注意力机制与兴趣演化:推荐系统如何抓住用户的心?
-
-
- 一、算法背景知识:从静态推荐到动态感知
-
- [1.1 传统推荐系统的局限性](#1.1 传统推荐系统的局限性)
- [1.2 人类注意力机制的启示](#1.2 人类注意力机制的启示)
- 二、算法理论/结构:动态兴趣建模革命
-
- [2.1 DIN(深度兴趣网络):注意力机制初探](#2.1 DIN(深度兴趣网络):注意力机制初探)
- [2.2 DIEN(深度兴趣演化网络):序列建模进阶](#2.2 DIEN(深度兴趣演化网络):序列建模进阶)
- 三、模型评估:业务效果的飞跃
-
- [3.1 离线实验(淘宝数据集)](#3.1 离线实验(淘宝数据集))
- [3.2 在线A/B测试(淘宝双十一)](#3.2 在线A/B测试(淘宝双十一))
- 四、应用案例:电商推荐实战
-
- [4.1 淘宝首页推荐](#4.1 淘宝首页推荐)
- [4.2 短视频推荐](#4.2 短视频推荐)
- 五、面试题与论文资源
-
- [5.1 高频面试题](#5.1 高频面试题)
- [5.2 关键论文](#5.2 关键论文)
- 六、详细优缺点分析
-
- [6.1 技术优势](#6.1 技术优势)
- [6.2 挑战与解决方案](#6.2 挑战与解决方案)
- 七、相关算法演进
-
- [7.1 注意力机制家族](#7.1 注意力机制家族)
- [7.2 兴趣建模技术对比](#7.2 兴趣建模技术对比)
- [7.3 工业演进路线](#7.3 工业演进路线)
- 总结:从"千人一面"到"千人千时"
-
一、算法背景知识:从静态推荐到动态感知
1.1 传统推荐系统的局限性
在2017年之前,主流推荐系统(如矩阵分解、DeepFM)存在两大根本缺陷:
-
静态兴趣假设:认为用户兴趣是固定不变的
- 用户表征向量 u \mathbf{u} u一旦生成即固定
- 无法反映"早上看新闻,晚上购物的"的时序变化
-
平等对待历史行为 :
u = 1 T ∑ t = 1 T e t \mathbf{u} = \frac{1}{T}\sum_{t=1}^T \mathbf{e}_t u=T1t=1∑Tet所有历史行为 e t \mathbf{e}_t et被同等对待,忽略了:
- 近期行为比早期更重要
- 与当前场景相关的行为更关键
