Batch: 200/782 | 单Batch损失: 0.3616 | 累计平均损失: 0.4021 Epoch: 19/50 | Batch: 300/782 | 单Batch损失: 0.5229 | 累计平均损失: 0.4017 Epoch: 19/50 | Batch: 400/782 | 单Batch损失: 0.3150 | 累计平均损失: 0.3999 Epoch: 19/50 | Batch: 500/782 | 单Batch损失: 0.4656 | 累计平均损失: 0.3961 Epoch: 19/50 | Batch: 600/782 | 单Batch损失: 0.4970 | 累计平均损失: 0.3980 Epoch: 19/50 | Batch: 700/782 | 单Batch损失: 0.4652 | 累计平均损失: 0.3989 Epoch 19/50 完成 | 耗时: 41.85s | 训练准确率: 86.03% | 测试准确率: 85.44% Epoch: 20/50 | Batch: 100/782 | 单Batch损失: 0.4339 | 累计平均损失: 0.3789 Epoch: 20/50 | Batch: 200/782 | 单Batch损失: 0.6232 | 累计平均损失: 0.3755 Epoch: 20/50 | Batch: 300/782 | 单Batch损失: 0.3095 | 累计平均损失: 0.3820 Epoch: 20/50 | Batch: 400/782 | 单Batch损失: 0.2718 | 累计平均损失: 0.3882 Epoch: 20/50 | Batch: 500/782 | 单Batch损失: 0.4242 | 累计平均损失: 0.3861 Epoch: 20/50 | Batch: 600/782 | 单Batch损失: 0.4585 | 累计平均损失: 0.3873 Epoch: 20/50 | Batch: 700/782 | 单Batch损失: 0.4896 | 累计平均损失: 0.3869 Epoch 20/50 完成 | 耗时: 38.81s | 训练准确率: 86.26% | 测试准确率: 85.99% ================================================== 🛰️ **阶段 3:解冻所有层,进行全局微调** ================================================== Epoch: 21/50 | Batch: 100/782 | 单Batch损失: 0.4200 | 累计平均损失: 0.3498 Epoch: 21/50 | Batch: 200/782 | 单Batch损失: 0.2432 | 累计平均损失: 0.3323 Epoch: 21/50 | Batch: 300/782 | 单Batch损失: 0.3133 | 累计平均损失: 0.3310 Epoch: 21/50 | Batch: 400/782 | 单Batch损失: 0.4987 | 累计平均损失: 0.3280 Epoch: 21/50 | Batch: 500/782 | 单Batch损失: 0.1875 | 累计平均损失: 0.3281 Epoch: 21/50 | Batch: 600/782 | 单Batch损失: 0.1709 | 累计平均损失: 0.3234 Epoch: 21/50 | Batch: 700/782 | 单Batch损失: 0.2414 | 累计平均损失: 0.3212 Epoch 21/50 完成 | 耗时: 48.79s | 训练准确率: 88.75% | 测试准确率: 87.58% Epoch: 22/50 | Batch: 100/782 | 单Batch损失: 0.2785 | 累计平均损失: 0.2874 Epoch: 22/50 | Batch: 200/782 | 单Batch损失: 0.3556 | 累计平均损失: 0.2938 Epoch: 22/50 | Batch: 300/782 | 单Batch损失: 0.3327 | 累计平均损失: 0.2930 Epoch: 22/50 | Batch: 400/782 | 单Batch损失: 0.2000 | 累计平均损失: 0.2898 Epoch: 22/50 | Batch: 500/782 | 单Batch损失: 0.1706 | 累计平均损失: 0.2935 Epoch: 22/50 | Batch: 600/782 | 单Batch损失: 0.2644 | 累计平均损失: 0.2929 Epoch: 22/50 | Batch: 700/782 | 单Batch损失: 0.3852 | 累计平均损失: 0.2933 Epoch 22/50 完成 | 耗时: 48.99s | 训练准确率: 89.72% | 