DeepSeek 前几天发布了 V3.2 的正式版公告。标准版的DeepSeek - V3.2适用于日常场景,而DeepSeek - V3.2 - Speciale 则具备较强的指令跟随、数学证明和逻辑验证能力。

双版本发布,日常场景 VS 专业场景
DeepSeek 这次推出了两个定位不同的版本。
DeepSeek-V3.2:能思考,会用工具,还跑得快
这是面向大多数用户和开发者的模型。官方数据显示,其综合推理能力已达到 GPT-5 水平,仅微弱差距次于 Gemini-3.0-Pro,但是其成本却远低于GPT-5。
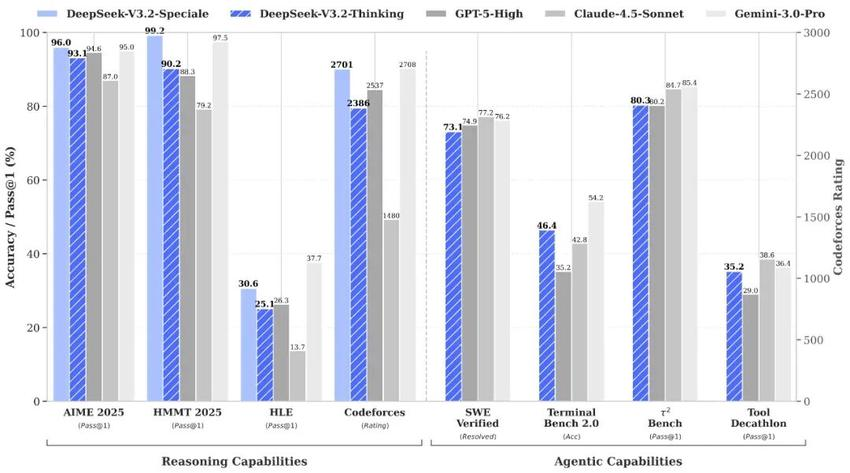
它的核心进化在于平衡与实战:
-
思考融入工具调用(Thinking with Tools):这是 V3.2 最大的杀手锏。以往的模型,要么闷头思考,要么傻傻调用工具。V3.2 打通了这两者,支持在思考模式下调用工具。模型可以先分析问题,决定调用什么工具,根据工具返回的结果继续思考,再进行下一步操作。
-
效率暴增:相比 Kimi-K2-Thinking 等竞品,V3.2 显著降低了输出长度。简单说就是:废话少了,干货多了,响应快了,Token 成本降了。这对于需要大规模部署 Agent(智能体)的企业来说,是实打实的降本增效。
DeepSeek-V3.2-Speciale:为极限难题而生
这是一个不计成本、追求极致智力的版本。它结合了 DeepSeek-Math-V2 的定理证明能力,专门用来搞研究的。
它的战绩足以让整个 AI 圈子侧目
-
ICPC World Finals 2025(国际大学生程序设计竞赛):金牌,水平相当于人类选手 第 2 名。
-
IOI 2025(国际信息学奥林匹克):金牌,位列人类选手 第 10 名。
-
同时斩获 IMO 2025 和 CMO 2025 数学奥赛金牌。
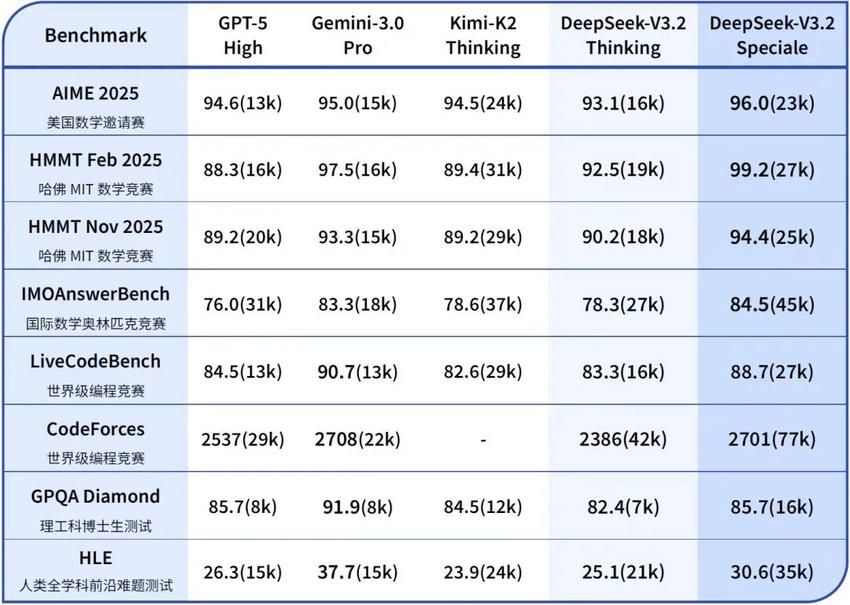
这个版本强,但也贵,因为它消耗的 Token 显著更多,且目前仅供研究,不支持工具调用,也没有针对日常闲聊优化。就像一个按秒计费的顶级数学家,只有在标准版搞不定的时候,才需要请它出山。
DeepSeek V3.2 的正式发布,说明了。
长文本应用成本下降
- 过去,企业想要处理几十万字的法律文档或金融财报,只能依赖昂贵的闭源 API(如 Claude 3 Opus)。DeepSeek v3.2 证明了通过稀疏注意力机制,可以在消费级或中端算力上实现同等效果。这将直接拉低 RAG(检索增强生成)和长文档分析的落地门槛。
"开源打不过闭源"的终结
- 业内一直说"开源模型永远落后闭源模型8个月。"这个结论不好说对不对,但 v3.2 标准版对标 GPT-5,Speciale 版在竞赛中横扫金牌,证明了开源模型在顶级智力任务上已经具备了与闭源巨头(OpenAI, Google)正面硬刚的实力。
算力效率的新标杆
- DeepSeek 再次证明,单纯堆参数、堆显卡不是唯一出路。通过算法优化(DSA)和训练策略调整(两阶段训练:先密集热身,再稀疏训练),可以用更少的算力达到 SOTA(当前最佳)水平。这给那些算力受限的研究机构和企业指明了一条新路。
本地部署实战指南
