在数字化转型加速推进的背景下,数据生成规则作为数据工程的核心技术要素,其系统化应用已成为企业构建智能数据生态的关键路径。通过可配置的规则引擎实现数据的智能化构建。本文将结合ETLCloud平台的演示数据生成规则的使用技巧。
使用数据生成器规则中的生成6位随机数来演示
1.数据生成器
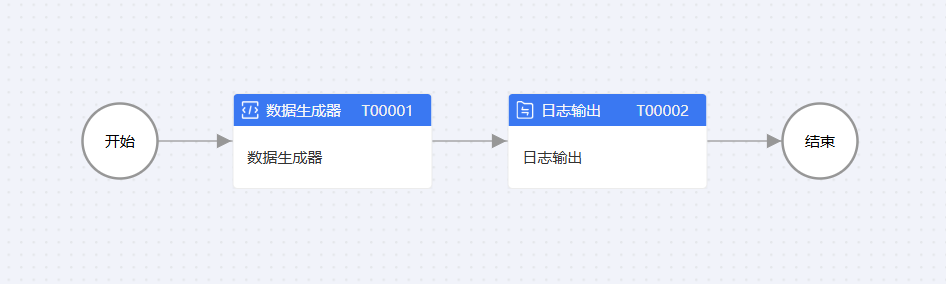
使用数据生成器生成3条数据
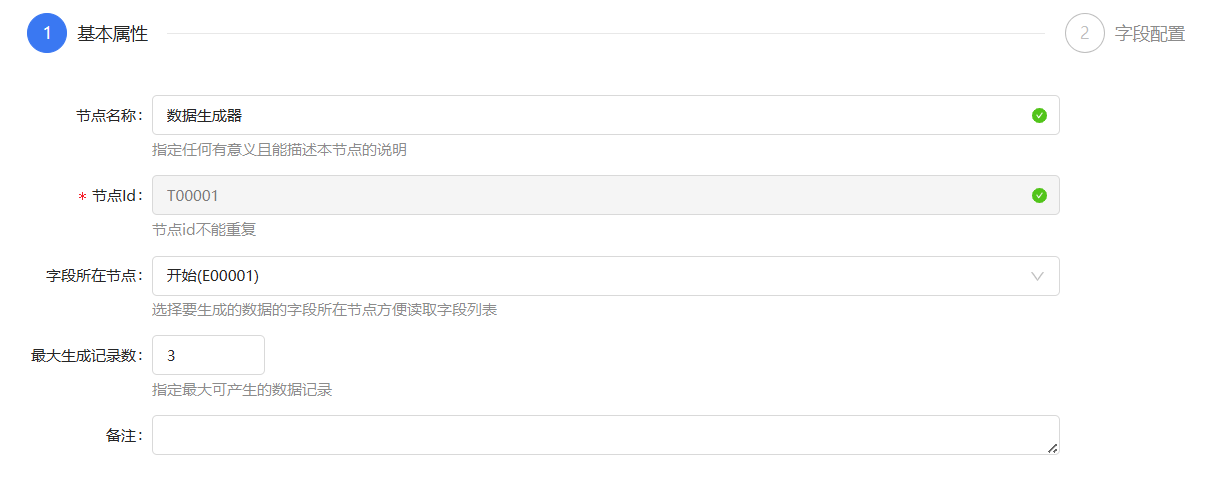
设置字段值id,并用数据生成规则中的生成6位随机数对他进行赋值
