本系列为笔者的 Leetcode 刷题记录,顺序为 Hot 100 题官方顺序,根据标签命名,记录笔者总结的做题思路,附部分代码解释和疑问解答,01~07为C++语言,08及以后为Java语言。
01 岛屿数量

java
class Solution {
public int numIslands(char[][] grid) {
}
}方法一:深度优先搜索
java
class Solution {
//方法:深度优先搜索
//核心:grid[i][j] = '0'; i=row j=column
//1.创建递归方法
public void dfs(char[][] grid, int i, int j){
int row = grid.length;
int column = grid[0].length;
if(i<0 || j<0 || i>=row || j>=column || grid[i][j] == '0'){
return;
}
//⭐
grid[i][j] = '0';
//2.上下左右
dfs(grid, i+1, j);
dfs(grid, i-1, j);
dfs(grid, i, j+1);
dfs(grid, i, j-1);
}
public int numIslands(char[][] grid) {
if(grid == null || grid.length == 0){
return 0;
}
int row = grid.length;
int column = grid[0].length;
int ans = 0;
for(int i=0; i<row; i++){
for(int j=0; j<column; j++){
if(grid[i][j] == '1'){
ans++;
dfs(grid, i, j);
}
}
}
return ans;
}
}那为什么正常我们不判断 grid[0].length == 0 呢?
grid == null:直接返回grid.length == 0:没有任意行,不用继续- 至于
grid[0].length是否为 0,在 Leetcode 官方测试用例中不会出现奇怪的"0列"矩阵(如[[], [], []])。就算出现你访问也在之后(第一个循环里i < row直接就不会进j的循环)
方法二:广度优先搜索
java
class Solution {
//方法:广度优先搜索
//核心:grid[i][j] = '0'
public int numIslands(char[][] grid) {
if(grid == null || grid.length == 0){
return 0;
}
int row = grid.length;
int column = grid[0].length;
int ans = 0;
for(int i=0; i<row; i++){
for(int j=0; j<column; j++){
if(grid[i][j] == '1'){
ans++;
grid[i][j] = '0';
//1.创建并加入
Deque<Integer> queue = new LinkedList<>();
queue.offer(i * column + j);
while(!queue.isEmpty()){
//2.弹出并判断
int id = queue.poll();
int r = id / column;
int c = id % column;
//3.上下左右孩子结点
if(r-1 >= 0 && grid[r-1][c] == '1'){
queue.offer((r-1) * column + c);
grid[r-1][c] = '0';
}
if(r+1 < row && grid[r+1][c] == '1'){
queue.offer((r+1) * column + c);
grid[r+1][c] = '0';
}
if(c-1 >= 0 && grid[r][c-1] == '1'){
queue.offer(r * column + (c-1));
grid[r][c-1] = '0';
}
if(c+1 < column && grid[r][c+1] == '1'){
queue.offer(r * column + (c+1));
grid[r][c+1] = '0';
}
}
}
}
}
return ans;
}
}02 腐烂的橘子


java
class Solution {
//方法:多源广度优先搜索
int[] di = {-1, 0, 1, 0};
int[] dj = {0, -1, 0, 1};
public int orangesRotting(int[][] grid) {
if(grid == null || grid.length == 0){
return -1;
}
//1.创建并加入
Deque<Integer> queue = new LinkedList<>();
Map<Integer, Integer> map = new HashMap<>();
int row = grid.length;
int column = grid[0].length;
int ans = 0;
for(int i=0; i<row; i++){
for(int j=0; j<column; j++){
if(grid[i][j] == 2){
int id = i * column + j; //二维展开一维
queue.offer(id);
map.put(id, 0);
}
}
}
//2.弹出并判断
while(!queue.isEmpty()){
int id = queue.poll();
int i = id / column;
int j = id % column;
//3.上下左右孩子结点
for(int k=0; k<4; k++){
int ni = i + di[k];
int nj = j + dj[k];
if(ni>=0 && ni<row && nj>=0 && nj<column && grid[ni][nj]==1){
grid[ni][nj] = 2; //核心步骤
int nid = ni * column + nj;
queue.offer(nid);
map.put(nid, map.get(id) + 1);
ans = map.get(nid); //核心步骤
}
}
}
//4.检查是否有正常橘子
for(int[] ro : grid){
for(int v : ro){
if(v == 1){
return -1;
}
}
}
return ans;
}
}① map建立的意义是什么,不能每次直接ans++吗?
不能简单用 ans++,因为扩散不是简单的线性递增,而是层级递进,且同一层可能同时有多个节点扩散。
② ans = map.get(nid); 不用搞一个Math.max之类的吗,万一更新后比之前小呢?
bfs的特性是按层级遍历,从起点到每个节点的路径最短,不存在"后更新时间更小"的情况。
③ queue.remove()是从队列的头部出去还是尾部出去?
queue.poll() 或 queue.remove() 默认是从队列头部移除元素,即先进先出。
④ if(v == 1)为什么v直接是数字,而不是grid[][] = 1这样的格式?
for(int[] ro : grid),ro是二维数组中的每一行(一维数组)。for(int v : ro),v是当前行中的每个元素,也就是grid中的单元格值。
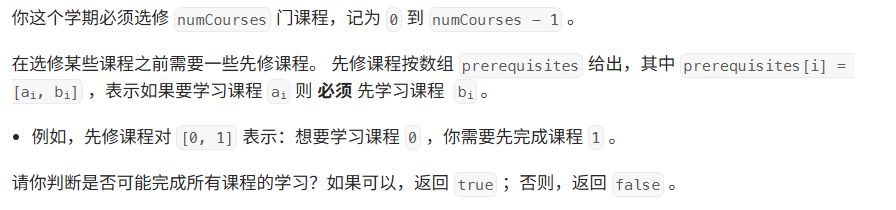
03 课程表