对于想要在本地运行 DeepSeek V3.2 的用户,或者希望通过 API 集成新特性的工程师来说,Python 环境配置是一个关卡。
无论是本地部署推理(依赖 PyTorch、Transformers),还是调用 API 进行复杂的"思考+工具"交互,都离不开 Python 生态。
特别是 V3.2 引入了新的 API 交互逻辑:在多轮对话中,需要手动处理 reasoning_content(思维链)。例如,在同一个问题内需要回传思维链让模型继续思考,但在开启新问题时必须删除旧的思维链。这种精细的逻辑控制,必须通过 Python 脚本来实现。
为了解决这些脏活累活,我强烈推荐使用 ServBay。虽然它自称为 Web 开发工具,但它实际上是一个全能的开发环境管理平台。
ServBay 的核心优势:
-
一键安装 Python :不需要去官网下载安装包,也不用折腾 Homebrew,ServBay 可以一键安装最新版的 Python,完美适配 DeepSeek V3.2 的依赖需求。
-
环境互不干扰:ServBay 的环境是独立的,不会污染系统文件。可以在里面随意安装 PyTorch、Transformers 等大型库,玩坏了重置即可,安全无痛。
-
多版本共存:如果你的旧项目还在用 Python 3.9,而 DeepSeek 推荐更新的版本,ServBay 支持同时运行多个环境,互不打架。
调用演示,体验 V3.2
由于 V3.2 的 API 调用逻辑有更新,以下是一段基于 Python 的标准调用示例。
python
from openai import OpenAI
import os
# 建议将 Key 放入环境变量,或者直接替换
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com"
)
messages = [
{"role": "user", "content": "帮我计算斐波那契数列第10位,并解释原理"}
]
# 发起请求
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
stream=True
)
print("DeepSeek V3.2 正在思考并回答...\n")
reasoning_content = ""
content = ""
for chunk in response:
delta = chunk.choices[0].delta
# 获取思考过程
current_reasoning = getattr(delta, 'reasoning_content', None)
if current_reasoning:
reasoning_content += current_reasoning
print(current_reasoning, end="", flush=True)
# 获取最终回答
if delta.content:
content += delta.content
print(delta.content, end="", flush=True)
print("\n")通过 ServBay 快速搞定 Python 环境,就能跳过繁琐的配置环节,直接把 DeepSeek V3.2 的强大能力接入到工作流中。无论是用于日常提效的标准版,还是用于攻克难题的 Speciale 版,都可以上手玩一下。