在电商平台中,基于用户的协同过滤推荐算法是一种常见的推荐系统方法。它通过分析用户之间的相似性来推荐商品。以下是一个简单的实现思路和示例代码,使用Java语言。
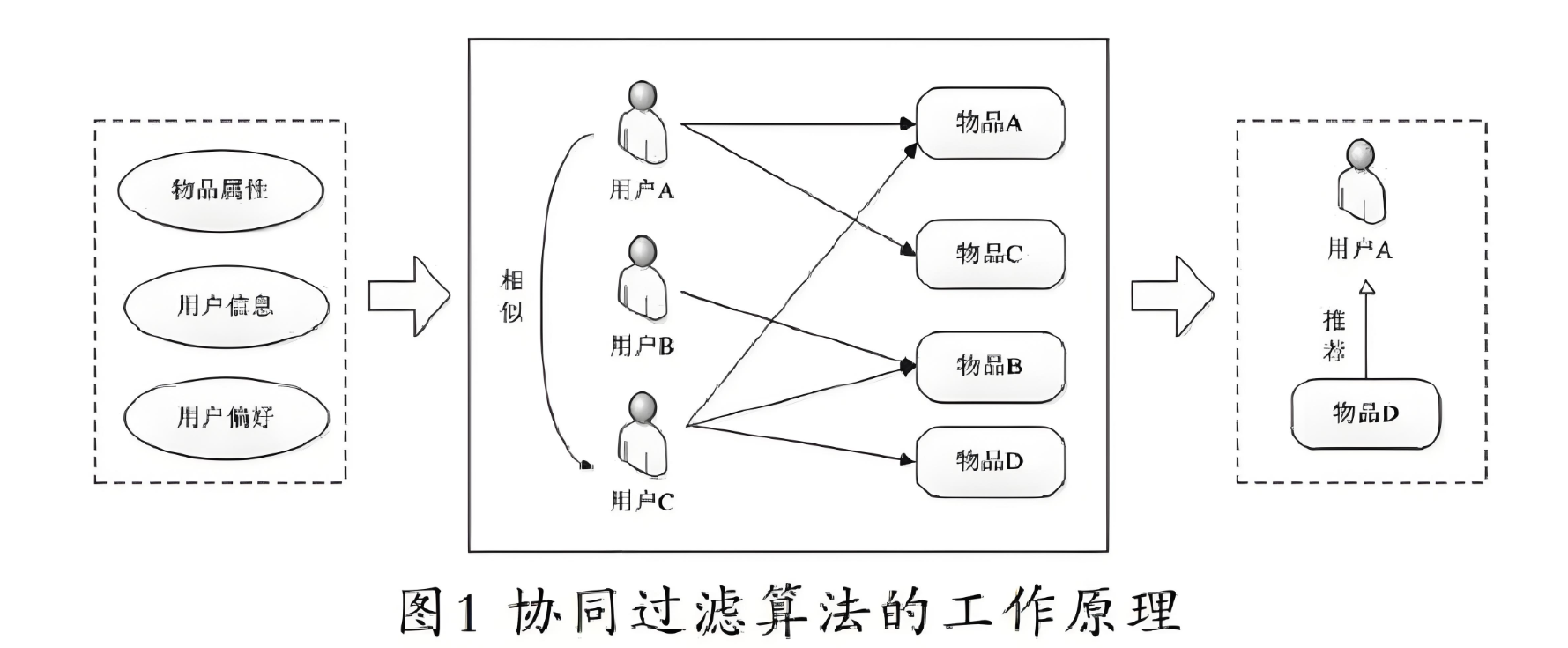
实现思路
- 数据准备:收集用户的评分数据,通常以用户-商品评分矩阵的形式存储。
- 计算相似度:使用余弦相似度或皮尔逊相关系数等方法计算用户之间的相似度。
- 生成推荐:根据相似用户的评分,预测目标用户对未评分商品的评分,并进行推荐。
1. 算法核心思想
基于用户的协同过滤通过以下步骤工作:
-
计算用户之间的相似度
-
找到与目标用户最相似的K个用户
-
根据这些相似用户的喜好预测目标用户可能喜欢的商品
-
推荐预测评分最高的N个商品
2.Java实现代码
javascript
import java.util.*;
public class UserBasedCF {
// 用户-商品评分矩阵
private Map<Integer, Map<Integer, Double>> userItemRatingMatrix;
// 用户相似度矩阵
private Map<Integer, Map<Integer, Double>> userSimilarityMatrix;
// 商品-用户倒排表
private Map<Integer, Set<Integer>> itemUserInverseTable;
public UserBasedCF() {
userItemRatingMatrix = new HashMap<>();
userSimilarityMatrix = new HashMap<>();
itemUserInverseTable = new HashMap<>();
}
/**
* 添加用户评分数据
* @param userId 用户ID
* @param itemId 商品ID
* @param rating 评分
*/
public void addRating(int userId, int itemId, double rating) {
// 添加到用户-商品矩阵
userItemRatingMatrix.putIfAbsent(userId, new HashMap<>());
userItemRatingMatrix.get(userId).put(itemId, rating);
// 添加到商品-用户倒排表
itemUserInverseTable.putIfAbsent(itemId, new HashSet<>());
itemUserInverseTable.get(itemId).add(userId);
}
/**
* 计算用户之间的相似度(使用皮尔逊相关系数)
*/
public void calculateUserSimilarities() {
// 获取所有用户列表
Set<Integer> users = userItemRatingMatrix.keySet();
for (int u1 : users) {
userSimilarityMatrix.putIfAbsent(u1, new HashMap<>());
Map<Integer, Double> u1Ratings = userItemRatingMatrix.get(u1);
for (int u2 : users) {
if (u1 == u2) continue;
Map<Integer, Double> u2Ratings = userItemRatingMatrix.get(u2);
// 计算两个用户的共同评分商品
Set<Integer> commonItems = new HashSet<>(u1Ratings.keySet());
commonItems.retainAll(u2Ratings.keySet());
if (commonItems.size() < 2) {
// 共同评分商品太少,相似度为0
userSimilarityMatrix.get(u1).put(u2, 0.0);
continue;
}
// 计算皮尔逊相关系数
double sum1 = 0, sum2 = 0;
double sum1Sq = 0, sum2Sq = 0;
double pSum = 0;
for (int item : commonItems) {