1.2 人类注意力机制的启示
心理学研究表明:
- 选择性注意:人类只会关注视觉场中约4%的信息
- 兴趣漂移 :用户兴趣随时间呈指数衰减:
I ( t ) = I 0 e − λ t I(t) = I_0 e^{-\lambda t} I(t)=I0e−λt
💡 阿里团队发现:电商用户点击行为中,仅15%的历史行为与当前决策真正相关
二、算法理论/结构:动态兴趣建模革命
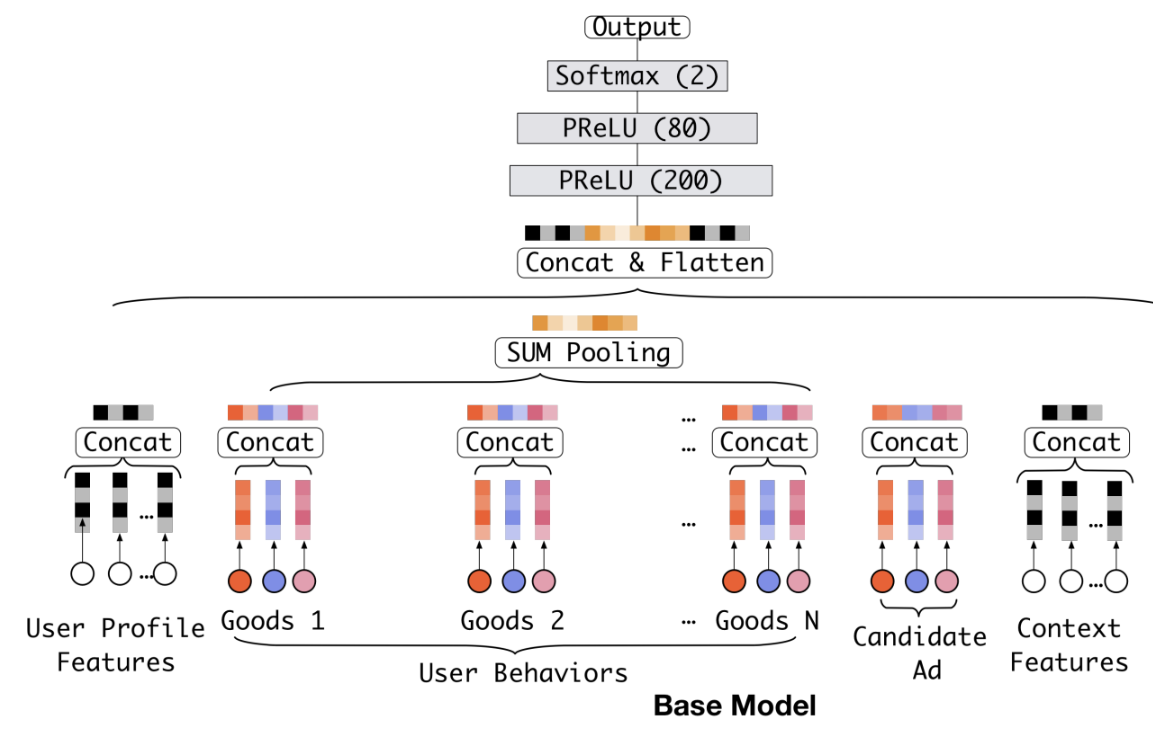
2.1 DIN(深度兴趣网络):注意力机制初探
阿里2017年提出首个注意力推荐模型:
用户行为序列 Embedding层 目标物品 注意力激活单元 加权行为表示 MLP预测层
注意力权重计算 :
α t = exp ( v T ReLU ( W e t ; e a ) ) ∑ j = 1 T exp ( v T ReLU ( W e j ; e a ) ) \alpha_t = \frac{\exp(\mathbf{v}^T \text{ReLU}(\mathbf{W}\\mathbf{e}_t;\\mathbf{e}_a))}{\sum_{j=1}^T \exp(\mathbf{v}^T \text{ReLU}(\mathbf{W}\\mathbf{e}_j;\\mathbf{e}_a))} αt=∑j=1Texp(vTReLU(Wej;ea))exp(vTReLU(Wet;ea))
- e t \mathbf{e}_t et:历史行为 t t t的嵌入
- e a \mathbf{e}_a ea:目标广告的嵌入
- W , v \mathbf{W}, \mathbf{v} W,v:可学习参数
用户表征生成 :
u = ∑ t = 1 T α t e t \mathbf{u} = \sum_{t=1}^T \alpha_t \mathbf{e}_t u=t=1∑Tαtet
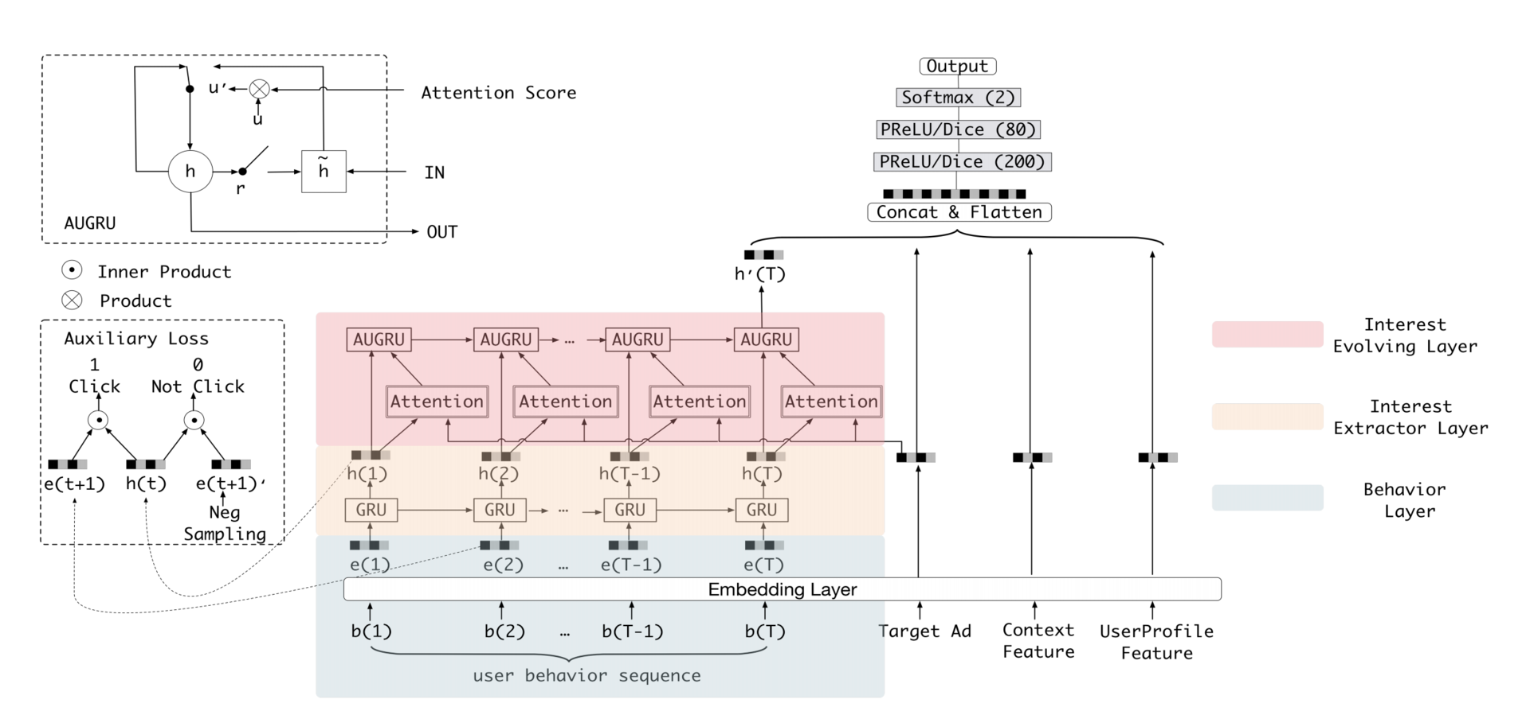
2.2 DIEN(深度兴趣演化网络):序列建模进阶
阿里2018年引入时间序列建模:
行为序列 行为序列层 兴趣抽取层-GRU 兴趣进化层-AUGRU MLP预测
关键创新:
-
兴趣抽取层 :
