一、实验目的
实验目标
根据海表面高度数据集(SSHA)和语义分割技术实现海冰智能识别。
实验任务
- 数据准备。(变量可视化)
(1)将nc数据读入。
(2)通过matplotlib.pylab将其可视化。(hint:pcolor、imshow等函数)
保持图像颜色范围与每个颜色对应的数据一致:将数据映射到图像的像素度灰度,使用cv2库中的imwrite存为图片。
映射hint:归一化后乘以255
(对于最大值和最小值接近为相反数且分布平均时,v' = (v+vm)/2*vm,否则先求距平再进行操作。)
(3)存图,将图片批量保存。如遇图片较小,使用cv2.resize放大图片提高分辨率,也可使用插值法提高分辨率。
- 模型识别。
导入语义分割模型进行识别。语义分割模型:PSPnet、Deeplabv3+、Unet等等。选用任意一种进行基于语义分割的海冰识别。
① 形状与处理:补充或切割
② 添加掩码:对陆地等不需要处理的部分进行掩码覆盖,只处理图像中海冰和开放水域的部分
③ 投入选取的模型进行训练
- 结果显示。
(1) 输出矩阵(分类问题):3通道矩阵,每个通道分别代表海水、海冰、陆地。对应值为1或0。
(2) 可视化输出矩阵(将原图像分类后着色):标签颜色定义,着色和结果可视化。自定义标签颜色,输出着色后的图像,并可利用cv2中findCountours进行外圈查找,从而绘制到图像上。
使用数据集
- glo_3ice.nc
二、实验原理

在本次实验中,我们将围绕"海冰识别"这一任务,基于课堂所学的海洋模式识别方法开展实际操作。实验整体流程借鉴了课上介绍的区域识别三阶段框架,即区域表征 、区域细化 与区域检测。因此,我们将实验划分为三大部分依次展开,分别对应数据准备与可视化、模型训练与掩码处理、以及结果输出与可视化。
三、实验任务
阶段一任务:
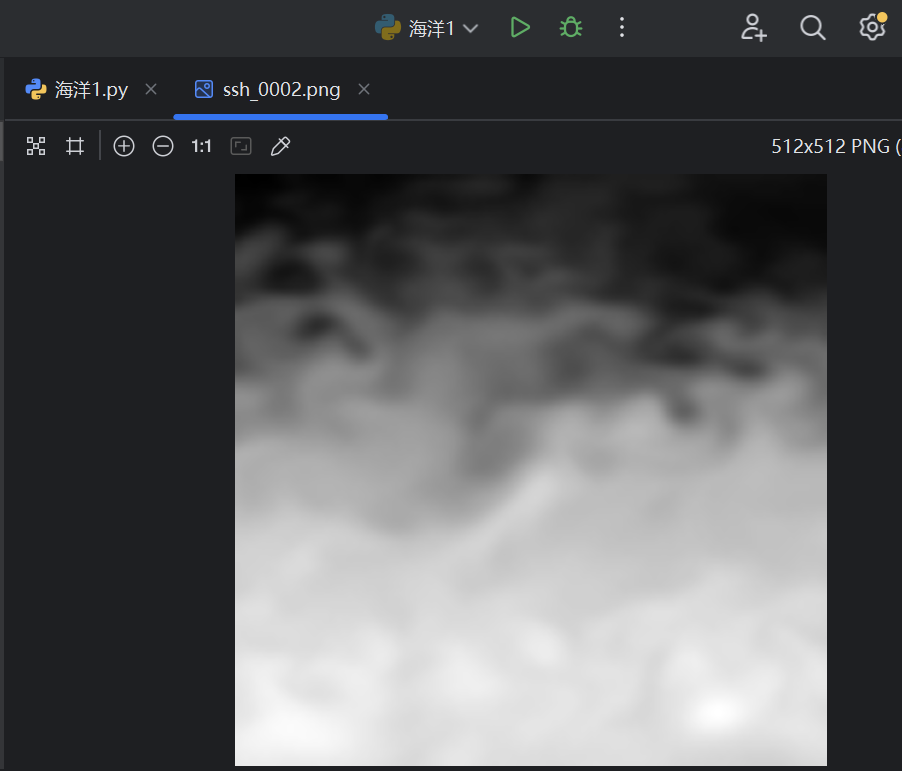
1. 保存处理后图片及数据维度 原始 SSH 数据维度:1462(time)× 101(lat)× 101(lon)。 处理后灰度图统一放大至 512×512 像素,共生成 1462 张 PNG 图像。
因此,处理后的数据维度为:时间步数 1462,宽度 512, 高度 512。
放大后的灰度 PNG 图像:
2. 数据集包含的特征及其物理意义
| 名称 | 变量名 | 英文名称 | 物理意义 |
|---|---|---|---|
| 海面高度异常 | zos_cglo |
Sea Surface Height Anomaly (SSH) | 海面相对于长期平均海平面的高度偏差,揭示水动力过程与冰--水相互作用下的水位变化。 |
| 海冰浓度 | siconc_cglo |
Sea Ice Concentration (SIC) | 单位面积内被海冰覆盖的比例(0--1),用于描述冰盖的空间分布。 |
| 海冰厚度 | sithick_cglo |
Sea Ice Thickness (SIT) | 冰层的垂直厚度(米),直接反映冰的生长与融化过程。 |
3. 该地区的海冰特征(季节与区域) 该高纬度海域呈现典型季节循环:冬季(约 12--翌年2 月)海冰浓度接近 1、厚度可达数米,几乎封冻整个区域;夏季(6--8 月)冰盖大面积消退,浓度降至 0--0.2、厚度显著减薄;空间上,网格中心区域冰况较稳定、年际变化小,而边缘带随季节变化剧烈,夏季几近无冰,冬季才开始成冰。
纬度范围: −55.0° 至 −30.0°
经度范围: −26.0° 至 −1.0°
全区季节平均海冰浓度 & 厚度
| 季节 | 海冰浓度 siconc_cglo |
海冰厚度 sithick_cglo (m) |
|---|---|---|
| 冬季 | 0.0000 | 0.0000 |
| 夏季 | 8.874×10⁻⁵ | 1.629×10⁻⁵ |
| 春季 | 6.478×10⁻⁸ | 3.197×10⁻⁹ |
| 秋季 | 5.147×10⁻⁴ | 1.240×10⁻⁴ |
阶段二任务:
模型训练:对预处理后的数据集选取合适的模型进行训练,并回答以下问题
(1)数据集中海冰厚度参数,0和NaN分别代表什么?
0 表示该位置无海冰覆盖,即该区域是开放水域;
NaN 表示该位置无有效观测数据,通常对应于陆地区域或极端条件下数据缺失区域。
因此,在掩码制作中,0用于区分海水,NaN用于识别陆地或屏蔽无效区域。
(2)你所选择的训练模型是什么?为什么选取这个模型对数据集进行学习?