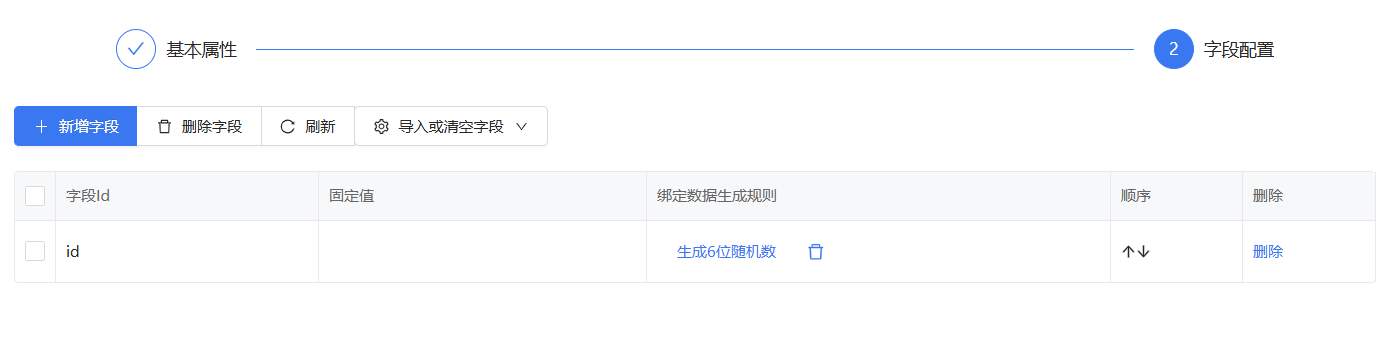
运行成功后查看日志,生成的3个id均为随机数

2.库表输入
以下是库表输入的场景
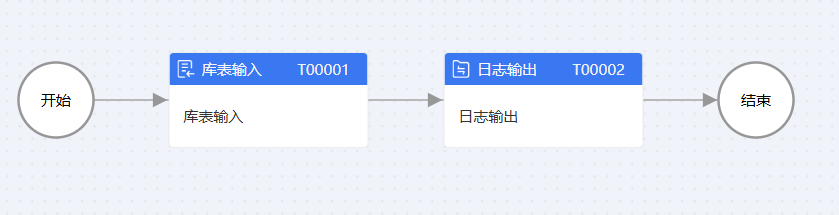
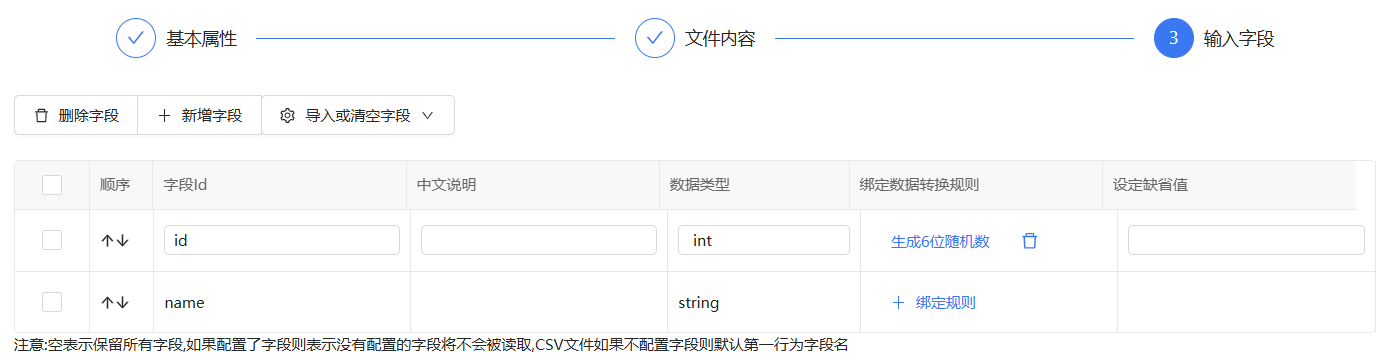
在第三步输入字段可以配置数据生成规则
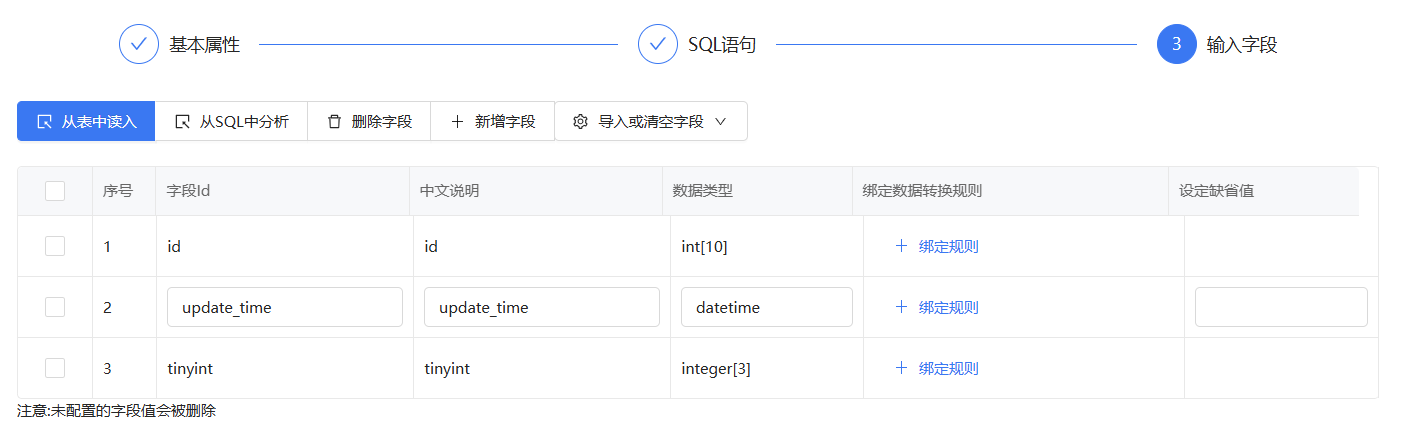
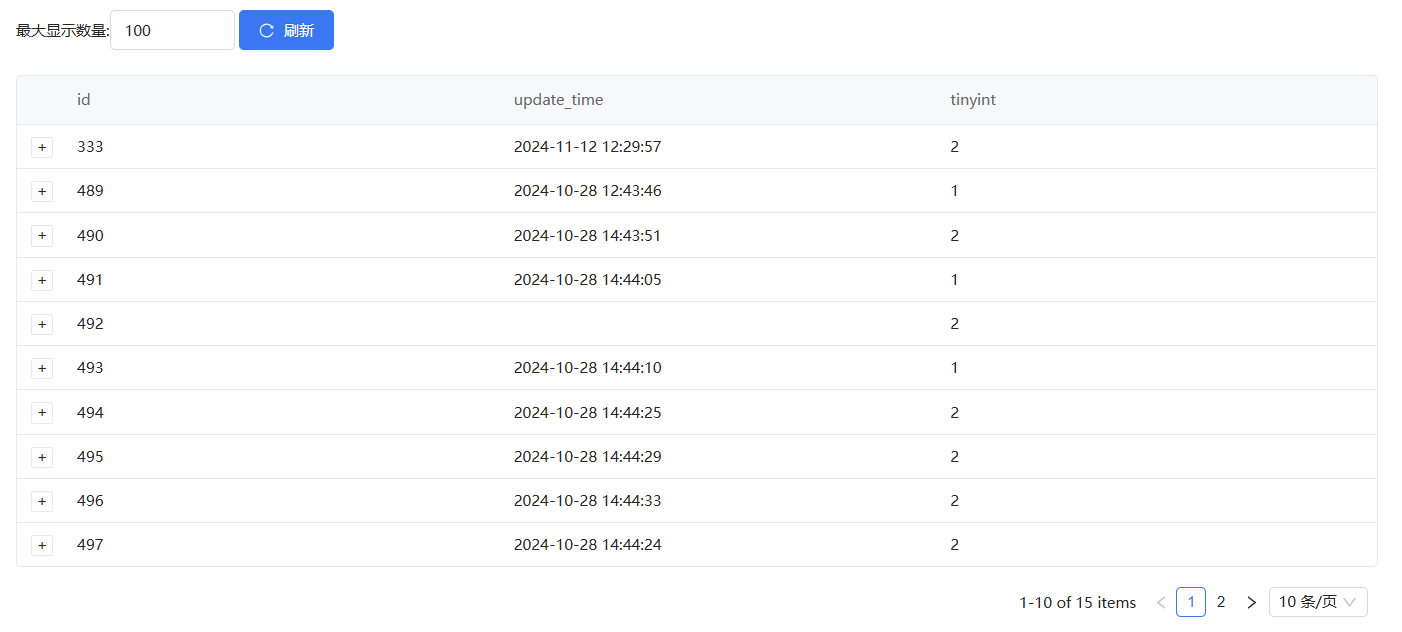
