什么是MCP
最近在做一些AI相关的软件,正好接触到了MCP,现在包括Visual Studio Code和Cursor,以及很多编程的IDE都支持了MCP调用,这篇文章就来简单介绍一下MCP是什么以及工作原理浅析。
MCP,全称Model Context Protocol(模型上下文协议),是一种由Anthropic公司开发的开放协议。它的主要目的是让大型语言模型(LLM)能够与外部数据源(如数据库、API)、工具(如计算器、搜索引擎)和服务无缝集成。官网把MCP比作AI的USB-C接口,以一个通用的接口实现各种各样的扩展。
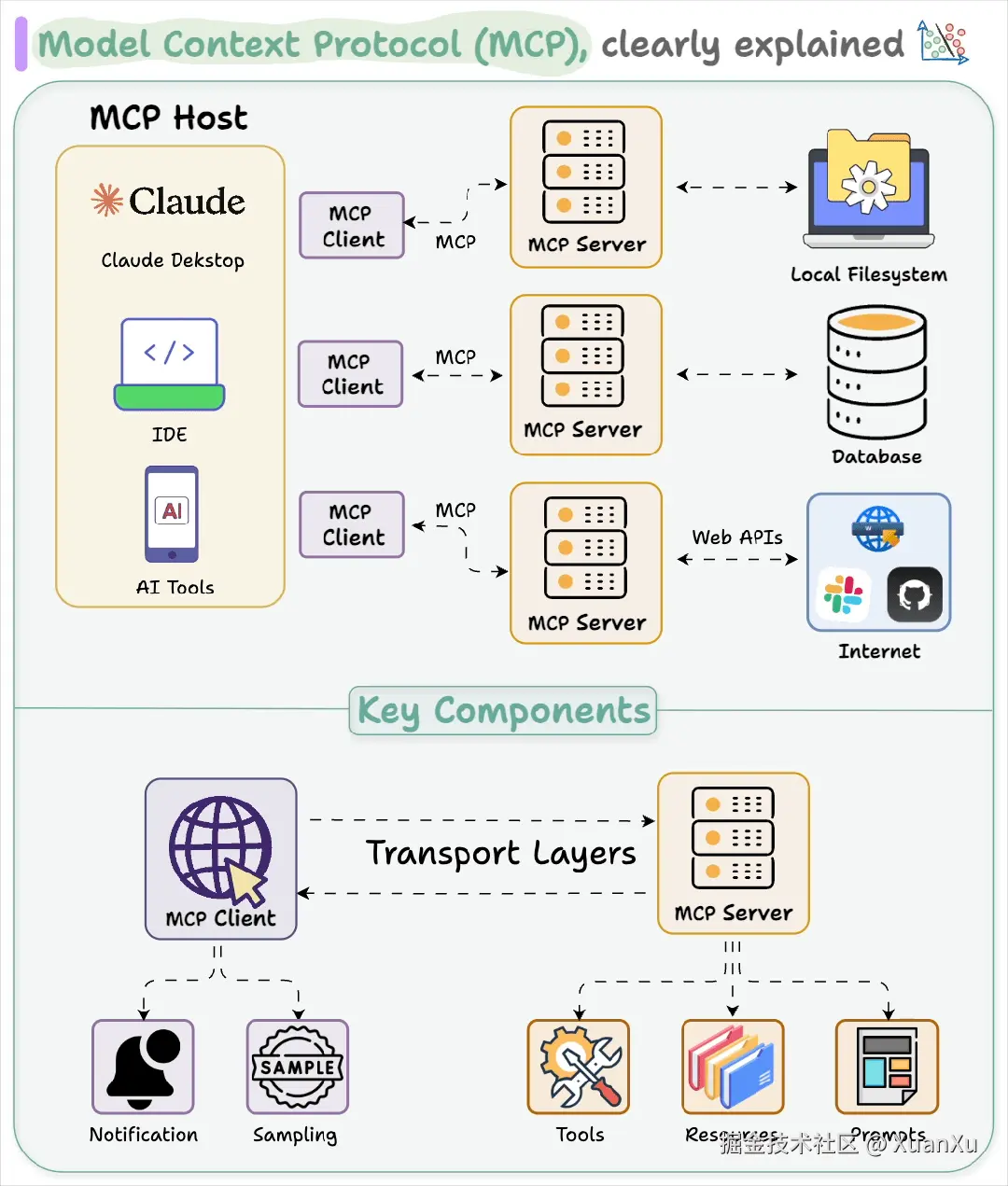
这里有几个重要的概念
MCP Client
这就是你本机的客户端,比如VSCode,Cursor等等,负责对MCP Server发起请求,实现对MCP Server的调用。
核心职责:
-
上下文管理
-
维护完整的对话历史(用户消息/模型回复/工具结果)
-
按 MCP 协议标准化组织上下文格式
-
-
大模型协作
-
将用户请求 + 上下文 + 可用工具列表发送给大模型
-
解析模型响应:判断是最终答案还是工具调用请求
-
-
工具执行引擎
-
执行模型请求的工具调用(API/数据库/计算等)
-
将工具结果标记化后注入上下文tools字段
-
MCP Server
MCP Server就是实现功能的服务器,可以对接不同的服务,比如Weather MCP可以对接一个天气查询服务,查询出来的结果通过MCP协议来进行发送,本机的MCP Client就可以接收到并喂给AI。MCP Server不一定要是云端远程的服务器,也可以是本地搭建的,直接连接本地数据库,只要实现MCP协议就可以调用。
核心职责:
协议适配器
- 接收符合 MCP 规范的请求(标准化 JSON 格式)
- 将tools call输出转换为 MCP 结构化响应
MCP协议
定义了所有请求和响应的标准格式,这样即使不同的客户端,不同的服务器,只要实现了MCP协议就可以实现兼容,MCP Client和MCP Server就是通过这个协议来进行通信。
关于MCP协议的详细介绍可以看Anthropic的官方文档
Specification - Model Context Protocol
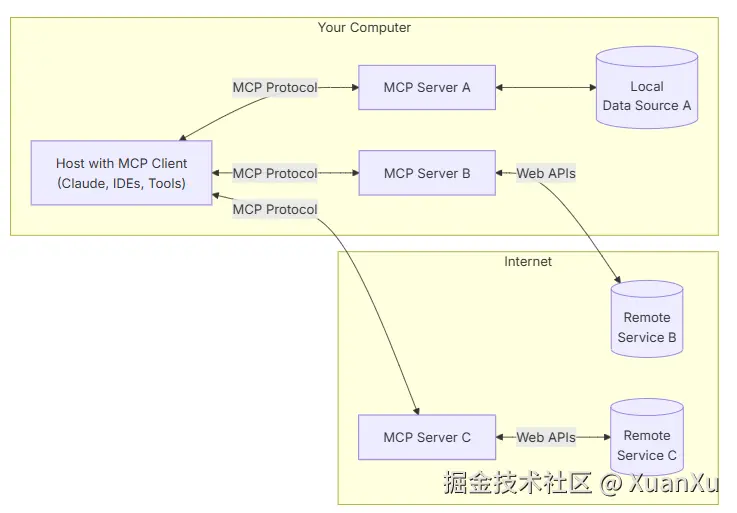
MCP传输机制
简单来说,MCP服务器主要做这几件事
-
提供上下文和数据,告诉AI这个服务器能干什么
-
提供一个Function可供AI调用
MCP客户端主要做这几件事
-
每次获取到AI生成的结果,检查AI调用tools的请求,并进行调用,之后加入上下文返回给AI
