文章目录
- [🏳️🌈 1. 导入模块](#🏳️🌈 1. 导入模块)
- [🏳️🌈 2. Pandas数据处理](#🏳️🌈 2. Pandas数据处理)
-
- [2.1 读取数据](#2.1 读取数据)
- [2.2 数据信息](#2.2 数据信息)
- [2.3 数据去重](#2.3 数据去重)
- [2.4 订单日期处理提取年份](#2.4 订单日期处理提取年份)
- [2.5 产品名称处理](#2.5 产品名称处理)
- [🏳️🌈 3. Pyecharts数据可视化](#🏳️🌈 3. Pyecharts数据可视化)
-
- [3.1 每年销售额和利润分布](#3.1 每年销售额和利润分布)
- [3.2 各地区销售额和利润分布](#3.2 各地区销售额和利润分布)
- [3.3 各省订单量分布](#3.3 各省订单量分布)
- [3.4 各省销售额分布](#3.4 各省销售额分布)
- [3.5 各类别产品订单量](#3.5 各类别产品订单量)
- [3.6 客户类别占比](#3.6 客户类别占比)
- [3.7 Apriori算法关联分析](#3.7 Apriori算法关联分析)
- [3.8 帕累托分析](#3.8 帕累托分析)
- [🏳️🌈 4. 可视化项目源码+数据](#🏳️🌈 4. 可视化项目源码+数据)
大家好,我是 👉 【Python当打之年(点击跳转)】
本期我们利用Python分析「超市销售数据集」,看看:每年销售额和利润分布、各地区销售额和利润分布、各省订单量分布、各省销售额分布、各类别产品订单量、客户类别占比等等,希望对大家有所帮助,如有疑问或者需要改进的地方可以联系小编。
涉及到的库:
