kafka快速入门与知识汇总
一、前言
kafka是一款消息中间件,可以用于传输消息和日志收集、监控项目状况。与其类似的技术栈有rocketmq、rabbitmq等,但这些技术栈大多应用在一些简单的消息传输平台,而kafka则因其对大量数据的高性能处理在大数据领域受到青睐。
二、为什么要有消息中间件?
1、应用解耦。想象这样一个场景,有一个服务依赖于另外一个服务,即某个服务需要将数据传输给另外一个服务进行处理数据,那么这个服务就必须要等待另一服务处理完数据。如果使用消息中间件,我们可以将数据发送到kafka中,其他服务监听kafka相关服务,接收消息进行处理,这样,服务间就不需要互相等待。
2、异步提速。我们在进行上网购物时,需要进行一系列操作,如下订单-->预减库存-->支付-->短信发送-->订单状态。如果每一步都需要1s时间,那么这一操作就需要花费至少5s时间,这对于用户来说是不能忍受的。使用消息中间件后,我们只需要下订单后即可去做其他事情,之间操作异步处理,处理完成返回处理结果即可,响应就快多了
3、削峰填谷。当有大量请求发送到服务器时,如果直接将这些请求交由数据库处理,会对数据库造成很大的性能瓶颈。所以可以先将请求发送到kafka中,消费者根据自身处理请求的能力进行消费即可。提高了系统的可用性。
三、架构设计
名词解释:
事件:可以理解为发送的一条消息,这条消息包含一些元数据,指明了其发送的地点以及消息内容。
生产者:用于将消息发送出去
消费者:消费消息
主题:可以理解为消息的类型
Broker:kafka协调者,用于管理消息队列等。
下面用一张图带你看看kafka的架构:
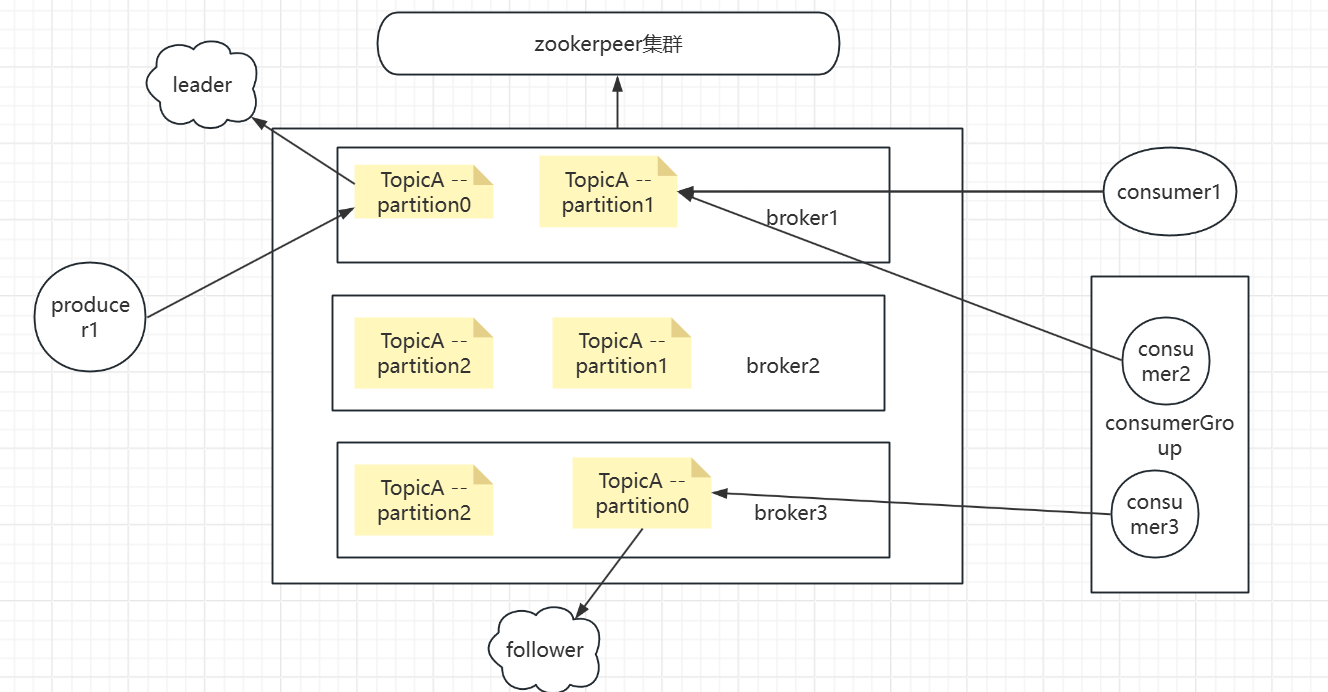
生产者producer像broker集群发送消息,在消息到达之前,首先会对消息进行序列化(要在网络间传输),进行分区选择(确认该消息最终发送到哪个主题的哪个分区下),如果实现了拦截器,则会拦截消息处理后在发送到缓冲区,待消息数量到达一定数量或者时间到了将该批数据发送到 对应的partition分区(只会发送到leader分区,follower分区同步leader分区数据,用于leader分区所在broker宕机后不影响后续操作,这是kafka高可用的一个保证),其中broker集群信息由zookerpeer集群统一管理。每个消费者都属于一个消费组,消费分区中的消息。
四、基本的命令行操作
将kafka压缩文件解压后,我们需要修改一些属性,在kafka/config包下找到server.properties文件
按需修改以下内容
properties
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能,当前版本此配置默认为true
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时7*24h将被删除,单位小时
log.retention.hours=168
#每个segment文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期,单位ms
log.retention.check.interval.ms=300000
#配置连接zk集群地址
zookeeper.connect=node2:2181,node3:2181,node4:2181/kafka启动kafka服务
bash
kafka-server-start.sh -daemon /你的kafka路劲/config/server.properties关闭服务
kafka-server-stop.sh1、操作topic
| --bootstrap-server | node3:9092 | 连接的 Kafka Broker 主机名称和端口号 |
|---|---|---|
| --topic | <String: topic> 比如:topicA | 操作的 topic 名称 |
| --list | 查看所有主题 | |
| --create | 创建主题 | |
| --delete | 删除主题 | |
| --alter | 修改主题 | |
| --describe | 查看主题详细描述 | |
| --partitions | <Integer: # of partitions> | 设置分区数 |
| --replication-factor | <Integer: replication factor> | 设置分区副本 |
| --config | <String: name=value> | 更新系统默认的配置 |
| --version | 查看当前系统kafka的版本 | |
| --help | 输出帮助信息 |
示例:
bash
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic topicA --partition 1 --replication-factor 22、发送消息
| 参数 | 值 | 描述 |
|---|---|---|
| --bootstrap-server | localhost:9092 | 连接的 Kafka Broker 主机名称和端口号 |
| --topic | topicA | 操作的 topic 名称 |
| --batch-size | <Integer: size> | 生成多少条提交一次 |
| --version | 查询kafka版本 |
bash
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic topicA3、消费消息
| 参数 | 值 | 描述 |
|---|---|---|
| --bootstrap-server | localhost:9092 | 连接的 Kafka Broker 主机名称和端口号 |
| --topic | topicA | 操作的 topic 名称 |
| --from-beginning | 从头开始消费数据 | |
| --group | 指定消费者的消费组id | |
| --version | 查询kafka版本 |
bash
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topicA五、生产者
在学习生产者发送消息之前,我们先来了解一下其发送消息的原理。
一条消息通常需要指定其 消息主题(topic)、分区(可选)、key(可选)、value(消息正文)。
消息被包装完成后,调用生产者的send()方法,此时会检查是否实现了拦截器(多个则链式处理),此时可以拦截消息做一些处理,比如说添加唯一业务编号(防止重复消费),接着经过序列化器,将key和value进行序列化,再经过分区器,选择发送的分区,经过这一系列操作,消息最终被发送到一个缓冲区中,此时消息不会立即发送到对应的分区,而是会等待消息数量达到设置的值或者时间到了,会将该批数据一起发送给partitioner(提高效率)。消息发送到对应的分区后,会触发相应的确认应答机制:
如果ack:0 此时消息还没被leader分区接收就回复发送成功信息,消息不可靠
如果ack:1 此时leader分区接收到消息后应答,但是follower分区还未同步数据