-
最后将AI返回的结果展示给用户
MCP协议通信格式
MCP协议的数据传输统一使用JSON-RPC 2.0传输格式,大模型和用户进行交互时发送的请求都会使用该格式来进行传输。
MCP协议通信的通道
STDIO标准输入输出
Stdio协议使用标准输入输出流来实现通信,可以直接实现本地工具的调用并获取调用结果。写前端时Cursor的Agent模式调用命令行工具,执行npm install以及npm run dev实际上就是使用的Stdio协议来调用MCP Server,只需要在配置中将npm添加为MCP Server即可。
下方就配置了一个名为npm-install的本地MCP Server。
json
{
"mcpServers": {
"npm-install": {
"command": "npm,
"args": [
"install"
]
}
}
}HTTP SSE
sse协议全称为Server-Sent-Event,也就是通过服务器自动发送事件来获取更新消息。有了这项技术,大模型生成出一个新的token的时候就不需要MCP Client一直循环请求获取,而是直接收到服务器推送过来的消息进行显示(DeepSeek的网页展示token就是使用的这项技术)。sse和WebSocket有些类似,但是SSE只能是服务器推送消息,而ws是双向通信。
在MCP协议中,对于远程的,需要调用云端的MCP Server,就采用sse来和MCP Client进行交互。比如下方定义了一个fetch MCP Server,大模型可以调用这个MCP Server来获取网页内容。
json
{
"mcpServers": {
"fetch": {
"type": "sse",
"url": "https://example.fetch.com/sse"
}
}
}并不是所有调用远程的API都必须使用sse,你也可以使用node.js自己实现一个Stdio协议的MCP Server,然后自己编写代码在内部使用fetch或者axios来对远程的API来进行调用。这样直接在本地配置npx启动MCP Server,大模型请求的时候就是执行本地的命令,然后使用http请求调用远程API。
在MCP Client启动时,就会获取所有MCP Server的信息,之后你每次和大模型聊天时,MCP Server的信息将会被加在模型的上下文中一起发送给大模型,大模型就可以知道有哪些工具可以调用并发起调用请求了。
下面是一次对话的简单介绍。
比如我们在MCP Client软件中问大模型今天上海天气怎么样。