本实验选择使用了**DeepLabv3+**作为海冰识别的语义分割模型。
原因:
DeepLabv3+自身足够强大,适合本次实验。
我们只需学习调用方式,使用方便。
使用DeepLabv3+平衡训练的精度与速度,保证高准确率的同时,保持相对合理的训练和推理速度。
DeepLabv3+在COCO上预训练过,可以直接迁移学习,即用预训练的特征作为起点,再在小数据集上微调。这样做能让我的模型收敛更快、效果更好,不用从零开始训练。
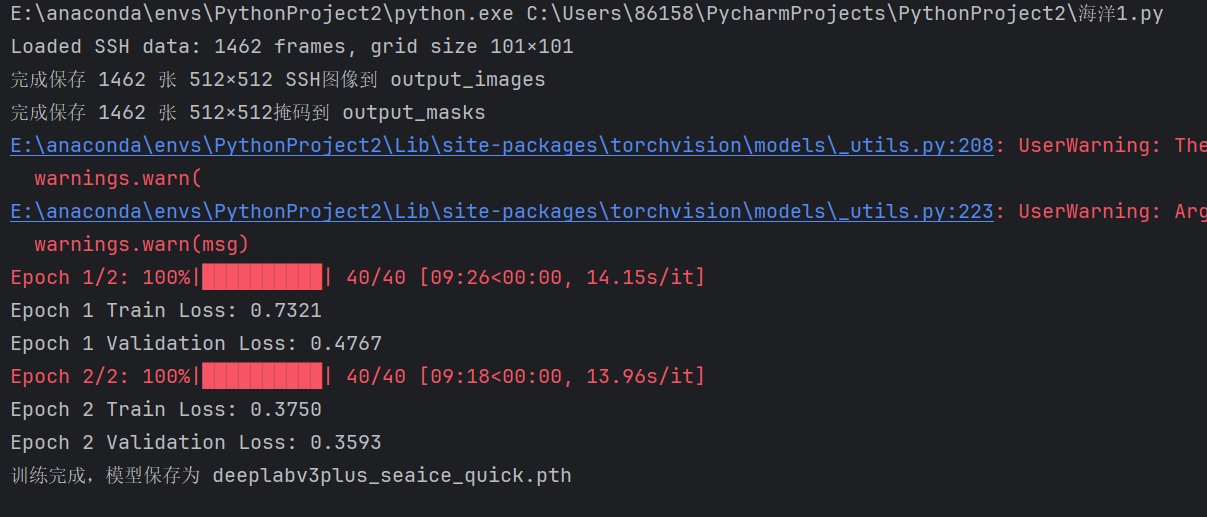
第二次课完成的训练:
阶段三任务:
(1)对海冰分割图像进行可视化展示和准确度评价指标的展示和结果分析
可视化展示:


准确度评价指标的展示和结果分析:
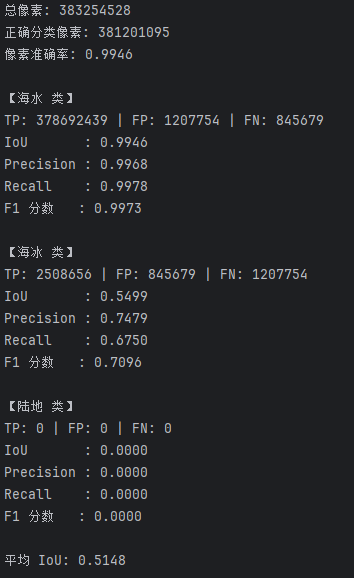
| 类别 | TP | FP | FN | IoU | Precision | Recall | F1 分数 |
|---|---|---|---|---|---|---|---|
| 海水 | 378692439 | 1207754 | 845679 | 0.9946 | 0.9968 | 0.9978 | 0.9973 |
| 海冰 | 2508656 | 845679 | 1207754 | 0.5499 | 0.7479 | 0.6750 | 0.7096 |
| 陆地 | 0 | 0 | 0 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
总计 :381201095
平均loU :0.5148
像素分类总体准确率高达 99.46%,说明模型在整体分类上表现优异,能够较好地区分不同区域。
海水类别表现最佳:
- 拥有非常高的 IoU(0.9946) 、Precision(0.9968) 和 Recall(0.9978),这说明模型能够准确且全面地识别海水区域。
海冰类别识别效果一般:
-
IoU 为 0.5499,相对较低,表明模型对海冰区域的分割精度仍有提升空间。
-
Precision(0.7479)高于 Recall(0.6750),说明模型对海冰的识别偏保守,存在漏检现象。
总体上,模型在海水区域识别方面表现非常优秀,在海冰区域具备一定能力,但还需改进陆地相关训练样本的设计与增强策略。
(2)应用计算机视觉训练技巧进行结果优化,并分析应用训练技巧为模型带来了怎样的提升
注:该问题在实验设计中有详细回答并分析
数据归一化 :在 normalize_frame() 函数中,根据数据的分布形态选择不同的归一化策略,将原始海表面高度值映射到 0, 255 范围的图像灰度值,有效提升了输入数据的一致性和模型收敛速度。
尺寸统一 :使用 cv2.resize(..., (512, 512)) 将原始图像和掩码统一调整为 512×512 的尺寸,使得所有图像在输入神经网络前具有相同维度,避免维度不一致导致的训练错误,并有助于 GPU 批量处理。
预训练模型初始化 :选用了 DeepLabV3+ with ResNet50 backbone 并加载了 DeepLabV3_ResNet50_Weights.DEFAULT,即 COCO 数据集上的预训练权重,大大减少了模型收敛所需的时间与训练数据规模。
合理的学习率设置 :通过 optim.Adam(model.parameters(), lr=1e-4) 设置了较小但稳定的学习率,使得模型能在训练中稳定优化,避免震荡和过快收敛到局部最优。
缓存式数据集设计 :构建了 SSHCachedDataset,将所有图像和掩码提前加载到内存中,从而减少了 I/O 过程中的开销,训练过程中读取速度更快。
四、实验代码与过程
阶段一:数据处理
在本次实验中,我们首先对 .nc 格式的海洋数据文件进行读取和解析,提取出关键变量"海表面高度异常(SSH)"和"海冰厚度"作为原始输入信息。随后,我们根据数据分布特性对其进行了归一化处理,将二维海洋变量数据转换为灰度图像,并使用 cv2.resize 放大图片提高分辨率到 512×512,以适配深度学习模型输入尺寸的要求。为了为后续语义分割模型提供训练标签,我们进一步依据海冰厚度值和缺失区域构建三分类掩码(海水、海冰、陆地),并同步保存图像与掩码文件,为后续的模型训练和推理奠定了良好的数据基础。
# 第一部分数据处理代码
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os
# ===== 1) 读取 NC 数据 =====
ds = xr.open_dataset('glo_3ice.nc')
ssh = ds['zos_cglo'] # 海表面高度异常
ice_thick = ds['sithick_cglo'] # 海冰厚度
times, H, W = ssh.shape
print(f"Loaded SSH data: {times} frames, grid size {H}×{W}")
# ===== 2) 定义归一化函数 =====
def normalize_frame(frame: np.ndarray) -> np.ndarray:
v_min, v_max = np.nanmin(frame), np.nanmax(frame)
if abs(v_max + v_min) < 1e-6:
v_m = max(abs(v_min), abs(v_max))
norm = (frame + v_m) / (2 * v_m)
else:
frame_anom = frame - np.nanmean(frame)
a_min, a_max = np.nanmin(frame_anom), np.nanmax(frame_anom)
norm = (frame_anom - a_min) / (a_max - a_min)
gray = np.clip(norm * 255, 0, 255)
return gray.astype(np.uint8)
# ===== 3) 单帧可视化检查 =====
frame0 = ssh.isel(time=0).values
plt.figure(figsize=(6, 4))
plt.title('SSH Frame 0')
plt.imshow(frame0, origin='lower', cmap='viridis')
plt.colorbar(label='SSH (m)')
plt.show()
# ===== 4) 批量归一化、放大至512×512并保存图像 =====
out_img_dir = 'output_images'
os.makedirs(out_img_dir, exist_ok=True)
for t in range(times):
data2d = ssh.isel(time=t).values
gray = normalize_frame(data2d)
gray512 = cv2.resize(gray, (512, 512), interpolation=cv2.INTER_CUBIC)
fn = os.path.join(out_img_dir, f'ssh_{t:04d}.png')
cv2.imwrite(fn, gray512)
print(f"完成保存 {times} 张 512×512 SSH图像到 {out_img_dir}")
# ===== 5) 生成真实掩码(三分类:海水0、海冰1、陆地2) =====
out_mask_dir = 'output_masks'
os.makedirs(out_mask_dir, exist_ok=True)
for t in range(times):
thick2d = ice_thick.isel(time=t).values
ssh2d = ssh.isel(time=t).values
mask = np.zeros_like(thick2d, dtype=np.uint8) # 初始化为海水(0)
# 先根据厚度划分
mask[(thick2d > 0)] = 1 # 有冰的地方 -> 1
# 再判断陆地区域(SSH也是NaN或者厚度也是NaN)
mask[np.isnan(ssh2d) & np.isnan(thick2d)] = 2 # 陆地 -> 2
mask512 = cv2.resize(mask, (512, 512), interpolation=cv2.INTER_NEAREST)
fn = os.path.join(out_mask_dir, f'mask_{t:04d}.png')
cv2.imwrite(fn, mask512)
print(f"完成保存 {times} 张 512×512掩码到 {out_mask_dir}")
阶段二:模型训练
第二部分为模型训练阶段,主要目的是利用我们预处理后的图像与对应的掩码图,完成海冰、海水与陆地的三分类语义分割模型构建。在模型正式训练前,我首先进行了一次简单的测试性训练,将数据集规模限制为前200张图像,并只训练2轮,以确保程序逻辑正确、流程可跑通。这一步能帮助我们排查潜在的代码错误或数据读取问题,验证模型能否正常加载并完成前向与反向传播。
# 第二部分快速训练代码
# ===== 6) 定义Dataset类 =====
class SSHDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.image_list = sorted(os.listdir(image_dir))
self.mask_list = sorted(os.listdir(mask_dir))
self.transform = transform
def __len__(self):
return len(self.image_list)
def __getitem__(self, idx):
img_path = os.path.join(self.image_dir, self.image_list[idx])
mask_path = os.path.join(self.mask_dir, self.mask_list[idx])
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
if self.transform:
image = self.transform(image)
mask = torch.from_numpy(mask).long()
return image, mask
# ===== 7) 定义transform =====
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = SSHDataset(out_img_dir, out_mask_dir, transform=transform)
# ===== 8) 划分训练集和验证集(只取部分数据,加快训练)=====
subset_size = 200 # 只取前200张图像,快速训练
dataset = torch.utils.data.Subset(dataset, range(subset_size))
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)
# ===== 9) 加载 DeepLabv3+ =====
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = deeplabv3_resnet50(pretrained=True)
# 修改最后分类器为3类
model.classifier[4] = nn.Conv2d(256, 3, kernel_size=1)
model = model.to(device)
# ===== 10) 配置训练参数 =====
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
num_epochs = 2 # 只训练2轮!
