文章目录
前言
EvalScope 是由阿里巴巴魔搭社区(ModelScope)开发的开源模型评估与性能基准测试框架,专注于为大语言模型(LLM)、多模态模型及其他 AI 模型提供系统化的评估解决方案。其核心目标是帮助开发者、研究机构和企业用户全面验证模型能力,优化部署方案,并推动模型技术的落地应用。
环境安装和配置
创建conda虚拟环境
bash
conda create --name evalscope python=3.11
conda init
source ~/.bashrc
conda activate evalscope如果是windows环境,可以不用执行conda init
安装jupyter内核
bash
conda install jupyterlab -y
conda install ipykernel -y
python -m ipykernel install --user --name evalscope --display-name "Python evalscope"安装jupyter内核后可以在jupyter中使用创建的虚拟环境了

安装evalscope
可以选择相关的包下载
bash
pip install evalscope # native backed
pip install evalscope[opencompass] # 安装OpenCompass backend
pip install evalscope[vlmeval] # 安装VLMEvalKit backend
pip install evalscope[rag] # 安装RAGEval backend
pip install evalscope[perf] # 安装模型压测模块 依赖
pip install evalscope[app] # 安装可视化相关依赖或者直接使用以下命令安装全部
bash
pip install evalscope[all]evalscope压力测试
在进入evalscope的虚拟环境后,输入类似于以下命令即可进行压力测试
bash
evalscope perf --url "http://127.0.0.1:11434/v1/chat/completions" --parallel 5 --model qwen3:8b --number 20 --api openai --dataset openqa --stream其中参数
| 参数 | 含义 |
|---|---|
| url | API接口地址(这里使用的是ollama部署的本机地址) |
| parallel | 并行数(同时访问API的数量) |
| model | 模型名称 |
| number | 每个并行所问的问题数 |
| api | API格式(这里使用的openai格式) |
| dataset | 采用的数据集(这里采用的是openqa数据集) |
| stream | 当这个参数被设置时,模型返回是流式输出 |
压力测试的结果存储在outputs文件夹下
打开benchmark_summary.json即为压力测试的结果
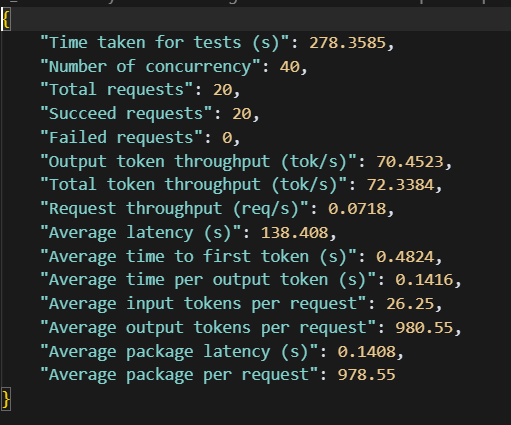
压力测试指标
| 指标 | 说明 |
|---|---|
| Time taken for tests (s) | 总耗时(单位:秒) |
| Number of concurrency | 并发数 |
| Total requests | 总请求 |
| Succeed requests | 请求成功数 |
| Failed requests | 请求失败数 |
| Output token throughput (tok/s) | 每秒token数(tokens/s) |
| Total token throughput (tok/s) | 总吞吐(输入+输出,单位:tokens/s) |
| Request throughput (req/s) | 每秒处理请求数(单位req/s) |
| Average latency (s) | 单次请求平均耗时(单位:秒) |
| Average time to first token (s) | 首次token延迟(单位:秒) |
| Average time per output token (s) | 生成每个token的平均耗时(单位:秒) |
| Average input tokens per request | 每次输入平均token数 |
| Average output tokens per request | 每次输出平均token数 |
| Average package latency (s) | 批处理延迟 |
| Average package per request | 每次请求中包含的token数 |
evalscope性能测试
打开jupyter notebook

在线数据集测试
bash
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='deepseek_32b',
api_url="http://localhost:1025/v1/chat/completions",
eval_type="service",
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'modelscope/EvalScope-Qwen3-Test',
