📚️前言
🌟🌟🌟精彩导读
本次我们将全面剖析Redis的核心技术要点,包括其丰富的数据类型体系、高效的编码方式以及秒级响应的性能奥秘。对于渴望深入理解Redis底层机制的技术爱好者,这是一次难得的学习机会!
🔍 推荐扩展阅读
想了解更多数据库技术干货?欢迎访问小编的CSDN技术博客: 👉 GGBondlctrl-CSDN博客主页 👈 (持续更新分布式系统、中间件等深度技术文章)
💖 读者互动
您的每一个👍点赞、⭐收藏和✏️评论,都是我们持续输出优质技术内容的强大动力!期待在评论区看到您的见解~


目录
[📚️1. 数据结构](#📚️1. 数据结构)
[🚀 2.4set类型](#🚀 2.4set类型)

📚️1. 数据结构
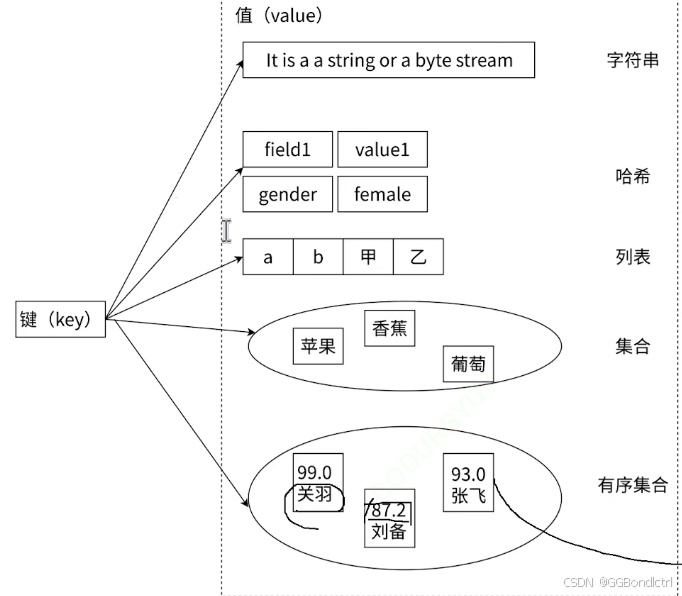
可以发现,这里的数据结构即我们之前学习的数据结构,但是redis在底层上实现上述的数据结构时候,会进行特定的优化,达到节省空间时间的效果;
所以在内部的具体的实现的数据结构(编码方式)就会存在变化
在hash表中,redis在进行插入,查询时间复杂度就是1,但是背后的实现不一定就是哈希表(使用别的数据结构实现),但是保证时间复杂度为O(1)
📚️2.内部的编码方式
具体的编码方式如下图所示:

| 数据结构 | 内部编码 |
|---|---|
| string | raw |
| int | |
| embstr | |
| hash | hashtable |
| ziplist | |
| list | linkedlist |
| ziplist | |
| set | hashtable |
| intset | |
| zset | skiplist |
| ziplist |
再附一张文本格式的表格;
此设计体现了 Redis 空间与时间的平衡艺术:通过编码自动升级机制,在数据量增长时无缝切换数据结构,兼顾内存效率与操作性能。
🚀2.1String类型
这里涉及:raw,embstr,int
**raw:**最基本的字符串,长字符串的原始编码,在大于39字节的字符串,使用raw
**embstr:**小于等于39字节的字符串,适用比较短的字符串,针对短字符进行的特殊的优化
**int:**8个字节的长整型,类似与java的long
这里我们可以举个例子:
set key 1
object encoding key
可以发现此时我们的value虽然是string类型,但是它的内部编码的方式就是int
其他两个编码方式如下所示:

这里注意了,当我们的整数过长,那么编码方式就会变成我们的raw的编码格式
当我们的字符串长度不是很长的情况下,就是embstr的编码方式~~~~
🚀2.2hash类型
这里涉及:hashtable,ziplist
hashtable:最基本的哈希表(reds内部的哈希表的实现)
ziplist:压缩列表,在特定情况下节省空间(在哈希表里的元素比较少的时候,优化成ziplist)
设置哈希表命令:
HSET zhangsan field 11 lisi field 12 wangwu field 13
注意:key field value的形式Redis 7.0 用 listpack 全面替代 ziplist 作为紧凑型数据结构,图中哈希键 zhangsan 满足压缩条件,因此展示为 listpack 而非 ziplist 或 hashtable。