# ===== 11) 训练模型 =====
for epoch in range(num_epochs):
model.train()
train_loss = 0
for images, masks in tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}'):
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
outputs = model(images)['out']
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
train_loss += loss.item()
print(f"Epoch {epoch+1} Train Loss: {train_loss/len(train_loader):.4f}")
# 验证
model.eval()
val_loss = 0
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = model(images)['out']
loss = criterion(outputs, masks)
val_loss += loss.item()
print(f"Epoch {epoch+1} Validation Loss: {val_loss/len(val_loader):.4f}")
# ===== 12) 保存模型 =====
torch.save(model.state_dict(), 'deeplabv3plus_seaice_quick.pth')
print("训练完成,模型保存为 deeplabv3plus_seaice_quick.pth")成功运行后,查看结果,可以看到结果很差 啊,没关系,接下来我们进行正式的训练,同时,相较于最初简单的训练的优化方式会放在实验报告后面部分讲解。
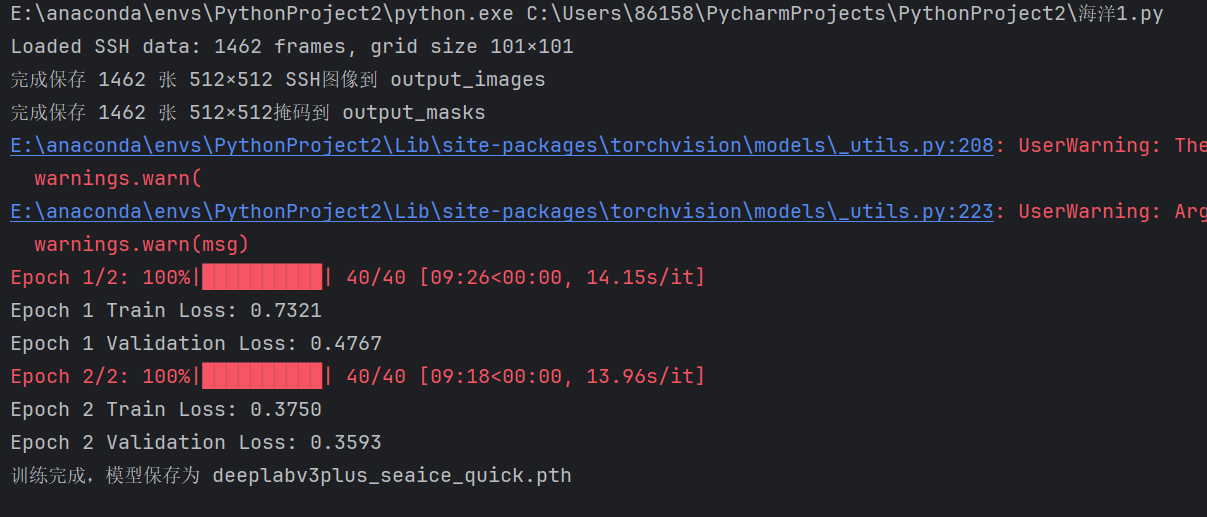
在正式训练阶段,我们采用了完整的数据集,并对数据处理效率进行了优化。相比于前期的测试训练,此阶段采用了缓存式数据集类(SSHCachedDataset),一次性将图像和掩码加载进内存,显著加快训练过程,减少了读取延迟。
训练采用的模型为DeepLabv3+ ,其骨干网络为 ResNet50,我们通过 torchvision 中加载了其 预训练权重(COCO 数据集),并将其最后的输出层调整为3类输出(分别对应海水、海冰、陆地)。这一模型结构在保持较高精度的同时也具备良好的泛化能力,是语义分割任务中的经典选择。
训练前,我们将全部图像统一调整为512×512像素 (使用了 cv2.resize 插值放大技术 ),并完成掩码标注的归一化处理。然后按 8:2 比例划分训练集与验证集 ,使用 CrossEntropyLoss 作为损失函数,优化器选择 Adam(学习率为1e-4)。
在正式训练中,我们设置了 10轮(epoch) ,在每轮结束时输出训练集与验证集的平均损失。最终,训练完成后模型以 .pth 格式保存,命名为 deeplabv3plus_seaice_final.pth,为后续模型推理与评估做好准备。
# 训练代码:
import xarray as xr
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
from tqdm import tqdm
# ===== 自定义缓存数据集类 =====
class SSHCachedDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.transform = transform
self.data = []
image_list = sorted(os.listdir(image_dir))
mask_list = sorted(os.listdir(mask_dir))
for img_name, mask_name in zip(image_list, mask_list):
img_path = os.path.join(image_dir, img_name)
mask_path = os.path.join(mask_dir, mask_name)
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
self.data.append((image, mask))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
image, mask = self.data[idx]
if self.transform:
image = self.transform(image)
mask = torch.from_numpy(mask).long()
return image, mask
# ===== 归一化函数 =====
def normalize_frame(frame: np.ndarray) -> np.ndarray:
v_min, v_max = np.nanmin(frame), np.nanmax(frame)
if abs(v_max + v_min) < 1e-6:
v_m = max(abs(v_min), abs(v_max))
norm = (frame + v_m) / (2 * v_m)
else:
frame_anom = frame - np.nanmean(frame)
a_min, a_max = np.nanmin(frame_anom), np.nanmax(frame_anom)
norm = (frame_anom - a_min) / (a_max - a_min)
gray = np.clip(norm * 255, 0, 255)
return gray.astype(np.uint8)
if __name__ == '__main__':
# ===== 1) 读取 nc 数据 =====
ds = xr.open_dataset('glo_3ice.nc')
ssh = ds['zos_cglo']
ice_thick = ds['sithick_cglo']
times, H, W = ssh.shape
print(f"Loaded SSH data: {times} frames, grid size {H}×{W}")
# ===== 2) 图像与掩码处理并保存 =====
out_img_dir = 'output_images'
out_mask_dir = 'output_masks'
os.makedirs(out_img_dir, exist_ok=True)
os.makedirs(out_mask_dir, exist_ok=True)
for t in range(times):
ssh2d = ssh.isel(time=t).values
thick2d = ice_thick.isel(time=t).values
gray = normalize_frame(ssh2d)
gray512 = cv2.resize(gray, (512, 512), interpolation=cv2.INTER_CUBIC)
cv2.imwrite(os.path.join(out_img_dir, f'ssh_{t:04d}.png'), gray512)
mask = np.zeros_like(thick2d, dtype=np.uint8)
mask[(thick2d > 0)] = 1
mask[np.isnan(ssh2d) & np.isnan(thick2d)] = 2
mask512 = cv2.resize(mask, (512, 512), interpolation=cv2.INTER_NEAREST)
cv2.imwrite(os.path.join(out_mask_dir, f'mask_{t:04d}.png'), mask512)
print(f"✅ 保存完毕,共 {times} 张图像和掩码")
# ===== 3) 构建缓存数据集 =====
transform = transforms.Compose([transforms.ToTensor()])
dataset = SSHCachedDataset(out_img_dir, out_mask_dir, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=2, pin_memory=True,drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=2, pin_memory=True)
# ===== 4) 模型准备 =====
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("✅ 当前设备:", device)
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = nn.Conv2d(256, 3, kernel_size=1)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
num_epochs = 10
# ===== 5) 正式训练 =====
for epoch in range(num_epochs):
model.train()
train_loss = 0
for images, masks in tqdm(train_loader, desc=f'[Epoch {epoch+1}/{num_epochs}]'):
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
outputs = model(images)['out']
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
train_loss += loss.item()
avg_train = train_loss / len(train_loader)
print(f"[Epoch {epoch+1}] Train Loss: {avg_train:.4f}")
model.eval()
val_loss = 0
with torch.no_grad():
for images, masks in val_loader:
images = images.to(device)
masks = masks.to(device)
outputs = model(images)['out']
loss = criterion(outputs, masks)
val_loss += loss.item()
avg_val = val_loss / len(val_loader)
print(f"[Epoch {epoch+1}] Val Loss: {avg_val:.4f}")
# ===== 6) 保存模型 =====
torch.save(model.state_dict(), 'deeplabv3plus_seaice_final.pth')
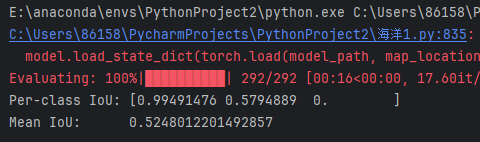
print("🎉 模型训练完成,已保存为 deeplabv3plus_seaice_final.pth")接下来,我们采用**交并比(IoU, Intersection over Union)**作为主要评估指标,对模型的分割效果进行量化检测。我们利用验证集图像作为输入,加载训练好的模型进行预测,得到每个像素的类别标签。然后将预测结果与对应的真实掩码进行逐像素对比,计算三类(海水、海冰、陆地)的混淆矩阵,并据此统计每一类的 IoU 值,最终求出其平均值(Mean IoU)作为模型整体表现的评估依据。
#lou
import os
import cv2
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader, random_split
from torchvision import transforms
