第五章:数据模型与架构
欢迎来到第五章!
在前几章中,我们学习了网页用户界面(UI)(控制面板)、应用配置(系统参数设置)、任务编排(视频生成流程的总调度)和任务状态管理(进度追踪机制)。
现在我们将探讨支撑这些功能的基础构件:数据模型与架构。
什么是数据模型与架构?
想象烘焙蛋糕时需要食谱(操作指南)和精确配比的原料(数据)。但如何确定面粉该用什么碗装?糖的计量方式?这需要原料与工具的结构化组织。
在软件系统中,数据模型 和架构正是为此而生:
- 架构(Schema) :类似蓝图模板 ,定义数据组成要素、类型(文本/数值/布尔值/列表等)及组织方式。例如"用户"架构可能包含
name(文本)、age(数值)、is_active(布尔值)三个字段。 - 数据模型 :基于架构创建的具体实例对象 ,严格遵循蓝图规则。例如用户模型的实例可能是
{ "name": "Alice", "age": 30, "is_active": true }。
在MoneyPrinterTurbo中,数据模型与架构用于定义:
- 视频生成请求的结构(用户在UI中配置的所有参数)
- 视频素材信息的格式(如URL地址、时长等)
- 系统内部模块/外部服务间的通信协议
- 第四章所述任务状态的数据结构
这种结构化设计确保数据组织有序、格式统一,便于各模块正确处理与流转。
基于Pydantic的数据模型实现
前文传送:Meetily后端框架 AI摘要结构化 | SummaryResponse模型 | Pydantic库 | vs marshmallow库
MoneyPrinterTurbo使用Python库Pydantic构建数据模型:
- Pydantic特性 :通过Python类型提示(如
str/int/bool/list)定义数据结构。创建模型对象时自动验证数据合规性,若类型错误(如文本填入数值字段)则抛出异常。 - 选择Pydantic的原因 :
- 定义清晰:代码中显式声明数据结构
- 自动校验:数据输入时即时验证
- 类型转换:自动将字典等原始数据转为结构化对象
项目主要数据模型定义于app/models/schema.py,均继承自Pydantic的BaseModel。
核心模型示例:VideoParams
视频生成的核心模型是VideoParams,它完整承载用户在UI中配置的所有参数。以下是app/models/schema.py中的简化定义:
python
# 摘自app/models/schema.py的简化代码
from typing import Optional, List, Union
from enum import Enum
from pydantic import BaseModel
import pydantic.dataclasses
# 视频比例枚举定义
class VideoAspect(str, Enum):
landscape = "16:9" # 横屏
portrait = "9:16" # 竖屏
square = "1:1" # 正方形
# 素材信息数据结构
@pydantic.dataclasses.dataclass
class MaterialInfo:
provider: str = "pexels" # 素材源
url: str = "" # 素材URL
duration: int = 0 # 素材时长
# 主视频参数模型
class VideoParams(BaseModel):
video_subject: str # 必填:视频主题(字符串)
video_script: str = "" # 可选:剧本文本(默认空字符串)
video_terms: Optional[str | list] = None # 可选:关键词(字符串/列表/空值)
video_aspect: Optional[VideoAspect] = VideoAspect.portrait.value # 比例(枚举值)
video_clip_duration: Optional[int] = 5 # 素材片段时长(默认5秒)
# ... 其他视频/音频/字幕参数 ...
video_materials: Optional[List[MaterialInfo]] = None # 素材列表(MaterialInfo对象)
subtitle_enabled: Optional[bool] = True # 字幕开关(布尔值,默认开启)
font_size: int = 60 # 字体大小(整型,默认60)
# ... 更多字幕参数 ...
# Pydantic配置(高级设置)
class Config:
arbitrary_types_allowed = True关键要素解析:
- 继承结构 :
class VideoParams(BaseModel)声明继承自Pydantic基类 - 字段类型 :
video_subject: str必填字符串字段video_script: str = ""带默认值的可选字段Optional[...]表示可空字段(如Optional[str]可为字符串或None)Union[bool, str]允许布尔值或字符串(如字幕背景颜色字段)
- 嵌套模型 :
List[MaterialInfo]表示该字段为MaterialInfo对象的列表 - 枚举约束 :
VideoAspect枚举限制比例参数只能取三个预定义值
模型在系统中的应用
数据模型贯穿系统各模块的交互流程:
1. 网页UI的数据封装
用户在UI表单填写参数后,数据被封装为字典并转换为VideoParams对象:
python
# 网页UI(Streamlit)中的概念代码
from app.models.schema import VideoParams
# 收集表单数据
ui_data = {
"video_subject": st.session_state["video_subject_input"],
"video_aspect": st.session_state["video_aspect_select"],
# ... 其他参数 ...
}
try:
# 创建结构化对象
video_params = VideoParams(**ui_data)
print(f"创建视频参数对象:{video_params.video_subject}")
# 传递给任务编排器
# start_video_task(video_params)
except pydantic.ValidationError as e:
st.error(f"参数错误:{e}") # 数据校验失败时提示此过程通过Pydantic自动校验数据合法性,确保传入编排器的参数结构正确。
2. 任务编排器的参数传递
编排器入口函数明确接收VideoParams类型参数:
python
# 摘自app/services/task.py的简化代码
from app.models.schema import VideoParams
def start(task_id, params: VideoParams):
logger.info(f"任务{task_id}启动,主题:{params.video_subject}")
# 直接访问结构化参数
aspect_ratio = params.video_aspect
font_size = params.font_size
# ... 调用各服务模块 ...通过params.field_name的点语法,编排器可高效获取各项参数,无需处理原始字典数据。
3. 服务间通信
其他服务模块也采用模型化交互:
- 素材服务返回
MaterialInfo对象列表 - API接口使用
TaskResponse/VideoScriptResponse等模型定义请求响应格式 - 状态管理器存储的任务状态数据遵循
TaskQueryResponse结构
4. 状态管理的结构化存储
第四章所述状态数据虽然以字典形式存储,但查询响应仍通过模型保证结构一致性:
python
# 状态查询响应模型示例
class TaskQueryResponse(BaseModel):
task_id: str
state: int
progress: int
videos: Optional[List[str]] = None
error: Optional[str] = NonePydantic的底层运作机制
创建Pydantic模型实例时发生以下过程:
- 数据解析:将原始数据(如UI提交的字典)转换为字段值
- 类型校验:验证各字段类型是否符合定义
- 自动转换:尝试类型兼容转换(如字符串"123"转为整型123)
- 对象实例化:校验通过后生成结构化对象
以下序列图展示模型在系统中的应用流程:
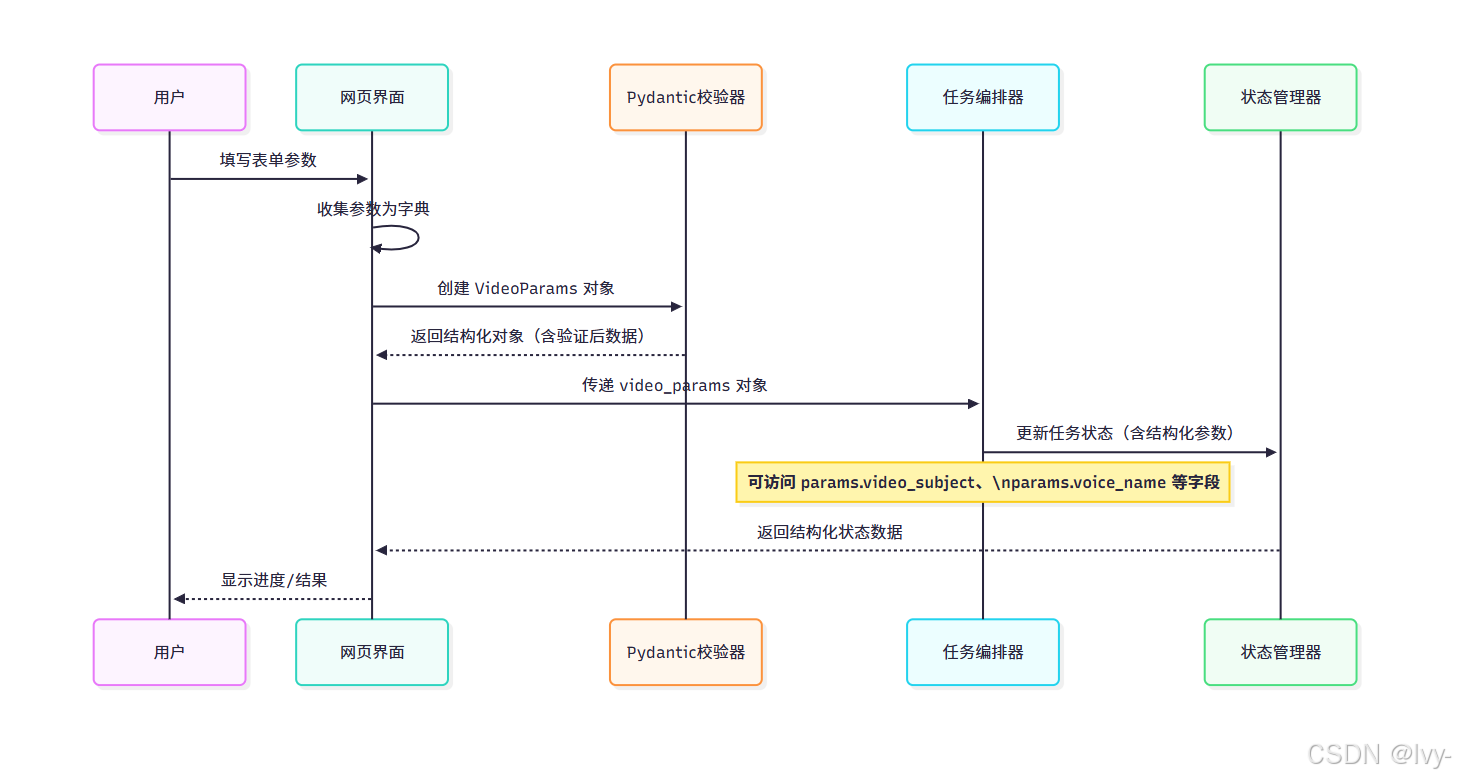