double r1 = u1Ratings.get(item);
double r2 = u2Ratings.get(item);
sum1 += r1;
sum2 += r2;
sum1Sq += Math.pow(r1, 2);
sum2Sq += Math.pow(r2, 2);
pSum += r1 * r2;
}
int n = commonItems.size();
double num = pSum - (sum1 * sum2 / n);
double den = Math.sqrt((sum1Sq - Math.pow(sum1, 2) / n) *
(sum2Sq - Math.pow(sum2, 2) / n));
double sim = (den == 0) ? 0 : num / den;
userSimilarityMatrix.get(u1).put(u2, sim);
}
}
}
/**
* 为目标用户推荐商品
* @param userId 目标用户ID
* @param k 相似用户数量
* @param n 推荐商品数量
* @return 推荐商品ID列表
*/
public List<Integer> recommendItems(int userId, int k, int n) {
if (!userItemRatingMatrix.containsKey(userId)) {
return Collections.emptyList();
}
// 获取目标用户已评分的商品
Set<Integer> ratedItems = userItemRatingMatrix.get(userId).keySet();
// 获取相似用户并按相似度排序
List<Map.Entry<Integer, Double>> similarUsers = new ArrayList<>(
userSimilarityMatrix.get(userId).entrySet());
similarUsers.sort((a, b) -> b.getValue().compareTo(a.getValue()));
// 取前k个相似用户
if (similarUsers.size() > k) {
similarUsers = similarUsers.subList(0, k);
}
// 计算推荐商品的预测评分
Map<Integer, Double> itemPredictions = new HashMap<>();
for (Map.Entry<Integer, Double> entry : similarUsers) {
int similarUser = entry.getKey();
double similarity = entry.getValue();
// 获取相似用户评过但目标用户未评的商品
Map<Integer, Double> similarUserRatings = userItemRatingMatrix.get(similarUser);
for (Map.Entry<Integer, Double> ratingEntry : similarUserRatings.entrySet()) {
int item = ratingEntry.getKey();
if (!ratedItems.contains(item)) {
double rating = ratingEntry.getValue();
// 加权评分
itemPredictions.merge(item, similarity * rating, Double::sum);
}
}
}
// 对预测评分进行归一化处理
for (Map.Entry<Integer, Double> entry : similarUsers) {
int similarUser = entry.getKey();
double similarity = entry.getValue();
Map<Integer, Double> similarUserRatings = userItemRatingMatrix.get(similarUser);
for (int item : itemPredictions.keySet()) {
if (similarUserRatings.containsKey(item)) {