测试准确率: 88.06% Epoch: 23/50 | Batch: 100/782 | 单Batch损失: 0.3448 | 累计平均损失: 0.2880 Epoch: 23/50 | Batch: 200/782 | 单Batch损失: 0.3574 | 累计平均损失: 0.2777 Epoch: 23/50 | Batch: 300/782 | 单Batch损失: 0.1636 | 累计平均损失: 0.2787 Epoch: 23/50 | Batch: 400/782 | 单Batch损失: 0.2874 | 累计平均损失: 0.2785 Epoch: 23/50 | Batch: 500/782 | 单Batch损失: 0.3345 | 累计平均损失: 0.2763 Epoch: 23/50 | Batch: 600/782 | 单Batch损失: 0.2607 | 累计平均损失: 0.2753 Epoch: 23/50 | Batch: 700/782 | 单Batch损失: 0.2872 | 累计平均损失: 0.2743 Epoch 23/50 完成 | 耗时: 49.06s | 训练准确率: 90.30% | 测试准确率: 88.10% Epoch: 24/50 | Batch: 100/782 | 单Batch损失: 0.2014 | 累计平均损失: 0.2681 Epoch: 24/50 | Batch: 200/782 | 单Batch损失: 0.4149 | 累计平均损失: 0.2629 Epoch: 24/50 | Batch: 300/782 | 单Batch损失: 0.3364 | 累计平均损失: 0.2594 Epoch: 24/50 | Batch: 400/782 | 单Batch损失: 0.4253 | 累计平均损失: 0.2604 Epoch: 24/50 | Batch: 500/782 | 单Batch损失: 0.3066 | 累计平均损失: 0.2600 Epoch: 24/50 | Batch: 600/782 | 单Batch损失: 0.1681 | 累计平均损失: 0.2593 Epoch: 24/50 | Batch: 700/782 | 单Batch损失: 0.3618 | 累计平均损失: 0.2585 Epoch 24/50 完成 | 耗时: 48.64s | 训练准确率: 90.96% | 测试准确率: 88.31% Epoch: 25/50 | Batch: 100/782 | 单Batch损失: 0.2214 | 累计平均损失: 0.2511 Epoch: 25/50 | Batch: 200/782 | 单Batch损失: 0.2966 | 累计平均损失: 0.2615 Epoch: 25/50 | Batch: 300/782 | 单Batch损失: 0.1594 | 累计平均损失: 0.2570 Epoch: 25/50 | Batch: 400/782 | 单Batch损失: 0.2951 | 累计平均损失: 0.2499 Epoch: 25/50 | Batch: 500/782 | 单Batch损失: 0.1901 | 累计平均损失: 0.2499 Epoch: 25/50 | Batch: 600/782 | 单Batch损失: 0.2421 | 累计平均损失: 0.2502 Epoch: 25/50 | Batch: 700/782 | 单Batch损失: 0.1874 | 累计平均损失: 0.2486 Epoch 25/50 完成 | 耗时: 57.76s | 训练准确率: 91.23% | 测试准确率: 88.42% Epoch: 26/50 | Batch: 100/782 | 单Batch损失: 0.1826 | 累计平均损失: 0.2474 Epoch: 26/50 | Batch: 200/782 | 单Batch损失: 0.1973 | 累计平均损失: 0.2447 Epoch: 26/50 | Batch: 300/782 | 单Batch损失: 0.2452 | 累计平均损失: 0.2410 Epoch: 26/50 | Batch: 400/782 | 单Batch损失: 0.1659 | 累计平均损失: 0.2416 Epoch: 26/50 | Batch: 500/782 | 单Batch损失: 0.2407 | 累计平均损失: 0.2397 Epoch: 26/50 | Batch: 600/782 | 单Batch损失: 0.2094 | 累计平均损失: 0.2429 Epoch: 26/50 | Batch: 700/782 | 单Batch损失: 0.2353 | 累计平均损失: 0.2424 Epoch 26/50 完成 | 耗时: 51.15s | 训练准确率: 91.46% | 测试准确率: 88.71% Epoch: 27/50 | Batch: 100/782 | 单Batch损失: 0.1910 | 累计平均损失: 0.2312 Epoch: 27/50 | Batch: 200/782 | 单Batch损失: 0.3840 | 累计平均损失: 0.2365 Epoch: 27/50 | Batch: 300/782 | 单Batch损失: 0.1632 | 累计平均损失: 0.2367 Epoch: 27/50 | Batch: 400/782 | 单Batch损失: 0.2913 | 累计平均损失: 0.2333 Epoch: 27/50 | Batch: 500/782 | 单Batch损失: 0.3134 | 累计平均损失: 0.2328 Epoch: 27/50 | Batch: 600/782 | 单Batch损失: 0.1631 | 累计平均损失: 0.2342 Epoch: 27/50 | Batch: 700/782 | 单Batch损失: 0.2806 | 累计平均损失: 0.2337 Epoch 27/50 完成 | 耗时: 63.20s | 训练准确率: 91.81% | 测试准确率: 88.69% Epoch: 28/50 | Batch: 100/782 | 单Batch损失: 0.2078 | 累计平均损失: 0.2163 Epoch: 28/50 | Batch: 200/782 | 单Batch损失: 0.1341 | 累计平均损失: 0.2195 Epoch: 28/50 | Batch: 300/782 | 单Batch损失: 0.0757 | 累计平均损失: 0.2200 Epoch: 28/50 | Batch: 400/782 | 单Batch损失: 0.1576 | 累计平均损失: 0.2222 Epoch: 28/50 | Batch: 500/782 | 单Batch损失: 0.2282 | 累计平均损失: 0.2260 Epoch: 28/50 | Batch: 600/782 | 单Batch损失: 0.2603 | 累计平均损失: 0.2237 Epoch: 28/50 | Batch: 700/782 | 单Batch损失: 0.3284 | 累计平均损失: 0.2232 Epoch 28/50 完成 | 耗时: 80.36s | 训练准确率: 92.22% | 测试准确率: 88.81% Epoch: 29/50 | Batch: 100/782 | 单Batch损失: 0.1633 | 累计平均损失: 0.2198 Epoch: 29/50 | Batch: 200/782 | 单Batch损失: 0.1148 | 累计平均损失: 0.2193 Epoch: 29/50 | Batch: 300/782 | 单Batch损失: 0.1129 | 累计平均损失: 0.2186 Epoch: 29/50 | Batch: 400/782 | 单Batch损失: 0.1436 | 累计平均损失: 0.2200 Epoch: 29/50 | Batch: 500/782 | 单Batch损失: 0.3171 | 累计平均损失: 0.2224 Epoch: 29/50 | Batch: 600/782 | 单Batch损失: 0.1653 | 累计平均损失: 0.2221 Epoch: 29/50 | Batch: 700/782 | 单Batch损失: 0.2816 | 累计平均损失: 0.2217 Epoch 29/50 完成 | 耗时: 74.72s | 训练准确率: 92.23% | 测试准确率: 88.78% Epoch: 30/50 | Batch: 100/782 | 单Batch损失: 0.2561 | 累计平均损失: 0.2105 Epoch: 30/50 | Batch: 200/782 | 单Batch损失: 0.0962 | 累计平均损失: 0.2091 Epoch: 30/50 | Batch: 300/782 | 单Batch损失: 0.1850 | 累计平均损失: 0.2069 Epoch: 30/50 | Batch: 400/782 | 单Batch损失: 0.1692 | 累计平均损失: 0.2086 Epoch: 30/50 | Batch: 500/782 | 单Batch损失: 0.2072 | 累计平均损失: 0.2089 Epoch: 30/50 | Batch: 600/782 | 单Batch损失: 0.1508 | 累计平均损失: 0.2110 Epoch: 30/50 | Batch: 700/782 | 单Batch损失: 0.2121 | 累计平均损失: 0.2122 Epoch 30/50 完成 | 耗时: 51.10s | 训练准确率: 92.45% | 测试准确率: 89.09% Epoch: 31/50 | Batch: 100/782 | 单Batch损失: 