**详细视频演示请联系博主
项目实现:

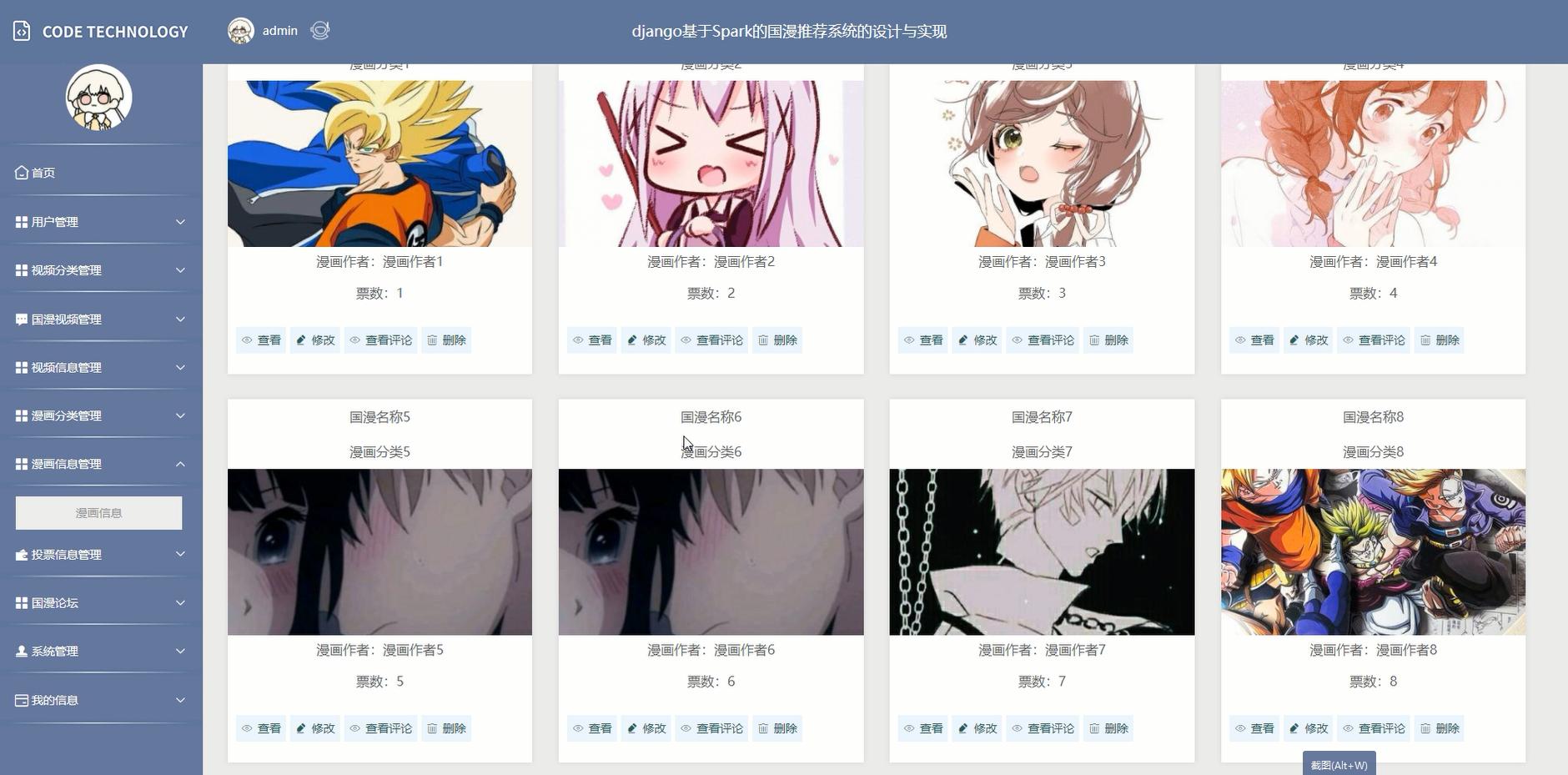

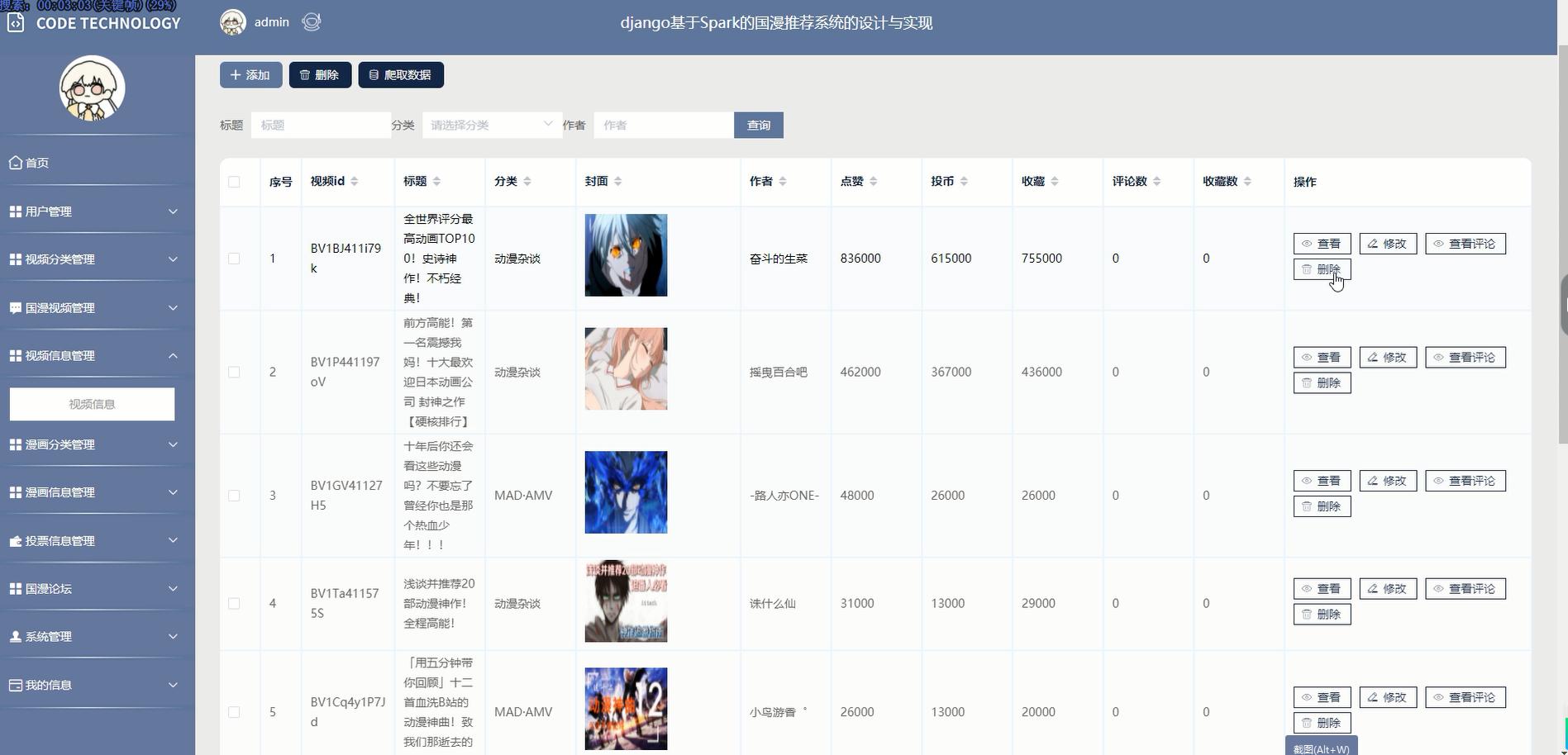

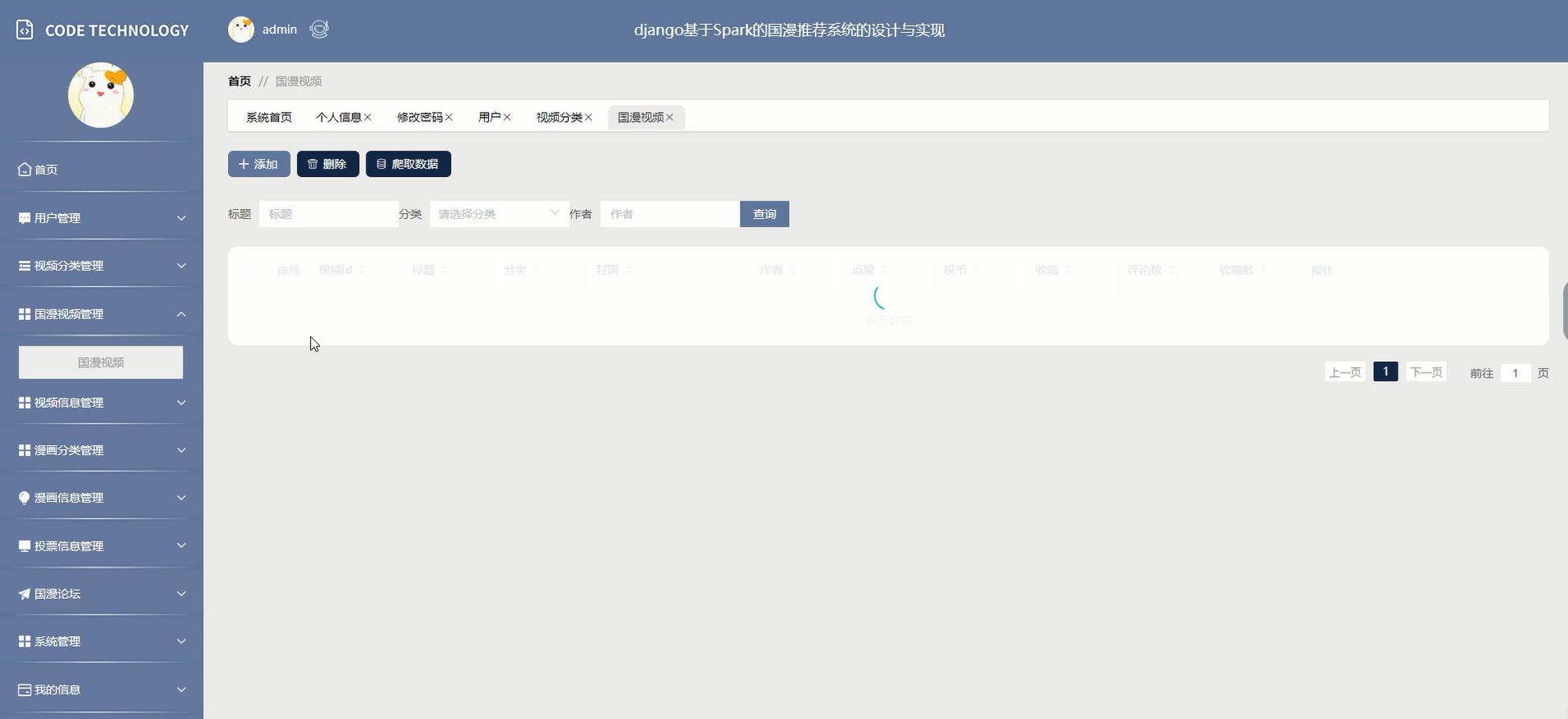
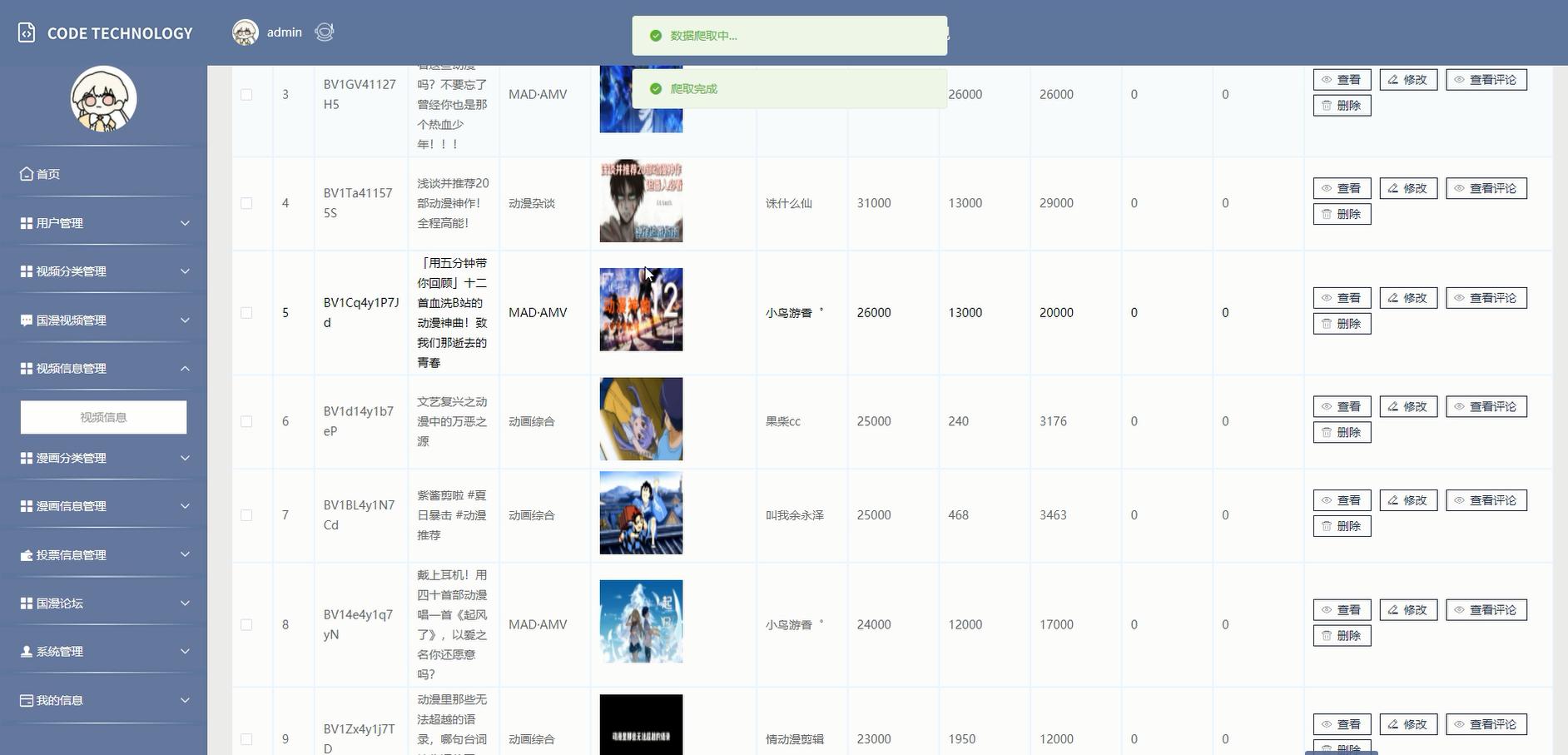
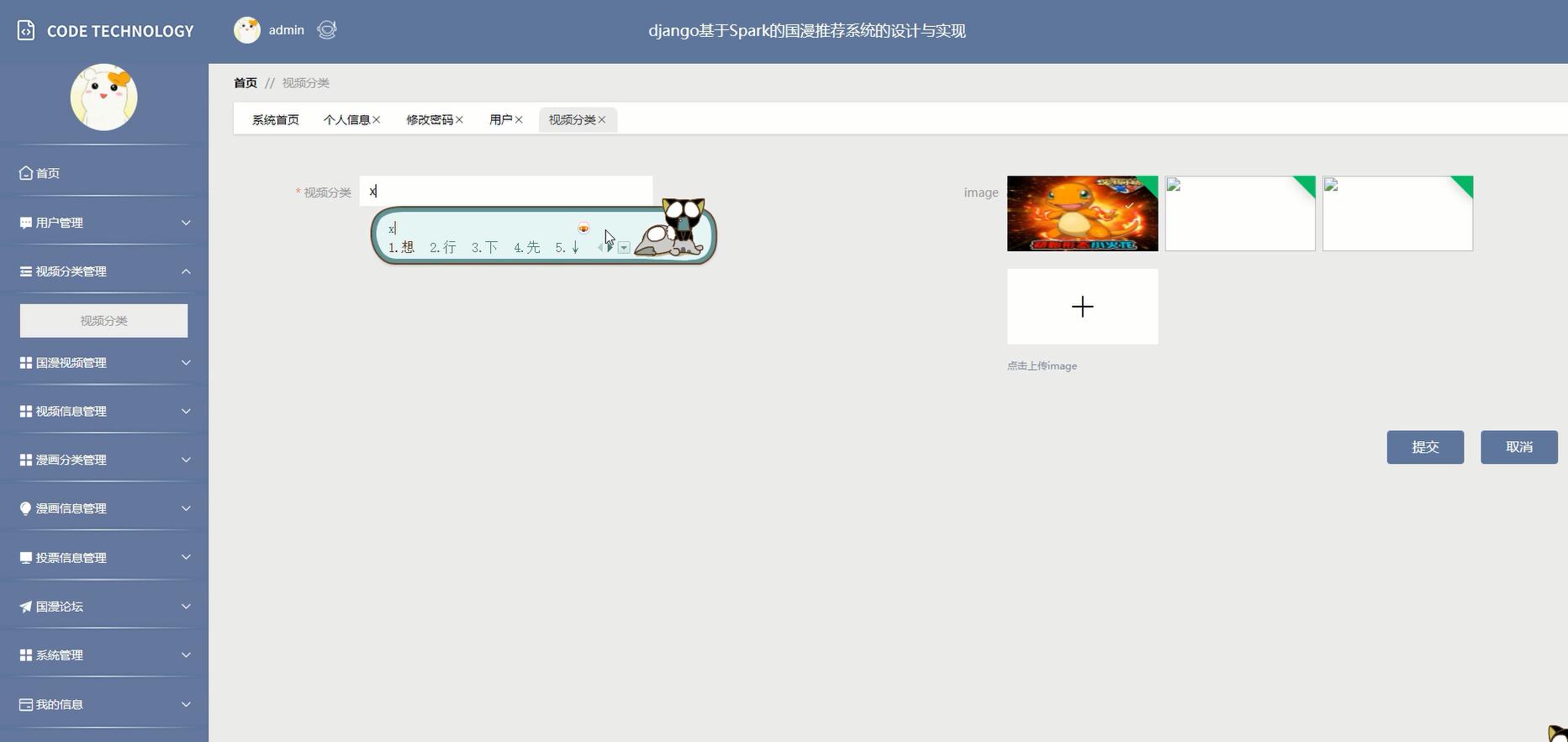
核心代码:
from pyspark.sql import SparkSession
from pyspark.ml.recommendation import ALS
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.sql.functions import col
class ComicRecommender:
def init (self):
self.spark = SparkSession.builder