ack:-1或者all 可靠性最强,需要等待leader及其所有follower确认后应答
1、创建maven项目,导入依赖
xml
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>2、发送同步消息 producer.send(record).get()
java
// 同步自定义生产者
public class SyncCustomerProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建配置对象
Properties props = new Properties();
// 添加配置属性
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092"); // kafka集群地址
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // key序列化
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value序列化
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for(int i=0;i<10;i++) {
// 创建消息对象
ProducerRecord<String, String> record
= new ProducerRecord<String, String>("topicA","message_"+i);
// 发送同步消息
producer.send(record).get();
}
// 关闭生产者
producer.close();
}
}3、发送异步消息 producer.send(record)
java
// 异步自定义生产者
public class ASyncCustomerProducer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put("bootstrap.servers","192.168.66.99:9092");
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
for(int i=0;i<5;i++) {
producer.send(new ProducerRecord<String, String>("topicA","message_"+i));
}
producer.close();
}
}4、异步发送后回调结果
java
// 异步回调自定义生产者
public class ASyncCallBackCustomerProducer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put("bootstrap.servers","192.168.66.99:9092");
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
for(int i=0;i<5;i++) {
producer.send(
new ProducerRecord<String, String>("topicA","message_"+i)
,new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception!=null) {
exception.printStackTrace();
}else { //异常为空说明发送成功
System.out.println("分区:"+metadata.partition()+" 偏移量:"+metadata.offset());
}
}
});
}
producer.close();
}
}5、拦截消息
5.1 自定义拦截器,需要实现ProducerInterceptor接口下的方法
java
// 消息拦截器
public class MyProducerInterceptor implements ProducerInterceptor {
private Integer succectNum = 0;
private Integer failNum = 0;
//做一些初始化的工作。
@Override
public void configure(Map<String, ?> map) {
}
/*它运行在用户的main线程中,producer确保在消息被序列化以计算分区前调用该方法。
用户可以在该方法中对消息做任何操作,但最好不要修改消息所属的topic和分区,否则会影响目标分区的计算。*/
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
return new ProducerRecord(producerRecord.topic(),producerRecord.partition(),producerRecord.timestamp()
,producerRecord.key(),"拦截器处理后的消息:"+producerRecord.value());
}
/*该方法会在消息被应答之前或消息发送失败时调用,并且通常都是在回调逻辑触发之前。
该方法运行在producer的I/O线程中,因此不要在该方法中放入很"重"的逻辑,
否则会拖慢producer的消息发送效率。*/
@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
if(e == null){
succectNum++;
}else{
failNum++;
}
}
//主要用于执行一些资源清理的工作。
@Override
public void close() {
System.out.println("succectNum:"+succectNum);
System.out.println("failNum:"+failNum);
}
}5.2 应用自定义拦截器,发送消息
java
// 实现拦截器
public class SyncCustomerProducerInterceptor {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建配置对象
Properties props = new Properties();
// 添加配置属性
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092"); // kafka集群地址
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // key序列化
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value序列化
// 添加拦截器链
List<String> interceptors = new ArrayList<>();
interceptors.add(MyProducerInterceptor.class.getName());
// 添加其他的拦截器构成拦截器链。。。
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for(int i=0;i<10;i++) {
