一.排序
概念:
排序其本质是将一组无序的数据元素(如数字、字符、对象等)按照某种特定的规则(称为 "排序依据")重新排列成有序序列的过程
核心目的:
排序的核心目的是降低数据的无序性,使数据满足 "可快速检索""可按规律处理" 等需求
分类(根据排序过程中数据是否全部存放在内存中):
- 内部排序(Internal Sorting)
所有待排序数据均可放入内存中,排序过程仅在内存中完成。常见的排序算法(如冒泡排序、插入排序、快速排序等)均为内部排序。 - 外部排序(External Sorting)
待排序数据量过大,无法全部放入内存(如 TB 级数据),排序过程需要通过内存与外存(如硬盘)的数据交换完成。例如数据库中的大表排序,通常结合内部排序和归并操作实现
排序的稳定性:
假设有一组数据,其中包含两个值相等的元素(记为 a 和 b),且在排序前 a 位于 b 之前(即 a 的索引 < b 的索引)
如果排序后,a 仍然在 b 之前,则称该排序算法是稳定的;
如果排序后,b 跑到了 a 之前,则称该排序算法是不稳定的
排序算法
1)直接插入排序
直接插入排序(Straight Insertion Sort)是一种简单直观的排序算法,其核心思想是将数组分为已排序和未排序两部分,每次从未排序部分取出一个元素,插入到已排序部分的正确位置
直接插入排序是稳定的
时间复杂度:
最坏情况:数组完全逆序,每次插入需移动所有已排序元素,时间为O(n^2)
最好情况:数组已有序,每次插入仅需比较 1 次,时间为O(n)。平均情况:O(n^2)
空间复杂度:
仅需常数级额外空间(暂存当前元素),空间复杂度为O(1),属于原地排序
java
public void insertSort(int[] array) {
for (int i = 1; i < array.length; i++) {
int tmp = array[i];
int j = i-1;
for (; j >= 0; j--) {
if (tmp < array[j]) {
array[j+1] = array[j];
}else {
break;
}
}
array[j+1] = tmp;
}
}注意:
- 时间复杂度可分为三部分操作,
遍历,查找应放置位置,移动数据(查找与移动其实同时发生但我看为了两步)
无论情况如何,遍历部分永远不变为(n-1)
而查找部分,在最坏情况下(倒序)为一个等差数列
而数据移动部分,在该写法中与查找同时发生(边比较,边移动)


-
我曾想过何不用二分查找优化查询应放置位置
这确实可以优化查询这一步,但该做法不同于给出的示例,虽优化了比较次数,但移动次数无法优化(依然边比较边移动,受数组性质的限制,对数据的移动量无法改变)
-
进而我想到了链表的实现,而链表虽能优化数据的移动却又无法同时又由于链表性质的限制,无法通过下标索引实现二分查找,故在查找部分效率较低只能顺序查找,但是却能优化数据的移动
2)希尔排序(直接插入排序的优化)
希尔排序(Shell Sort)是插入排序的一种改进版本,也称为 "缩小增量排序"(Diminishing Increment Sort)。它通过将原始数据分成多个子序列来改善插入排序的性能,使得元素能够更快地移动到最终位置
希尔排序是不稳定的



java
public void shellSort(int[] array) {
int gap = array.length;
while (gap > 1) {
//增量序列选择为希尔原始序列
gap /= 2;
shell(array,gap);
}
}
public void shell(int[] array,int gap) {
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i-gap;
for (; j >= 0; j -= gap) {
if (tmp < array[j]) {
array[j+gap] = array[j];
}else {
break;
}
}
array[j+gap] = tmp;
}
}3)选择排序
选择排序不是稳定的排序
空间复杂度为O(1)
单向选择排序
其核心思想是每一轮从未排序部分选择最小(或最大)的元素,与未排序部分的第一个元素交换位置,逐步将数组分为「已排序部分」和「未排序部分」。整个过程是单向的(从左到右或从右到左),因此称为单向选择排序

java
public void selectSort(int[] array) {
int minIndex;
for (int i = 0; i < array.length; i++) {
minIndex = i;
for (int j = i + 1; j < array.length; j++) {
if (array[minIndex] > array[j]) {
minIndex = j;
}
}
//swap交换函数
swap(array,i,minIndex);
}
}双向选择排序
双向选择排序(Bidirectional Selection Sort) 是对单向选择排序的优化,它在每一轮中同时寻找最小值和最大值,并将它们分别放到未排序部分的两端。这样每轮可以确定两个元素的位置,理论上比单向选择排序快约一倍