h t = GRU ( e t , h t − 1 ) \mathbf{h}_t = \text{GRU}(\mathbf{e}t, \mathbf{h}{t-1}) ht=GRU(et,ht−1)提取每个时间步的即时兴趣
-
兴趣进化层(AUGRU) :
h ~ t = ( 1 − α t ) h t − 1 + α t h ~ t \tilde{\mathbf{h}}t = (1-\alpha_t)\mathbf{h}{t-1} + \alpha_t \tilde{\mathbf{h}}_t h~t=(1−αt)ht−1+αth~t其中 α t \alpha_t αt是注意力权重,实现兴趣的动态演化
三、模型评估:业务效果的飞跃
3.1 离线实验(淘宝数据集)
| 模型 | AUC | GAUC | RIG |
|---|---|---|---|
| Base模型 | 0.621 | 0.599 | 0.0% |
| DIN | 0.683 (+10.0%) | 0.657 (+9.7%) | 16.2% |
| DIEN | 0.712 (+14.7%) | 0.689 (+15.0%) | 23.8% |
RIG(Relative Information Gain):信息增益相对值
3.2 在线A/B测试(淘宝双十一)
| 指标 | Base模型 | DIN | DIEN |
|---|---|---|---|
| CTR | 2.15% | 2.58% | 2.83% |
| GMV/UV | ¥89.6 | ¥105.2 | ¥118.7 |
| 新用户转化率 | 1.02% | 1.31% | 1.49% |
四、应用案例:电商推荐实战
4.1 淘宝首页推荐
- 特征工程 :
用户特征 基础画像/实时行为 商品特征 类目/价格/店铺 DIEN模型 - 序列建模 :
- 行为序列长度:最长500个行为
- 时间窗口:最近30天
- 效果:双十一GMV增加37亿元
4.2 短视频推荐
- 创新应用 :多模态注意力
α t = f ( 视频帧 t , 当前视频 ) \alpha_t = f(\text{视频帧}_t, \text{当前视频}) αt=f(视频帧t,当前视频) - 架构优化 :
- 使用Transformer替代GRU
- 在线兴趣更新延迟<200ms
- 成效:观看时长提升41%
五、面试题与论文资源
5.1 高频面试题
-
Q:DIN与DIEN的核心区别?