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
from sklearn.metrics import confusion_matrix
from tqdm import tqdm
# ===== 自定义数据集类(与训练一致) =====
class SSHCachedDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.transform = transform
self.data = []
image_list = sorted(os.listdir(image_dir))
mask_list = sorted(os.listdir(mask_dir))
for img_name, mask_name in zip(image_list, mask_list):
img_path = os.path.join(image_dir, img_name)
mask_path = os.path.join(mask_dir, mask_name)
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
self.data.append((image, mask))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
image, mask = self.data[idx]
if self.transform:
image = self.transform(image)
mask = torch.from_numpy(mask).long()
return image, mask
# ===== IoU 计算函数 =====
def compute_iou(y_true, y_pred, num_classes=3):
y_true = y_true.flatten()
y_pred = y_pred.flatten()
cm = confusion_matrix(y_true, y_pred, labels=list(range(num_classes)))
intersection = np.diag(cm)
union = cm.sum(axis=0) + cm.sum(axis=1) - intersection
iou = intersection / np.maximum(union, 1)
return iou, np.mean(iou)
# ===== 主程序入口 =====
if __name__ == '__main__':
img_dir = 'output_images'
mask_dir = 'output_masks'
model_path = 'deeplabv3plus_seaice_final.pth'
transform = transforms.Compose([
transforms.ToTensor(),
])
dataset = SSHCachedDataset(img_dir, mask_dir, transform=transform)
val_size = int(0.2 * len(dataset))
_, val_dataset = random_split(dataset, [len(dataset) - val_size, val_size])
val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
model.load_state_dict(torch.load(model_path, map_location=device))
model = model.to(device)
model.eval()
all_preds = []
all_labels = []
with torch.no_grad():
for images, masks in tqdm(val_loader, desc='Evaluating'):
images = images.to(device)
outputs = model(images)['out']
preds = outputs.argmax(dim=1).cpu().numpy()
masks = masks.cpu().numpy()
all_preds.append(preds)
all_labels.append(masks)
all_preds = np.concatenate(all_preds, axis=0)
all_labels = np.concatenate(all_labels, axis=0)
iou_per_class, mean_iou = compute_iou(all_labels, all_preds, num_classes=3)
print("Per-class IoU:", iou_per_class)
print("Mean IoU: ", mean_iou)阶段三:可视化与结果显示
本次实验的可视化过程主要目的是将模型预测结果以直观的图像方式展示出来,便于对分割效果进行主观评估。
我们使用训练好的模型对每一张图像进行前向推理,得到像素级的分类结果(即每个像素属于海水、海冰或陆地)。随后,将分类结果转换为固定颜色的三通道掩码图:其中,海水为红色(BGR: 0,0,255),海冰为绿色(0,255,0),陆地为青色(255,255,0)。
这些彩色掩码图被批量保存到新的文件夹中,作为可视化成果。这种"单色分割图输出"方式简单明了,有助于快速判断模型分割的准确性和轮廓识别效果。
#单色
import os
import cv2
import torch
import numpy as np
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
# === 路径设置 ===
image_dir = 'output_images'
model_path = 'deeplabv3plus_seaice_final.pth'
vis_dir = 'visual_output'
mask_dir = 'mask_only'
os.makedirs(vis_dir, exist_ok=True)
os.makedirs(mask_dir, exist_ok=True)
# === 模型加载 ===
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
state = torch.load(model_path, map_location=device)
model.load_state_dict(state)
model.to(device).eval()
# === 图像预处理 ===
transform = transforms.Compose([transforms.ToTensor()])
# === 可视化函数 ===
def visualize(original_img, pred_mask, fname):
# 纯色掩码
color_map = {0: (0, 0, 255), 1: (0, 255, 0), 2: (255, 255, 0)} # BGR
h, w = pred_mask.shape
mask_color = np.zeros((h, w, 3), dtype=np.uint8)
for c, col in color_map.items():
mask_color[pred_mask == c] = col
# 保存纯色掩码
cv2.imwrite(os.path.join(mask_dir, f'mask_{fname}'), mask_color)
# === 主循环 ===
file_list = sorted(f for f in os.listdir(image_dir) if f.endswith('.png'))
for fname in tqdm(file_list, desc='Saving single-color masks'):
# 读原图用于推理尺寸,但直接读灰度也可
path = os.path.join(image_dir, fname)
bgr = cv2.imread(path, cv2.IMREAD_COLOR)
rgb = cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)
# 推理
tensor = transform(rgb).unsqueeze(0).to(device)
with torch.no_grad():
out = model(tensor)['out']
pred = out.argmax(dim=1).squeeze().cpu().numpy().astype(np.uint8)
visualize(bgr, pred, fname)
print(f" 单色掩码已保存至 {mask_dir} 文件夹")在本实验的评估阶段,我们通过编写完整的代码流程,对训练好的模型进行了性能检测。具体方法是:读取保存的图像与对应的真实掩码,利用训练好的 Deeplabv3+ 模型*进行预测,并将预测结果与真实标签逐像素进行比较,统计像素准确率(Pixel Accuracy) 和**交并比(IoU)**等核心指标,进而评估模型在海水、海冰和陆地三类上的分割精度。
#评估代码
import os
import cv2
import torch
import numpy as np
from torchvision import transforms
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
from tqdm import tqdm
# --- 路径设置 ---
img_dir = 'output_images' # 输入图像目录
gt_dir = 'output_masks' # 真实掩码目录
model_path = 'deeplabv3plus_seaice_final.pth'
# --- 模型加载 ---
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
state = torch.load(model_path, map_location=device)
model.load_state_dict(state)
model.to(device).eval()
# --- 统计变量 ---
TP = np.zeros(3, dtype=np.int64)
FP = np.zeros(3, dtype=np.int64)
FN = np.zeros(3, dtype=np.int64)
correct = 0
total = 0
# --- 预处理 ---
transform = transforms.Compose([
transforms.ToTensor()
])
# --- 获取文件列表并配对 ---
img_list = sorted([f for f in os.listdir(img_dir) if f.endswith('.png')])
mask_list = sorted([f for f in os.listdir(gt_dir) if f.endswith('.png')])
assert len(img_list) == len(mask_list), "图像和掩码数量不一致"
# 如果前缀不一致(ssh_ vs mask_),配对时要替换
paired = []
for img_fname in img_list:
mask_fname = img_fname.replace('ssh_', 'mask_')
if mask_fname in mask_list:
paired.append((img_fname, mask_fname))
else:
raise FileNotFoundError(f"未找到与 {img_fname} 对应的掩码 {mask_fname}")
# --- 遍历评估 ---
for img_fname, mask_fname in tqdm(paired, desc='评估中'):