下面是没有配置生成6位随机数的数据
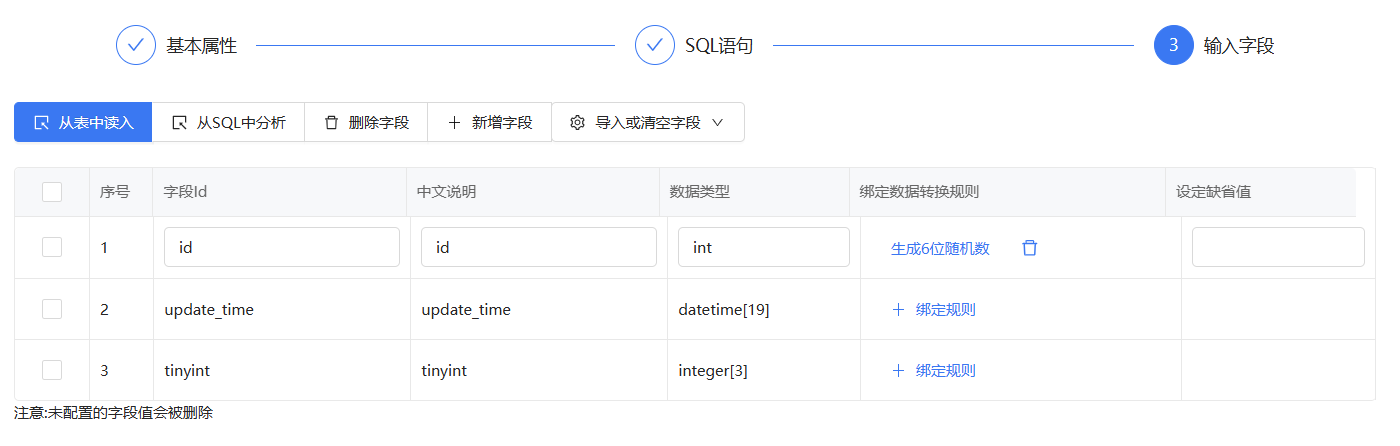
把id字段绑定生成6位随机数
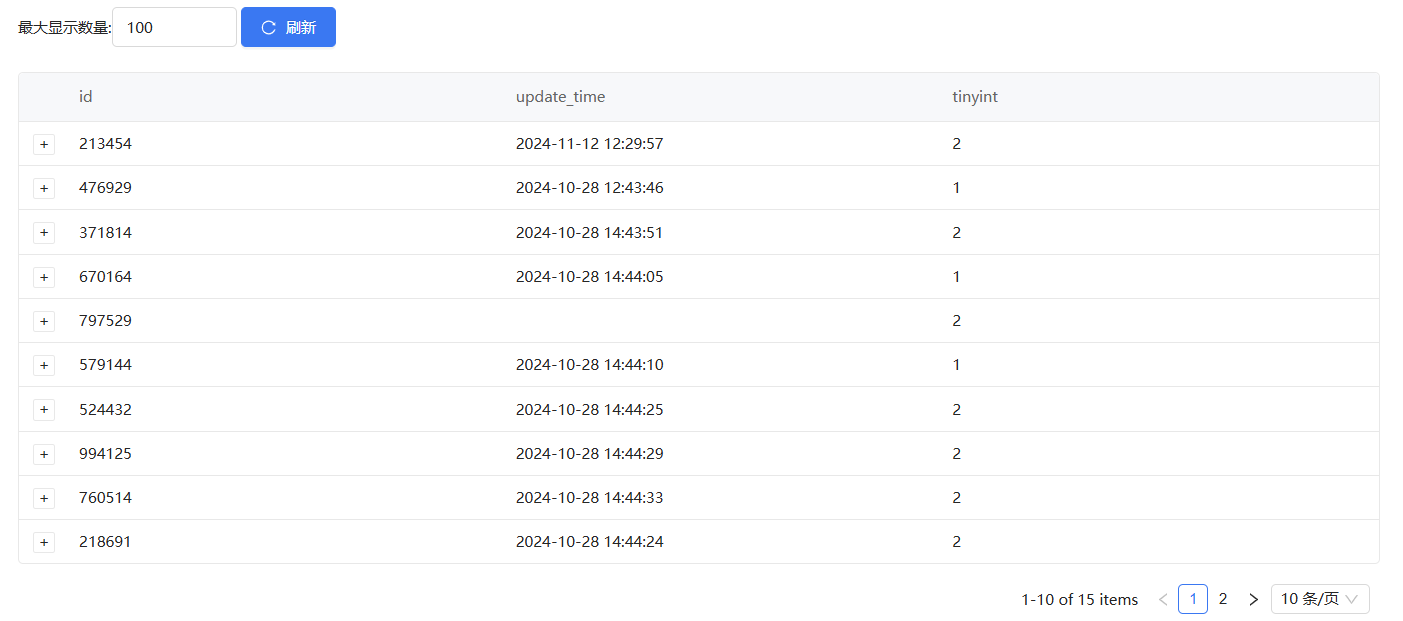
查看绑定生成6位随机数后的结果
3.库表输出
搭配数据生成器来演示
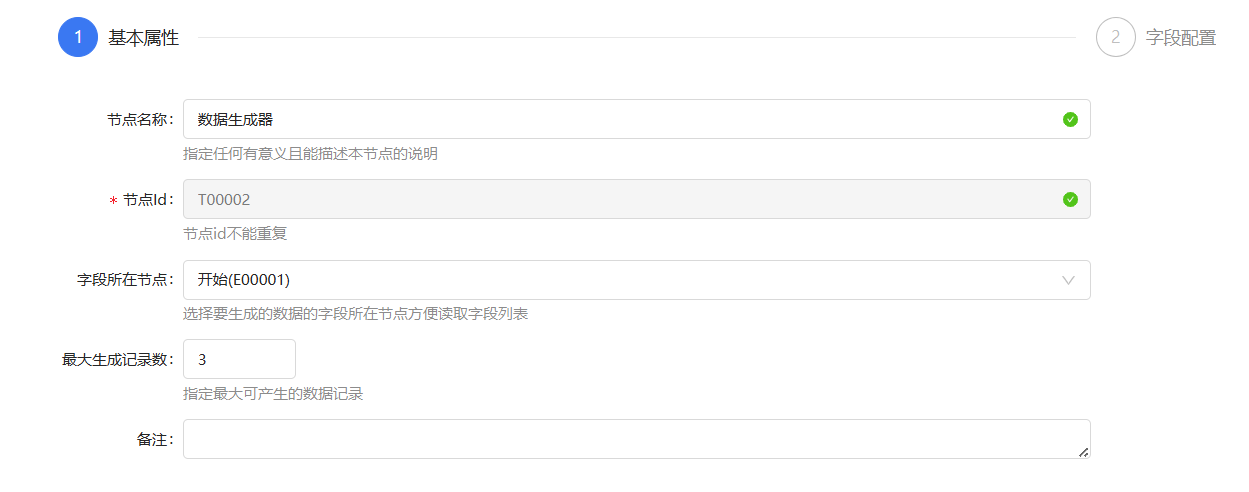
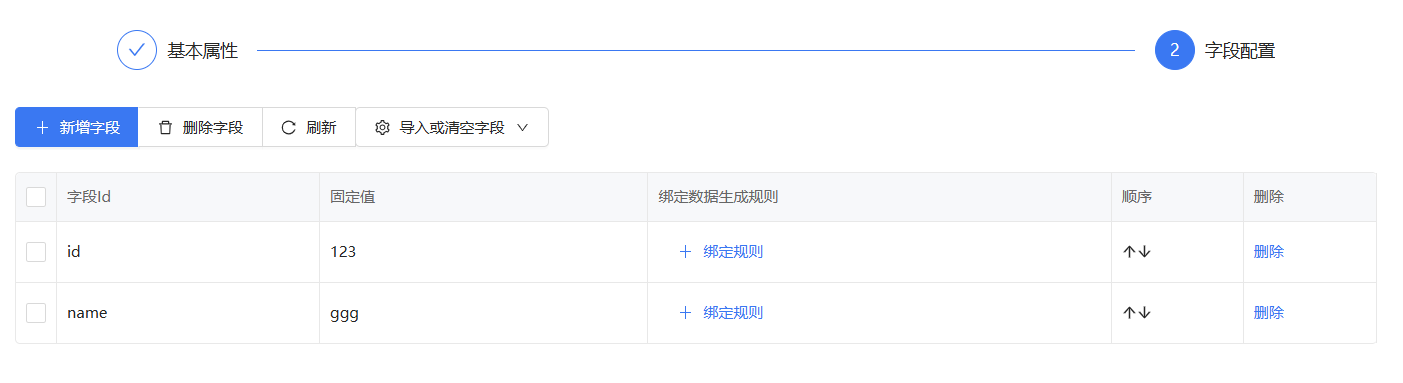
使用数据生成器生成3条如下数据
