先用通俗的话介绍一下什么是LSTM
咱们用一个生活化的例子,把 LSTM 说清楚。
想象你在看一部很长的电影,需要记住剧情来理解后面的发展。普通的 "循环神经网络(RNN)" 就像一个记性不好的人:前面的剧情看了没多久就忘了,看到后面关键情节时,可能已经不记得前面的伏笔(比如 "前面出现的那个配角,其实是后面的反派"),导致理解出错。
而 LSTM(长短期记忆网络)就像一个 "有好记性的助手",它能主动判断:哪些剧情该记、哪些该忘、现在需要用哪些记忆。具体怎么做到的?它靠三个 "功能开关"(专业叫 "门")来管理记忆,就像你整理抽屉的过程:
1. 第一个开关:"该扔啥"(遗忘门)
你的抽屉(可以理解为 "长期记忆库")里堆了很多旧东西(前面的剧情、信息)。有些东西早就没用了(比如电影开头一闪而过的路人),留着占地方。这时候 "遗忘门" 就像你的手,会主动把这些没用的东西扔掉,给新东西腾地方。
2. 第二个开关:"该存啥"(输入门)
新剧情来了(比如电影里主角拿到了一把钥匙),这个信息可能很重要(后面要用来开锁)。"输入门" 会判断:这个新信息值得放进抽屉吗?如果值得,就把它整齐地放进去,和剩下的有用旧东西(比如主角的身份)放在一起。
3. 第三个开关:"该用啥"(输出门)
现在看到电影的某个片段(比如主角走到一扇锁着的门),你需要从抽屉里找有用的记忆来理解:"哦,前面拿到的钥匙应该就是开这扇门的!" 这时候 "输出门" 会从抽屉里精准地把 "钥匙" 这个记忆拿出来,帮你理解当前的情节。
总结一下
LSTM 就像一个 "智能抽屉":
- 抽屉本身(细胞状态)用来存长期重要的记忆;
- 三个开关(遗忘门、输入门、输出门)负责 "扔垃圾、存新货、取要用的东西";
- 这样一来,不管剧情多长(序列多复杂),它都能记住关键信息,不会像普通 RNN 那样 "记了后面忘前面"。
它能干啥?
比如:
- 理解一句话:"他昨天买了个西瓜,今天它坏了"------LSTM 能记住 "它" 指的是 "西瓜"(前面的信息);
- 预测明天的天气:需要记住前几天的温度、湿度变化(长期趋势);
- 语音转文字:能把 "我明天...(中间有杂音)... 班" 补全成 "我明天上班"(靠前后文记忆)。
简单说,LSTM 就是个 "会聪明记东西的网络",专门解决 "记不住长远信息" 的问题~
专业术语介绍
核心结构:一个 "仓库"+ 三个 "管理员"
LSTM 的核心是 "细胞状态(Cell State)" (可以理解为 "长期记忆仓库"),以及三个控制它的 "门(Gate)"(相当于仓库管理员)。
1. 细胞状态(Cell State)------ 仓库本身
类比:就像你家那个大衣柜,专门存长期重要的东西(比如过冬的羽绒服、毕业证这种不常用但必须留着的)。
专业说:它是一条贯穿整个序列(比如一句话、一串时间点)的 "信息高速公路",用来存储长期需要记住的核心信息,状态变化缓慢(不会随便丢东西)。
2. 遗忘门(Forget Gate)------ 扔垃圾的管理员
类比:衣柜里堆了去年穿破的旧 T 恤、过期的优惠券,这个管理员会检查:"这些还有用吗?没用就扔了腾地方。"
专业说:它通过一个 sigmoid 函数 输出 0-1 之间的数值(0 = 全扔,1 = 全留),决定细胞状态中哪些旧信息应该被遗忘(比如句子里早就没用的代词、时间序列里的噪音)。
3. 输入门(Input Gate)------ 存新货的管理员
类比:你新买了一件冲锋衣,这个管理员会先判断:"这件需要放进衣柜长期保存吗?" 如果需要,就把它整理好(比如叠整齐),再放进衣柜和剩下的有用旧东西(比如羽绒服)放在一起。
专业说:它分两步:
- 第一步:用 sigmoid 函数筛选 "新输入的信息里哪些值得存"(0 = 不存,1 = 存);
- 第二步:把选中的新信息用 tanh 函数 处理成 "候选细胞状态(Candidate Cell State)"(相当于 "叠整齐的新衣服");
- 最后,把候选状态 "加" 到细胞状态里(更新仓库库存)。
4. 输出门(Output Gate)------ 取东西的管理员
类比:现在要出门露营,你需要从衣柜里找冲锋衣。这个管理员会从衣柜里挑出 "冲锋衣",递给你(同时可能也会把 "要不要带羽绒服" 的信息记下来,给下次参考)。
专业说:它也分两步:
- 第一步:用 sigmoid 函数从细胞状态里筛选 "当前需要用哪些信息";
- 第二步:把选中的信息用 tanh 函数处理后,生成 隐藏状态(Hidden State)(相当于 "递给你的冲锋衣");
- 隐藏状态既是当前时刻的输出(比如理解句子的当前词、预测当前时间点的数值),也会传给下一个时刻的 LSTM 单元(作为 "下次参考的信息")。
串起来再看:
比如处理句子 "小明买了个苹果,他吃了它":
- 细胞状态(仓库):会记住 "苹果" 这个核心信息(长期记忆);
- 遗忘门:看到 "他" 时,会忘记前面可能无关的信息(比如 "买" 这个动作的细节);
- 输入门:把 "苹果" 这个新信息存入细胞状态;
- 输出门:看到 "它" 时,从细胞状态里取出 "苹果",确定 "它" 指的是苹果(隐藏状态输出这个结果)。
术语小结表:
| 专业术语 | 类比角色 | 核心功能 |
|---|---|---|
| 细胞状态(Cell State) | 长期记忆仓库 | 存储贯穿序列的核心信息 |
| 遗忘门(Forget Gate) | 扔垃圾的管理员 | 筛选并丢弃细胞状态中的无用旧信息 |