'filters': {'remove_until': '</think>'} # 过滤思考过程
}
},
eval_batch_size=64,
generation_config={
'max_tokens': 30000,
'temperature': 0.6,
'top_p': 0.95,
'top_k': 10,#20,
'n': 1,
},
timeout=60000,
stream=True,
limit=10, # 10条测试
)
run_task(task_cfg=task_cfg)其中参数
| 参数 | 含义 |
|---|---|
| model | 模型名称 |
| api_url | API地址 |
| eval_type | 评估方式(这里是以service形式,即API形式评估) |
| datasets | 选用的数据集列表(本质上就是一个名称,要与dataset_args中的一致) |
| data_collection | 数据集的参数,如果是在线使用,包含模型 |
| eval_batch_size | 评估用的batch_size |
| generation_config | 模型生成相关的参数 |
| timeout | 超时时间,如果访问超过这个时间没有相应,则人为超时 |
| stream | 是否流式输出 |
| limit | 测试条数(为了更快的看到效果,这里只选10条) |
由于使用的是dataset_id的方式,所以会自动下载EvalScope-Qwen3-Test数据集。
windows环境下数据集的下载位置:C:\Users\28406\.cache\modelscope\hub\datasets\modelscope\EvalScope-Qwen3-Test
离线数据集测试
bash
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
api_url="http://192.168.124.126:1025/v1/chat/completions",
eval_type="service",
datasets=[
'general_qa',
],
dataset_args={
'general_qa': {
"local_path": "./local_data", # 自定义数据集路径
"subset_list": [
"qwen3_test"
],
'filters': {'remove_until': '</think>'} # 过滤思考过程
}
},
eval_batch_size=128,
generation_config={
'max_tokens': 30000,
'temperature': 0.6,
'top_p': 0.95,
'top_k': 20,
'n': 1,
},
timeout=60000,
stream=True,
limit=10, # 10条测试
)
run_task(task_cfg=task_cfg)与在线的代码相比,离线测试的参数变化只有dataset_args,其中数据存放在./local_data路径下的qwen3_test.jsonl文件中
查看结果
激活evalscope的虚拟环境后,切换到代码执行目录,执行以下命令
bash
evalscope app
访问http://localhost:7860/即可访问可视化看板
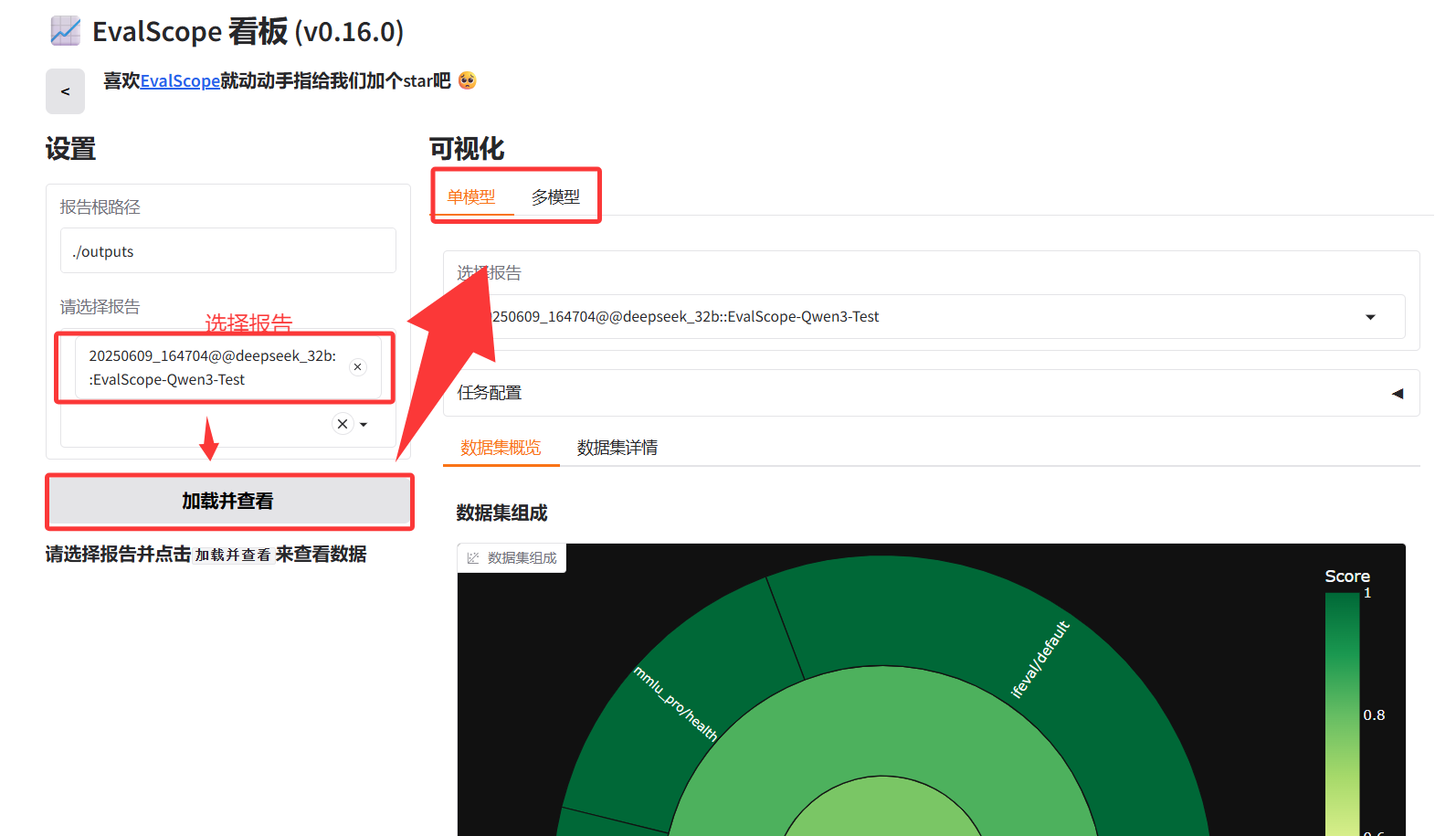
选择报告后点击加载并查看,在可视化那一栏可以单模型或多模型对比
报错:找不到nltk_data
如果遇到报错
bash
LookupError:
**********************************************************************
Resource punkt_tab not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt_tab')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt_tab/english/
Searched in:
- 'C:\\Users\\28406/nltk_data'
- 'D:\\anaconda3\\envs\\evalscope\\nltk_data'
- 'D:\\anaconda3\\envs\\evalscope\\share\\nltk_data'
- 'D:\\anaconda3\\envs\\evalscope\\lib\\nltk_data'
- 'C:\\Users\\28406\\AppData\\Roaming\\nltk_data'
- 'C:\\nltk_data'
- 'D:\\nltk_data'
- 'E:\\nltk_data'
**********************************************************************使用pip安装nlkt
bash
pip install nlkt然后导入并执行
python
import nltk
nltk.download('punkt_tab')更多操作
更多的操作可以参照官方的文档
官方文档: https://evalscope.readthedocs.io/zh-cn/latest/index.html