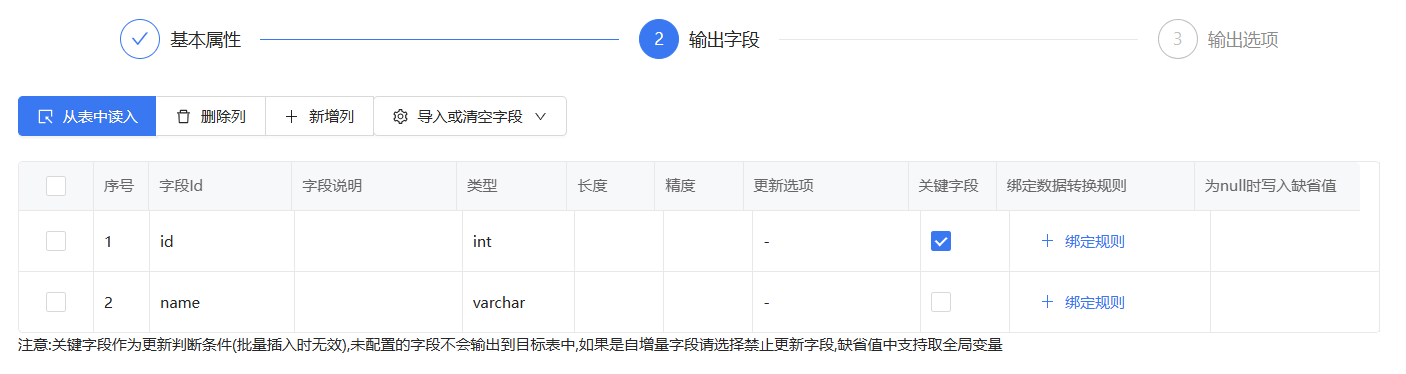
库表输出的配置,把id设为主键
运行流程,流程显示成功插入3条数据
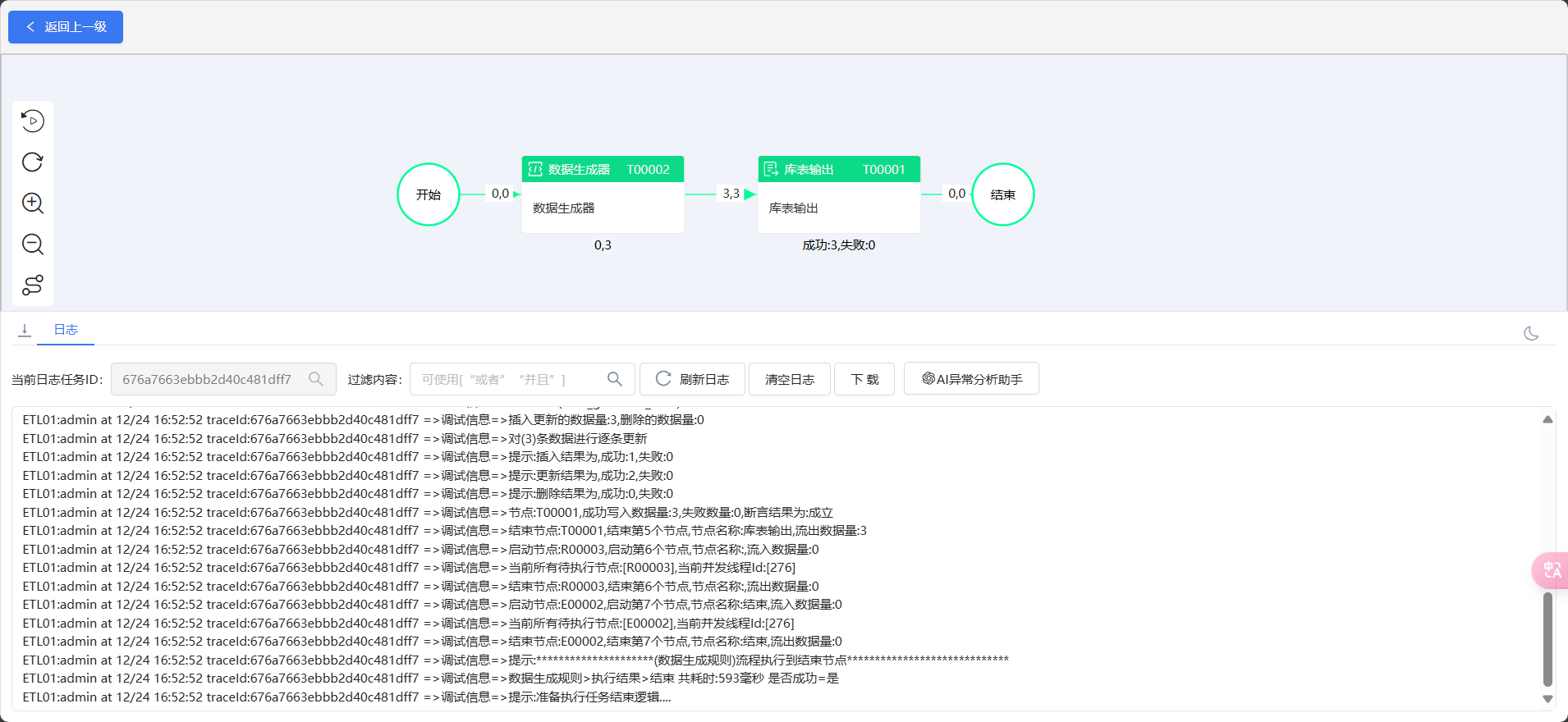
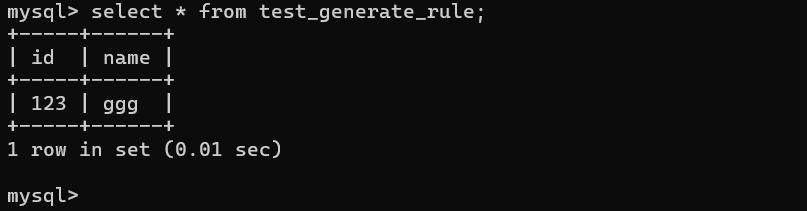
但实际上数据库只插入了1条,因为id为主键不可重复
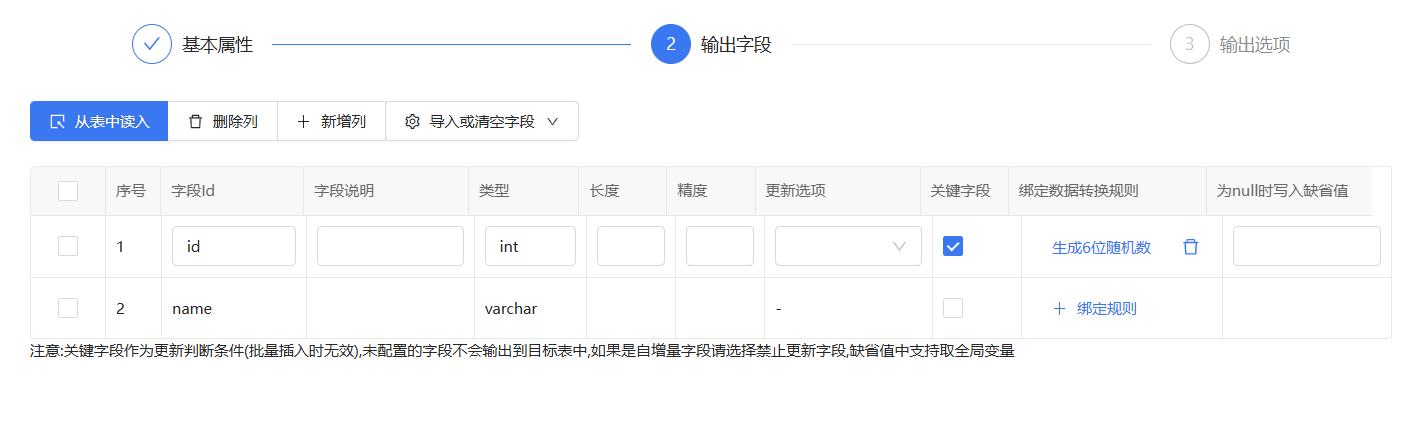
在库表输出中的输出字段里讲id配置上生成6位随机数,再次运行流程查看效果
