在解决风险类问题时,我们往往面临要在很多个指标中筛选关键指标的抉择。每个指标都是根据真实数据计算得出的,但是只有少数是能作为解释模型的,其余的都算是冗余特征。
这听起来有点像是稳健回归,但区别在于稳健回归是为了将数据的整体趋势不被部分离散点所带歪,而稀疏建模则是在损失函数中添加惩罚项,从而自动筛选保留少数的重要特征,而不是仅仅通过是否离散来判断。
以下是一个用于解释的例子:
R
set.seed(123)
n <- 100 # 样本数
p <- 100 # 特征数
# 生成稀疏数据:只有前5个特征真实影响y
X <- matrix(rnorm(n * p), n, p)
beta_true <- c(3, -2, 1.5, 0, 0, rep(0, p-5)) # 后95个系数为0
y <- X %*% beta_true + rnorm(n, sd = 1) # 添加噪声
# 转换为数据框(添加一些无关特征)
df <- data.frame(y, X)
library(glmnet) # 安装:install.packages("glmnet")
# 准备数据(x需为矩阵,y为向量)
x <- as.matrix(df[, -1])
y <- df$y
# 拟合Lasso模型(alpha=1表示纯L1惩罚)
lasso_model <- glmnet(x, y, alpha = 1, lambda = 0.1) # lambda需调优
# 查看系数(自动稀疏化)
coef(lasso_model)
# 10折交叉验证找最优lambda
cv_fit <- cv.glmnet(x, y, alpha = 1)
plot(cv_fit) # 展示MSE随lambda的变化
# 最优lambda下的系数
best_lambda <- cv_fit$lambda.min
coef(cv_fit, s = "lambda.min") # 非零系数即关键特征
# 普通线性回归(所有特征都保留)
lm_model <- lm(y ~ ., data = df)
summary(lm_model) # 结果难以解释,且容易过拟合输出:
R
Residual standard error: NaN on 0 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: NaN
F-statistic: NaN on 99 and 0 DF, p-value: NA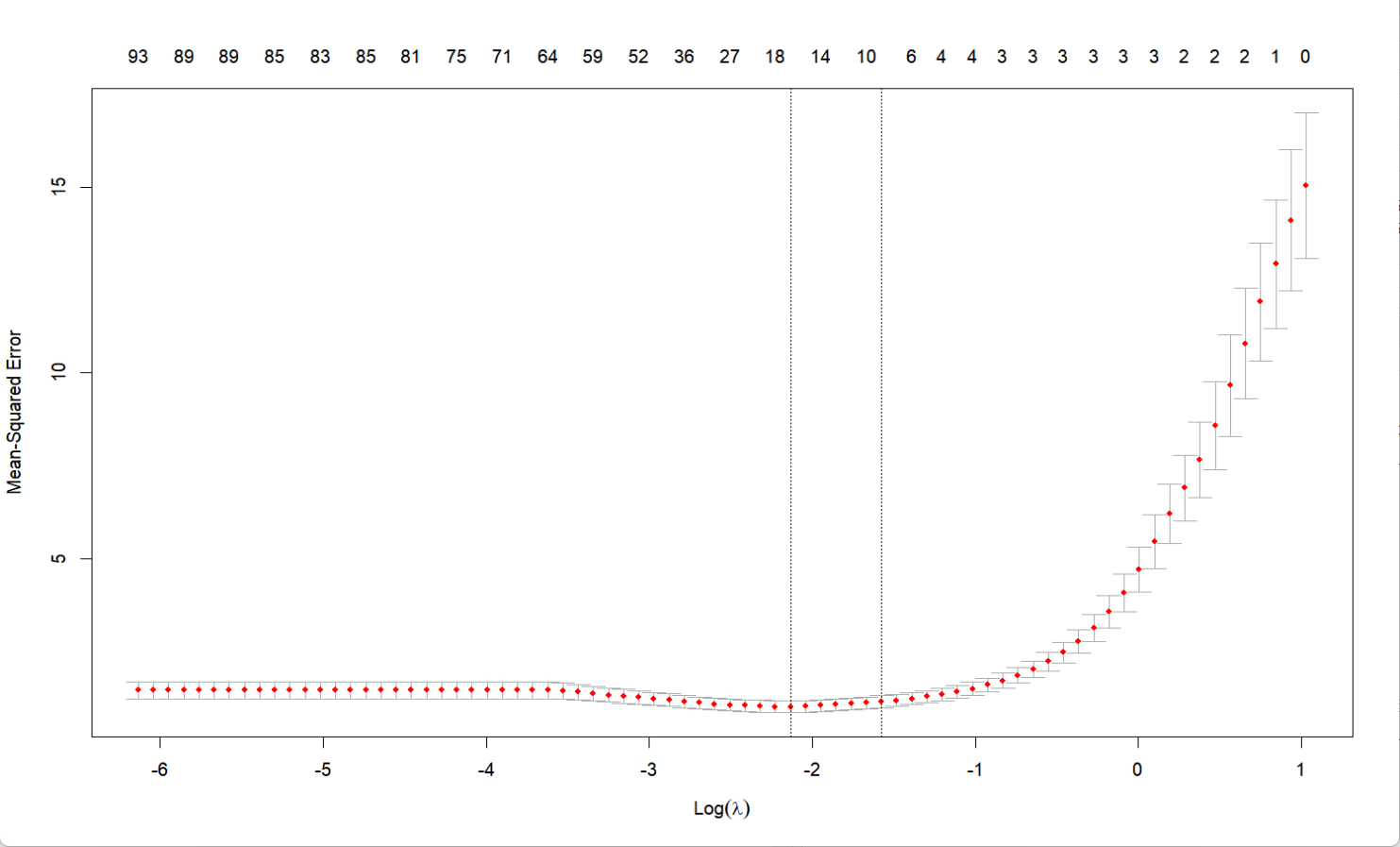
从输出中可以看到,如果是用普通线性回归,结果显示统计量失效,无法解释;而稀疏建模则是把其余的冗余变量的系数都强制归为0了,而从图像可以观察到,当参数减少时,模型包含的特征逐渐增多,误差也在逐渐下降。