- Pandas--- 数据处理
- Pyecharts--- 数据可视化
🏳️🌈 1. 导入模块
python
import pandas as pd
from pyecharts.charts import *
from pyecharts import options as opts
import warnings
warnings.filterwarnings('ignore')🏳️🌈 2. Pandas数据处理
2.1 读取数据
python
df = pd.read_excel('超市销售数据.xlsx')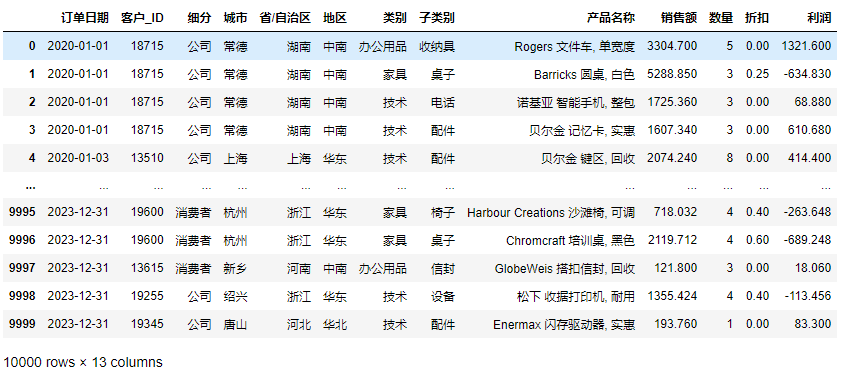
2.2 数据信息
python
df.info()
2.3 数据去重
python
df = df.drop_duplicates()2.4 订单日期处理提取年份
python
df['年'] = df['订单日期'].dt.year2.5 产品名称处理
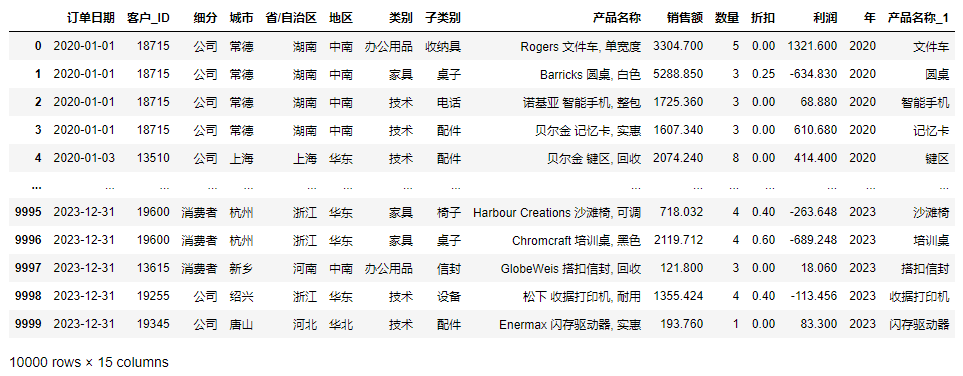
🏳️🌈 3. Pyecharts数据可视化
3.1 每年销售额和利润分布
python
defget_chart1():
chart = (
Bar()
.add_xaxis(x_data)
.add_yaxis('销售额', y_data1,gap='5%',label_opts=opts.LabelOpts(formatter='{c}万'))
.add_yaxis('利润', y_data2,gap='5%',label_opts=opts.LabelOpts(formatter='{c}万'))