该流程体现了模型如何确保从用户输入到状态存储的全链路数据一致性。
总结
数据模型与架构作为系统基石,通过Pydantic等工具实现结构化数据定义与校验。VideoParams等模型清晰定义了视频生成任务的参数结构,贯穿UI、编排器、服务模块与状态管理的全流程。这种设计保障了数据流动的可靠性与系统扩展性。
接下来我们将深入探讨驱动剧本生成的核心模块:大语言模型服务,解析AI如何将用户主题转化为精彩剧本。
第六章:LLM集成
在前几章中,我们探讨了《第一章:配置》(如何设置系统)、《第二章:任务管理》(任务如何排队处理)、《第三章:视频生成任务》(视频任务的处理步骤)以及《第四章:任务状态》(如何跟踪任务进度)。
现在,让我们看看最激动人心的部分:MoneyPrinterTurbo如何利用人工智能生成视频创意内容。这正是由LLM集成组件实现的。
为何需要LLM集成?
假设我们要制作关于"学习编程的优势"的视频,传统流程需要:
- 编写说明性脚本
- 构思视觉创意或搜索匹配脚本的视频素材关键词(如"敲击笔记本键盘"、"团队协作"、"增长趋势图")
LLM集成 组件通过连接大语言模型(如OpenAI的GPT系列、DeepSeek、Moonshot等),实现以下核心功能:
- 根据视频主题生成完整脚本
- 基于脚本内容提取相关素材搜索关键词
- 构建创意概念与视频素材间的智能桥梁
前文传送: BrowserOS LLM供应商集成 | 更新系统 | Sparkle框架 | 自动化构建系统 | Generate Ninja
LLM集成工作原理
在视频生成任务中,LLM集成执行以下流程:
连接LLM服务商
如第一章:配置所述,通过config.toml文件配置LLM服务商:
toml
# config.toml(简化LLM配置段)
[app]
llm_provider = "OpenAI" # 可选DeepSeek/Moonshot/Ollama等
# OpenAI配置
openai_api_key = "您的OpenAI密钥"
openai_model_name = "gpt-3.5-turbo"
# DeepSeek配置
deepseek_api_key = "您的DeepSeek密钥"
deepseek_base_url = "https://api.deepseek.com"
deepseek_model_name = "deepseek-chat"API接口视图
MoneyPrinterTurbo提供独立API端点供Web UI调用:
1. 生成脚本接口
python
@router.post("/scripts")
def generate_video_script(body: VideoScriptRequest):
video_script = llm.generate_script(
video_subject=body.video_subject,
language=body.video_language,
paragraph_number=body.paragraph_number,
)
return {"video_script": video_script}- 输入:POST请求体含主题、语言、段落数
- 输出:JSON格式生成脚本
2. 生成关键词接口
python
