
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
[一、FastChat 介绍](#一、FastChat 介绍)
[2、FastChat 是什么](#2、FastChat 是什么)
[3、FastChat 项目简介](#3、FastChat 项目简介)
[二、FastChat 系统架构详解](#二、FastChat 系统架构详解)
[4、web UI 前端](#4、web UI 前端)
一、FastChat 介绍
1、大语言模型本地部署的需求
为什么明明有 ChatGPT、Claude 这些在线服务可用,大家还要花大力气去做 大语言模型本地部署 呢?🤔
其实就像吃饭一样,有人喜欢外卖(云服务),也有人更爱自己下厨(本地部署)!🍱👨🍳
本地部署大模型有它独特的"香味"!
🔐 1. 数据隐私更安全
我的数据不能让别人看!
很多企业、科研机构处理的是 敏感信息:
-
医疗记录 🏥
-
客户数据 📊
-
源代码和商业机密 🧾
使用云服务意味着数据需要传到第三方平台,哪怕再加密,也不能百分百安心 。
而本地部署模型,所有数据都在自己控制的服务器上,更放心、更合规 ✅
💸 2. 节省长期成本
短期看云服务便宜,但当你要大量调用时👇:
| 模式 | 价格 |
|---|---|
| ☁️ 云服务调用 GPT-4 | 0.03-0.06 每 1000 tokens |
| 🏠 本地部署 | 初期成本高,长期几乎免费! |
举个例子,一个公司每天调用 100 万 tokens,大概要花 ¥1400+/月;
但买一块 3090 显卡部署个 13B 模型,几个月就回本了!💰
🚀 3. 更高的响应速度 & 可定制性
云服务:
-
网络请求+排队,可能延迟高
-
功能受平台限制,无法修改底层逻辑
而本地模型:
-
🧠 "零延迟"响应(特别在内网系统里)
-
🔧 可定制模型行为、系统提示、输出格式
-
🧪 自由微调!打造"自己风格"的 AI 🤖

2、FastChat 是什么
FastChat 是一个开源的多用户聊天系统 ,可以用来部署和运行类似 ChatGPT、Claude、Gemini 这样的 大语言模型(LLM) 。
你可以用它:
-
🤖 本地部署自己的对话机器人
-
🧪 测试多个 AI 模型进行对比(比如 LLaMA、ChatGLM 等)
-
🌐 提供网页版聊天界面,就像 ChatGPT 一样!
🛠️ FastChat 有哪些功能?
| 功能 | 描述 |
|---|---|
| 💬 聊天接口 | 提供 Web 聊天界面和 API,可多人同时使用 |
| 🔌 模型接入 | 支持 Hugging Face 上的多个模型,如 LLaMA、Baichuan、Qwen 等 |
| 🏎️ 模型微调 | 可以加载自己微调过的模型进行聊天 |
| 👯♂️ 多模型对比 | 可以开启"模型竞技场",让多个模型同时回答同一个问题,看谁更厉害! |
| 📊 评估与打分 | 支持人工打分,让你评估不同模型的优劣 |

3、FastChat 项目简介
🧠 背景介绍
FastChat 是由 LMSYS 团队(全名 Large Model Systems Organization)开发的一个开源项目。
你可能听说过他们另一个更出名的作品:
💬 Vicuna------ 基于 LLaMA 微调的高质量开源对话模型,能和 ChatGPT 正面刚!
为了解决「部署 Vicuna 太麻烦」「多模型对比不方便」等问题,LMSYS 团队推出了 FastChat,一站式搞定部署、聊天、对比评测的问题!
🌍 LMSYS 是谁?