那么我们将会发送一个请求给大模型,messages中为用户发送的信息,还会带上一个tools字段,告诉大模型它有哪些工具可供调用,比如下方我们就告诉了大模型有一个weather工具可以调用。
json
{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "今天上海天气怎么样?"
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": true,
"tools": [
{
"type": "function",
"function": {
"name": "weather",
"description": "获取国内的天气预报",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "需要查询的地区"
}
}
}
}
}
]
}接下来大模型进行响应,模型会进行判断是否需要执行tools
json
{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "今天上海天气怎么样?"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_M4eYNv6oPaLunpZLe1iWdfiK",
"function": {
"name": "weather",
"arguments": "{\"location\":\"上海\"}"
},
"type": "function"
}
]
},
{
"role": "tool",
"content": "[{\"type\":\"text\",\"text\":\"地点: 121,31\\n观测时间: 2025-03-27T16:51+08:00\\n天气: 阴\\n温度: 13°C\\n体感温度: 12°C\\n风向: 东北风\\n风力: 1级\"}]",
"tool_call_id": "call_M4eYNv6oPaLunpZLe1iWdfiK"
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": true,
"tools": [
{
"type": "function",
"function": {
"name": "fd71edc4f65924613b9fd8330e78eb243",
"description": "获取中国国内的天气预报",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "需要查询的地区"
}
}
}
}
}
]
}大模型会判断出用户想要查询天气,于是会生成一个调用weather tool的请求,下方就是大模型返回的结果。