0.1330 | 累计平均损失: 0.1954 Epoch: 31/50 | Batch: 200/782 | 单Batch损失: 0.2532 | 累计平均损失: 0.2058 Epoch: 31/50 | Batch: 300/782 | 单Batch损失: 0.1695 | 累计平均损失: 0.2046 Epoch: 31/50 | Batch: 400/782 | 单Batch损失: 0.1964 | 累计平均损失: 0.2045 Epoch: 31/50 | Batch: 500/782 | 单Batch损失: 0.0687 | 累计平均损失: 0.2040 Epoch: 31/50 | Batch: 600/782 | 单Batch损失: 0.4410 | 累计平均损失: 0.2047 Epoch: 31/50 | Batch: 700/782 | 单Batch损失: 0.1006 | 累计平均损失: 0.2059 Epoch 31/50 完成 | 耗时: 57.40s | 训练准确率: 92.72% | 测试准确率: 89.32% Epoch: 32/50 | Batch: 100/782 | 单Batch损失: 0.1012 | 累计平均损失: 0.1954 Epoch: 32/50 | Batch: 200/782 | 单Batch损失: 0.2048 | 累计平均损失: 0.1974 Epoch: 32/50 | Batch: 300/782 | 单Batch损失: 0.4336 | 累计平均损失: 0.1986 Epoch: 32/50 | Batch: 400/782 | 单Batch损失: 0.1788 | 累计平均损失: 0.2033 Epoch: 32/50 | Batch: 500/782 | 单Batch损失: 0.1836 | 累计平均损失: 0.2022 Epoch: 32/50 | Batch: 600/782 | 单Batch损失: 0.1269 | 累计平均损失: 0.2021 Epoch: 32/50 | Batch: 700/782 | 单Batch损失: 0.2143 | 累计平均损失: 0.2047 Epoch 32/50 完成 | 耗时: 50.97s | 训练准确率: 92.78% | 测试准确率: 89.22% Epoch: 33/50 | Batch: 100/782 | 单Batch损失: 0.1374 | 累计平均损失: 0.1842 Epoch: 33/50 | Batch: 200/782 | 单Batch损失: 0.0895 | 累计平均损失: 0.1901 Epoch: 33/50 | Batch: 300/782 | 单Batch损失: 0.1727 | 累计平均损失: 0.1937 Epoch: 33/50 | Batch: 400/782 | 单Batch损失: 0.1783 | 累计平均损失: 0.1945 Epoch: 33/50 | Batch: 500/782 | 单Batch损失: 0.1266 | 累计平均损失: 0.1949 Epoch: 33/50 | Batch: 600/782 | 单Batch损失: 0.1565 | 累计平均损失: 0.1944 Epoch: 33/50 | Batch: 700/782 | 单Batch损失: 0.1922 | 累计平均损失: 0.1945 Epoch 33/50 完成 | 耗时: 50.85s | 训练准确率: 93.14% | 测试准确率: 89.33% Epoch: 34/50 | Batch: 100/782 | 单Batch损失: 0.1293 | 累计平均损失: 0.2027 Epoch: 34/50 | Batch: 200/782 | 单Batch损失: 0.1487 | 累计平均损失: 0.1986 Epoch: 34/50 | Batch: 300/782 | 单Batch损失: 0.1553 | 累计平均损失: 0.1969 Epoch: 34/50 | Batch: 400/782 | 单Batch损失: 0.1961 | 累计平均损失: 0.1978 Epoch: 34/50 | Batch: 500/782 | 单Batch损失: 0.1541 | 累计平均损失: 0.1956 Epoch: 34/50 | Batch: 600/782 | 单Batch损失: 0.2765 | 累计平均损失: 0.1940 Epoch: 34/50 | Batch: 700/782 | 单Batch损失: 0.3413 | 累计平均损失: 0.1946 Epoch 34/50 完成 | 耗时: 49.00s | 训练准确率: 93.17% | 测试准确率: 89.47% Epoch: 35/50 | Batch: 100/782 | 单Batch损失: 0.2093 | 累计平均损失: 0.1851 Epoch: 