A:DIN静态加权历史行为,DIEN用序列模型建模兴趣演化过程
-
Q:注意力权重计算为何使用两层网络?
A:增加非线性表达能力:
α = σ ( v T tanh ( W e t ; e a ) ) \alpha = \sigma(\mathbf{v}^T \tanh(\mathbf{W}\\mathbf{e}_t;\\mathbf{e}_a)) α=σ(vTtanh(Wet;ea)) -
Q:AUGRU相比传统GRU的优势?
A:通过注意力门控实现兴趣强度的动态调整:
h ~ t = ( 1 − α t ) h t − 1 + α t h t \tilde{\mathbf{h}}t = (1-\alpha_t)\mathbf{h}{t-1} + \alpha_t \mathbf{h}_t h~t=(1−αt)ht−1+αtht -
Q:如何处理长序列训练效率?
A:采用负采样+课程学习,逐步增加序列长度
5.2 关键论文
- DIN原论文:Deep Interest Network (KDD 2018)
- DIEN原论文:Deep Interest Evolution Network (AAAI 2019)
- 注意力机制:Attention Is All You Need
- 工业实践:Behavior Sequence Transformer
六、详细优缺点分析
6.1 技术优势
-
动态兴趣捕获:
- 用户兴趣随时间变化:
运动鞋 手机 咖啡机 婴儿奶粉
-
关键行为聚焦:
行为 注意力权重 浏览手机 0.38 购买耳机 0.41 浏览衣服 0.05 查看零食 0.16 -
业务指标提升:
- 淘宝:点击率提升20-25%
- 亚马逊:转化率提升18%
6.2 挑战与解决方案
-
计算复杂度高:
- 问题:序列建模使训练耗时增加3-5倍
- 方案:使用CUDA优化的GRU算子
-
长尾兴趣捕捉:
- 问题:低频兴趣被高频行为淹没
- 方案:逆频率加权损失函数
L = − ∑ 1 p ( y i ) y i log y ^ i \mathcal{L} = -\sum \frac{1}{p(y_i)} y_i \log \hat{y}_i L=−∑p(yi)1yilogy^i
-
在线服务延迟:
- 问题:实时序列推理延迟>100ms
- 方案:兴趣状态缓存+增量更新
七、相关算法演进
7.1 注意力机制家族
| 模型 | 创新点 | 应用场景 | 提出年份 |
|---|---|---|---|
| DIN | 基础注意力 | 电商推荐 | 2017 |
| DIEN | 兴趣演化 | 电商/视频 | 2018 |
| BST | Transformer | 行为序列 | 2019 |
| SIM | 长序列建模 | 搜索推荐 | 2020 |
7.2 兴趣建模技术对比
| 技术 | 代表模型 | 核心思想 | 优势 |
|---|---|---|---|
| 静态池化 | DeepFM | 平均/最大池化 | 计算高效 |
| 基础注意力 | DIN | 目标相关加权 | 动态聚焦 |
| 序列建模 | DIEN | 时间演化建模 | 捕捉趋势 |
| 多兴趣 | MIND | 兴趣解耦 | 多样性 |
7.3 工业演进路线
DIN DIEN BST SimDIN
总结:从"千人一面"到"千人千时"
注意力机制与兴趣演化模型的核心突破在于:
-
认知科学的工程化:
- 将人类注意力机制数学化为 α = f ( e t , e a ) \alpha = f(\mathbf{e}_t, \mathbf{e}_a) α=f(et,ea)
- 兴趣漂移建模为 h t = AUGRU ( h t − 1 , e t ) \mathbf{h}t = \text{AUGRU}(\mathbf{h}{t-1}, \mathbf{e}_t) ht=AUGRU(ht−1,et)
-
业务价值的飞跃:
- 淘宝:年GMV增长超百亿
- YouTube:观看时长提升40%+
-
技术范式的变革:
静态表征 动态兴趣 实时演化 元宇宙虚拟人
🌟 未来方向:
- 多模态兴趣建模:融合视觉/语音/文本信号
- 因果兴趣推断:区分真实兴趣与曝光偏差
- 联邦兴趣学习:隐私保护下的个性化
正如DIEN论文所述:"Modeling the evolutionary nature of user interests is the key to capturing the dynamic preference patterns" ------ 理解用户兴趣的动态本质,正是推荐系统抓住人心的关键所在。