.set_global_opts(
title_opts=opts.TitleOpts(
title='1-每年销售额和利润分布',
subtitle=subtitle,
pos_top='2%',
pos_left='center'
),
legend_opts=opts.LegendOpts(pos_top='15%')
)
)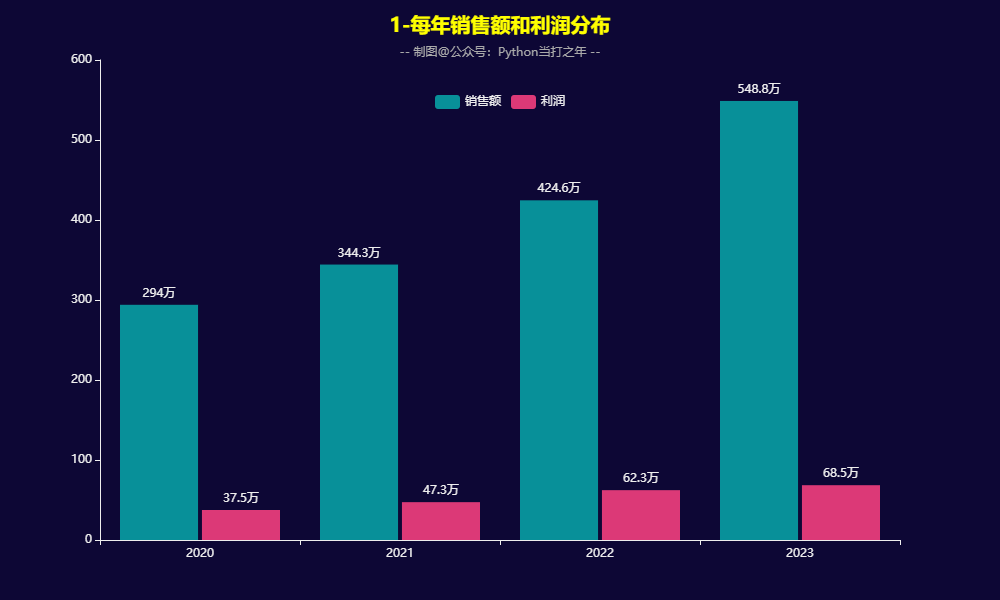
- 销售额和利润均呈现逐年增长的趋势。
3.2 各地区销售额和利润分布
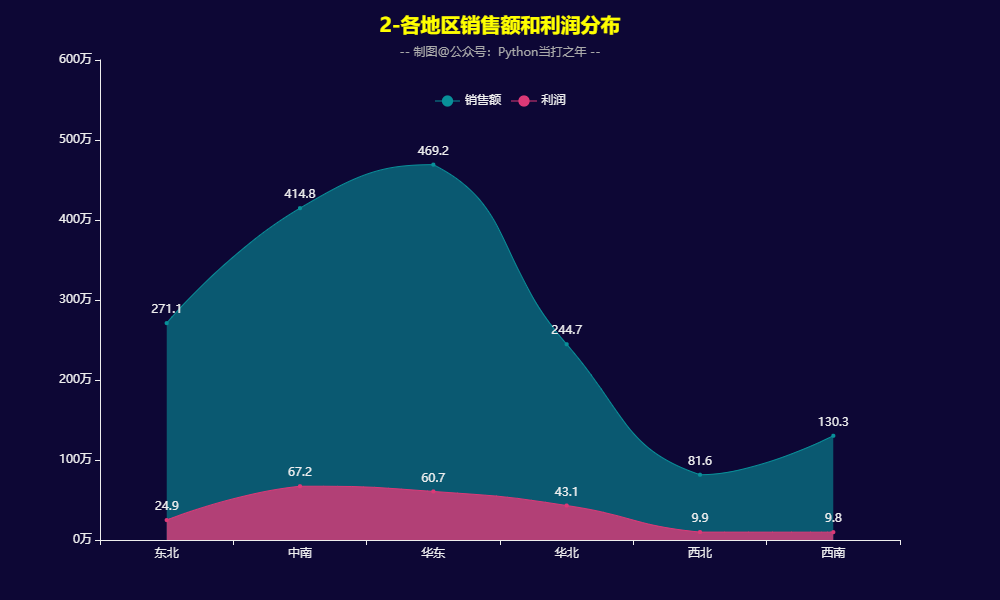
- 华东大区的销售额最高,反映出当地消费能力较高,中南和东北地区紧随其后,利润方面来看,中南地区和华东地区的利润要远高于其他地区。
3.3 各省订单量分布

- 沿海地区的订单量要明显高于内地,尤其是广东、山东、江苏、辽宁。
3.4 各省销售额分布

3.5 各类别产品订单量
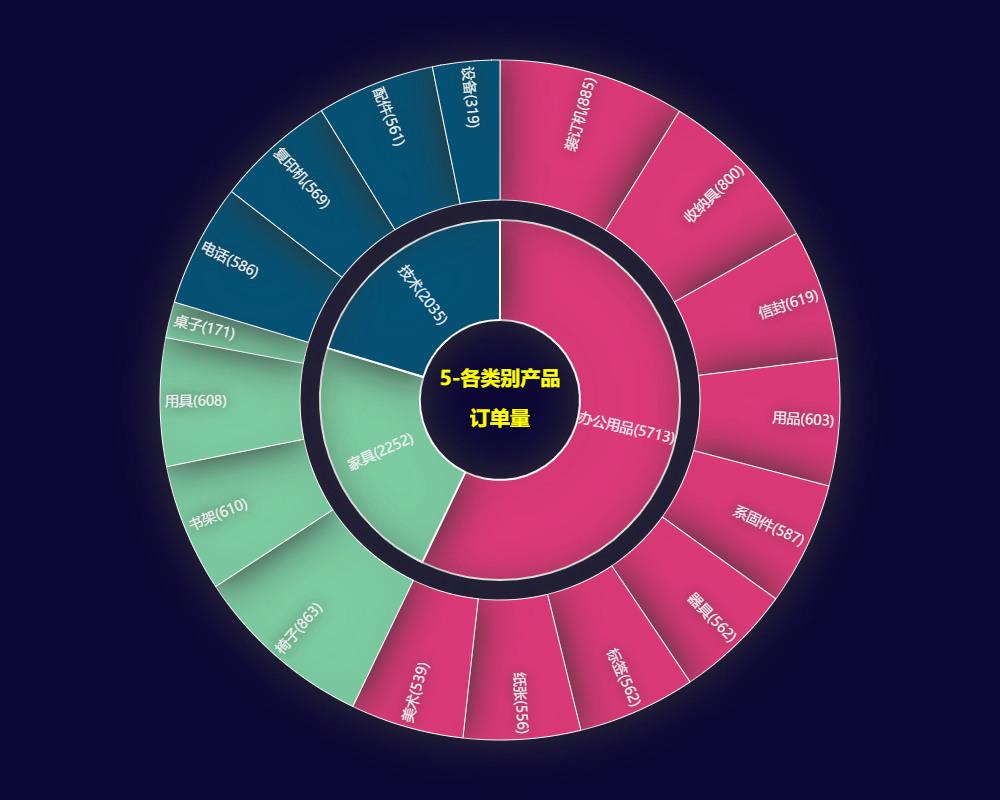
- 办公用品类商品需求量最大,占比超过了50%,技术类和家具类各占20%左右。
3.6 客户类别占比
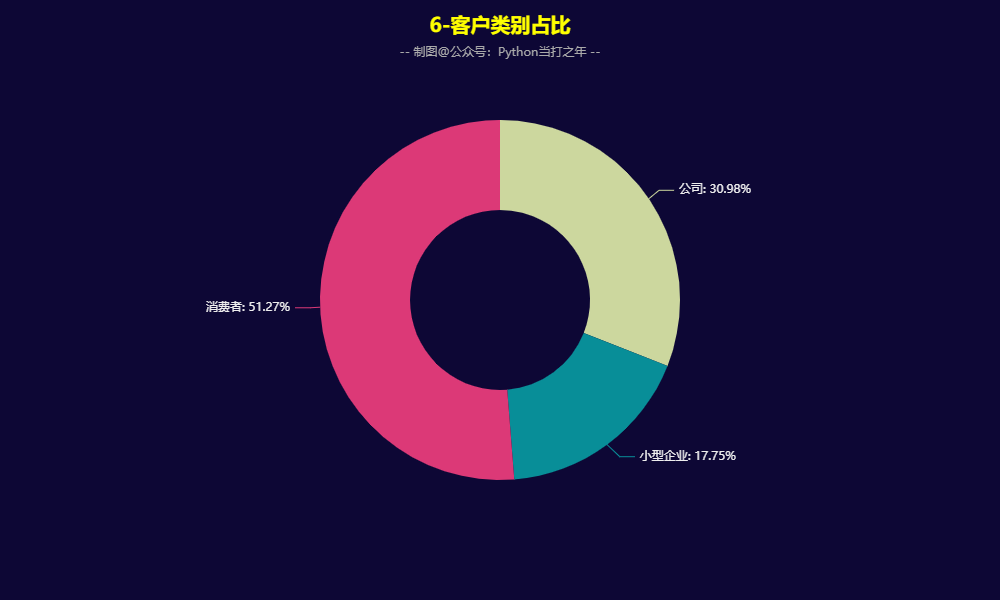
- 客户类别以个体消费者为主,其次是公司和小型企业。
3.7 Apriori算法关联分析
python
# 转换为算法可接受模型(布尔值)
te = TransactionEncoder()
d_data = te.fit(data_am).transform(data_am)