35/50 | Batch: 200/782 | 单Batch损失: 0.1467 | 累计平均损失: 0.1864 Epoch: 35/50 | Batch: 300/782 | 单Batch损失: 0.1454 | 累计平均损失: 0.1834 Epoch: 35/50 | Batch: 400/782 | 单Batch损失: 0.2127 | 累计平均损失: 0.1838 Epoch: 35/50 | Batch: 500/782 | 单Batch损失: 0.2117 | 累计平均损失: 0.1856 Epoch: 35/50 | Batch: 600/782 | 单Batch损失: 0.0858 | 累计平均损失: 0.1846 Epoch: 35/50 | Batch: 700/782 | 单Batch损失: 0.2139 | 累计平均损失: 0.1863 Epoch 35/50 完成 | 耗时: 71.60s | 训练准确率: 93.61% | 测试准确率: 89.61% Epoch: 36/50 | Batch: 100/782 | 单Batch损失: 0.1055 | 累计平均损失: 0.1911 Epoch: 36/50 | Batch: 200/782 | 单Batch损失: 0.2387 | 累计平均损失: 0.1828 Epoch: 36/50 | Batch: 300/782 | 单Batch损失: 0.2092 | 累计平均损失: 0.1828 Epoch: 36/50 | Batch: 400/782 | 单Batch损失: 0.1390 | 累计平均损失: 0.1829 Epoch: 36/50 | Batch: 500/782 | 单Batch损失: 0.1597 | 累计平均损失: 0.1848 Epoch: 36/50 | Batch: 600/782 | 单Batch损失: 0.2191 | 累计平均损失: 0.1844 Epoch: 36/50 | Batch: 700/782 | 单Batch损失: 0.2329 | 累计平均损失: 0.1844 Epoch 36/50 完成 | 耗时: 82.24s | 训练准确率: 93.35% | 测试准确率: 89.55% Epoch: 37/50 | Batch: 100/782 | 单Batch损失: 0.2323 | 累计平均损失: 0.1669 Epoch: 37/50 | Batch: 200/782 | 单Batch损失: 0.3011 | 累计平均损失: 0.1693 Epoch: 37/50 | Batch: 300/782 | 单Batch损失: 0.1559 | 累计平均损失: 0.1764 Epoch: 37/50 | Batch: 400/782 | 单Batch损失: 0.2042 | 累计平均损失: 0.1775 Epoch: 37/50 | Batch: 500/782 | 单Batch损失: 0.2905 | 累计平均损失: 0.1791 Epoch: 37/50 | Batch: 600/782 | 单Batch损失: 0.1836 | 累计平均损失: 0.1795 Epoch: 37/50 | Batch: 700/782 | 单Batch损失: 0.0844 | 累计平均损失: 0.1789 Epoch 37/50 完成 | 耗时: 81.55s | 训练准确率: 93.87% | 测试准确率: 89.33% Epoch: 38/50 | Batch: 100/782 | 单Batch损失: 0.2374 | 累计平均损失: 0.1650 Epoch: 38/50 | Batch: 200/782 | 单Batch损失: 0.2358 | 累计平均损失: 0.1669 Epoch: 38/50 | Batch: 300/782 | 单Batch损失: 0.1836 | 累计平均损失: 0.1724 Epoch: 38/50 | Batch: 400/782 | 单Batch损失: 0.1060 | 累计平均损失: 0.1717 Epoch: 38/50 | Batch: 500/782 | 单Batch损失: 0.1447 | 累计平均损失: 0.1717 Epoch: 38/50 | Batch: 600/782 | 单Batch损失: 0.2479 | 累计平均损失: 0.1750 Epoch: 38/50 | Batch: 700/782 | 单Batch损失: 0.1666 | 累计平均损失: 0.1759 Epoch 38/50 完成 | 耗时: 81.31s | 训练准确率: 93.77% | 测试准确率: 89.64% Epoch: 39/50 | Batch: 100/782 | 单Batch损失: 0.0714 | 累计平均损失: 0.1656 Epoch: 39/50 | Batch: 200/782 | 单Batch损失: 