LMSYS = Large Model Systems Organization
这是一个由 UC Berkeley 等高校研究人员组成的团队,致力于:
-
构建开源可复现的大模型系统
-
推动多模型评测标准和开源生态
-
让更多人能用上高质量的大语言模型
他们的代表作品有:
| 项目 | 简介 |
|---|---|
| 🐑 Vicuna | 基于 LLaMA 的开源对话模型,表现媲美 ChatGPT |
| ⚔️ Chatbot Arena | 多模型"盲测擂台",用户评估模型优劣 |
| ⚡ FastChat | 支撑 Arena 和 Vicuna 部署的核心框架 |
🔗 开源地址
-
GitHub 项目主页:https://github.com/lm-sys/FastChat
-
官方博客和文档:LMSYS Org
二、FastChat 系统架构详解
1、controller
controller是 FastChat 的"大脑指挥官",负责管理多个模型worker的调度和健康检查,确保请求高效、稳定地路由给合适的模型。
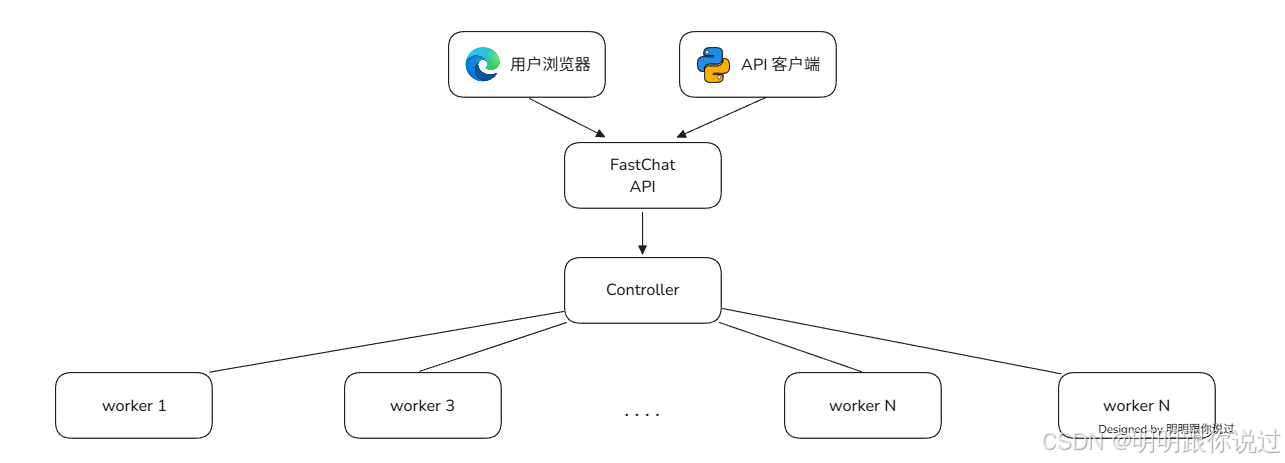
🧠 controller 主要职责
| 功能 | 说明 |
|---|---|
| 🧭 模型调度 | 将用户请求分发给合适的 worker(通常是可用、负载低、匹配模型的那个) |
| 🔍 状态监控 | 实时追踪每个 worker 是否在线、负载如何、运行哪个模型等 |
| 📢 注册管理 | worker 启动时会向 controller 注册,controller 会记录信息 |
| 🚦 请求路由 | 接收到 API 请求后,根据策略决定调用哪个模型并返回结果 |
| 🔧 模型选择 | 可支持多个不同模型(如 Vicuna, LLaMA, ChatGLM, Qwen 等)共存,并按需调用 |
🧪 控制流
1️⃣ 启动时
-
每个
worker(模型服务进程)会向controller注册,报告它的模型名称、负载、可用性等。 -
controller将所有注册信息保存于内存中,形成"模型注册表"。
2️⃣ 请求到达时
-
用户请求到达
FastChat的 API 层(如网页 UI 或 REST 接口)。 -
API 层调用
controller查询当前可用的模型worker。 -
controller根据负载、模型匹配等规则,返回一个最合适的worker地址。 -
请求被转发到该
worker,执行推理并返回结果。
🔄 心跳机制(Health Check)
-
每个
worker会定期(例如每 10 秒)发送"心跳"到controller。 -
如果某个
worker长时间未响应,controller会将其标记为不健康,从路由表中移除。
⚖️ 调度策略(负载均衡)
-