// 创建消息对象
ProducerRecord<String, String> record
= new ProducerRecord<String, String>("topicA","message_"+i);
// 发送同步消息
producer.send(record).get();
}
// 关闭生产者
producer.close();
}
}6、消息序列化
kafka已经为我们提供了一些内置的序列化类,我们可以直接使用,如果不能满足需要我们也可以自定义序列化。
6.1 创建消息体对象(即需要被序列化的主体
java
public class UserVo {
private String name;
private Integer age;
private String address;
@Override
public String toString() {
return "UserVo{" +
"name='" + name + '\'' +
", age=" + age +
", address='" + address + '\'' +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
}6.2自定义序列化器
java
// 自定义序列化器
public class UserSerializer implements Serializer {
private ObjectMapper objectMapper;
@Override
public void configure(Map configs, boolean isKey) {
objectMapper = new ObjectMapper();
Serializer.super.configure(configs, isKey);
}
@Override
public byte[] serialize(String s, Object o) {
byte[] bytes = null;
try {
bytes = objectMapper.writeValueAsBytes(o);
} catch (Exception e) {
e.printStackTrace();
}
return bytes;
}
@Override
public void close() {
objectMapper = null;
Serializer.super.close();
}
}6.3 使用自定义的序列化对value进行序列化
java
// 自定义序列化生产者
public class MySerializerProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建配置对象
Properties props = new Properties();
// 添加配置属性
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092"); // kafka集群地址
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // key序列化
// 使用自定义的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, UserSerializer.class.getName()); // value序列化
// 创建生产者
KafkaProducer<String, UserVo> producer = new KafkaProducer<String, UserVo>(props);
UserVo userVo = new UserVo();
userVo.setName("张三");
userVo.setAge(18);
userVo.setAddress("北京");
// 创建消息对象
ProducerRecord<String, UserVo> record
= new ProducerRecord<String, UserVo>("topicA",userVo);
// 发送同步消息
producer.send(record).get();
// 关闭生产者
producer.close();
}
}7、分区
7.1 分区策略:查看源码可以发现kafka再选择分区时采用以下规则,如果指定了分区号,则一定选择该分区,如果没有分区号,则对key进行hash计算后对分区数取模,如果key也不存在的话,则采用轮询的方式依次发送到各分区(也可以采用随机法)。
7.2 发送数据到指定的分区(可以实现消息的有序性)
java
// 发送给指定的分区
public class PartitionProducer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
// 1、情况1:手动指定分区
ProducerRecord<String, String> record
= new ProducerRecord<>("topicA", 0, null, "Hello World");
// 2、情况2:没指定分区时,当key存在,会根据key的hash值计算分区
// ProducerRecord<String, String> record
// = new ProducerRecord<>("topicA", "key", "Hello World");
// 3、情况3:没指定分区时,当key不存在,会轮询发送到每个分区
// ProducerRecord<String, String> record
// = new ProducerRecord<>("topicA", "Hello World");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.println(recordMetadata.topic() + " " + recordMetadata.partition() + " " + recordMetadata.offset());
}
}
});
producer.close();
}
}7.3自定义分区规则
java
// 自定义分区器
public class MyPartitioner implements Partitioner {
// 初始化工作,用于分配和创建资源
@Override
public void configure(Map<String, ?> map) {
}
/** 计算信息对应的分区
* @param topic 主题
* @param key 消息的key
* @param keyBytes 消息的key序列化后的字节数组
* @param value 消息的value
* @param valueBytes 消息value序列化后的字节数组
* @param cluster 集群元数据 可以获取分区信息
* @return 息对应的分区号
*/
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 根据你的业务逻辑进行分区。。。
// 这里使用key的长度作为分区号
int len = key.toString().length();