0.2346 | 累计平均损失: 0.1699 Epoch: 39/50 | Batch: 300/782 | 单Batch损失: 0.2008 | 累计平均损失: 0.1710 Epoch: 39/50 | Batch: 400/782 | 单Batch损失: 0.2054 | 累计平均损失: 0.1708 Epoch: 39/50 | Batch: 500/782 | 单Batch损失: 0.1076 | 累计平均损失: 0.1703 Epoch: 39/50 | Batch: 600/782 | 单Batch损失: 0.0607 | 累计平均损失: 0.1686 Epoch: 39/50 | Batch: 700/782 | 单Batch损失: 0.2755 | 累计平均损失: 0.1683 Epoch 39/50 完成 | 耗时: 81.15s | 训练准确率: 93.95% | 测试准确率: 89.67% Epoch: 40/50 | Batch: 100/782 | 单Batch损失: 0.1794 | 累计平均损失: 0.1669 Epoch: 40/50 | Batch: 200/782 | 单Batch损失: 0.0493 | 累计平均损失: 0.1678 Epoch: 40/50 | Batch: 300/782 | 单Batch损失: 0.2379 | 累计平均损失: 0.1690 Epoch: 40/50 | Batch: 400/782 | 单Batch损失: 0.1025 | 累计平均损失: 0.1690 Epoch: 40/50 | Batch: 500/782 | 单Batch损失: 0.1547 | 累计平均损失: 0.1701 Epoch: 40/50 | Batch: 600/782 | 单Batch损失: 0.0876 | 累计平均损失: 0.1703 Epoch: 40/50 | Batch: 700/782 | 单Batch损失: 0.1686 | 累计平均损失: 0.1702 Epoch 40/50 完成 | 耗时: 67.61s | 训练准确率: 94.01% | 测试准确率: 89.84% Epoch: 41/50 | Batch: 100/782 | 单Batch损失: 0.1905 | 累计平均损失: 0.1635 Epoch: 41/50 | Batch: 200/782 | 单Batch损失: 0.1010 | 累计平均损失: 0.1635 Epoch: 41/50 | Batch: 300/782 | 单Batch损失: 0.2289 | 累计平均损失: 0.1663 Epoch: 41/50 | Batch: 400/782 | 单Batch损失: 0.1762 | 累计平均损失: 0.1655 Epoch: 41/50 | Batch: 500/782 | 单Batch损失: 0.1919 | 累计平均损失: 0.1659 Epoch: 41/50 | Batch: 600/782 | 单Batch损失: 0.1375 | 累计平均损失: 0.1659 Epoch: 41/50 | Batch: 700/782 | 单Batch损失: 0.1894 | 累计平均损失: 0.1646 Epoch 41/50 完成 | 耗时: 81.80s | 训练准确率: 94.15% | 测试准确率: 89.82% Epoch: 42/50 | Batch: 100/782 | 单Batch损失: 0.1321 | 累计平均损失: 0.1552 Epoch: 42/50 | Batch: 200/782 | 单Batch损失: 0.1208 | 累计平均损失: 0.1530 Epoch: 42/50 | Batch: 300/782 | 单Batch损失: 0.1458 | 累计平均损失: 0.1543 Epoch: 42/50 | Batch: 400/782 | 单Batch损失: 0.1978 | 累计平均损失: 0.1554 Epoch: 42/50 | Batch: 500/782 | 单Batch损失: 0.1350 | 累计平均损失: 0.1571 Epoch: 42/50 | Batch: 600/782 | 单Batch损失: 0.1054 | 累计平均损失: 0.1584 Epoch: 42/50 | Batch: 700/782 | 单Batch损失: 0.1255 | 累计平均损失: 0.1587 Epoch 42/50 完成 | 耗时: 68.28s | 训练准确率: 94.42% | 测试准确率: 89.68% Epoch: 43/50 | Batch: 100/782 | 单Batch损失: 0.2327 | 累计平均损失: 0.1462 Epoch: 43/50 | Batch: 200/782 | 单Batch损失: 0.2214 | 累计平均损失: 0.1514 