java
public void selectSort2(int[] array) {
int left = 0;
int right = array.length-1;
while (left < right) {
//minIndex和maxIndex 的初始值并不关键,只要范围在该数组内就行
int minIndex = left;
int maxIndex = left;
//注意内层循环的条件,一定是i <= right
for (int i = left; i <= right ; i++) {
if(array[i] < array[minIndex]) {
minIndex = i;
}
if(array[i] > array[maxIndex]) {
maxIndex = i;
}
}
swap(array,left,minIndex);
//核心问题:索引冲突,在执行第一个swap的同时,下标的改变可能影响下一个swap
if(maxIndex == left) {
maxIndex = minIndex;
}
swap(array,right,maxIndex);
left++;
right--;
}
}
public void selectSort3(int[] array) {
//类比selectSort2
int left = 0;
int right = array.length - 1;
while (left < right) {
//为了说明minIndex和maxIndex 的初始值并不关键,与selectSort2不同
int minIndex = left;
int maxIndex = right;
for (int j = left; j <= right; j++) {
if (array[j] > array[maxIndex]) {
maxIndex = j;
}
if (array[j] < array[minIndex]) {
minIndex = j;
}
}
swap(array, minIndex, left);
if (maxIndex == left) {
// 处理索引冲突,依然是写在第一个swap后
maxIndex = minIndex;
}
swap(array, maxIndex, right);
left++;
right--;
}
}注意:
核心问题:索引冲突,在执行第一个swap的同时,下标的改变可能影响下一个swap,处理方式如代码所示
4)冒泡排序
冒泡排序(Bubble Sort)是一种简单直观的排序算法,其核心思想是通过重复比较相邻元素并交换顺序错误的元素,使值较大的元素像 "气泡" 一样逐渐 "上浮" 到数组的末尾
冒泡排序可以有效优化
冒泡排序是稳定的
空间复杂度是O(1)
时间复杂度 :
最坏情况是否优化结果相同

最好情况
- 如果无优化:

- 如果进行了优化:

java
//无优化
public static void bubbleSort(int[] array) {
for (int i = 0; i < array.length-1; i++) {
for (int j = 0; j < array.length-1-i; j++) {
if(array[j] > array[j+1]) {
swap(array,j,j+1);
}
}
}
}
//有优化
public static void bubbleSort(int[] array) {
for (int i = 0; i < array.length-1; i++) {
boolean flg = false;
for (int j = 0; j < array.length-1-i; j++) {
if(array[j] > array[j+1]) {
swap(array,j,j+1);
flg = true;
}
}
if(!flg) {
return;
}
}
}5)堆排序
堆排序(Heap Sort)是一种基于二叉堆数据结构的高效排序算法

体现实现过程的例子
大堆9, 6, 5, 1, 3, 4, 2, 1



建堆的时间复杂度分析
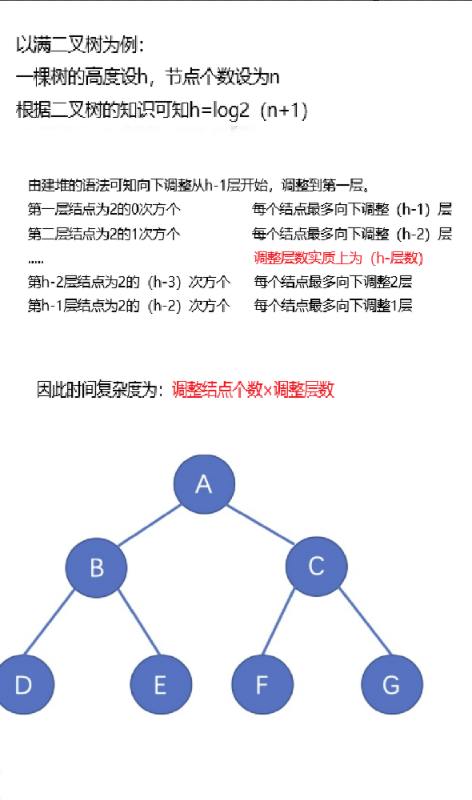
因此根据数学计算可得结果为:
2的h次方 - h -1
又因为图中所写二叉树的知识点将h替换为n
可得结果为
n-log2(n+1)≈ n
因此建堆的时间复杂度为O(n)
堆排序实现

java
public void heapSort(int[] array) {
createBigHeap(array);
int end = array.length-1;
while (end > 0) {
swap(array,0,end);
siftDown(array,0,end);
end--;
}
}
private void createBigHeap(int[] array) {
for (int parent = (array.length-1-1)/2; parent >= 0 ; parent--) {
siftDown(array,parent,array.length);
}
}
private void siftDown(int[] array,int parent,int end) {
int child = 2*parent+1;
while (child < end) {
if(child + 1 < end && array[child] < array[child+1]) {
child++;
}
if(array[child] > array[parent]) {
swap(array,child,parent);
parent = child;
child = 2*parent+1;
}else {
break;
}
}
}注意:
从大到小排序建小堆,从小到大排序建大堆
以给出具体过程的例子来说,建立大堆后将最大数值放置到堆的"末尾"(即已调整部分)
然后调整堆时每次减小堆大小(即未调整部分),给出新的"末尾"