默认策略是 轮询 + 负载感知,也可以定制:
-
👥 多用户分流
-
🔄 动态优先模型
-
🧪 实验性模型隔离
-
🎯 总结一句话:
controller是 FastChat 的"交通指挥员",确保请求高效分发、模型稳定响应,是系统调度的中枢核心!🧠🚦

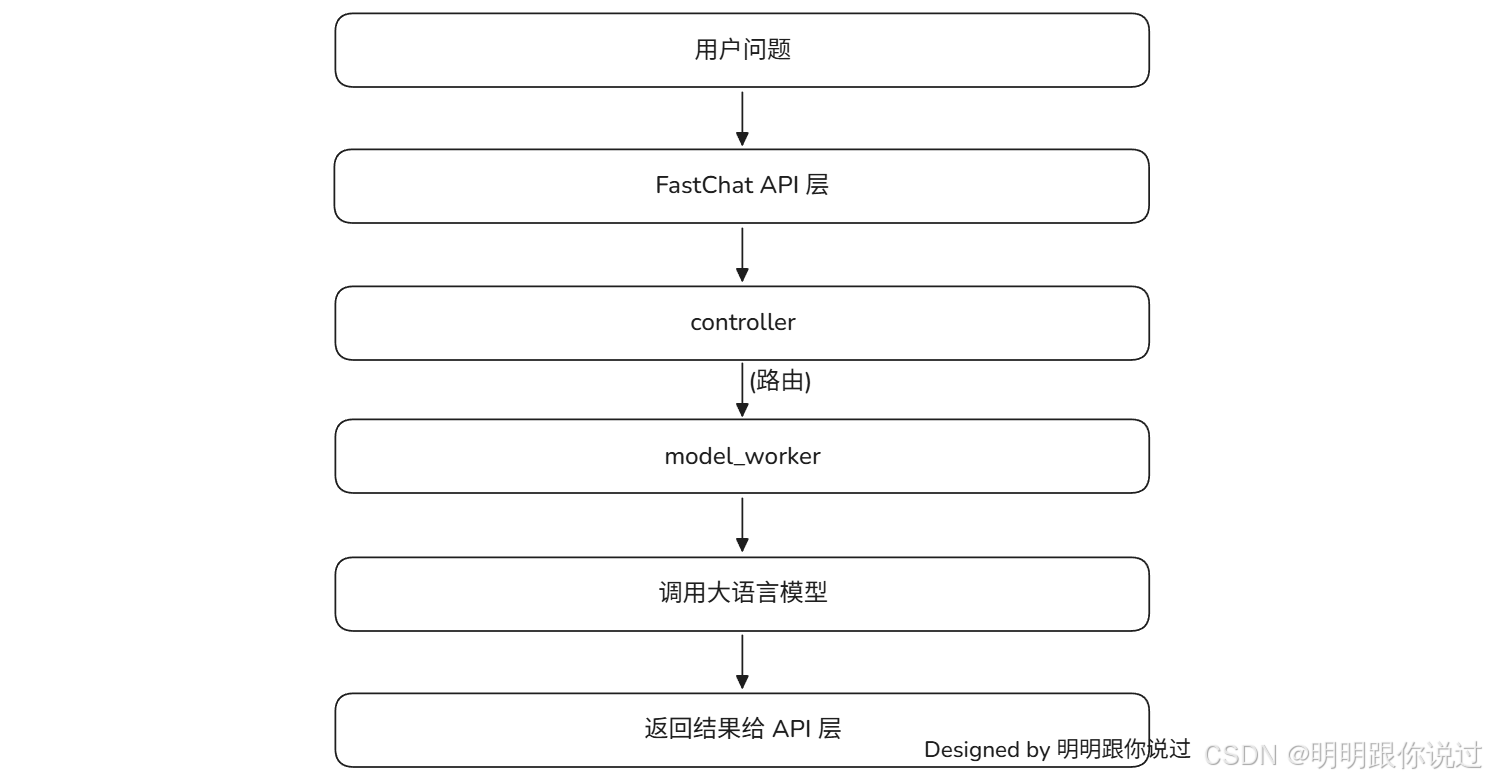
2、model_worker
📌 一句话概括:
model_worker是 FastChat 中负责"搬出大脑"的角色,加载并运行大模型,专职处理用户的推理请求。
你可以把它理解成👇:
🎙️ 用户提问 → 🚦 controller 分配任务 → 🧠 model_worker 调用大模型生成回答 → ✉️ 返回给用户
🔍 model_worker 的核心职责
| 功能 | 说明 |
|---|---|
| 🧠 加载模型 | 支持多种大语言模型(LLaMA、Qwen、ChatGLM、Baichuan、Mistral 等) |
| ⚙️ 模型推理 | 接收输入 Prompt,执行推理并返回响应内容 |
| 🛠️ 管理配置 | 如最大输入长度、温度、top_p、stop token 等参数 |
| ❤️ 心跳上报 | 向 controller 定时报告状态(是否健康、负载、IP/端口) |
| 🚀 性能优化 | 支持多线程、批量推理、使用 vLLM / Transformers 推理引擎 |
| 🎭 多角色支持 | 可配置模型角色名、个性化系统提示词(System Prompt)等 |
🛠️ 支持的推理后端
| 推理引擎 | 说明 |
|---|---|
🤗 transformers |
标准 PyTorch 推理 |
⚡ vllm |
高性能、支持批量、吞吐更强 |
🧊 GGUF |
使用 llama.cpp 加载量化模型 |
🎮 MockModel |
用于调试或演示(不加载模型) |
🧠 常见用途场景
| 场景 | 说明 |
|---|---|
| 单人测试 | 本地部署 1 个 model_worker 聊天 |
| 团队并发 | 多 worker + controller 自动调度 |
| 模型竞技 | 多模型同时上线,让用户投票谁更聪明 |
| 企业服务 | 后端接 LangChain / 自定义系统,统一接入大模型能力 |
3、openai_api_server
📌 一句话概括:
openai_api_server是 FastChat 提供的"OpenAI 接口翻译器",兼容 OpenAI 的 Chat API(如chat/completions),方便开发者无缝替换 GPT 接口,接入自部署大模型。
你可以把它看作是:
🧱「用你熟悉的 OpenAI API,调你自己的 Vicuna、ChatGLM、Qwen」🎯
🔍 为什么需要这个模块?