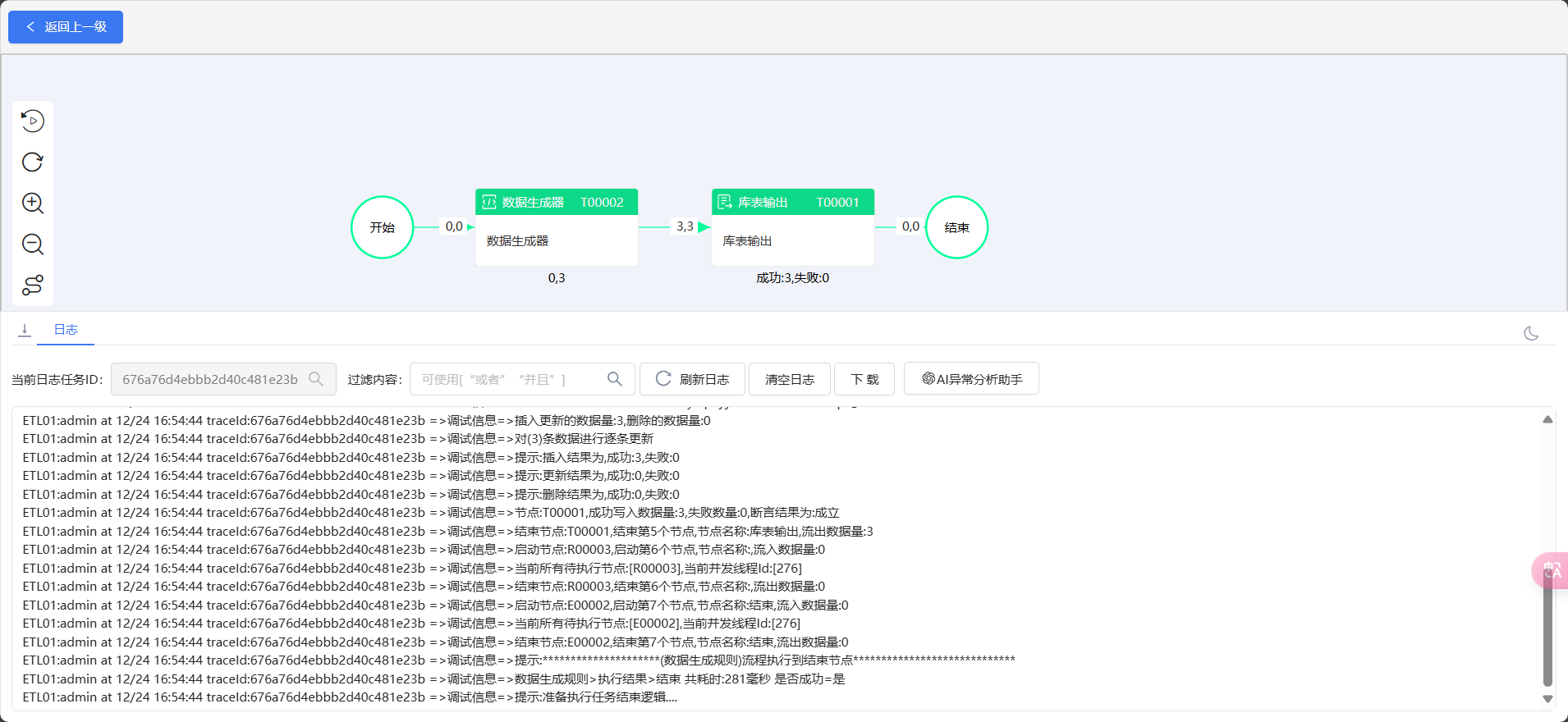
可以发现数据已经成功插入了
4.数据清洗转换
搭配库表输入演示

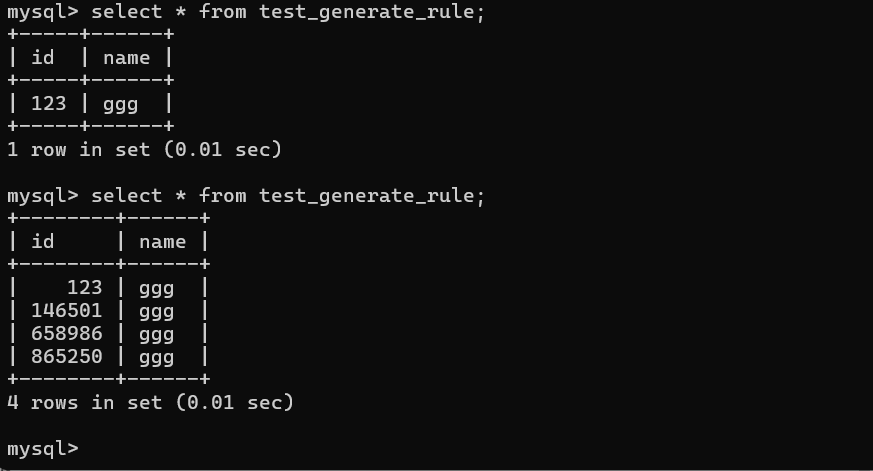
这是库表输入的数据
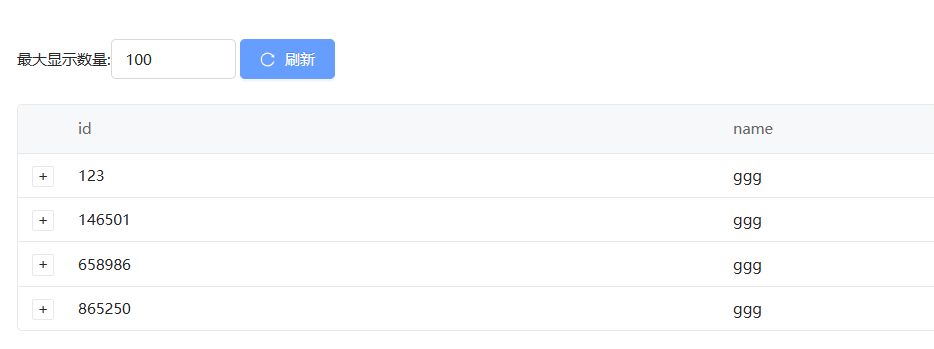
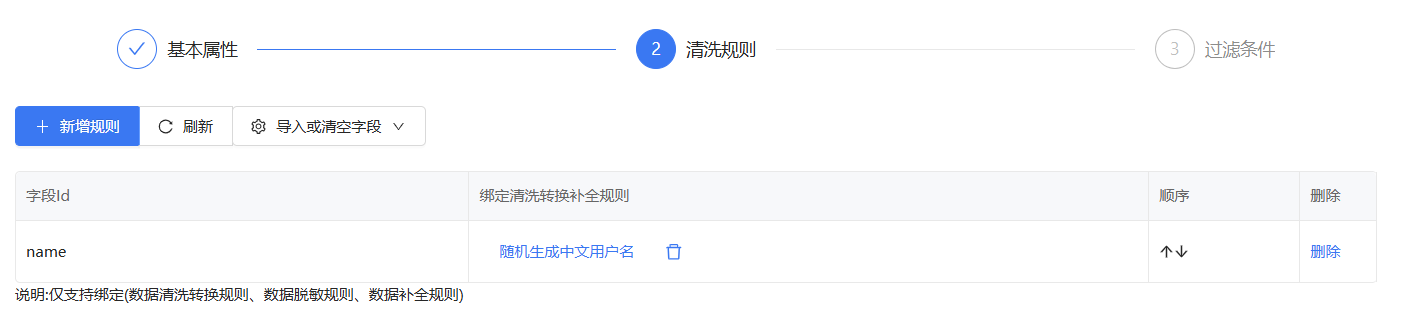
绑定数据生成规则中的随机生成中文用户名
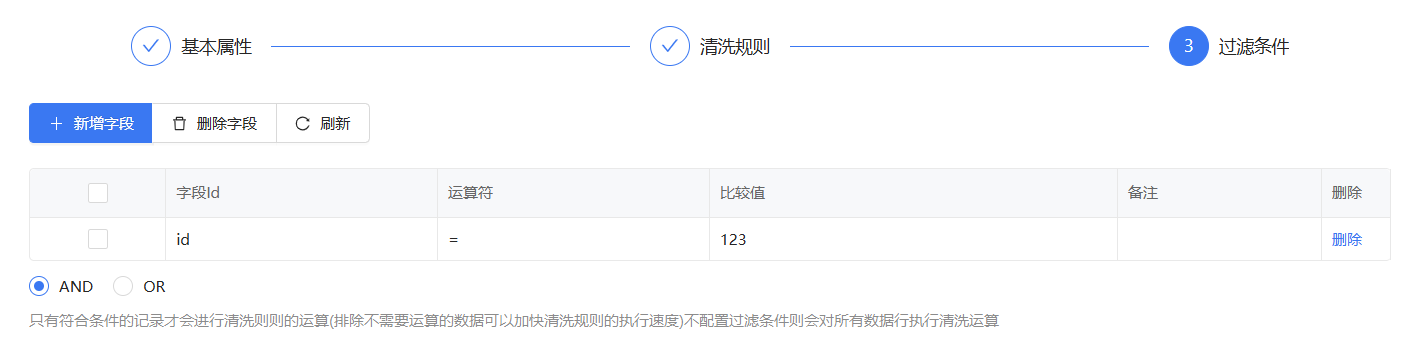