Epoch: 43/50 | Batch: 300/782 | 单Batch损失: 0.1359 | 累计平均损失: 0.1488 Epoch: 43/50 | Batch: 400/782 | 单Batch损失: 0.2362 | 累计平均损失: 0.1500 Epoch: 43/50 | Batch: 500/782 | 单Batch损失: 0.1305 | 累计平均损失: 0.1501 Epoch: 43/50 | Batch: 600/782 | 单Batch损失: 0.1552 | 累计平均损失: 0.1528 Epoch: 43/50 | Batch: 700/782 | 单Batch损失: 0.0895 | 累计平均损失: 0.1531 Epoch 43/50 完成 | 耗时: 48.83s | 训练准确率: 94.59% | 测试准确率: 89.91% Epoch: 44/50 | Batch: 100/782 | 单Batch损失: 0.1532 | 累计平均损失: 0.1545 Epoch: 44/50 | Batch: 200/782 | 单Batch损失: 0.2617 | 累计平均损失: 0.1534 Epoch: 44/50 | Batch: 300/782 | 单Batch损失: 0.2021 | 累计平均损失: 0.1534 Epoch: 44/50 | Batch: 400/782 | 单Batch损失: 0.1155 | 累计平均损失: 0.1527 Epoch: 44/50 | Batch: 500/782 | 单Batch损失: 0.0798 | 累计平均损失: 0.1519 Epoch: 44/50 | Batch: 600/782 | 单Batch损失: 0.1413 | 累计平均损失: 0.1532 Epoch: 44/50 | Batch: 700/782 | 单Batch损失: 0.1824 | 累计平均损失: 0.1544 Epoch 44/50 完成 | 耗时: 48.27s | 训练准确率: 94.53% | 测试准确率: 89.98% Epoch: 45/50 | Batch: 100/782 | 单Batch损失: 0.2251 | 累计平均损失: 0.1506 Epoch: 45/50 | Batch: 200/782 | 单Batch损失: 0.1273 | 累计平均损失: 0.1457 Epoch: 45/50 | Batch: 300/782 | 单Batch损失: 0.1685 | 累计平均损失: 0.1443 Epoch: 45/50 | Batch: 400/782 | 单Batch损失: 0.1954 | 累计平均损失: 0.1449 Epoch: 45/50 | Batch: 500/782 | 单Batch损失: 0.0879 | 累计平均损失: 0.1455 Epoch: 45/50 | Batch: 600/782 | 单Batch损失: 0.3393 | 累计平均损失: 0.1445 Epoch: 45/50 | Batch: 700/782 | 单Batch损失: 0.1599 | 累计平均损失: 0.1447 Epoch 45/50 完成 | 耗时: 47.46s | 训练准确率: 94.94% | 测试准确率: 90.15% Epoch: 46/50 | Batch: 100/782 | 单Batch损失: 0.0921 | 累计平均损失: 0.1571 Epoch: 46/50 | Batch: 200/782 | 单Batch损失: 0.0767 | 累计平均损失: 0.1518 Epoch: 46/50 | Batch: 300/782 | 单Batch损失: 0.1400 | 累计平均损失: 0.1521 Epoch: 46/50 | Batch: 400/782 | 单Batch损失: 0.1224 | 累计平均损失: 0.1483 Epoch: 46/50 | Batch: 500/782 | 单Batch损失: 0.1307 | 累计平均损失: 0.1463 Epoch: 46/50 | Batch: 600/782 | 单Batch损失: 0.1079 | 累计平均损失: 0.1465 Epoch: 46/50 | Batch: 700/782 | 单Batch损失: 0.2093 | 累计平均损失: 0.1462 Epoch 46/50 完成 | 耗时: 47.49s | 训练准确率: 94.91% | 测试准确率: 89.90% Epoch: 47/50 | Batch: 100/782 | 单Batch损失: 0.2271 | 累计平均损失: 0.1398 Epoch: 47/50 | Batch: 200/782 | 单Batch损失: 0.0876 | 累计平均损失: 0.1420 Epoch: 47/50 | Batch: 300/782 | 