itemPredictions.put(item,
itemPredictions.get(item) / Math.abs(similarity));
}
}
}
// 按预测评分排序并返回前n个商品
List<Map.Entry<Integer, Double>> sortedItems = new ArrayList<>(itemPredictions.entrySet());
sortedItems.sort((a, b) -> b.getValue().compareTo(a.getValue()));
List<Integer> recommendations = new ArrayList<>();
for (int i = 0; i < Math.min(n, sortedItems.size()); i++) {
recommendations.add(sortedItems.get(i).getKey());
}
return recommendations;
}
// 测试代码
public static void main(String[] args) {
UserBasedCF recommender = new UserBasedCF();
// 模拟用户评分数据
recommender.addRating(1, 101, 5.0);
recommender.addRating(1, 102, 3.0);
recommender.addRating(1, 103, 2.5);
recommender.addRating(2, 101, 2.0);
recommender.addRating(2, 102, 2.5);
recommender.addRating(2, 103, 5.0);
recommender.addRating(2, 104, 2.0);
recommender.addRating(3, 101, 2.5);
recommender.addRating(3, 104, 4.0);
recommender.addRating(3, 105, 4.5);
recommender.addRating(3, 107, 5.0);
recommender.addRating(4, 101, 5.0);
recommender.addRating(4, 103, 3.0);
recommender.addRating(4, 104, 4.5);
recommender.addRating(4, 106, 4.0);
recommender.addRating(4, 107, 2.0);
// 计算用户相似度
recommender.calculateUserSimilarities();
// 为用户1推荐2个商品
List<Integer> recommendations = recommender.recommendItems(1, 2, 2);
System.out.println("为用户1推荐的商品: " + recommendations);
}
}3. 代码说明
-
数据结构:
-
userItemRatingMatrix: 存储用户对商品的评分 -
userSimilarityMatrix: 存储用户之间的相似度 -
itemUserInverseTable: 商品到用户的倒排表,加速计算
-
-
核心方法:
-
addRating(): 添加用户评分数据 -
calculateUserSimilarities(): 计算用户相似度(使用皮尔逊相关系数) -
recommendItems(): 为目标用户生成推荐列表
-
-
推荐过程:
-
找到与目标用户最相似的K个用户
-
收集这些相似用户评价过但目标用户未评价的商品
-
计算这些商品的预测评分(加权平均)
-
返回评分最高的N个商品作为推荐
-
4. 实际应用中的优化建议
-
数据稀疏性问题:
-
实现降维技术(如SVD)
-
使用混合推荐方法(结合基于内容的推荐)
-
-
性能优化:
-
使用稀疏矩阵存储数据
-
实现增量更新机制,避免全量计算
-
使用MapReduce或Spark进行分布式计算
-
-
冷启动问题:
-
对于新用户,可以使用热门商品推荐
-
对于新商品,可以使用基于内容的推荐
-
-
业务适配:
-
考虑时间衰减因素(最近的评分权重更高)
-
加入业务规则过滤(如库存、价格区间等)
-