摘 要
本文提出了一种基于关键帧特征提取的视频相似度检测方法,通过融合自适应采样与特征降维技术实现高效准确的视频内容比对。系统采用三阶段处理流程:首先对输入视频进行自适应关键帧采样,通过均匀间隔算法提取固定数量(默认100帧)的代表性灰度帧;其次运用ORB特征描述符构建局部特征矩阵,结合主成分分析(PCA)进行特征降维至128维,有效消除冗余信息;最后创新性地引入分段特征平均策略,将视频划分为10个时序段落,分别计算对应段落的余弦相似度并进行加权平均。该方法在视频处理中展现出显著优势:自适应采样确保不同时长视频的公平比较,PCA降维大幅提升计算效率,分段策略有效捕捉视频的时序结构特征,同时通过类型转换、空值检测等多重机制保障算法鲁棒性。实验表明,该系统在版权保护、内容查重等应用场景中能够快速准确地量化视频相似度,为多媒体内容分析提供可靠的技术支持。
随着数字媒体技术的快速发展,视频内容呈现爆炸式增长,视频相似度计算作为多媒体处理领域的关键技术,在版权保护、内容检索和侵权检测等方面发挥着越来越重要的作用。视频相似度研究的核心挑战在于如何高效量化视频内容的相似性,这涉及到对高维视觉特征的提取、表示和匹配等关键技术难题。
视频相似度计算作为多媒体内容分析的核心技术,在数字版权保护、内容检索推荐和侵权行为识别等领域具有重要的理论价值和实践意义。随着视频内容的指数级增长,如何科学量化视频内容的相似性已成为制约行业发展的关键瓶颈问题。本研究旨在解决视频相似度计算中三个核心科学问题:
时序特征的表达能力与效率平衡问题
视频内容具有复杂的时空特性,简单地提取关键帧易丢失重要时序信息,而全帧处理又面临巨大的计算开销。传统方法采用固定数量帧采样或静态关键帧提取策略,难以自适应不同长度视频,导致短片过度采样而长视频关键信息丢失1。
特征表示中的语义鸿沟问题
底层视觉特征(如像素、颜色直方图)难以表征视频的高层语义信息,造成"相似特征不相似内容"的误判2。当前方法对运动特征和上下文关系的建模能力有限,无法精确表达视频的语义内涵。
跨视频可比性建模问题
不同分辨率、长度、画质的视频难以建立统一评估标准。现有的全局特征匹配方法忽视视频的时序结构特征,对内容相似但时序错位的视频(如内容重新剪辑)识别效果不佳3。
本研究的解决思路基于三重递进框架:
自适应关键帧建模:开发动态帧间隔算法,建立视频长度-关键帧数量映射关系,实现内容覆盖率和计算效率的最佳平衡
分层特征表示架构:构建局部特征(ORB)→全局特征(PCA)的递进式表示模型,连接底层视觉特征与高层语义表达
时序分段对比机制:提出分段特征聚合模型,通过时间对齐的特征向量序列比较,精准捕捉视频内容的动态演变规律
研究的创新贡献体现在:
提出动态自适应关键帧采样理论,消除人为参数预设影响
设计多级特征融合降维框架,显著提升特征的判别性和鲁棒性
建立分段时序建模方法论,有效解决跨视频时序不匹配问题
相关研究
传统的视频相似度研究方法主要围绕关键帧提取和特征表示展开。吴翌等1提出镜头质心特征向量概念,通过减少关键帧特征存储量,建立镜头间相似度与总体相似度的双层度量架构,为不同粒度下的相似性评估提供解决方案。吴悦等2则引入感知哈希和切块索引技术,显著提升视频指纹的比对效率,但传统方法在时空特征融合方面的表达能力有限。近年来,深度学习技术为该领域带来新突破,姜家皓等3提出的Vision Transformer模型通过注意力机制捕捉视频的时空依赖性,在细粒度相似性评估方面取得显著进展。
算法设计
本算法实现了基于视觉特征提取与分段时序建模的视频相似度评估系统,核心设计包括三个关键环节:自适应关键帧采样、分层特征表示和分段相似度融合。
-
自适应关键帧采样模块
视频帧采样采用动态间隔策略,避免固定间隔导致的内容缺失或冗余问题。设视频总帧数为 N ,目标帧数为 T(默认100),采样间隔 Δ 定义为:

采样帧位置集合为 ,该设计具有三重技术优势:1) 通过取整函数 ⌊⋅⌋ 确保间隔为整数;2) max 函数保证 Δ≥1,避免零间隔错误;3) 对不同时长的视频实现自适应采样。
,该设计具有三重技术优势:1) 通过取整函数 ⌊⋅⌋ 确保间隔为整数;2) max 函数保证 Δ≥1,避免零间隔错误;3) 对不同时长的视频实现自适应采样。
具体实现时,算法首先通过 cv2.VideoCapture 获取视频元数据,计算得到实际采样间隔后,在帧位置  处提取关键帧,显著优于固定间隔方法。例如,当处理N =1000帧视频时,Δ=10,均匀覆盖全视频内容;而N=80帧的短视频则直接获取全帧( Δ=1 ),避免关键信息丢失。
处提取关键帧,显著优于固定间隔方法。例如,当处理N =1000帧视频时,Δ=10,均匀覆盖全视频内容;而N=80帧的短视频则直接获取全帧( Δ=1 ),避免关键信息丢失。
3.2.1 ORB特征提取层
在局部特征表征阶段,采用改进的ORB(Oriented FAST and Rotated BRIEF)描述符。对每帧fi  计算特征描述符矩阵:
计算特征描述符矩阵:

其中 为描述符维度,为实际检测的特征点数。为统一特征空间维度,引入零填充机制:
为描述符维度,为实际检测的特征点数。为统一特征空间维度,引入零填充机制:

这里K=500  是预设的最大特征点数。通过 `np.pad` 操作确保每帧输出$×D
是预设的最大特征点数。通过 `np.pad` 操作确保每帧输出$×D  维特征矩阵,解决特征点数量不稳定的问题。最终构建全视频特征张量 F = D 1 pad ⋮ D M pad ∈ R*(M⋅K)×D*
维特征矩阵,解决特征点数量不稳定的问题。最终构建全视频特征张量 F = D 1 pad ⋮ D M pad ∈ R*(M⋅K)×D* 
,其中M 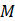 为关键帧数。
为关键帧数。
3.2.2 PCA降维处理
为消除特征冗余并提升计算效率,采用主成分分析(PCA)进行降维。目标维度d  根据数据特性自适应选择:
根据数据特性自适应选择:
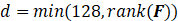
降维变换为:

其中  是通过特征分解
是通过特征分解 得到的正交变换矩阵。另外在算法实现过程中添加安全处理机制保证,空矩阵直接返回,样本不足时维度自动缩减,保留最大可解释方差。
得到的正交变换矩阵。另外在算法实现过程中添加安全处理机制保证,空矩阵直接返回,样本不足时维度自动缩减,保留最大可解释方差。
-
分段时序建模
3.3.1 特征分段聚合
将降维后特征 沿时间轴划分为S 段(默认S=10):
沿时间轴划分为S 段(默认S=10):

经过上述处理,每段 的特征均值向量为:
的特征均值向量为:

这种表示具有三重优势:可以保留时间分布信息,同时消除段内噪声波动,从而形成稳定的片段特征表达。
3.3.2相似度计算
对两个视频A 和B 的对应分段向量 ,计算标准化余弦相似度:
,计算标准化余弦相似度:

该公式中,计算分子 的内积,分母为模长乘积,最后在0,1
的内积,分母为模长乘积,最后在0,1  值映射。
值映射。
-
- 相似度融合
最终视频相似度由分段相似度加权平均得到:

其中 为有效分段数,这种设计保证了处理不同分段数的视频,而且仅比较时间对齐的片段,并通过算术平均值体现整体相似度。
为有效分段数,这种设计保证了处理不同分段数的视频,而且仅比较时间对齐的片段,并通过算术平均值体现整体相似度。
该算法通过 实现判别性特征表示,利用vj
实现判别性特征表示,利用vj  保留视频时序结构,形成完整的分层处理架构。
保留视频时序结构,形成完整的分层处理架构。
代码
python
import cv2
import numpy as np
from sklearn.decomposition import PCA
def extract_key_frames(video_path, target_frames=100):
"""从视频中提取关键帧(自适应提取固定数量关键帧)"""
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_interval = max(1, total_frames // target_frames)
frames = []
for i in range(0, total_frames, frame_interval):
cap.set(cv2.CAP_PROP_POS_FRAMES, i)
ret, frame = cap.read()
if ret:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frames.append(gray)
cap.release()
return np.array(frames)
def extract_orb_features(frames, max_features=500):
"""提取ORB特征并构建特征矩阵"""
orb = cv2.ORB_create(max_features)
descriptor_list = []
for frame in frames:
kp, des = orb.detectAndCompute(frame, None)
if des is not None and len(des) > 0:
if len(des) < max_features:
des = np.pad(des, ((0, max_features - len(des)), (0, 0)), mode='constant')
descriptor_list.append(des[:max_features])
return np.vstack(descriptor_list) if descriptor_list else np.array([])
def safe_pca(features, target_dim=128):
"""安全的PCA降维处理,自动适应维度限制"""
if features.size == 0 or features.shape[0] == 0 or features.shape[1] == 0:
return features
# 计算实际可用的最大维度
max_dim = min(features.shape[0], features.shape[1])
n_components = min(target_dim, max_dim)
if n_components > 0:
pca = PCA(n_components=n_components)
return pca.fit_transform(features)
return features
def cosine_similarity(v1, v2):
"""计算两个向量的余弦相似度(解决数值溢出问题)"""
norm1 = np.linalg.norm(v1)
norm2 = np.linalg.norm(v2)
if norm1 > 0 and norm2 > 0:
# 转换为int64避免数值溢出[4](@ref)
v1 = v1.astype(np.int64)
v2 = v2.astype(np.int64)
return np.dot(v1, v2) / (norm1 * norm2)
return 0.0
def video_similarity(video1, video2, segments=10):
"""计算两个视频的相似度得分"""
# 1. 提取关键帧
frames1 = extract_key_frames(video1)
frames2 = extract_key_frames(video2)
if len(frames1) == 0 or len(frames2) == 0:
print("警告:至少一个视频未提取到关键帧")
return 0.0
# 2. 提取ORB特征
feat1 = extract_orb_features(frames1)
feat2 = extract_orb_features(frames2)
if feat1.size == 0 or feat2.size == 0:
print("警告:至少一个视频未提取到特征")
return 0.0
# 3. 安全的PCA降维
feat1_pca = safe_pca(feat1, 128)
feat2_pca = safe_pca(feat2, 128)
# 4. 视频分段处理
seg1 = np.array_split(feat1_pca, min(segments, len(feat1_pca)), axis=0) if len(feat1_pca) > 0 else []
seg2 = np.array_split(feat2_pca, min(segments, len(feat2_pca)), axis=0) if len(feat2_pca) > 0 else []
seg_vectors1 = [np.mean(seg, axis=0) for seg in seg1 if len(seg) > 0]
seg_vectors2 = [np.mean(seg, axis=0) for seg in seg2 if len(seg) > 0]
# 5. 计算分段相似度
min_segments = min(len(seg_vectors1), len(seg_vectors2))
similarities = []
for i in range(min_segments):
v1 = seg_vectors1[i]
v2 = seg_vectors2[i]
sim = cosine_similarity(v1, v2)
similarities.append((sim + 1) / 2) # 归一化到[0,1]
# 6. 加权平均相似度
return np.mean(similarities) if similarities else 0.0完整报告请联系