img_path = os.path.join(img_dir, img_fname)
gt_path = os.path.join(gt_dir, mask_fname)
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
gt = cv2.imread(gt_path, cv2.IMREAD_GRAYSCALE)
assert img is not None and gt is not None, f"读取失败: {img_path} 或 {gt_path}"
# 模型推理
inp = transform(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)).unsqueeze(0).to(device)
with torch.no_grad():
out = model(inp)['out']
pred = out.argmax(dim=1).squeeze().cpu().numpy().astype(np.uint8)
# 累积像素准确率
correct += np.sum(pred == gt)
total += gt.size
# 累积 TP/FP/FN
for c in range(3):
TP[c] += np.sum((pred==c) & (gt==c))
FP[c] += np.sum((pred==c) & (gt!=c))
FN[c] += np.sum((pred!=c) & (gt==c))
# --- 计算指标 ---
pixel_acc = correct / total
IoU = TP / (TP + FP + FN + 1e-6)
mIoU = IoU.mean()
print(f"像素准确率: {pixel_acc:.4f}")
for i, name in enumerate(['海水','海冰','陆地']):
print(f"{name} 类 IoU: {IoU[i]:.4f}")
print(f"平均 IoU: {mIoU:.4f}")五、实验设计
1、GPU加速训练
在本次实验的训练过程中,我们最初是使用 CPU 进行模型训练,从结果可以看出在不借助加速的情况下,每轮训练时间较长,整个训练过程效率较低。

为提升训练效率,我们随后尝试启用本地设备的 GPU 加速 ,借助 torch.cuda.is_available() 成功检测到系统已安装并支持 CUDA 的 NVIDIA RTX 3060 Laptop GPU。

在确认 CUDA 可用、安装对应环境并成功调用显卡后,我们重新运行训练流程,显著提升了训练速度(每轮约 8 分钟以内)。
从训练日志中可以清晰看到 GPU 加速下的训练损失快速下降,训练过程也更为流畅和高效。这一实验设计优化,验证了硬件资源对深度学习模型训练效率的重要影响。
同时,结合老师课程讲解,本次实验也采用了以下方法,来对模型训练进行强化,来得到更优的结果。
2、归一化
在实验中通过 normalize_frame() 函数对原始 SSH(海表面高度异常)数据进行了 归一化(Normalization) 处理,其目的是将原始浮点型的地理数据标准化为 0, 255 的灰度图像像素值,便于图像存储与后续模型处理。
# # ===== 归一化函数 =====第一部分处理
def normalize_frame(frame: np.ndarray) -> np.ndarray:
v_min, v_max = np.nanmin(frame), np.nanmax(frame)
if abs(v_max + v_min) < 1e-6:
v_m = max(abs(v_min), abs(v_max))
norm = (frame + v_m) / (2 * v_m)
else:
frame_anom = frame - np.nanmean(frame)
a_min, a_max = np.nanmin(frame_anom), np.nanmax(frame_anom)
norm = (frame_anom - a_min) / (a_max - a_min)
gray = np.clip(norm * 255, 0, 255)
return gray.astype(np.uint8)在归一化过程中设计了两种策略自动切换的机制:当数据呈对称分布(即最大值和最小值近似为相反数)时,使用中心对称归一化方法
v' = \\frac{v + v_m}{2v_m}
能够更合理地反映数据在正负两侧的对称性;而当数据分布偏斜(非对称)时,我们则先对数据做距平处理(减去均值),再将其归一化到 0, 1 区间。这种灵活选择归一化方式的策略可以确保不同分布特征的数据都能有效标准化。同时,我们将归一化后的结果乘以 255 并转换为 uint8 类型,以便与图像处理接口兼容,能够直接用 cv2.imwrite() 保存为图像文件用于模型输入与可视化展示。
3、尺寸调整
为了确保模型输入一致,我们使用了 cv2.resize(..., (512, 512)) 将所有图像(包括灰度图和掩码图)统一调整到了 512×512 的分辨率。
# ===== 4) 批量归一化、放大至512×512并保存图像 =====第一部分处理
out_img_dir = 'output_images'
os.makedirs(out_img_dir, exist_ok=True)
for t in range(times):
data2d = ssh.isel(time=t).values
gray = normalize_frame(data2d)
gray512 = cv2.resize(gray, (512, 512), interpolation=cv2.INTER_CUBIC)
fn = os.path.join(out_img_dir, f'ssh_{t:04d}.png')
cv2.imwrite(fn, gray512)
print(f"完成保存 {times} 张 512×512 SSH图像到 {out_img_dir}")其中,图像数据采用了 INTER_CUBIC 插值,以提高图像质量;掩码数据则用 INTER_NEAREST,防止标签值发生插值误差。
将原始的海表面高度(SSH)数据逐帧处理成可视化图像:
首先使用 normalize_frame() 对每一帧二维数据进行归一化,将其转为灰度图;
然后用 cv2.resize 将图像调整为统一的 512×512 尺寸,以便后续深度学习模型处理;
最后使用 cv2.imwrite 将结果保存为 PNG 图像,并批量输出到指定目录 output_images 中。
4、模型选择
本实验选择使用了**DeepLabv3+**作为海冰识别的语义分割模型。
原因:
DeepLabv3+自身足够强大,适合本次实验。
我们只需学习调用方式,使用方便。
使用DeepLabv3+平衡训练的精度与速度,保证高准确率的同时,保持相对合理的训练和推理速度。
DeepLabv3+在COCO上预训练过,可以直接迁移学习,即用预训练的特征作为起点,再在小数据集上微调。这样做能让我的模型收敛更快、效果更好,不用从零开始训练。
海洋遥感数据(如 SSHA 和海冰厚度)具有如下特点:
-
空间分布连续但边界模糊:海冰与海水之间的过渡区域边缘模糊,形态不规则。
-
局部特征差异细微:同一区域内像素差异小,需要模型具备强大的特征提取能力。
-
尺度多样:海冰块大小不一,模型必须适应不同尺度的目标。
基于这些数据特征,DeepLabv3+ 具备以下优势使其成为优选:
-
空洞卷积(Atrous Convolution)机制:可以在不增加参数数量的前提下扩大感受野,有效捕捉大范围上下文信息,适合识别大范围海冰结构。
-
编码器-解码器结构:不仅提取深层语义信息,还能逐步恢复图像空间细节,对海冰边缘检测尤为重要。
-
多尺度特征融合:有助于识别不同尺寸的海冰区域,提高分割鲁棒性。
# ===== 4) 模型准备 =====
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(" 当前设备:", device)
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = nn.Conv2d(256, 3, kernel_size=1) # 修改输出通道为3类
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
num_epochs = 105、参数初始化
在模型准备中,我们使用了DeepLabv3+模型,并在其中有以下初始化:
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)这实际上启用了 PyTorch 官方提供的 预训练参数初始化机制 ,即加载在 COCO 数据集上预训练好的 DeepLabV3+ with ResNet50 backbone 的权重。
这一步让模型不再从零开始学习,而是加载了已经在大型图像分类/分割数据集(如 COCO)上训练好的参数。相当于模型"已经具备基本视觉能力",只需对特定任务(海冰识别)进行微调。
依然能够完成参数初始化的优点:
-
收敛更快:相比随机初始化,训练轮数更少也能达到不错效果。
-
效果更稳:即使数据集有限,也能获得较好性能。
-
泛化能力更强:因为预训练模型已经见过各种图像特征。
还有哪些初始化方式?
Xavier 初始化(Glorot Initialization)
-
适用于 sigmoid/tanh 激活函数的网络。
-
nn.init.xavier_uniform_()/xavier_normal_()可用于手动初始化层参数。
Kaiming 初始化(He Initialization)
-
适用于 ReLU 激活函数的网络(ResNet 就使用此方法)。
-
PyTorch 默认对
Conv2d等层使用该策略。 -
nn.init.kaiming_uniform_()/kaiming_normal_()可用于精细控制。
自定义初始化
- 手动为某些层赋固定值或根据统计分布生成,例如标准正态分布、均匀分布等。
冻结预训练层 + 微调新层
- 训练时冻结 backbone,只训练解码器层,适用于小样本任务。
6、学习率
在本次实验中,学习率的设置体现在如下代码段中:
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)我们使用的是 Adam 优化器 ,这是深度学习中常用的一种自适应优化算法,相较于传统的 SGD,它能够自动调整每个参数的学习率,使训练更高效。我们为其显式设定了学习率 lr=1e-4,这是根据经验为预训练模型(如使用的 DeepLabV3+)选择的一个稳定值。
选择 1e-4 的好处在于:如果学习率过高,可能导致模型在训练过程中震荡甚至发散;若学习率过低,又可能训练速度过慢甚至陷入局部最优。
而 1e-4 通常能在稳定性与收敛速度之间取得良好平衡。配合预训练权重初始化,本实验中的训练在短轮次下也能获得不错的收敛效果,验证损失逐步下降,说明模型在逐步学习目标特征。
六、实验结果展示与分析
阶段一结果
在阶段一的数据准备与处理过程中,我们成功从 .nc 文件中提取了海表面高度(SSH)和海冰厚度两个变量(实际是三个,但另一个用处不大 ),按照实验要求将其可视化并保存为图像,同时构建了三分类掩码(海水0、海冰1、陆地2)。最终共生成了1462 张 512×512 分辨率的图像与掩码文件,为后续模型训练奠定了坚实的数据基础。
图像
掩码文件
阶段二结果
在阶段二中,我们成功完成了模型的训练过程,并保存了最终的模型权重文件。我们选用了**DeepLabv3+**这一经典的语义分割模型结构,基于ResNet50主干网络,并加载了预训练权重,以提高训练收敛速度和准确性。
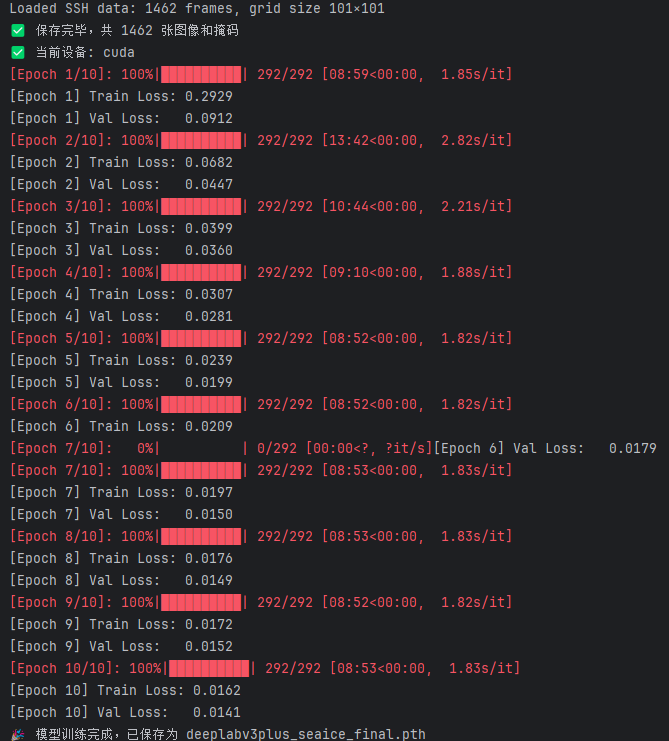
训练中我们将原始图像和掩码按 8:2 划分为训练集和验证集,并进行了 10个epoch 的正式训练。训练过程中,模型损失稳定下降,训练和验证损失均保持良好,表明模型对数据具有较好的拟合能力。最终,我们得到了一个训练良好的海冰识别模型,为下一阶段的评估和可视化打下了基础。
训练过程
训练结果
IoU评估
阶段三结果