单Batch损失: 0.2563 | 累计平均损失: 0.1465 Epoch: 47/50 | Batch: 400/782 | 单Batch损失: 0.1245 | 累计平均损失: 0.1445 Epoch: 47/50 | Batch: 500/782 | 单Batch损失: 0.1176 | 累计平均损失: 0.1448 Epoch: 47/50 | Batch: 600/782 | 单Batch损失: 0.1681 | 累计平均损失: 0.1447 Epoch: 47/50 | Batch: 700/782 | 单Batch损失: 0.1941 | 累计平均损失: 0.1437 Epoch 47/50 完成 | 耗时: 47.45s | 训练准确率: 95.07% | 测试准确率: 90.03% Epoch: 48/50 | Batch: 100/782 | 单Batch损失: 0.1503 | 累计平均损失: 0.1361 Epoch: 48/50 | Batch: 200/782 | 单Batch损失: 0.0962 | 累计平均损失: 0.1404 Epoch: 48/50 | Batch: 300/782 | 单Batch损失: 0.4808 | 累计平均损失: 0.1447 Epoch: 48/50 | Batch: 400/782 | 单Batch损失: 0.1307 | 累计平均损失: 0.1465 Epoch: 48/50 | Batch: 500/782 | 单Batch损失: 0.0648 | 累计平均损失: 0.1444 Epoch: 48/50 | Batch: 600/782 | 单Batch损失: 0.1002 | 累计平均损失: 0.1438 Epoch: 48/50 | Batch: 700/782 | 单Batch损失: 0.2035 | 累计平均损失: 0.1424 Epoch 48/50 完成 | 耗时: 47.78s | 训练准确率: 94.93% | 测试准确率: 90.27% Epoch: 49/50 | Batch: 100/782 | 单Batch损失: 0.0835 | 累计平均损失: 0.1356 Epoch: 49/50 | Batch: 200/782 | 单Batch损失: 0.0732 | 累计平均损失: 0.1360 Epoch: 49/50 | Batch: 300/782 | 单Batch损失: 0.2437 | 累计平均损失: 0.1371 Epoch: 49/50 | Batch: 400/782 | 单Batch损失: 0.1142 | 累计平均损失: 0.1361 Epoch: 49/50 | Batch: 500/782 | 单Batch损失: 0.0778 | 累计平均损失: 0.1368 Epoch: 49/50 | Batch: 600/782 | 单Batch损失: 0.0833 | 累计平均损失: 0.1368 Epoch: 49/50 | Batch: 700/782 | 单Batch损失: 0.1409 | 累计平均损失: 0.1388 Epoch 49/50 完成 | 耗时: 48.56s | 训练准确率: 95.19% | 测试准确率: 90.02% Epoch: 50/50 | Batch: 100/782 | 单Batch损失: 0.1375 | 累计平均损失: 0.1370 Epoch: 50/50 | Batch: 200/782 | 单Batch损失: 0.0816 | 累计平均损失: 0.1380 Epoch: 50/50 | Batch: 300/782 | 单Batch损失: 0.2015 | 累计平均损失: 0.1382 Epoch: 50/50 | Batch: 400/782 | 单Batch损失: 0.1428 | 累计平均损失: 0.1400 Epoch: 50/50 | Batch: 500/782 | 单Batch损失: 0.1029 | 累计平均损失: 0.1391 Epoch: 50/50 | Batch: 600/782 | 单Batch损失: 0.1645 | 累计平均损失: 0.1391 Epoch: 50/50 | Batch: 700/782 | 单Batch损失: 0.1572 | 累计平均损失: 0.1391 Epoch 50/50 完成 | 耗时: 48.92s | 训练准确率: 95.15% | 测试准确率: 90.15% 训练完成! 开始绘制结果图表...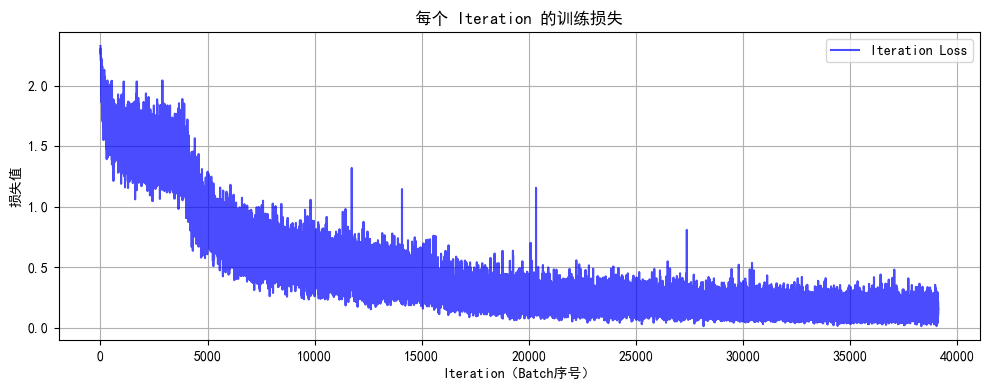
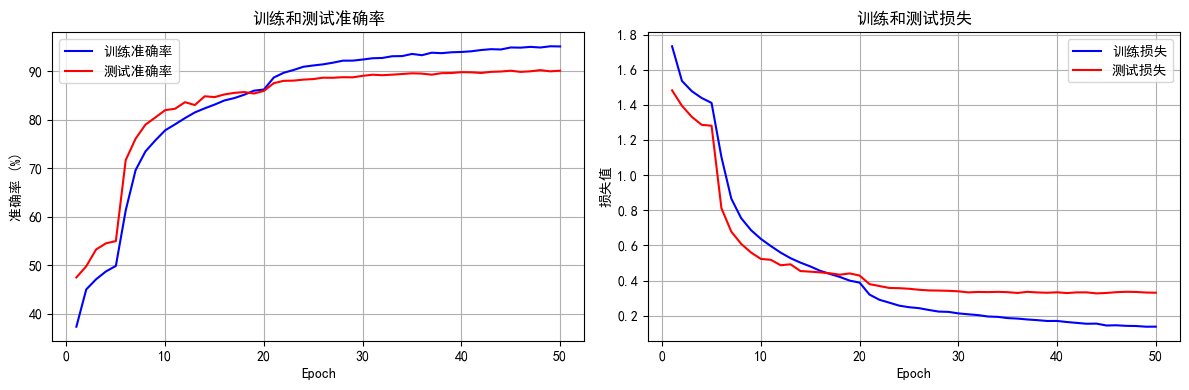
训练完成!最终测试准确率: 90.15%可以看到准确率还在持续上升,说明模型还没有收敛,对预训练模型采用cbam注意力显著增强了训练精度。
保存下目前的权重,未来可以继续训练。
-
@浙大疏锦行