| 输入门(Input Gate) | 存新货的管理员 | 筛选并存储新信息到细胞状态 |
| 候选细胞状态 | 整理好的新货 | 待存入仓库的新信息(预处理后) |
| 输出门(Output Gate) | 取东西的管理员 | 从细胞状态中筛选信息生成隐藏状态 |
| 隐藏状态(Hidden State) | 当前要用的东西 | 作为当前输出,同时传给下一个时刻 |
这样一来,每个术语对应的 "功能" 和 "类比角色" 就清晰了~ 核心就是:细胞状态存长期记忆,三个门控(遗忘、输入、输出)负责 "删、存、取",解决了普通 RNN "记不住长远信息" 的问题。
简易代码实战(简模型构建)
一、初始化函数:创建四个线性层和激活函数
def __init__(self, input_size, hidden_size):
super(FixedLSTMCell, self).__init__()
self.hidden_size = hidden_size
# 为每个门单独设置线性层
self.forget_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.input_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.cell_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.output_gate = nn.Linear(input_size + hidden_size, hidden_size)
self.sigmoid = nn.Sigmoid() # 门控函数(输出0-1之间的值)
self.tanh = nn.Tanh() # 状态激活函数(输出-1到1之间的值)关键点:
- 线性层的输入维度 :
input_size + hidden_size,因为要拼接当前输入和上一时刻的隐藏状态 - 线性层的输出维度 :
hidden_size,与隐藏状态维度一致 - sigmoid 函数:将值压缩到 0,1 区间,用于控制门的 "开关程度"
- tanh 函数:将值压缩到 -1,1 区间,用于生成新信息和规范化细胞状态
二、前向传播:五步核心操作
1. 输入拼接
combined = torch.cat((input, hidden), 1)- 操作 :将当前输入
input(形状:[batch_size, input_size])和上一时刻的隐藏状态hidden(形状:[batch_size, hidden_size])在维度 1 上拼接 - 结果 :
combined的形状为[batch_size, input_size + hidden_size]
2. 计算遗忘门
f_t = self.sigmoid(self.forget_gate(combined))- 数学公式 :
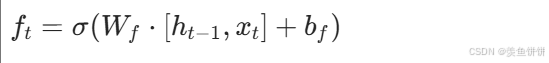
- 分步操作 :
self.forget_gate(combined):线性变换,计算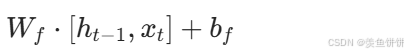
self.sigmoid(...):应用 sigmoid 函数,将结果压缩到 0,1 区间
- 作用:决定上一时刻的细胞状态 \(C_{t-1}\) 中哪些信息需要被遗忘
3. 计算输入门和候选状态
i_t = self.sigmoid(self.input_gate(combined))
c_tilde = self.tanh(self.cell_gate(combined))- 输入门数学公式 :
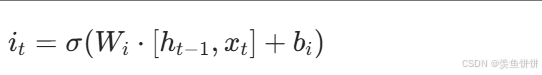
- 作用:决定候选状态 \(\tilde{C}_t\) 中哪些信息需要被加入到细胞状态
- 候选状态数学公式 :
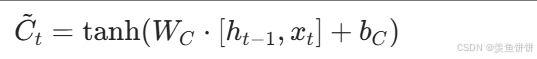
- 作用:基于当前输入生成的新信息,范围在 -1,1 之间
4. 更新细胞状态
cell = f_t * cell + i_t * c_tilde- 数学公式 :
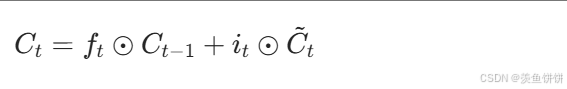
- 分步操作 :
- 遗忘旧信息 :
f_t * cell,将上一时刻的细胞状态按元素与遗忘门输出相乘- 如果 f_t某维度为 0,则对应维度的旧信息被完全遗忘
- 添加新信息 :
i_t * c_tilde,将候选状态按元素与输入门输出相乘- 如果 i_t 某维度为 1,则对应维度的新信息被完全保留
- 合并操作:将两部分相加,得到新的细胞状态
- 遗忘旧信息 :
5. 计算输出门和更新隐藏状态
o_t = self.sigmoid(self.output_gate(combined))
hidden = o_t * self.tanh(cell)- 输出门数学公式 :
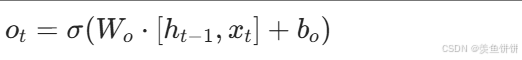
- 作用:决定细胞状态 C_t中哪些信息需要被输出为隐藏状态 h_t
- 隐藏状态更新公式 :
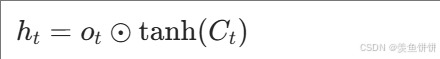
- 分步操作 :
self.tanh(cell):将细胞状态的值压缩到 -1,1 区间o_t * ...:按元素与输出门相乘,控制输出哪些信息
- 分步操作 :
三、用具体数字示例
假设:
input_size = 3(当前输入有 3 个特征)hidden_size = 4(隐藏状态有 4 个维度)batch_size = 1(单个样本)
1. 输入和隐藏状态
input = torch.tensor([[0.2, 0.5, 0.3]]) # 形状: [1, 3]
hidden = torch.tensor([[0.1, 0.4, 0.3, 0.2]]) # 形状: [1, 4]2. 拼接后的结果
combined = torch.cat((input, hidden), 1)
# combined = [[0.2, 0.5, 0.3, 0.1, 0.4, 0.3, 0.2]] # 形状: [1, 7]3. 计算遗忘门(简化示例)
假设 forget_gate 的权重矩阵 W_f和偏置 b_f为:
W_f = [[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7],
[0.2, 0.1, 0.4, 0.3, 0.6, 0.5, 0.8],
[0.3, 0.4, 0.1, 0.2, 0.7, 0.8, 0.5],
[0.4, 0.3, 0.2, 0.1, 0.8, 0.7, 0.6]] # 形状: [4, 7]
b_f = [0.1, 0.2, 0.3, 0.4] # 形状: [4]
则:
# 线性变换: W_f * combined + b_f
linear_output = [[1.05, 1.25, 1.35, 1.45]] # 形状: [1, 4]
# 应用sigmoid
f_t = sigmoid(linear_output) = [[0.74, 0.78, 0.80, 0.81]] # 形状: [1, 4]四、完整代码 + 注释
class FixedLSTMCell(nn.Module):
def __init__(self, input_size, hidden_size):
super(FixedLSTMCell, self).__init__()
self.hidden_size = hidden_size
# 四个线性层,分别对应四个门
self.forget_gate = nn.Linear(input_size + hidden_size, hidden_size) # 遗忘门
self.input_gate = nn.Linear(input_size + hidden_size, hidden_size) # 输入门
self.cell_gate = nn.Linear(input_size + hidden_size, hidden_size) # 候选状态
self.output_gate = nn.Linear(input_size + hidden_size, hidden_size) # 输出门
# 激活函数
self.sigmoid = nn.Sigmoid() # 将值压缩到[0,1],用于门控
self.tanh = nn.Tanh() # 将值压缩到[-1,1],用于生成新信息和规范化细胞状态
def forward(self, input, hidden, cell):
"""
input: 当前输入,形状为 [batch_size, input_size]
hidden: 上一时刻的隐藏状态,形状为 [batch_size, hidden_size]
cell: 上一时刻的细胞状态,形状为 [batch_size, hidden_size]
"""
# 1. 拼接当前输入和上一时刻的隐藏状态
combined = torch.cat((input, hidden), 1) # 形状: [batch_size, input_size + hidden_size]
# 2. 计算四个门控信号
f_t = self.sigmoid(self.forget_gate(combined)) # 遗忘门: [batch_size, hidden_size]
i_t = self.sigmoid(self.input_gate(combined)) # 输入门: [batch_size, hidden_size]
c_tilde = self.tanh(self.cell_gate(combined)) # 候选状态: [batch_size, hidden_size]
o_t = self.sigmoid(self.output_gate(combined)) # 输出门: [batch_size, hidden_size]
# 3. 更新细胞状态
# - f_t * cell: 选择性遗忘旧信息
# - i_t * c_tilde: 选择性添加新信息
cell = f_t * cell + i_t * c_tilde # 形状: [batch_size, hidden_size]
# 4. 更新隐藏状态
# - self.tanh(cell): 规范化细胞状态的值到[-1,1]
# - o_t * ...: 选择性输出细胞状态的信息
hidden = o_t * self.tanh(cell) # 形状: [batch_size, hidden_size]
return hidden, cell # 返回新的隐藏状态和细胞状态五、关键总结
- 四个线性层对应四个门,每个门学习不同的权重矩阵
- 三个门控机制(遗忘门、输入门、输出门)通过 sigmoid 函数实现 "开关" 控制
- 细胞状态通过选择性遗忘和添加实现长期记忆
- 隐藏状态是细胞状态的选择性输出,也是 LSTM 的最终输出