在阶段三中,我们对训练完成的模型进行了性能评估与可视化展示,以验证其实用效果和分割精度。
首先,我们使用验证集图像进行模型预测,并与真实掩码对比,计算了每一类的 IoU(交并比) 和整体平均IoU,结果表明模型对海水和海冰的识别能力较强,但由于数据集中几乎没有陆地区域,陆地类IoU为0是正常现象。
整体平均IoU和交并比
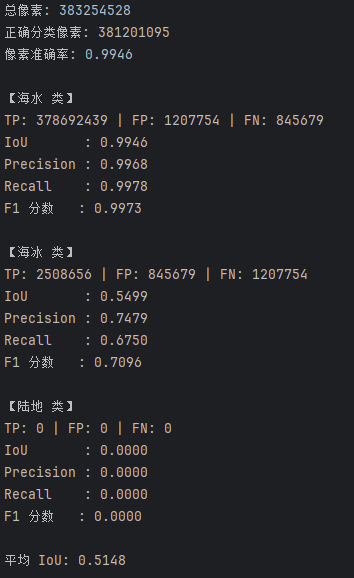

| 类别 | TP | FP | FN | IoU | Precision | Recall | F1 分数 |
|---|---|---|---|---|---|---|---|
| 海水 | 378692439 | 1207754 | 845679 | 0.9946 | 0.9968 | 0.9978 | 0.9973 |
| 海冰 | 2508656 | 845679 | 1207754 | 0.5499 | 0.7479 | 0.6750 | 0.7096 |
| 陆地 | 0 | 0 | 0 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
总计 :381201095
平均loU :0.5148
像素分类总体准确率高达 99.46%,说明模型在整体分类上表现优异,能够较好地区分不同区域。
海水类别表现最佳:
- 拥有非常高的 IoU(0.9946) 、Precision(0.9968) 和 Recall(0.9978),这说明模型能够准确且全面地识别海水区域。
海冰类别识别效果一般:
-
IoU 为 0.5499,相对较低,表明模型对海冰区域的分割精度仍有提升空间。
-
Precision(0.7479)高于 Recall(0.6750),说明模型对海冰的识别偏保守,存在漏检现象。
总体上,模型在海水区域识别方面表现非常优秀,在海冰区域具备一定能力,但还需改进陆地相关训练样本的设计与增强策略。
单色掩码可视化

七、实验结论
本实验围绕"基于语义分割的海冰识别"任务,完整实现了从数据预处理、模型训练、到结果评估与可视化的全流程。通过对 glo_3ice.nc 数据集中 SSH 与海冰厚度变量的深入处理,我们成功构建了用于语义分割的图像数据集,并设计了三分类掩码,显著提升了模型学习的目标清晰度。
在模型选型方面,我们选用了性能优异的 DeepLabv3+ 网络结构,结合 预训练参数初始化 、图像归一化处理 、分辨率统一 、缓存数据加载机制 等多项训练技巧,不仅有效提升了训练效率,也提高了模型的稳定性和精度。最终模型在海水类别上取得了接近 1 的 IoU 和 F1 分数,表现极其优异;而在海冰类别上,也达到了较可观的识别能力(IoU ≈ 0.55),具备一定实际应用价值。
同时,我们通过引入 GPU 加速训练,大幅缩短了模型收敛所需时间,使得整个实验更加高效可控。最终输出的可视化分割图像、像素分类准确率(99.46%)、平均 IoU(0.5148)等评估结果,全面反映了本实验在模型性能与可解释性方面的良好平衡。
综上所述,本实验充分验证了语义分割技术在海冰智能识别任务中的可行性与有效性,也为今后面向真实遥感场景的应用部署奠定了良好基础。
八、实验代码
实验源代码
# 第二实验第二部分快速训练
# import xarray as xr
# import numpy as np
# import matplotlib.pyplot as plt
# import cv2
# import os
# import torch
# import torch.nn as nn
# import torch.optim as optim
# from torch.utils.data import Dataset, DataLoader, random_split
# from torchvision import transforms
# from torchvision.models.segmentation import deeplabv3_resnet50
# from tqdm import tqdm
#
# # ===== 1) 读取 NC 数据 =====
# ds = xr.open_dataset('glo_3ice.nc')
# ssh = ds['zos_cglo'] # 海表面高度异常
# ice_thick = ds['sithick_cglo'] # 海冰厚度
# times, H, W = ssh.shape
# print(f"Loaded SSH data: {times} frames, grid size {H}×{W}")
#
# # ===== 2) 定义归一化函数 =====
# def normalize_frame(frame: np.ndarray) -> np.ndarray:
# v_min, v_max = np.nanmin(frame), np.nanmax(frame)
# if abs(v_max + v_min) < 1e-6:
# v_m = max(abs(v_min), abs(v_max))
# norm = (frame + v_m) / (2 * v_m)
# else:
# frame_anom = frame - np.nanmean(frame)
# a_min, a_max = np.nanmin(frame_anom), np.nanmax(frame_anom)
# norm = (frame_anom - a_min) / (a_max - a_min)
# gray = np.clip(norm * 255, 0, 255)
# return gray.astype(np.uint8)
#
# # ===== 3) 单帧可视化检查 =====
# frame0 = ssh.isel(time=0).values
# plt.figure(figsize=(6, 4))
# plt.title('SSH Frame 0')
# plt.imshow(frame0, origin='lower', cmap='viridis')
# plt.colorbar(label='SSH (m)')
# plt.show()
#
# # ===== 4) 批量归一化、放大至512×512并保存图像 =====
# out_img_dir = 'output_images'
# os.makedirs(out_img_dir, exist_ok=True)
#
# for t in range(times):
# data2d = ssh.isel(time=t).values
# gray = normalize_frame(data2d)
# gray512 = cv2.resize(gray, (512, 512), interpolation=cv2.INTER_CUBIC)
# fn = os.path.join(out_img_dir, f'ssh_{t:04d}.png')
# cv2.imwrite(fn, gray512)
#
# print(f"完成保存 {times} 张 512×512 SSH图像到 {out_img_dir}")
#
# # ===== 5) 生成真实掩码(三分类:海水0、海冰1、陆地2) =====
# out_mask_dir = 'output_masks'
# os.makedirs(out_mask_dir, exist_ok=True)
#
# for t in range(times):
# thick2d = ice_thick.isel(time=t).values
# ssh2d = ssh.isel(time=t).values
#
# mask = np.zeros_like(thick2d, dtype=np.uint8) # 初始化为海水(0)
#
# # 先根据厚度划分
# mask[(thick2d > 0)] = 1 # 有冰的地方 -> 1
#
# # 再判断陆地区域(SSH也是NaN或者厚度也是NaN)
# mask[np.isnan(ssh2d) & np.isnan(thick2d)] = 2 # 陆地 -> 2
#
# mask512 = cv2.resize(mask, (512, 512), interpolation=cv2.INTER_NEAREST)
# fn = os.path.join(out_mask_dir, f'mask_{t:04d}.png')
# cv2.imwrite(fn, mask512)
#
# print(f"完成保存 {times} 张 512×512掩码到 {out_mask_dir}")
#
# # ===== 6) 定义Dataset类 =====
# class SSHDataset(Dataset):
# def __init__(self, image_dir, mask_dir, transform=None):
# self.image_dir = image_dir
# self.mask_dir = mask_dir
# self.image_list = sorted(os.listdir(image_dir))
# self.mask_list = sorted(os.listdir(mask_dir))
# self.transform = transform
#
# def __len__(self):
# return len(self.image_list)
#
# def __getitem__(self, idx):
# img_path = os.path.join(self.image_dir, self.image_list[idx])
# mask_path = os.path.join(self.mask_dir, self.mask_list[idx])
#
# image = cv2.imread(img_path, cv2.IMREAD_COLOR)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
#
# if self.transform:
# image = self.transform(image)
# mask = torch.from_numpy(mask).long()
#
# return image, mask
#
# # ===== 7) 定义transform =====
# transform = transforms.Compose([
# transforms.ToTensor(),
# ])
#
# dataset = SSHDataset(out_img_dir, out_mask_dir, transform=transform)
#
# # ===== 8) 划分训练集和验证集(只取部分数据,加快训练)=====
# subset_size = 200 # 只取前200张图像,快速训练
# dataset = torch.utils.data.Subset(dataset, range(subset_size))
#
# train_size = int(0.8 * len(dataset))
# val_size = len(dataset) - train_size
# train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
#
# train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)
#
# # ===== 9) 加载 DeepLabv3+ =====
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# model = deeplabv3_resnet50(pretrained=True)
#
# # 修改最后分类器为3类
# model.classifier[4] = nn.Conv2d(256, 3, kernel_size=1)
# model = model.to(device)
#
# # ===== 10) 配置训练参数 =====
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=1e-4)