@router.post("/terms")
def generate_video_terms(body: VideoTermsRequest):
video_terms = llm.generate_terms(
video_subject=body.video_subject,
video_script=body.video_script,
amount=body.amount,
)
return {"video_terms": video_terms}- 输入:POST请求体含主题、脚本、关键词数量
- 输出:JSON格式关键词列表
核心实现(app/services/llm.py)
通信枢纽(_generate_response)
python
def _generate_response(prompt: str) -> str:
llm_provider = config.app.get("llm_provider")
# 根据配置初始化不同服务商客户端
if llm_provider == "openai":
client = OpenAI(api_key=config.openai_api_key)
elif llm_provider == "deepseek":
client = OpenAI(api_key=config.deepseek_api_key)
# 发送请求并处理响应
response = client.chat.completions.create(
model=model_name,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content脚本生成逻辑
python
def generate_script(video_subject: str, language: str, paragraph_number: int):
prompt = f"""
# 角色:视频脚本生成器
## 目标:基于主题生成{paragraph_number}段视频脚本
## 约束:
1. 直接输出原始脚本内容
2. 禁用Markdown格式
3. 使用与主题相同的语言
## 初始化:
- 视频主题:{video_subject}
""".strip()
return _generate_response(prompt)关键词生成逻辑
python
def generate_terms(video_subject: str, video_script: str, amount: int):
prompt = f"""
# 角色:视频搜索词生成器
## 目标:生成{amount}个素材搜索词
## 约束:
1. 输出JSON数组格式
2. 每个词1-3个单词
## 上下文:
### 视频主题
{video_subject}
### 视频脚本
{video_script}
""".strip()
response = _generate_response(prompt)
return json.loads(response)流程图解
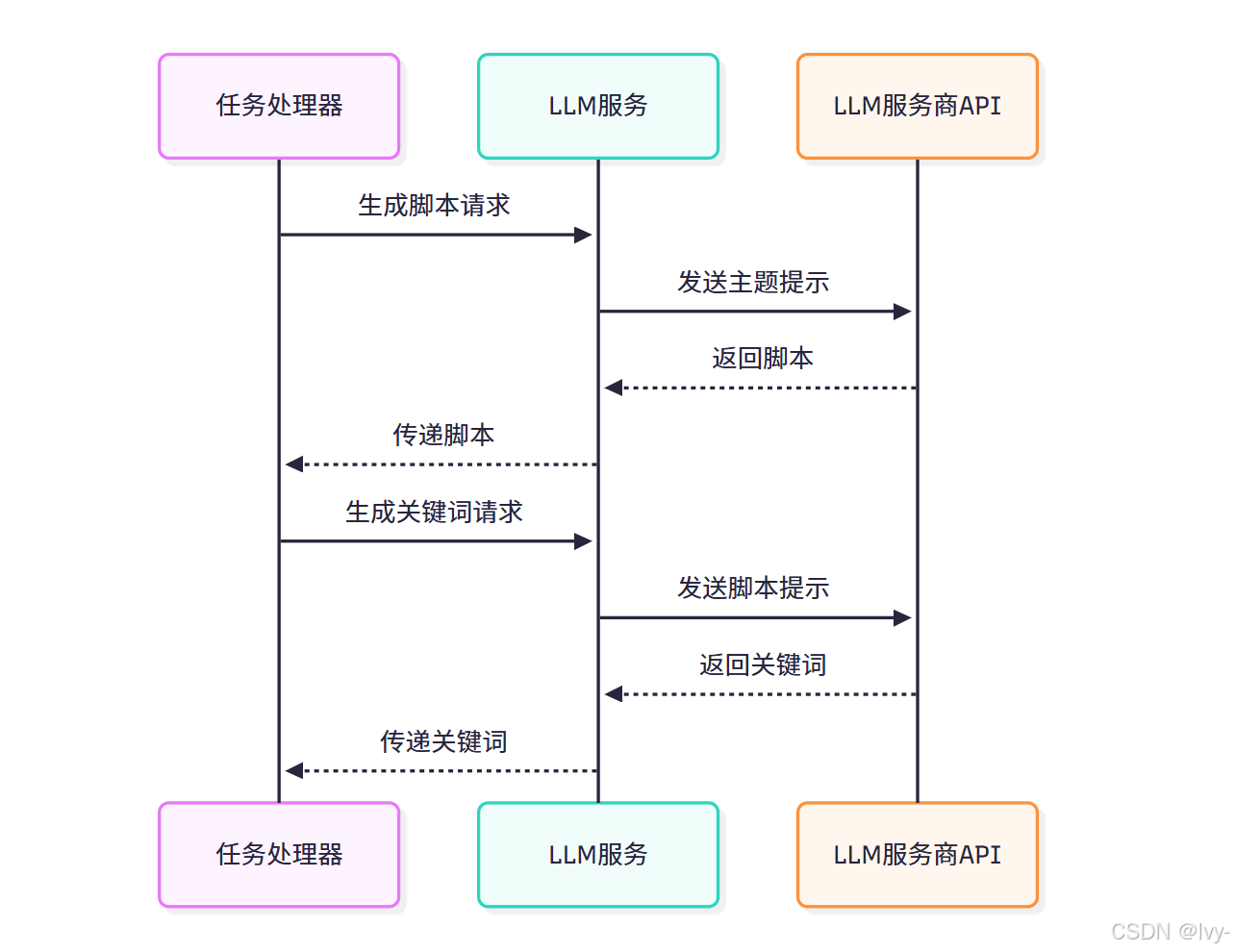
结论
LLM集成组件通过智能生成脚本和素材关键词,成为自动化视频制作流程的核心。