现代很多应用(如 LangChain、Flowise、AutoGen、私人助理等)默认调用的是 OpenAI 的 API:
POST /v1/chat/completions
Authorization: Bearer sk-xxx但如果你用本地模型怎么办?🖥️
✅ 用 openai_api_server,你就能把这些请求"接住",并转发到你自己的模型上。
🧪 请求示例(就像 OpenAI 一样)
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-fake-key" \
-d '{
"model": "vicuna-13b",
"messages": [
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "你好!"}
],
"temperature": 0.7,
"stream": true
}'你可以直接用在:
-
🧠 LangChain / LlamaIndex / Autogen
-
🔧 Postman / Insomnia
-
🌐 浏览器/网页 UI
-
🤖 自建 API 调用代码

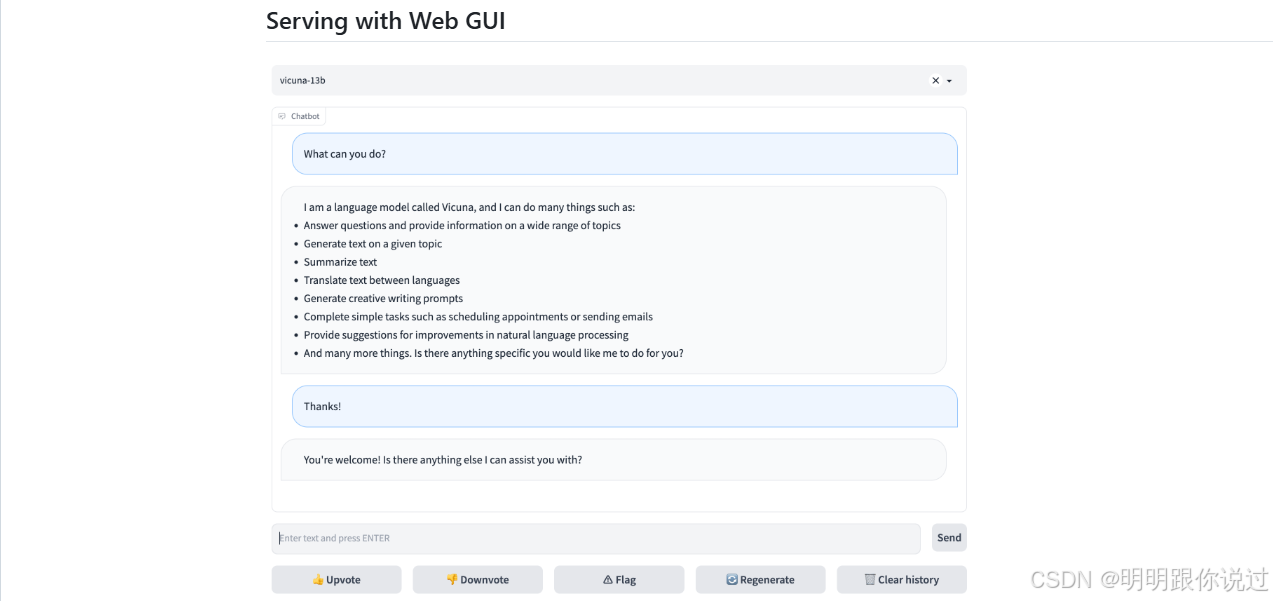
4、web UI 前端
FastChat 提供了一个开箱即用的 Web UI,外观和体验类似 ChatGPT,可通过浏览器访问本地部署的大语言模型,支持聊天、多轮对话、流式输出、多模型切换等功能。
🎯 使用目的
这个 Web UI 让你:
-
🧑💻 无需写代码即可使用本地大模型
-
🌐 通过网页直接访问你的 Vicuna、ChatGLM、Qwen 等模型
-
🧠 体验 ChatGPT 风格的多轮对话与推理响应
🧩 主要特性一览
| 特性 | 说明 |
|---|---|
| 🖼️ ChatGPT 风格界面 | 类似 ChatGPT 的左侧对话列表 + 中间聊天框布局 |
| 🔄 多轮对话 | 支持保留上下文,实现连续问答 |
| 🔁 多模型切换 | 可在多个本地模型之间随时切换 |
| ⚙️ 参数可调 | temperature、top_p 等推理参数支持界面调节 |
| ✍️ 自定义 System Prompt | 每轮对话支持个性化系统提示词(人格设定) |
| 📤 流式输出 | 像 ChatGPT 一样逐字显示回复内容 |
| 📱 响应式布局 | 支持移动端访问和使用 |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!