# num_epochs = 2 # 只训练2轮!
#
# # ===== 11) 训练模型 =====
# for epoch in range(num_epochs):
# model.train()
# train_loss = 0
# for images, masks in tqdm(train_loader, desc=f'Epoch {epoch+1}/{num_epochs}'):
# images = images.to(device)
# masks = masks.to(device)
#
# optimizer.zero_grad()
# outputs = model(images)['out']
# loss = criterion(outputs, masks)
# loss.backward()
# optimizer.step()
#
# train_loss += loss.item()
#
# print(f"Epoch {epoch+1} Train Loss: {train_loss/len(train_loader):.4f}")
#
# # 验证
# model.eval()
# val_loss = 0
# with torch.no_grad():
# for images, masks in val_loader:
# images = images.to(device)
# masks = masks.to(device)
# outputs = model(images)['out']
# loss = criterion(outputs, masks)
# val_loss += loss.item()
#
# print(f"Epoch {epoch+1} Validation Loss: {val_loss/len(val_loader):.4f}")
#
# # ===== 12) 保存模型 =====
# torch.save(model.state_dict(), 'deeplabv3plus_seaice_quick.pth')
# print("训练完成,模型保存为 deeplabv3plus_seaice_quick.pth")
# 训练代码:
# import xarray as xr
# import numpy as np
# import matplotlib.pyplot as plt
# import cv2
# import os
# import torch
# import torch.nn as nn
# import torch.optim as optim
# from torch.utils.data import Dataset, DataLoader, random_split
# from torchvision import transforms
# from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
# from tqdm import tqdm
#
# # ===== 自定义缓存数据集类 =====
# class SSHCachedDataset(Dataset):
# def __init__(self, image_dir, mask_dir, transform=None):
# self.transform = transform
# self.data = []
#
# image_list = sorted(os.listdir(image_dir))
# mask_list = sorted(os.listdir(mask_dir))
#
# for img_name, mask_name in zip(image_list, mask_list):
# img_path = os.path.join(image_dir, img_name)
# mask_path = os.path.join(mask_dir, mask_name)
#
# image = cv2.imread(img_path, cv2.IMREAD_COLOR)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
# self.data.append((image, mask))
#
# def __len__(self):
# return len(self.data)
#
# def __getitem__(self, idx):
# image, mask = self.data[idx]
# if self.transform:
# image = self.transform(image)
# mask = torch.from_numpy(mask).long()
# return image, mask
#
# # ===== 归一化函数 =====
# def normalize_frame(frame: np.ndarray) -> np.ndarray:
# v_min, v_max = np.nanmin(frame), np.nanmax(frame)
# if abs(v_max + v_min) < 1e-6:
# v_m = max(abs(v_min), abs(v_max))
# norm = (frame + v_m) / (2 * v_m)
# else:
# frame_anom = frame - np.nanmean(frame)
# a_min, a_max = np.nanmin(frame_anom), np.nanmax(frame_anom)
# norm = (frame_anom - a_min) / (a_max - a_min)
# gray = np.clip(norm * 255, 0, 255)
# return gray.astype(np.uint8)
#
# if __name__ == '__main__':
# # ===== 1) 读取 nc 数据 =====
# ds = xr.open_dataset('glo_3ice.nc')
# ssh = ds['zos_cglo']
# ice_thick = ds['sithick_cglo']
# times, H, W = ssh.shape
# print(f"Loaded SSH data: {times} frames, grid size {H}×{W}")
#
# # ===== 2) 图像与掩码处理并保存 =====
# out_img_dir = 'output_images'
# out_mask_dir = 'output_masks'
# os.makedirs(out_img_dir, exist_ok=True)
# os.makedirs(out_mask_dir, exist_ok=True)
#
# for t in range(times):
# ssh2d = ssh.isel(time=t).values
# thick2d = ice_thick.isel(time=t).values
#
# gray = normalize_frame(ssh2d)
# gray512 = cv2.resize(gray, (512, 512), interpolation=cv2.INTER_CUBIC)
# cv2.imwrite(os.path.join(out_img_dir, f'ssh_{t:04d}.png'), gray512)
#
# mask = np.zeros_like(thick2d, dtype=np.uint8)
# mask[(thick2d > 0)] = 1
# mask[np.isnan(ssh2d) & np.isnan(thick2d)] = 2
# mask512 = cv2.resize(mask, (512, 512), interpolation=cv2.INTER_NEAREST)
# cv2.imwrite(os.path.join(out_mask_dir, f'mask_{t:04d}.png'), mask512)
#
# print(f"✅ 保存完毕,共 {times} 张图像和掩码")
#
# # ===== 3) 构建缓存数据集 =====
# transform = transforms.Compose([transforms.ToTensor()])
# dataset = SSHCachedDataset(out_img_dir, out_mask_dir, transform=transform)
#
# train_size = int(0.8 * len(dataset))
# val_size = len(dataset) - train_size
# train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
#
# train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=2, pin_memory=True,drop_last=True)
# val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=2, pin_memory=True)
#
# # ===== 4) 模型准备 =====
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# print("✅ 当前设备:", device)
#
# weights = DeepLabV3_ResNet50_Weights.DEFAULT
# model = deeplabv3_resnet50(weights=weights)
# model.classifier[4] = nn.Conv2d(256, 3, kernel_size=1)
# model = model.to(device)
#
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=1e-4)
# num_epochs = 10
#
# # ===== 5) 正式训练 =====
# for epoch in range(num_epochs):
# model.train()
# train_loss = 0
# for images, masks in tqdm(train_loader, desc=f'[Epoch {epoch+1}/{num_epochs}]'):
# images = images.to(device)
# masks = masks.to(device)
#
# optimizer.zero_grad()
# outputs = model(images)['out']
# loss = criterion(outputs, masks)
# loss.backward()
# optimizer.step()
# train_loss += loss.item()
#
# avg_train = train_loss / len(train_loader)
# print(f"[Epoch {epoch+1}] Train Loss: {avg_train:.4f}")
#
# model.eval()
# val_loss = 0
# with torch.no_grad():
# for images, masks in val_loader:
# images = images.to(device)
# masks = masks.to(device)
# outputs = model(images)['out']
# loss = criterion(outputs, masks)
# val_loss += loss.item()
# avg_val = val_loss / len(val_loader)
# print(f"[Epoch {epoch+1}] Val Loss: {avg_val:.4f}")
#
# # ===== 6) 保存模型 =====
# torch.save(model.state_dict(), 'deeplabv3plus_seaice_final.pth')
# print("🎉 模型训练完成,已保存为 deeplabv3plus_seaice_final.pth")
# lou
# import os
# import cv2
# import torch
# import numpy as np
# from torch.utils.data import Dataset, DataLoader, random_split
# from torchvision import transforms
# from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
# from sklearn.metrics import confusion_matrix
# from tqdm import tqdm
#
# # ===== 自定义数据集类(与训练一致) =====
# class SSHCachedDataset(Dataset):
# def __init__(self, image_dir, mask_dir, transform=None):
# self.transform = transform
# self.data = []
#
# image_list = sorted(os.listdir(image_dir))
# mask_list = sorted(os.listdir(mask_dir))
#
# for img_name, mask_name in zip(image_list, mask_list):
# img_path = os.path.join(image_dir, img_name)
# mask_path = os.path.join(mask_dir, mask_name)
#
# image = cv2.imread(img_path, cv2.IMREAD_COLOR)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
# self.data.append((image, mask))
#
# def __len__(self):
# return len(self.data)
#
# def __getitem__(self, idx):
# image, mask = self.data[idx]
# if self.transform:
# image = self.transform(image)
# mask = torch.from_numpy(mask).long()
# return image, mask
#
# # ===== IoU 计算函数 =====
# def compute_iou(y_true, y_pred, num_classes=3):
# y_true = y_true.flatten()
# y_pred = y_pred.flatten()
# cm = confusion_matrix(y_true, y_pred, labels=list(range(num_classes)))
# intersection = np.diag(cm)
# union = cm.sum(axis=0) + cm.sum(axis=1) - intersection
# iou = intersection / np.maximum(union, 1)
# return iou, np.mean(iou)
#
# # ===== 主程序入口 =====
# if __name__ == '__main__':
# img_dir = 'output_images'
# mask_dir = 'output_masks'
# model_path = 'deeplabv3plus_seaice_final.pth'
#
# transform = transforms.Compose([
# transforms.ToTensor(),
# ])
#
# dataset = SSHCachedDataset(img_dir, mask_dir, transform=transform)
# val_size = int(0.2 * len(dataset))
# _, val_dataset = random_split(dataset, [len(dataset) - val_size, val_size])
# val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False)
#
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# weights = DeepLabV3_ResNet50_Weights.DEFAULT
