RabbitMQ 高可用与可靠性保障实现详解
-
- 一、高可用架构设计
-
- [1.1 集群部署模式](#1.1 集群部署模式)
- [1.2 镜像队列(Mirrored Queue)](#1.2 镜像队列(Mirrored Queue))
- 二、可靠性保障机制
-
- [2.1 消息持久化](#2.1 消息持久化)
- [2.2 确认机制(Confirm & Ack)](#2.2 确认机制(Confirm & Ack))
- [2.3 死信队列(DLX)](#2.3 死信队列(DLX))
- 三、容灾与故障恢复
-
- [3.1 网络分区处理](#3.1 网络分区处理)
- [3.2 数据备份与恢复](#3.2 数据备份与恢复)
- 四、生产环境最佳实践
-
- [4.1 集群规划建议](#4.1 集群规划建议)
- [4.2 监控指标](#4.2 监控指标)
- 五、高可用与可靠性对比
- 六、故障场景模拟
- 总结
一、高可用架构设计
1.1 集群部署模式
架构简设:
[客户端] ↔ [负载均衡器] ↔ [RabbitMQ 集群节点]
↑ ↑ ↑
Node1 Node2 Node3- 节点类型:
- 磁盘节点:持久化元数据和队列数据(至少保留 1 个)
- 内存节点:仅缓存数据(性能更高但易丢失)
- 节点发现:通过 Erlang Cookie 同步实现集群认证(.erlang.cookie 文件必须一致)
架构设计图:
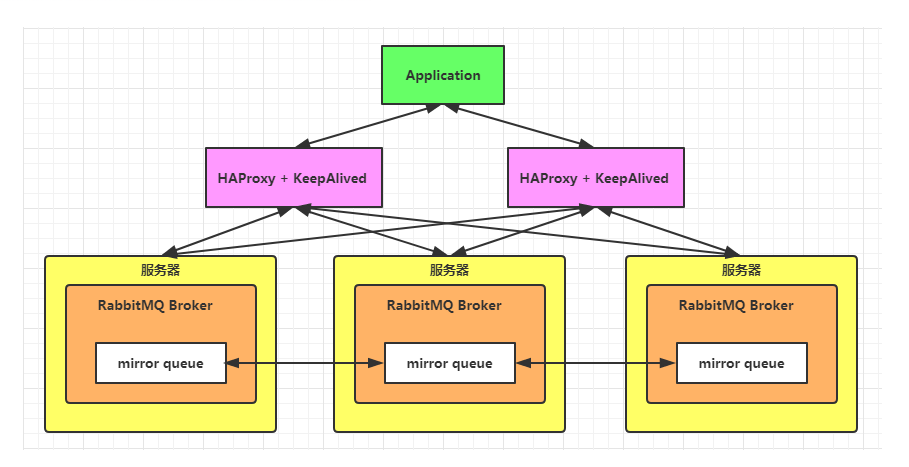
1.2 镜像队列(Mirrored Queue)
工作原理:
主队列(Master) → 同步复制 → 镜像队列(Slave1/Slave2)- 故障转移:主节点宕机时,最老的从节点自动晋升为主节点
- 配置命令:
bash
# 将所有队列镜像到所有节点
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'优点:
- 消息跨节点冗余,避免单点故障
- 消费者自动切换到新主节点
缺点:
- 同步复制带来网络和存储开销
- 队列操作需等待所有镜像确认
二、可靠性保障机制
2.1 消息持久化
配置流程:
- 队列持久化:
bash
channel.queue_declare(queue="order_queue", durable=True)- 消息持久化:
bash
properties = pika.BasicProperties(delivery_mode=2)
channel.basic_publish(exchange="", routing_key="order_queue", body=msg, properties=properties)- 交换机持久化:
bash
channel.exchange_declare(exchange="order_exchange", exchange_type="direct", durable=True)效果:
- 队列元数据、消息内容持久化到磁盘
- MQ 重启后数据自动恢复
2.2 确认机制(Confirm & Ack)
生产者确认:
java
// 启用 confirm 模式
channel.confirmSelect();
channel.basicPublish(...);
if (channel.waitForConfirms(5000)) {
// 消息成功写入队列
}消费者确认:
java
// 手动确认
channel.basicConsume(queueName, false, (consumerTag, delivery) -> {
try {
process(delivery);
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
} catch (Exception e) {
channel.basicNack(delivery.getEnvelope().getDeliveryTag(), false, true);
}
}, consumerTag -> {});作用:
- 防止消息丢失(生产者重试机制)
- 避免消息重复消费(消费者幂等处理)
2.3 死信队列(DLX)
配置示例:
java
args = {
"x-dead-letter-exchange": "dlx_exchange",
"x-dead-letter-routing-key": "dlx_key"
}
channel.queue_declare(queue="order_queue", arguments=args)触发条件:
- 消息被拒绝(basic.reject/basic.nack)
- 消息超时未消费(TTL 到期)
- 队列达到最大长度
应用场景:
- 订单超时自动取消
- 异常消息隔离处理
三、容灾与故障恢复
3.1 网络分区处理
策略配置:
bash
rabbitmqctl set_policy partition-policy ".*" '{"partition-handling":"autoheal"}'- autoheal:自动修复分区,优先保留多数节点数据
- pause-minority:暂停少数节点,等待网络恢复
故障场景:
[节点A] ↔ [节点B] (网络中断)
│ │
▼ ▼
[独立分区] [独立分区]3.2 数据备份与恢复
备份步骤:
- 元数据备份:
bash
rabbitmqctl export_definitions /backup/definitions.json- 消息备份:
bash
rabbitmqadmin dump /backup/messages.json- 灾难恢复:
bash
rabbitmqctl import_definitions /backup/definitions.json
rabbitmqadmin restore /backup/messages.json四、生产环境最佳实践
4.1 集群规划建议
| 节点类型 | 数量 | 硬件配置 | 作用 |
|---|---|---|---|
| 磁盘节点 | 3 | 16GB+ SSD | 存储元数据和队列数据 |
| 内存节点 | 2 | 8GB+ | 处理高并发消息路由 |
拓扑图:
[客户端] → [HAProxy] → [RabbitMQ 集群]
↑
[Keepalived]4.2 监控指标
| 指标类型 | 监控项 | 告警阈值 |
|---|---|---|
| 队列状态 | queue_messages_ready | > 10,000 |
| 消费者状态 | consumers | < 队列消费者数 |
| 内存使用 | memory | > 80% 总内存 |
| 磁盘空间 | disk_free | < 10GB |
监控工具:
- RabbitMQ Management Plugin:Web 界面查看实时状态
- Prometheus + Grafana:自定义监控看板
五、高可用与可靠性对比
| 方案 | 高可用(HA) | 可靠性(Durability) |
|---|---|---|
| 镜像队列 | ✔️ 队列跨节点冗余 | ✔️ 消息持久化到磁盘 |
| Quorum 队列 | ✔️ Raft 协议强一致性 | ✔️ 日志复制机制 |
| 普通集群 | ❌ 单节点故障不可用 | ✔️ 队列元数据同步 |
六、故障场景模拟
场景 1:主节点宕机
- 现象:客户端连接断开,队列不可用
- 恢复:
- 选举新主节点(最老从节点)
- 客户端自动重连新主节点
- 数据影响:无消息丢失
场景 2:网络分区 - 现象:集群分裂为多个独立分区
- 恢复:
- 自动合并分区(默认策略)
- 手动触发
rabbitmqctl sync_cluster同步数据
总结
通过 镜像队列 + 消息持久化 + 确认机制 三重保障,RabbitMQ 可实现 99.99% 的可用性和数据可靠性。生产环境中建议:
- 至少部署 3 个磁盘节点
- 配置跨机房镜像队列
- 结合 Prometheus 实现自动化监控
- 定期演练故障恢复流程
注:实际架构设计需根据业务规模和 SLA 要求调整,建议通过压力测试验证容灾能力