json
{
"role": "assistant",
"tool_calls": [
{
"id": "call_M4eYNv6oPaLunpZLe1iWdfiK",
"function": {
"name": "weather",
"arguments": "{\"location\":\"上海\"}"
},
"type": "function"
}
]
}然后MCP Client获取到大模型的响应之后,发现有调用tools的请求,就会去调用对应的MCP Server,再将调用的结果也添加到上下文中。
json
{
"role": "tool",
"content": "[{\"type\":\"text\",\"text\":\"地点: 121,31\\n观测时间: 2025-03-27T16:51+08:00\\n天气: 阴\\n温度: 13°C\\n体感温度: 12°C\\n风向: 东北风\\n风力: 1级\"}]",
"tool_call_id": "call_M4eYNv6oPaLunpZLe1iWdfiK"
}最后将调用完tool汇总的上下文一起再发回给大模型,大模型就可以进行总结然后生成结果返回给用户了。
总结
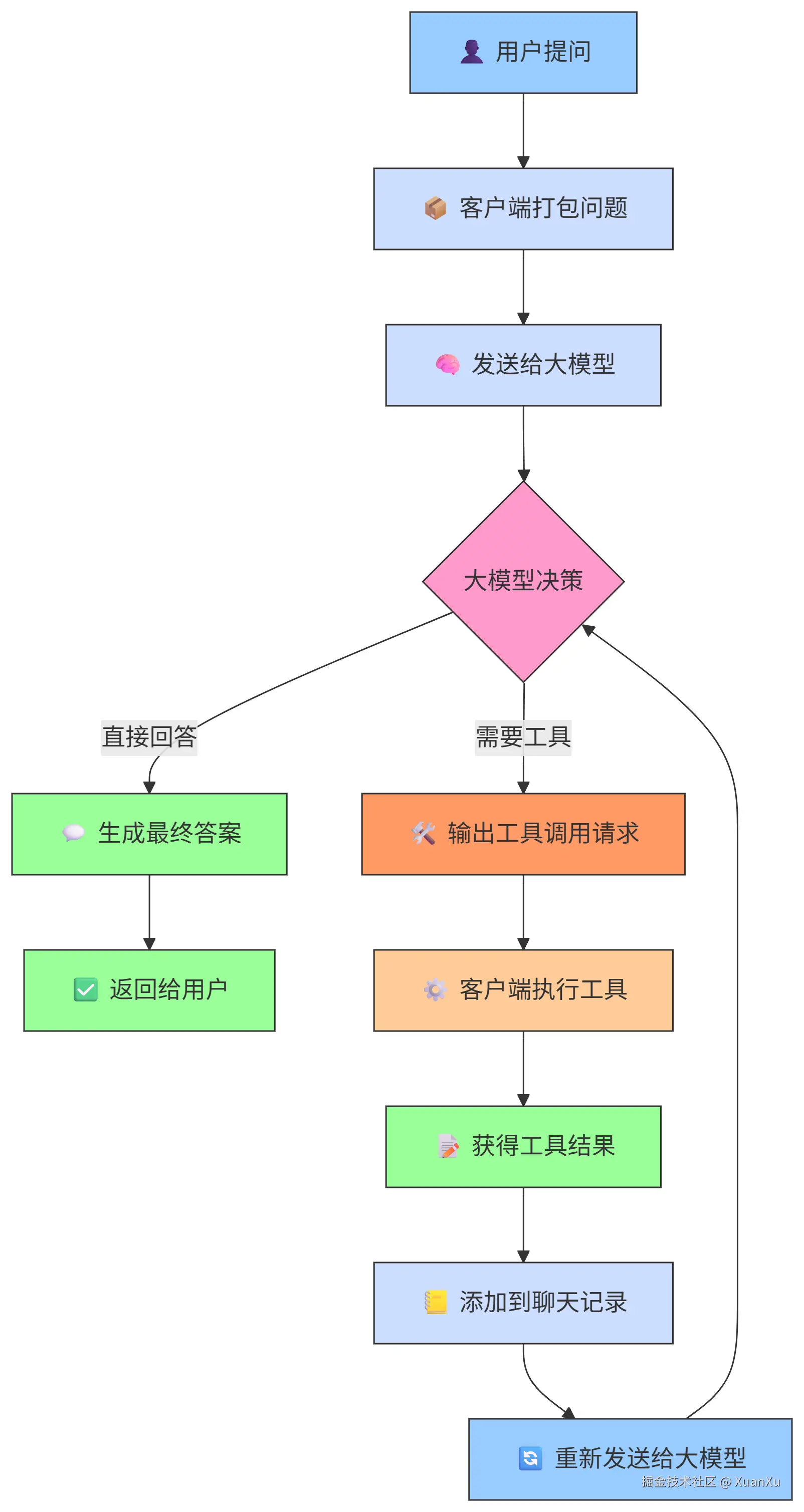
MCP调用过程
MCP协议调用通信过程中,严格遵循角色 (role): system, user, assistant, tool,所有交互历史(用户输入、LLM响应、工具请求、工具结果)都按顺序追加到这个列表中。每次调用LLM都传入整个 messages 列表。 LLM 通过它理解整个对话历史和状态。
当 LLM 决定调用工具时,它不会在普通文本 content 中描述请求 。相反,它会在在响应消息 (role='assistant') 中包含一个特殊的 tool_calls 属性 (MCP 核心约定)。
客户端执行工具并返回结果:
-
客户端解析
tool_calls,执行对应的工具函数。 -
对于每个完成的工具调用,客户端构造一个
role='tool'的消息。 -
这个消息必须包含:
-
content: 工具执行的结果(文本或可序列化数据)。 -
tool_call_id: 必须与请求中的id精确匹配 (MCP 核心机制,确保结果关联到正确的请求)。
-
总结下来,MCP协议的核心逻辑就是一个while循环,本质其实就是你和大模型聊天的时候告诉大模型有哪些工具是可以调用的,每个工具各自都能实现什么功能,然后大模型根据自己的判断来生成调用工具的参数,MCP Client识别到了大模型调用工具的参数,调用了模型之后再发回去,大模型再继续响应。