# model = deeplabv3_resnet50(weights=weights)
# model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
# model.load_state_dict(torch.load(model_path, map_location=device))
# model = model.to(device)
# model.eval()
#
# all_preds = []
# all_labels = []
#
# with torch.no_grad():
# for images, masks in tqdm(val_loader, desc='Evaluating'):
# images = images.to(device)
# outputs = model(images)['out']
# preds = outputs.argmax(dim=1).cpu().numpy()
# masks = masks.cpu().numpy()
#
# all_preds.append(preds)
# all_labels.append(masks)
#
# all_preds = np.concatenate(all_preds, axis=0)
# all_labels = np.concatenate(all_labels, axis=0)
#
# iou_per_class, mean_iou = compute_iou(all_labels, all_preds, num_classes=3)
# print("Per-class IoU:", iou_per_class)
# print("Mean IoU: ", mean_iou)
# 非单色
# import os
# import cv2
# import torch
# import numpy as np
# from tqdm import tqdm
# from torchvision import transforms
# from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
#
# # === 设置路径 ===
# image_dir = 'output_images'
# model_path = 'deeplabv3plus_seaice_final.pth'
# output_dir = 'visual_output'
# os.makedirs(output_dir, exist_ok=True)
#
# # === 模型加载 ===
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# weights = DeepLabV3_ResNet50_Weights.DEFAULT
# model = deeplabv3_resnet50(weights=weights)
# model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
# state = torch.load(model_path, map_location=device)
# model.load_state_dict(state)
# model.to(device).eval()
#
# # === 图像预处理 ===
# transform = transforms.Compose([
# transforms.ToTensor(),
# ])
#
# # === 可视化函数 ===
# def visualize(original_img, pred_mask, save_name):
# # 定义颜色映射 (BGR for OpenCV save)
# color_map = {
# 0: (0, 0, 255), # 海水 - 红
# 1: (0, 255, 0), # 海冰 - 绿
# 2: (255, 255, 0), # 陆地 - 青
# }
# h, w = pred_mask.shape
# # 合成彩色掩码
# mask_color = np.zeros((h, w, 3), dtype=np.uint8)
# for c, col in color_map.items():
# mask_color[pred_mask == c] = col
# # 缩放原图到同一尺寸
# orig_resized = cv2.resize(original_img, (w, h), interpolation=cv2.INTER_LINEAR)
# # 叠加
# overlay = cv2.addWeighted(orig_resized, 0.6, mask_color, 0.4, 0)
# # 提取海冰边界 (pred_mask==1)
# ice_mask = (pred_mask == 1).astype(np.uint8)
# contours, _ = cv2.findContours(ice_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# cv2.drawContours(overlay, contours, -1, (0, 255, 0), 2)
# # 保存 (BGR)
# out_bgr = cv2.cvtColor(overlay, cv2.COLOR_RGB2BGR)
# cv2.imwrite(os.path.join(output_dir, f'vis_{save_name}'), out_bgr)
#
# # === 主循环 ===
# file_list = sorted([f for f in os.listdir(image_dir) if f.endswith('.png')])
# for fname in tqdm(file_list, desc='Visualizing'):
# path = os.path.join(image_dir, fname)
# bgr = cv2.imread(path, cv2.IMREAD_COLOR)
# if bgr is None:
# continue
# rgb = cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)
# # 预测
# tensor = transform(rgb).unsqueeze(0).to(device)
# with torch.no_grad():
# out = model(tensor)['out']
# pred = out.argmax(dim=1).squeeze().cpu().numpy().astype(np.uint8)
# visualize(rgb, pred, fname)
#
# print(f"✅ 完成可视化,结果保存在 {output_dir} 文件夹。")
#
# 单色
# import os
# import cv2
# import torch
# import numpy as np
# from tqdm import tqdm
# from torch.utils.data import Dataset, DataLoader
# from torchvision import transforms
# from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
#
# # === 路径设置 ===
# image_dir = 'output_images'
# model_path = 'deeplabv3plus_seaice_final.pth'
# vis_dir = 'visual_output'
# mask_dir = 'mask_only'
# os.makedirs(vis_dir, exist_ok=True)
# os.makedirs(mask_dir, exist_ok=True)
#
# # === 模型加载 ===
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# weights = DeepLabV3_ResNet50_Weights.DEFAULT
# model = deeplabv3_resnet50(weights=weights)
# model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
# state = torch.load(model_path, map_location=device)
# model.load_state_dict(state)
# model.to(device).eval()
#
# # === 图像预处理 ===
# transform = transforms.Compose([transforms.ToTensor()])
#
# # === 可视化函数 ===
# def visualize(original_img, pred_mask, fname):
# # 纯色掩码
# color_map = {0: (0, 0, 255), 1: (0, 255, 0), 2: (255, 255, 0)} # BGR
# h, w = pred_mask.shape
# mask_color = np.zeros((h, w, 3), dtype=np.uint8)
# for c, col in color_map.items():
# mask_color[pred_mask == c] = col
# # 保存纯色掩码
# cv2.imwrite(os.path.join(mask_dir, f'mask_{fname}'), mask_color)
#
# # === 主循环 ===
# file_list = sorted(f for f in os.listdir(image_dir) if f.endswith('.png'))
# for fname in tqdm(file_list, desc='Saving single-color masks'):
# # 读原图用于推理尺寸,但直接读灰度也可
# path = os.path.join(image_dir, fname)
# bgr = cv2.imread(path, cv2.IMREAD_COLOR)
# rgb = cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB)
# # 推理
# tensor = transform(rgb).unsqueeze(0).to(device)
# with torch.no_grad():
# out = model(tensor)['out']
# pred = out.argmax(dim=1).squeeze().cpu().numpy().astype(np.uint8)
# visualize(bgr, pred, fname)
#
# print(f"✅ 单色掩码已保存至 {mask_dir} 文件夹")
# 评估代码
import os
import cv2
import torch
import numpy as np
from torchvision import transforms
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
from tqdm import tqdm
# --- 路径设置 ---
img_dir = 'output_images' # 输入图像目录
gt_dir = 'output_masks' # 真实掩码目录
model_path = 'deeplabv3plus_seaice_final.pth'
# --- 模型加载 ---
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
model.classifier[4] = torch.nn.Conv2d(256, 3, kernel_size=1)
state = torch.load(model_path, map_location=device)
model.load_state_dict(state)
model.to(device).eval()
# --- 统计变量 ---
TP = np.zeros(3, dtype=np.int64)
FP = np.zeros(3, dtype=np.int64)
FN = np.zeros(3, dtype=np.int64)
correct = 0
total = 0
# --- 预处理 ---
transform = transforms.Compose([
transforms.ToTensor()
])
# --- 获取文件列表并配对 ---
img_list = sorted([f for f in os.listdir(img_dir) if f.endswith('.png')])
mask_list = sorted([f for f in os.listdir(gt_dir) if f.endswith('.png')])
assert len(img_list) == len(mask_list), "图像和掩码数量不一致"
paired = []
for img_fname in img_list:
mask_fname = img_fname.replace('ssh_', 'mask_')
if mask_fname in mask_list:
paired.append((img_fname, mask_fname))
else:
raise FileNotFoundError(f"未找到与 {img_fname} 对应的掩码 {mask_fname}")
# --- 遍历评估 ---
for img_fname, mask_fname in tqdm(paired, desc='评估中'):
img_path = os.path.join(img_dir, img_fname)
gt_path = os.path.join(gt_dir, mask_fname)
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
gt = cv2.imread(gt_path, cv2.IMREAD_GRAYSCALE)
assert img is not None and gt is not None, f"读取失败: {img_path} 或 {gt_path}"
inp = transform(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)).unsqueeze(0).to(device)
with torch.no_grad():
out = model(inp)['out']
pred = out.argmax(dim=1).squeeze().cpu().numpy().astype(np.uint8)
correct += np.sum(pred == gt)
total += gt.size
for c in range(3):
TP[c] += np.sum((pred==c) & (gt==c))
FP[c] += np.sum((pred==c) & (gt!=c))
FN[c] += np.sum((pred!=c) & (gt==c))
# --- 计算评估指标 ---
pixel_acc = correct / total
IoU = TP / (TP + FP + FN + 1e-6)
mIoU = IoU.mean()
Precision = TP / (TP + FP + 1e-6)
Recall = TP / (TP + FN + 1e-6)
F1 = 2 * Precision * Recall / (Precision + Recall + 1e-6)
# --- 打印详细评估结果 ---
print(f"总像素: {total}")
print(f"正确分类像素: {correct}")
print(f"像素准确率: {pixel_acc:.4f}\n")
for i, name in enumerate(['海水','海冰','陆地']):
print(f"【{name} 类】")
print(f"TP: {TP[i]} | FP: {FP[i]} | FN: {FN[i]}")
print(f"IoU : {IoU[i]:.4f}")
print(f"Precision : {Precision[i]:.4f}")
print(f"Recall : {Recall[i]:.4f}")
print(f"F1 分数 : {F1[i]:.4f}\n")
print(f"平均 IoU: {mIoU:.4f}")