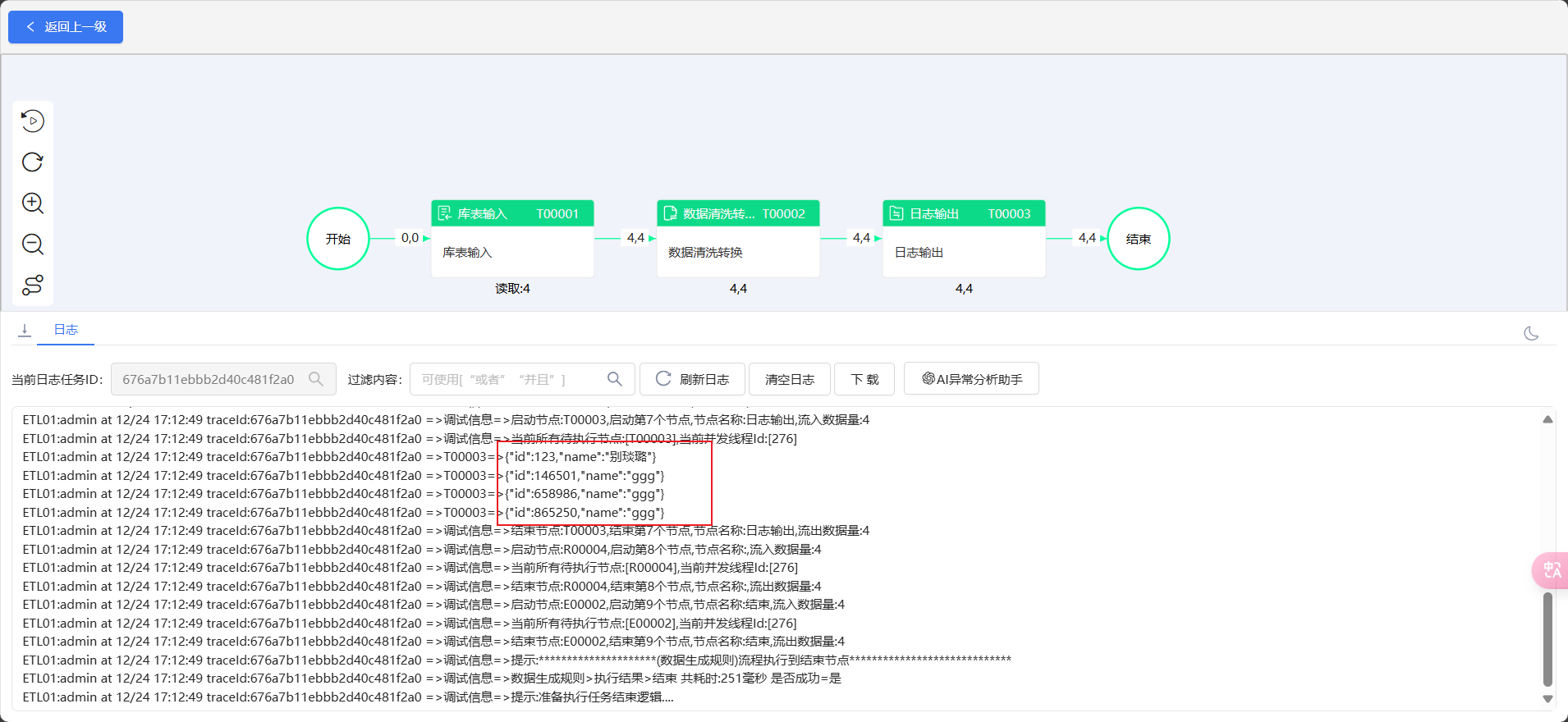
配置过滤条件只让id为123的name生成随机中文用户名
运行流程查看结果
5.文本文件读取
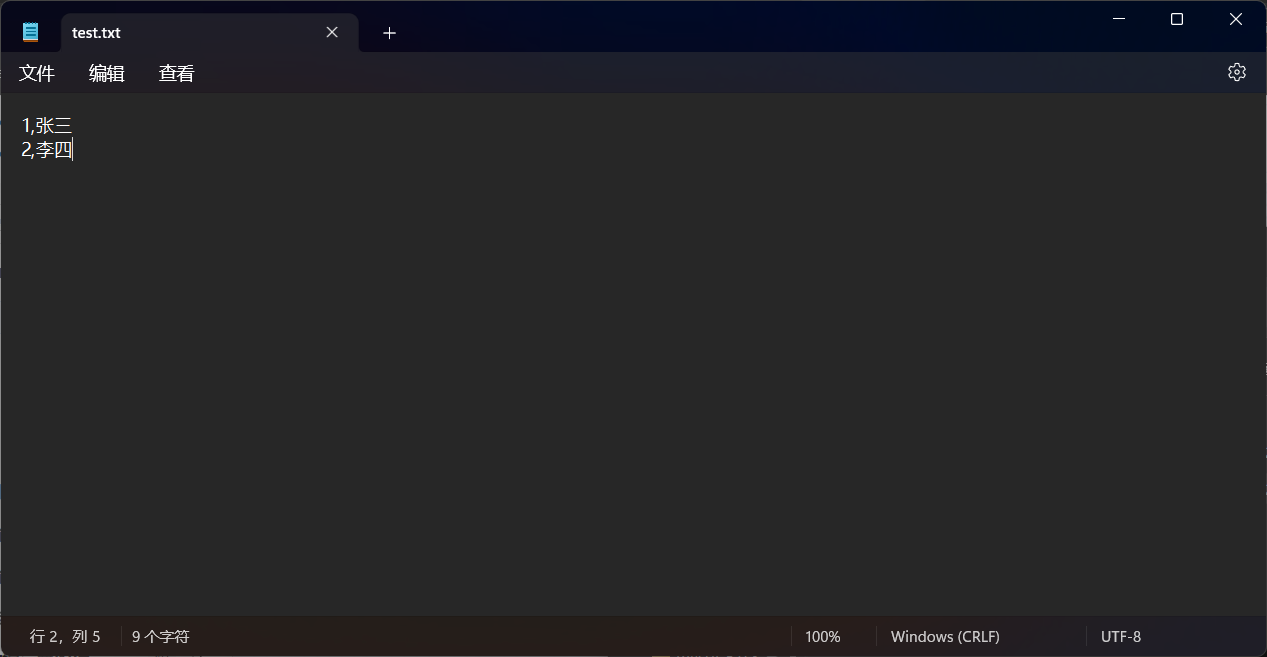
使用文本文件读取组件读取test.txt文件
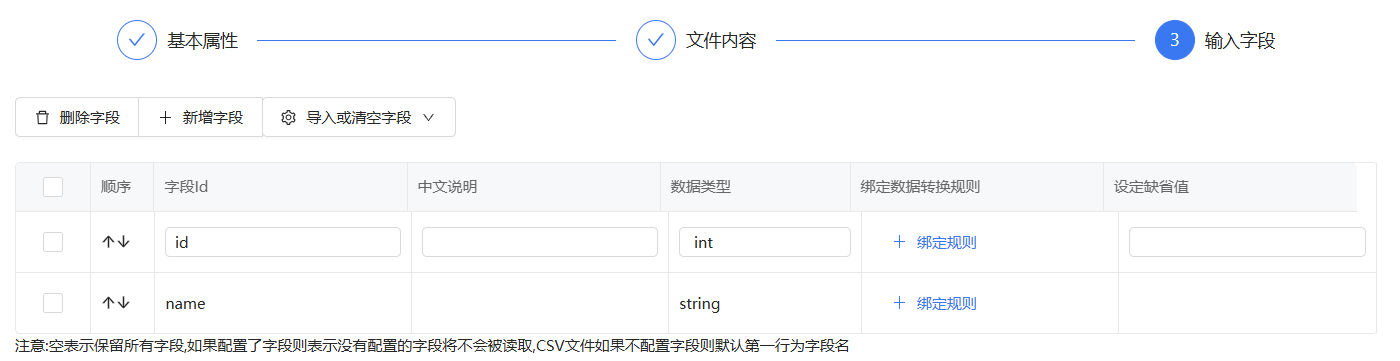
在文本文件读取组件中的第三部输入字段可以配置数据生成规则,我们先不配置运行流程
可以看到输出的就是test.txt文件的内容