java
class Solution {
public boolean canFinish(int numCourses, int[][] prerequisites) {
}
}方法一:深度优先搜索
java
class Solution {
//1.构造邻接表、访问数组、环判断符号;
List<List<Integer>> edges;
int[] visited;
boolean valid = true;
public boolean canFinish(int numCourses, int[][] prerequisites) {
//2.初始化邻接表、访问数组
edges = new ArrayList<List<Integer>>();
for(int i=0; i<numCourses; i++){
edges.add(new ArrayList<Integer>());
}
for(int[] info : prerequisites){
edges.get(info[1]).add(info[0]);
}
visited = new int[numCourses];
//3.遍历结点并调用dfs方法
for(int i=0; i<numCourses && valid; i++){
if(visited[i] == 0){
dfs(i);
}
}
return valid;
}
public void dfs(int u){
visited[u] = 1;
for(int v : edges.get(u)){
if(visited[v] == 0){
dfs(v);
if(!valid){
return;
}
}else if(visited[v] == 1){
valid = false;
return;
}
}
visited[u] = 2;
}
}方法二:广度优先搜索
java
class Solution {
//1.构造邻接表、入度数组、访问结点数量;
List<List<Integer>> edges;
int[] indeg;
int visited = 0;
public boolean canFinish(int numCourses, int[][] prerequisites) {
//2.初始化邻接表、入度数组
edges = new ArrayList<>();
for(int i=0; i<numCourses; i++){
edges.add(new ArrayList<>());
}
indeg = new int[numCourses];
for(int[] info : prerequisites){
edges.get(info[1]).add(info[0]);
indeg[info[0]]++; //入度增加
}
//3.广度优先搜索(queue)
//a.创建并加入
Deque<Integer> queue = new LinkedList<>();
for(int i=0; i<numCourses; i++){
if(indeg[i] == 0){
queue.offer(i);
visited++;
}
}
//b.弹出并判断
while(!queue.isEmpty()){
int u = queue.poll();
//c.左右孩子结点
for(int v : edges.get(u)){
indeg[v]--; //入度减小
if(indeg[v] == 0){
queue.offer(v);
visited++;
}
}
}
return visited == numCourses;
}
}04 实现 Trie(前缀树)


java
class Trie {
public Trie() {
}
public void insert(String word) {
}
public boolean search(String word) {
}
public boolean startsWith(String prefix) {
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
java
class Trie {
private Trie[] children;
private boolean isEnd;
public Trie() {
children = new Trie[26];
isEnd = false;
}
public void insert(String word) {
Trie node = this;
for(int i=0; i<word.length(); i++){
char ch = word.charAt(i);
int index = ch - 'a';
if(node.children[index] == null){
node.children[index] = new Trie();
}
node = node.children[index];
}
node.isEnd = true;
}
public boolean search(String word) {
Trie node = searchPrefix(word);
return node != null && node.isEnd == true;
}
public boolean startsWith(String prefix) {
return searchPrefix(prefix) != null;
}
private Trie searchPrefix(String prefix) {
Trie node = this;
for(int i=0; i<prefix.length(); i++){
char ch = prefix.charAt(i);
int index = ch - 'a';
if(node.children[index] == null){
return null;
}
node = node.children[index];
}
return node;
}
}① 求什么的长度是.length而不是.length()?
.length返回数组的长度
.length()返回字符串的长度
② node.children[index]是啥玩意儿?
java
private Trie[] children;这表示每个 Trie 节点里都有一个 children 数组,里面存放的是该节点的子节点,每个子节点也是一个 Trie 类型的对象。
children数组长度为26,我们只处理小写字母a~z,每个位置对应一个字母。children[0]就是指向存储字母'a'的那个子节点,children[1]指向'b'的子节点,依此类推。
③ return node != null && node.isEnd; 当中 node.isEnd 不太理解?
isEnd 是每个Trie节点里的一个布尔变量,表示这个节点是不是有单词"在此结束"的标志。
举例:
- 假设你插入了
"app"和"apple"两个单词。 - 路径
a -> p -> p -> l -> e在Trie里都存在,同时在"app"的最后字符的节点(第二个p)和"apple"的最后字符节点(e)上,isEnd都会标记为true。