df_t = pd.DataFrame(d_data,columns=te.columns_)
# 设置支持度求频繁项集
frequent_itemsets = apriori(df_t,min_support=0.04,use_colnames= True)
rules = association_rules(frequent_itemsets,metric = 'confidence',min_threshold = 0.1)
# 设置最小提升度, 一般认为提升度大于1的关联规则才有商业价值
rules = rules.drop(rules[rules.lift <1].index)
# 设置标题索引并打印结果
rules.rename(columns = {'antecedents':'from','consequents':'to','support':'sup','confidence':'conf'},inplace = True)
rules = rules[['from','to','sup','conf','lift']].sort_values('sup',ascending=False).reset_index(drop=True)结果:
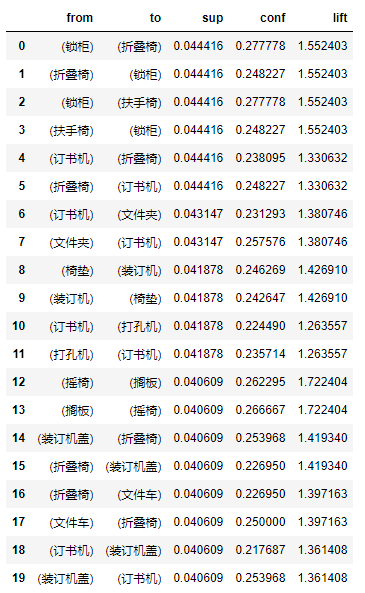
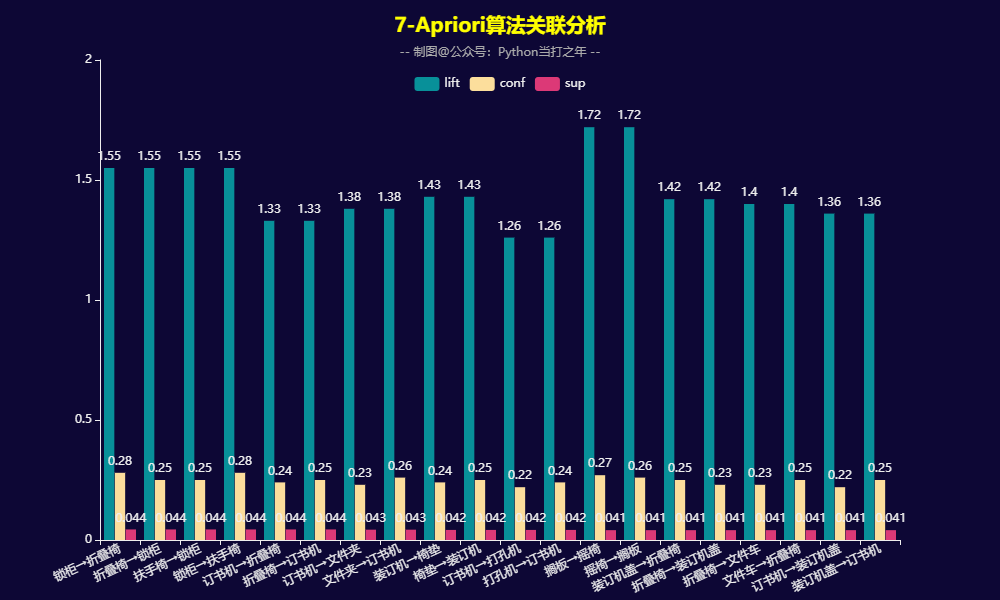
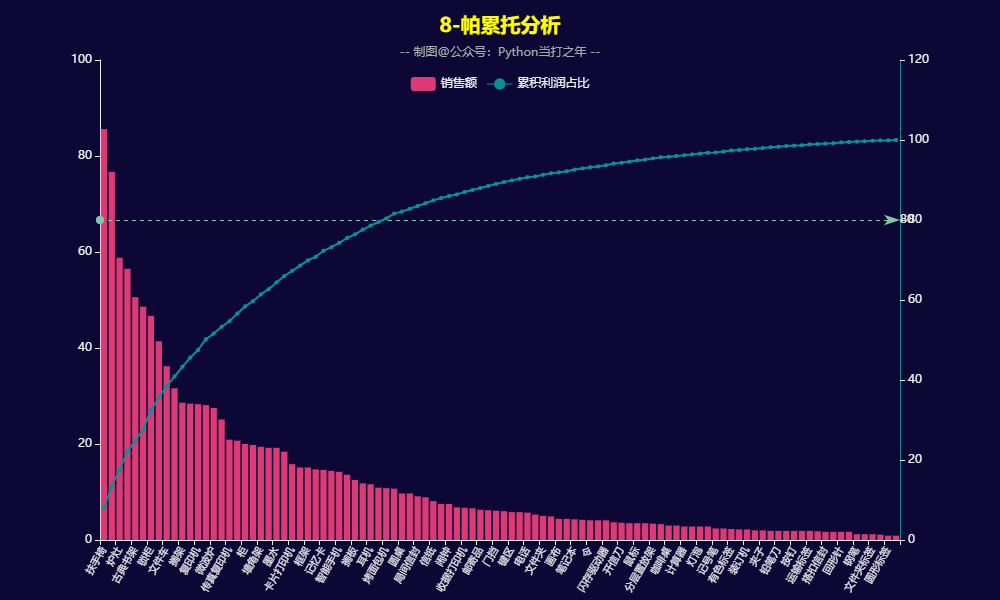
3.8 帕累托分析
帕累托分析模型(Pareto Analysis),又称80/20法则、ABC分析法或主次因素分析法,是一种基于"关键少数与次要多数"原理的决策工具,用于识别和优先处理对结果影响最大的关键因素。
python
defget_chart8():
bar = (
Bar()
.add_xaxis(x_data)
.add_yaxis("销售额", y_data1,itemstyle_opts=opts.ItemStyleOpts(color=range_color[-1]),
label_opts=opts.LabelOpts(is_show=False),)
.extend_axis(
yaxis=opts.AxisOpts(
max_=120,
)
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='8-帕累托分析',
subtitle=subtitle,
pos_top='2%',
pos_left='center',
),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=60,font_size=10)),
legend_opts=opts.LegendOpts(pos_top='12%')
)
)
line = (
Line()
.add_xaxis(x_data)
.add_yaxis(
"累积利润占比",
y_data2,
z=10,
yaxis_index=1,
label_opts=opts.LabelOpts(is_show=False),
)
)
🏳️🌈 4. 可视化项目源码+数据
以上就是本期为大家整理的全部内容了,赶快练习起来吧,原创不易,喜欢的朋友可以点赞、收藏 也可以分享 (注明出处)让更多人知道。