我们将id字段配置上数据生成规则中的生成随机6位数,再次运行流程效果
可以看到id已经是随机6位数的id了

6.Excel读取
使用Excel读取组件读取test.xlsx文件
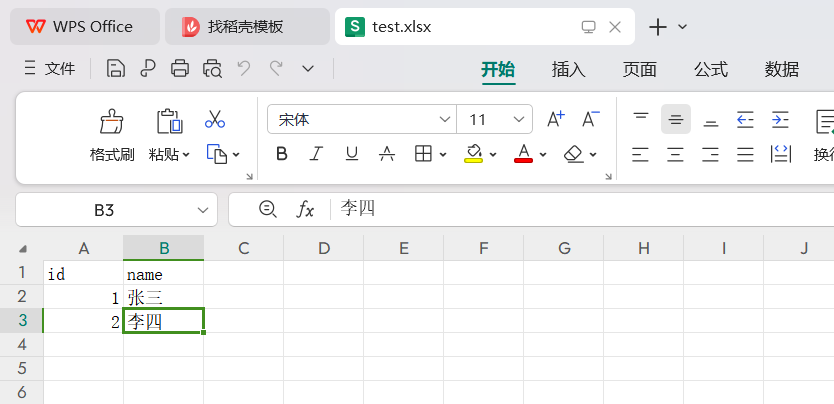
以下是Excel读取组件的配置,标题列配置选择自定义字段
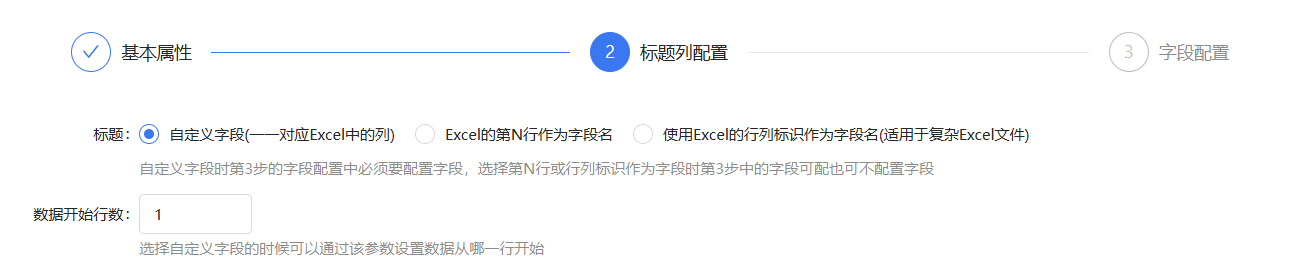
下面是字段配置,可以配置数据生成规则,现在先不配置,运行流程查看效果
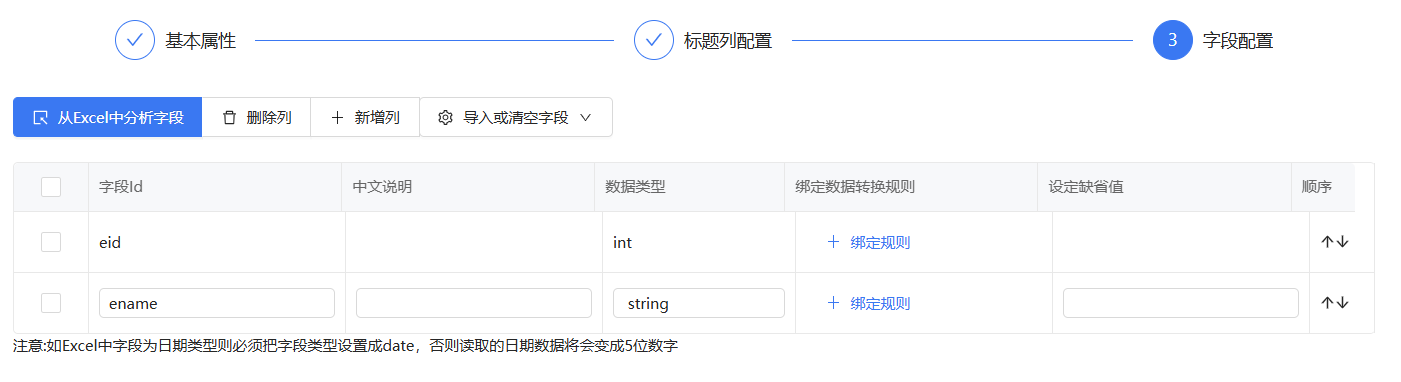