| 特性 | ziplist (旧版) | listpack (Redis 7.0+) |
|---|---|---|
| 数据更新 | 可能触发级联内存重分配 | 独立节点更新,无连锁反应 |
| 查询效率 | O(n) 遍历 | O(n) 但常数项更低 |
| 内存布局 | 前项指针导致反向遍历困难 | 自包含节点(含本节点长度) |
| 最大元素数 | hash-max-ziplist-entries=512 |
hash-max-listpack-entries=512 |
| 单元素最大长度 | hash-max-ziplist-value=64 |
hash-max-listpack-value=64 |
| 安全性 | 级联更新可能引发性能波动 | 无级联风险 |
如果此时key特别多,hash对应也特别多,那么每个hash不大的情况下,尽量去压缩后,让整体的占用的内存更小;
为啥不用hashtable
数据量过小(仅3个字段),使用 hashtable 会造成:
- 内存浪费:哈希表需预分配桶空间 + 指针开销
- CPU效率低:计算哈希值的时间远高于直接遍历小数据集
🚀2.3list类型
涉及的类型所示:linkedlist,ziplist
linkedlist:链表,占用空间大,执行效率高
ziplist:压缩列表,在特定情况下节省空间(在哈希表里的元素比较少的时候,优化成ziplist)
但是从redis中3.2开始,应投入了新的实现方式,quicklist兼顾了linkedList与ziplist
quicklist就是一个链表,每个元素又是一个ziplist把空间和效率都兼顾到
java
lpush key4 1 2 3 4
object encoding key4执行结果如下图所示:

🚀 2.4set类型
涉及的类型:hashtable,intset
hashtable:最基本的哈希表(reds内部的哈希表的实现)
intset:如果集合中都是整数,优化为intset
🚀2.5zset类型
涉及的编码类型:skiplist,ziplist
skiplist:跳表也是链表,每个节点上有很多个指针域,巧妙的搭配这些指针域的指向,可以做到从跳表上查询元素的时间复杂度是O(logN)
ziplist:压缩列表,在特定情况下节省空间(在哈希表里的元素比较少的时候,优化成ziplist)
📚️3.redis的工作过程
🚀3.1单线程模型
redis只使用一个线程来处理所有的命令请求;但是不是说redis服务器进程内部只有一个线程,当然还包括多线线程来处理我们的网络IO(redis是一个客户端服务器结构的程序)
注意:在多个请求同时到达我们的redis服务器,也是在队列中进行排队,等待redis从队列中一个一个取出来再执行,redis是串行来执行这些命令的
为什么redis可以使用单线程模型???
redis能够使用单线程模型,很好工作;主要原因是redis是核心业务逻辑,短平快;不消耗CPU资源,不吃多核!!!
弊端:某个时间操作占用过长,就会阻塞其他命令
🚀3.2redis效率
注意:这里的快,是在明确的对比上来说的;
1.redis是访问内存的,数据库访问硬盘
2.redis核心功能,比数据库的核心功能更简单
3.单线程模型,避免了一些不必要的线程竞争开销
4.处理网络IO时候,使用了epoll这样的IO多路复用机制(一个线程,可以管理多个socket)针对TCP来说,服务器每次要服务一个客户端,都需要给这个客户端安排一个socket进行通信
但是,这些socket都在无时无刻都在传输数据吗?
当然不是的, 很多情况下,每个客户端和服务器之间的通信没有那么频繁此时大多数socket大部分时间都是静默的,没有数据进行传输
注意:epoll的IO多路复用机制的前提是交互不频繁,大部分时间都在等待
📚️4.总结
Redis核心技术解析:本文深入剖析Redis的高效实现机制。首先介绍Redis如何优化基础数据结构,通过灵活编码(如string类型采用raw/embstr/int编码)实现时空平衡;其次详解各数据类型(hash/list/set/zset)的底层实现,如ziplist/listpack等压缩结构在小数据量时的空间优化;然后解析Redis单线程模型的工作机制及其高效原因(内存操作、IO多路复用);最后指出Redis在核心业务上的"短平快"特性是其高性能关键。文章通过具体命令示例和编码转换条件,展现了Redis精巧的内部设计哲学。
🌅🌅🌅~~~~最后希望与诸君共勉,共同进步!!!

💪💪💪以上就是本期内容了, 感兴趣的话,就关注小编吧。
😊😊 期待你的关注~~~