.appName("ComicRecommendation")
.config("spark.executor.memory", "4g")
.getOrCreate()
# 加载数据
self.ratings = self.spark.read.csv(
"data/user_ratings.csv",
header=True,
inferSchema=True
)
self.comics = self.spark.read.csv(
"data/comic_info.csv",
header=True,
inferSchema=True
)
def preprocess(self):
"""数据预处理"""
# 过滤无效评分
self.ratings = self.ratings.filter((col("rating") >= 1) & (col("rating") <= 5))
# 处理冷启动问题:添加默认评分
popular_comics = self.ratings.groupBy("comic_id").count()
avg_rating = self.ratings.groupBy().avg("rating").first()[0]
default_ratings = popular_comics.filter(col("count") > 100) \
.limit(100) \
.withColumn("user_id", lit(0)) \
.withColumn("rating", lit(avg_rating))
self.ratings = self.ratings.union(default_ratings)
def train_model(self):
"""训练ALS模型"""
# 划分训练集/测试集
train, test = self.ratings.randomSplit([0.8, 0.2])
# 配置ALS模型
als = ALS(
maxIter=10,
regParam=0.01,
userCol="user_id",
itemCol="comic_id",
ratingCol="rating",
coldStartStrategy="drop"
)
# 训练模型
self.model = als.fit(train)
# 评估模型
predictions = self.model.transform(test)
evaluator = RegressionEvaluator(
metricName="rmse",
labelCol="rating",
predictionCol="prediction"
)
rmse = evaluator.evaluate(predictions)
print(f"模型RMSE: {rmse}")
return self.model
def generate_recommendations(self, user_id, num_recs=10):
"""为用户生成推荐"""
# 创建用户DF
user_df = self.spark.createDataFrame([(user_id,)], ["user_id"])
# 获取推荐
recs = self.model.recommendForUserSubset(user_df, num_recs)
# 提取推荐结果
rec_list = recs.select("recommendations").first()[0]
# 关联漫画信息
comic_ids = [row.comic_id for row in rec_list]
comic_recs = self.comics.filter(col("id").isin(comic_ids))
return comic_recs.toPandas().to_dict(orient="records")
def update_model(self, new_ratings):
"""增量更新模型"""
# 将新评分添加到数据集
new_df = self.spark.createDataFrame(new_ratings)
self.ratings = self.ratings.union(new_df)
# 重新训练模型
self.train_model()