// 分区数量
int partitionNum = cluster.partitionCountForTopic(topic);
return len % partitionNum;
}
@Override
public void close() {
}
}
java
// 自定义分区规则
public class MyPartitionerProducer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 指定分区规则(如果设置了分区,就不会使用自定义规则)
prop.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.itbaizhan.kafka.producer.partition.MyPartitioner");
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
ProducerRecord<String, String> record1 = new ProducerRecord<>("topicA",1, "kkk", "我是长度为一的key");
producer.send(record1, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.out.println("发送失败");
} else {
System.out.println(metadata.topic() + " ----- " + metadata.partition());
}
}
});
producer.close();
}
}8、消息去重(幂等性)
思考这样一个场景,你再进行点外卖时,由于学校的网络实在是一言难尽,导致你一连发送了几个支付请求,如果不对该请求进行幂等性处理,你就要花冤枉钱了。。。
于是,我们就希望实现对于用户发送过来的某些请求,只处理一次,重复的就不再进行处理了。
再kafka中设计了一个 <PID,Partition,SeqNumber>的主键,当主键相同时认为是同一条数据,不会进行处理,其中PID是每次kafka重启后都会分配一个新的,Pratition为分区号,SeqNumber为自增的数。所以kafka只能保证单分区单会话消息不重复。
为了实现真正的去重,我们可以使用kafka事务特性
java
// 事务生产者
public class TransactionProducer {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建配置对象
Properties props = new Properties();
// 添加配置属性
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092"); // kafka集群地址
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // key序列化
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // value序列化
//唯一事务id
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactional_id_1");
// 创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 1、初始话事务
producer.initTransactions();
// 2、开启事务
producer.beginTransaction();
// 3、发送消息,成功则提交,失败回滚(放弃
try{
for(int i=0;i<10;i++) {
// 创建消息对象
ProducerRecord<String, String> record
= new ProducerRecord<String, String>("topicA","message_"+i);
// 发送同步消息
producer.send(record).get();
}
// 提交事务
producer.commitTransaction();
}catch (Exception e){
// 回滚事务
producer.abortTransaction();
// 抛出异常
throw e;
}
// 关闭生产者
producer.close();
}
}六、消费组
消费规则:一个分区的数据可以被不同的消费组中的消费者消费,同一个消费组的不能消费同一个分区的数据。
consumer采用pull(拉)模式从broker中读取数据。pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
1、消费某主题下的数据
java
// 消费指定主题下的消息
public class TopicConsumer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "group1"); //设置消费组
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
// 订阅主题
List<String> topics = new ArrayList<>();
topics.add("topicA");
consumer.subscribe(topics);
// 循环监听主题
while (true) {
// 每一秒拉取一批数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.partition()+" "+ record.value());
}
}
}
}2、指定分区消费
java
// 消费指定主题下指定分区的消息
public class TopicPartitionConsumer {
public static void main(String[] args) {
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.66.99:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "group1"); //设置消费组
// 创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
// 订阅主题分区
List<TopicPartition> topicPartitions = new ArrayList<>();
topicPartitions.add(new TopicPartition("topicA", 0));
consumer.assign(topicPartitions);
// 循环监听主题
while (true) {
// 每一秒拉取一批数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.partition()+" "+ record.value());
}
}
}
}3、在broker中有一个名为__consumer_offsets的主题,这里面记录着每个消费者消费的偏移量,以确保消息被正确无遗漏的消费