可以看到字段已经配置成我们想要的字段了

现在将eid字段配置上生成6位随机数的数据生成规则,再次运行流程查看效果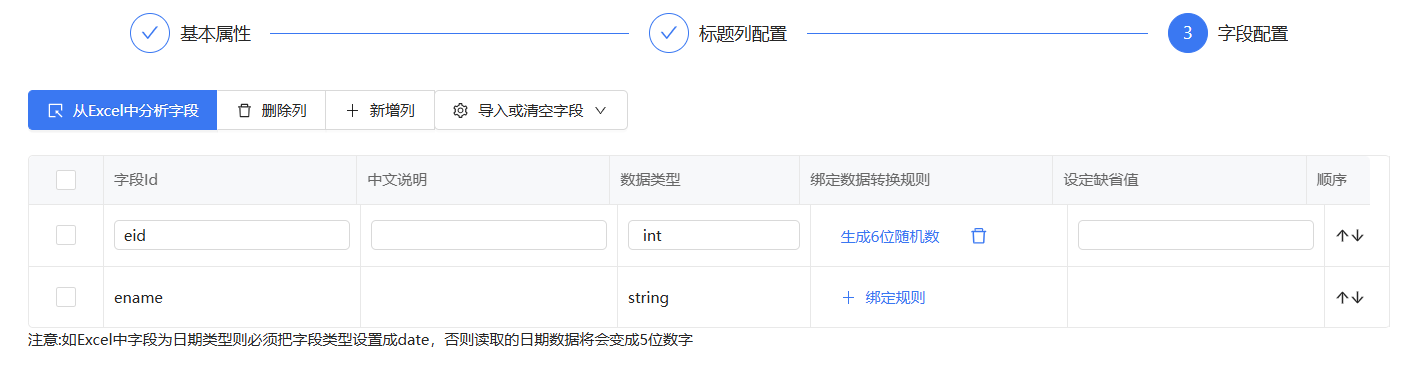
可以看到eid的值已经变了

以上就是数据生成规则的技巧!
最后
数据生成规则通过灵活的配置与算法设计,显著提升了数据工程任务的自动化水平与数据质量。在具体应用中,需结合业务场景选择合适的生成策略,并通过唯一性校验、错误处理等机制保障数据一致性。未来可进一步探索结合机器学习生成更复杂的数据模式,以满足智能化数据治理的需求。